") 實踐經(jīng)驗:在深度學(xué)習(xí)中喂飽GPU
實踐經(jīng)驗:在深度學(xué)習(xí)中喂飽GPU
深度學(xué)習(xí)模型訓(xùn)練是不是大力出奇跡,顯卡越多越好?非也,沒有512張顯卡,也可以通過一些小技巧優(yōu)化模型訓(xùn)練。本文作者分析了他的實踐經(jīng)驗。
前段時間訓(xùn)練了不少模型,發(fā)現(xiàn)并不是大力出奇跡,顯卡越多越好,有時候 1 張 v100 和 2 張 v100 可能沒有什么區(qū)別,后來發(fā)現(xiàn)瓶頸在其他地方,寫篇文章來總結(jié)一下自己用過的一些小 trick,最后的效果就是在 cifar 上面跑 vgg 的時間從一天縮到了一個小時,imagenet 上跑 mobilenet 模型只需要 2 分鐘每個 epoch。(文章末尾有代碼啦)
先說下跑 cifar 的時候,如果只是用 torchvision 的 dataloader (用最常見的 padding/crop/flip 做數(shù)據(jù)增強) 會很慢,大概速度是下面這種,600 個 epoch 差不多要一天多才能跑完,并且速度時快時慢很不穩(wěn)定。
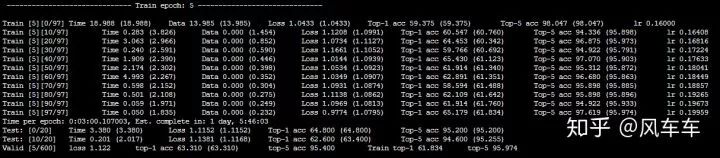
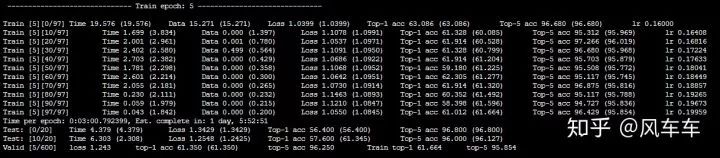
我最初以為是 IO 的原因,于是掛載了一塊內(nèi)存盤,改了一下路徑接著用 torchvision 的 dataloader 來跑,速度基本沒啥變化。。。
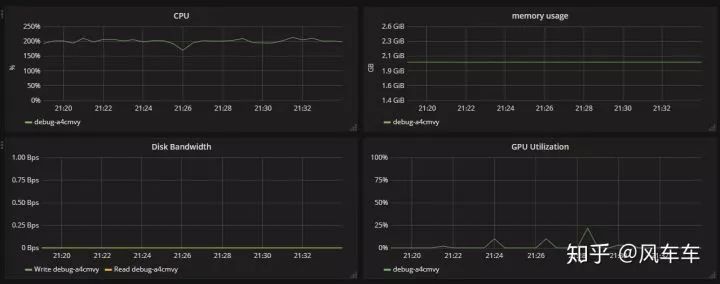
然后打開資源使用率看了下發(fā)現(xiàn) cpu 使用率幾乎已經(jīng)滿了(只能申請 2cpu 和一張 v100...),但是 gpu 的使用率非常低,這基本可以確定瓶頸是在 cpu 的處理速度上了。
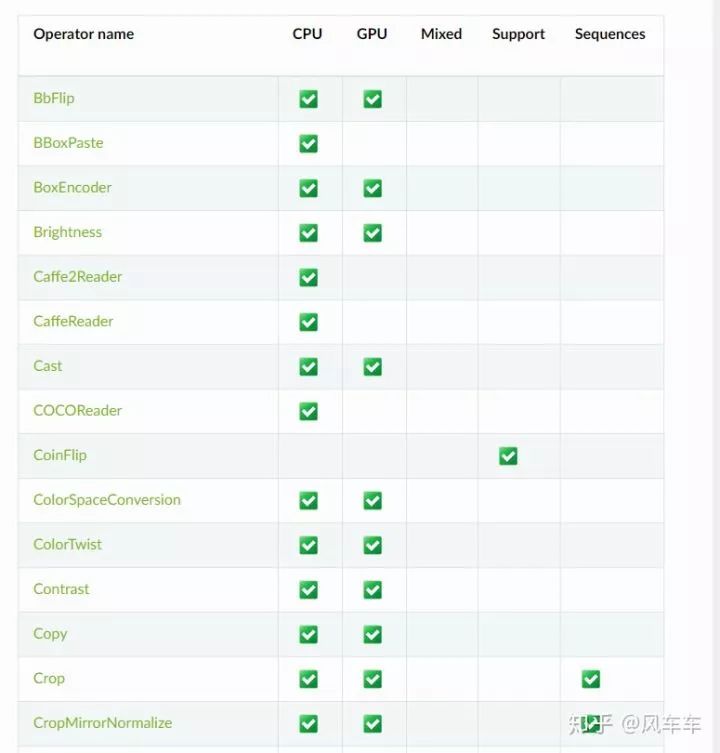
