 代碼+實驗分析,助你全面理解C3F
代碼+實驗分析,助你全面理解C3F
近兩年,有關人群計數的文章呈現出爆炸式增長。然而,人群計數不像其他任務(目標檢測、語義分割等)有著簡潔/易開發的開源代碼框架,大大降低了我們對于idea的驗證效率。
因此在2018年12月份,我萌生了自己搭一個人群計數框架的想法,盡可能兼顧當前主流數據集和主流算法。并于2019年3月底基本完成了主體框架。代碼發布之后,由于缺少對于代碼細節的文檔介紹,issues和emails讓人應接不暇。所以,在這里對該項目做一個代碼層面上的介紹,并輔之以一些實驗分析來幫助大家有效提高網絡性能。更重要的,希望能夠拋磚引玉,讓大家利用C3F,更高效地研究出性能更好的人群計數網絡,推動該領域的發展。
本文主要內容包括:
數據處理:不同數據集的處理過程。
模型:基于ImageNet分類模型設計的人群計數器以及我們復現的一些主流網絡。
訓練技巧:一些常見的網絡訓練技巧。
實驗結果:在Shanghai Tech Part B數據集上的實驗結果及分析。
總結。
致謝。
Q&A:一些常見問題的解答。
1. 數據處理
我們提供了常見的六個主流數據庫的預處理代碼,處理好的數據集以及PyTorch下的data loader,包括UCF_CC_50[1](UCF50),Shanghai Tech Part A/B[2](SHT A/B),WorldExpo'10[3](WE),UCF-QNRF[4](QNRF)以及GCC[5]。后期還會提供UCSD[11]和MALL[12]數據集的相關內容。
1.1 生成密度圖-處理參數
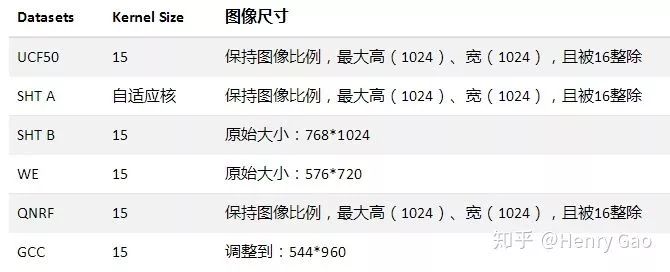
注:
1. 為了能夠使得輸入圖像兼容更多的網絡,預處理時對圖像的高和寬進行了限制,使其能夠被16整除。確保網絡中一些含有降采樣操作的層(conv with stride2 或者池化)能夠正確輸出。在人群計數領域中,常見encoder中一般輸出為1/8原圖尺寸,因此被16整除完全滿足需求。
2. 為節約顯存,對QNRF和GCC的圖像進行了保持長寬比的降采樣操作。
1.2 多Batch-size訓練
由于UCF50、SHT A、QNRF所包含的圖像尺寸不一,為了實現多batch size的訓練,我們重寫了collate_fn函數。該函數在隨機拿到N張圖像和GT后,選擇最小的高h_min和最小的寬w_min對所有圖像進行crop,拼成
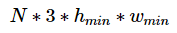
的Tensor送入到網絡中進行訓練。
根據經驗,如果是from scratch training,對于這幾個數據集建議采用多batch size訓練或者采用GCC-SFCN中加padding的方案;對于有預訓練參數的模型(AlexNet,VGG,ResNet等),建議采用單一batch size進行訓練。
1.3 Label Transform
代碼中我們提供了兩種對密度圖進行transform的操作。一種參考了CSRNet源碼[6]中對密度圖進行降采樣的操作(GTScaleDown),一種是對密度圖點乘一個放大因子(LabelNormalize)。
1.3.1 GTScaleDown
由于CSRNet中,網絡回歸的密度圖為原圖的1/8,因此作者對密度圖進行了降采樣,并點乘64以保證密度圖之和依然約等于總人數。該操作會帶來一個問題:會影響PSNR和SSIM的值。因此我們不建議使用該操作。在我們實現其他網絡過程中,也會出現網絡輸出為1/4,1/8等尺寸,為避免該問題,在網絡內部增加上采樣層實現與原圖大小的密度圖。
1.3.2 LabelNormalize
這算是一個訓練的trick,我們通過實驗發現,對于密度圖乘以一個較大的放大因子,可以使網絡更快的收斂,甚至取得更低的估計誤差。有關這一點的更進一步分析、實驗結果,移步實驗部分。
2. 模型
這一部分,我們介紹幾種常見分類網絡(AlexNet,VGG,ResNet等)“魔改”為人群計數的網絡。
2.1 Baseline模型
2.1.1 AlexNet
對于AlexNet網絡[7],我們小幅修改了conv1和conv2層的padding,以保證其對于feature map的大小能夠正常整除。同時,截取conv5之前的網絡,作為人群計數的encoder,其大小為原始輸入的1/16。decoder的設計依然遵循簡約的原則,用“兩層卷積+上采樣”直接回歸到1-channel的密度圖。
2.1.2 VGG系列:VGG和VGG+decoder
對于VGG網絡[8]的兩個變體,我們完全采用了VGG-16模型的前10個卷積層。其中,VGG采用了最為簡單的decoder,而VGG+decoder則是簡單設計了一個含有三個反卷積的模塊。下表展示了二者在SHT上的實驗結果。
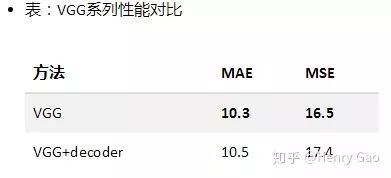

通過在SHT B上實驗結果來看,兩者的模型性能(MAE,MSE)差不多,但VGG+decoder有著更為精細的密度圖。二者的性能非常接近CSRNet(同樣的backbone)的結果。
2.1.3 ResNet系列:Res50和Res101
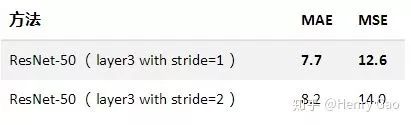
對于ResNet[9],為了保證密度圖的大小不至于過小(不小于原圖尺寸的1/8),我們修改了res.layer3中第一層stride的大小(將原本的2改為1),以此當做encoder。本著簡單的原則,decoder由兩層卷積構成。
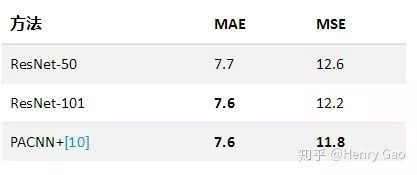
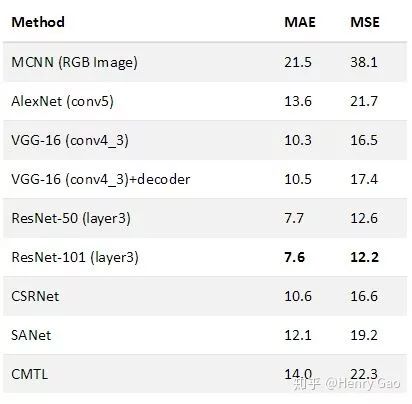
從實驗結果來看,ResNet展現除了強大的特征提取能力,在SHT B上直接達到了現有SOTA的水平。據我們所知,截止目前(2019.4),已發表/錄用文章中最好的是PACNN+[10],其MAE/MSE為:7.6/11.8。我們的模型在SHT B數據集上具體表現如下:
2.2 C3F框架下復現模型比較
除了上述基于ImageNet分類模型設計的Baselines以外,我們也嘗試在C3F下復現了以下幾個主流算法的結果,包括MCNN[2],CMTL[13],CSRNet[6]以及SANet[14]。我們復現的模型在SHT B數據集上具體表現如下:
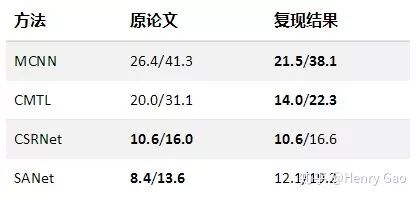
注:
1. 在MCNN復現過程中,與原網絡結構唯一不同在于,我們的MCNN處理的是RGB圖像。
2. 原始的CMTL在訓練前,通過隨機裁剪生成好了訓練集。我們采用在線裁剪的方法可以使訓練覆蓋更多的裁剪區域。此外,由于選擇了在線裁剪,CMTL中的分類任務的標簽頁適應性地改成了在線計算與分配。
3. 據我們所知,SANet復現結果,是當前所有復現中最接近論文結果的,雖然這一結果與論文結果依然相差甚遠。
3. 訓練技巧
3.1 LabelNormalize的調參
在C3F已公布的實驗結果中,均對密度圖進行了點乘100的操作。實驗過程中,我們也發現,設置一個合適的放大因子,對于網絡的有效訓練非常有益。這一節,我們簡要說一下為什么這樣一個簡單的操作會有效的原因。一個初始化好的計數網絡來說,自身參數符合一定的分布,如果目標分布和初始化分布相差過大的話,網絡會陷入一個比較差的局部解,難以訓練出好的結果。該特性在使用預訓練分類模型的計數網絡時,顯得更為重要。
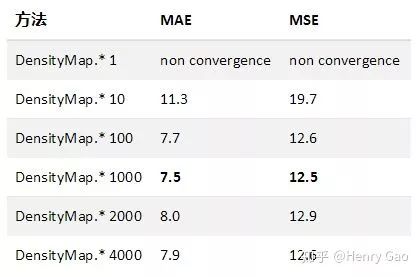
這一節,我們選擇Res50網絡,分別測試在對密度圖分別乘以[1,10,100,1000,2000,4000]時,網絡的計數性能差異。下表展示了不同放大因子下在SHT B上的實驗結果。我們發現,當采用原始密度圖時,網絡并不能正確收斂。觀察結果發現,網絡一直輸出一張全0的密度圖。陷入到一個局部解無法進一步優化。當放大因子為1000時,網絡達到了最優性能。之后,隨著放大因子的增加,網絡的計數性能又逐步降低。
(注:實驗中,其他參數均與results_reports/Res50/SHHB中的設置保持一致。)
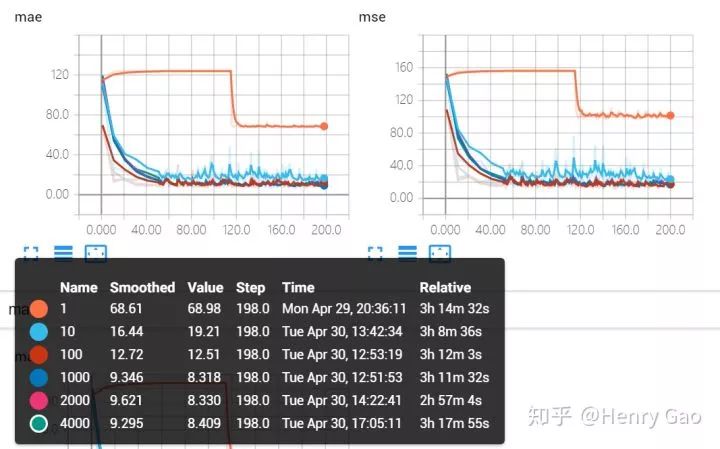
下圖展示了在六組不同的放大因子下,MAE和MSE在驗證集上隨時間的變化曲線。橙色曲線表示對密度圖不進行放大情況下,網絡性能的表現。我們發現,網絡陷入到一個局部解難以跳出。
不同放大因子的實驗對比
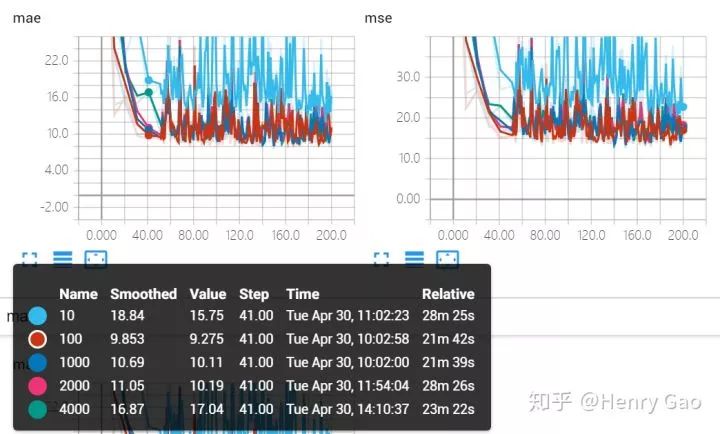
由于橙色曲線會干擾我們對其他參數曲線的對比,因此,下圖展示了移除掉橙色曲線后,即放大因子為[10,100,1000,2000,4000]的曲線對比。從圖中可以看出,除了放大因子取10時,效果較差,其他幾種曲線重合度非常高。
不同放大因子的實驗對比
綜上,我們設定一個較大的放大因子,不僅可以促使模型快速收斂,也可以幫助模型取得一個更優的性能。
3.2 特征圖大小對比:1/8 size v.s 1/16 size
過小的特征圖尺寸會對計數的性能產生非常大的影響。這里,我們進行兩組對比試驗:1) ResNet-50中res.layer3以前的層原封不動當做backbone,最終輸出密度圖作16x的上采樣;2) C3F最終采用的方案,輸出密度圖作8x的上采樣。
從實驗結果可以看出,在將stride改為1后,模型輸出了分辨率更高的密度圖,同時在計數誤差上取得了更好的效果。同時,我們也對比一下兩者在訓練過程中,測試集上MAE和MSE的表現,如下圖所示。其中藍色部分為stride=2的結果,橙色為stride=1的結果。能夠很直觀的看出,平滑后的曲線圖,橙色曲線整體要低于藍色曲線。(注:實驗中,其他參數均與results_reports/Res50/SHHB中的設置保持一致。)
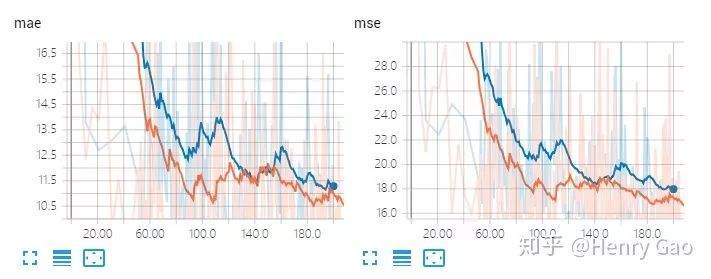
不同特征圖大小的實驗對比
3.3 數據歸一化中,均值和標準差對實驗結果的影響
C3F中,在misc中我們提供了cal_mean.py來計算數據集中的訓練數據中均值和標準差。大多數人會使用ImageNet的均值和標準差(也就是mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),經過實測,該參數對最終的性能影響有限。我們繼續使用Res50和MCNN網絡進行試驗,用兩種均值、標準差進行歸一化,比較最終的計數誤差,結果見下表。(注:Res50實驗中,其他參數均與results_reports/Res50/SHHB中的設置保持一致。MCNN實驗則是與results_reports/MCNN/SHHB中的設置保持一致)
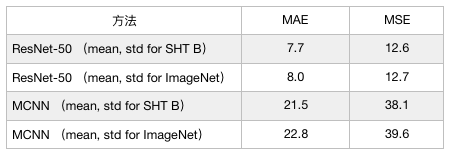
從表格中,我們可以看出,使用了自身數據集的均值和標準差,性能要略微優于使用ImageNet上的均值和標準差所得到的的結果。下圖展示了訓練過程中驗證集上MAE和MSE的變化曲線,其中橙色代表采用了SHT B的均值和標準差的實驗,藍色則為采用了ImageNet的結果。從圖中可以看出,二者的重合度非常高。
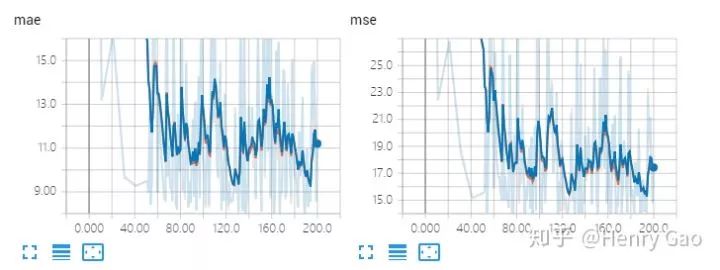
Res50:不同均值標準差的實驗對比
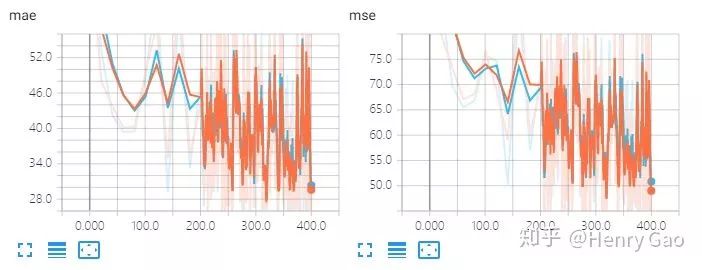
MCNN:不同均值標準差的實驗對比
由于人群圖像和ImageNet數據均屬于自然圖像,計算出的均值和標準差也比較類似。因此,改值對實驗結果的影響并不是很大。當然,影響程度也與數據集有關,如果數據具有很強的偏置,最好還是采用數據對應的均值和標準差。總的來說,我們還是建議使用訓練數據的均值和標準差,以取得更好的計數性能。
4. 實驗結果
本節,我們將復現的所有算法在SHT B上的性能展示出來,方便大家做最終的對比。我們發現,得益于ResNet-101強大的學習能力,以其為Backbone的人群計數器在MAE和MSE指標上超越了其他所有算法。此外,我們還發現,對于有預訓練參數的網絡,甚至可以不需要對網絡進行過多的設計,例如Dilated Conv、Multi-column Conv、Scale Aggregation等,就可以達到一個較好的結果。
5. 總結展望
本項目旨在提供一個簡單、高效、易用、靈活的人群計數框架,方便新手快速上手入門、資深研究者高效實現idea以及最大化模型性能。本技術報告則是對該項目的一個簡單介紹,使大家能夠對我們的項目有一個更深的理解,這樣用起來也會更加順手,最大化框架的使用度。
同時,我們英文Technical Report(為本文的精簡內容)也將在arxiv上預印。如果大家有任何問題、建議,歡迎大家在倉庫中提issue和PR,讓C3F變得更好!
6. 致謝
在整個項目推進的過程中,得到了很多人的大力支持。特別地,感謝@wwwzxoe303com對關鍵代碼的檢查和測試,感謝@PetitBai對項目Readme.md的校對,感謝Google Colab提供免費實驗資源。此外,我們的部分代碼、設計邏輯參考或直接借用了以下作者的倉庫/項目/代碼,在此一并表示感謝!正是有了以下幾個出色的開源代碼,我們才得以完成C3F項目。
rbgirshick/py-faster-rcnn
zijundeng/pytorch-semantic-segmentation
leeyeehoo/CSRNet-pytorch
BIGKnight/SANet_implementation
gjy3035/enet.pytorch
gjy3035/GCC-SFCN
gjy3035/PCC-Net(論文尚未發表,因此暫未公開源碼)
7. Q&A
Q1:能否提供Python3環境下的代碼?A:會,但現在時機不成熟。原因是Tensorboard暫時還不支持Python3.7,加之人手不足,暫無開發計劃。
Q2:為什么在SHT B上做實驗?以后會不會對其他數據集進行驗證?A:因為圖像尺寸相同,便于多batch-size的訓練和測試,能夠最大化利用顯卡,節省顯卡資源和訓練時間。對于其他數據集,由于自己的時間有限,也沒有足夠的顯卡資源,暫時不會做其他數據集實驗。
Q3:語義分割和人群計數非常類似,能不能直接用一些分割網絡呢?A:二者同屬于逐像素任務,前者為逐像素分類,后者為逐像素回歸。根據我的實驗,某些分割網絡直接修改最后一層為回歸層后,其效果與backbone相比,提升非常有限。甚至性能會有所下降。深層問題暫時還沒有仔細思考。不過據我所知,有人對此問題已經做了研究,大家耐心等待即可。
Q4:正確的訓練、驗證、測試流程應該是怎樣的?A:嚴格意義上,所有數據集應該都包含以上三種數據(如果沒有驗證集,則應該從訓練集中隨機選擇一部分)。在本項目中,為了能夠確保所有實驗結果可以復現,我們直接將測試集當做驗證集來監控訓練過程。
Q5:部分模型會在PyTorch1.0下報上采樣函數F.upsample的警告信息。A:該警告不影響訓練。為了兼容0.4版本,我們依然采用F.upsample方法來對Tensor進行放大尺寸的操作。
-
圖像
+關注
關注
2文章
1089瀏覽量
40598 -
數據處理
+關注
關注
0文章
617瀏覽量
28665 -
數據集
+關注
關注
4文章
1210瀏覽量
24854
原文標題:C3F—開源人群計數工具箱:快速上手、模型驗證、流程處理,你值得擁有
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
讓代碼助你理解I2C總線
如何提高代碼理解能力?
基于stm32f4的看門狗配置和實驗代碼
關于HAL庫代碼stm32f1xx_hal_uart.c代碼分析,不看肯定后悔
S3C2410內存管理單元MMU基礎實驗
CodeViz--一款分析C/C++源代碼中函數調用關系的調用
KLOCWORK INSIGHT:C#源代碼分析

一文助你全面理解機器學習
基于STM32F103C8 輸入捕獲實驗






 工商網監
工商網監
評論