后來查了一些資料發(fā)現(xiàn) nvidia 有一個庫叫 dali 可以用 gpu 來做圖像的前處理,從輸入,解碼到 transform 的一整套 pipeline,看了下常見的操作比如 pad/crop 之類的還挺全的,并且支持 pytorch/caffe/mxnet 等各種框架。
可惜在官方文檔中沒找到 cifar 的 pipeline,于是自己照著 imagenet 的版本寫了個,最初踩了一些坑(為了省事找了個 cifar 的 jpeg 版本來解碼,發(fā)現(xiàn)精度掉得很多還找不到原因,還得從 cifar 的二進制文件來讀取),最后總歸是達到了同樣的精度,再來看一看速度和資源使用率,總時間直接從一天縮短為一小時,并且 gpu 使用率高了很多。
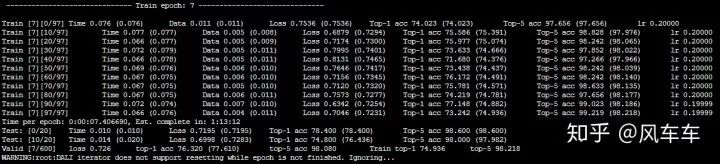
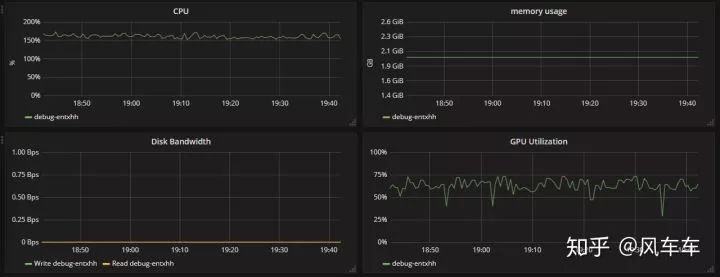
再說下 imagenet 的訓(xùn)練加速,最初也是把整個數(shù)據(jù)集拷到了掛載的內(nèi)存盤里面(160g 大概夠用了,從拷貝到解壓完成大概 10 分鐘不到),發(fā)現(xiàn)同樣用 torchvision 的 dataloader 訓(xùn)練很不穩(wěn)定,于是直接照搬了 dali 官方的 dataloader 過來,速度也是同樣起飛 hhhh(找不到當(dāng)時訓(xùn)練的圖片了),然后再配合 apex 的混合精度和分布式訓(xùn)練,申請 4 塊 v100,gpu 使用率可以穩(wěn)定在 95 以上,8 塊 v100 可以穩(wěn)定在 90 以上,最后直接上到 16 張 v100 和 32cpu,大概也能穩(wěn)定在 85 左右(看資源使用率發(fā)現(xiàn) cpu 到頂了,不然估計 gpu 也能到 95 以上),16 塊 v100 在 ImageNet 上跑 mobilenet 只需要 2 分鐘每個 epoch。
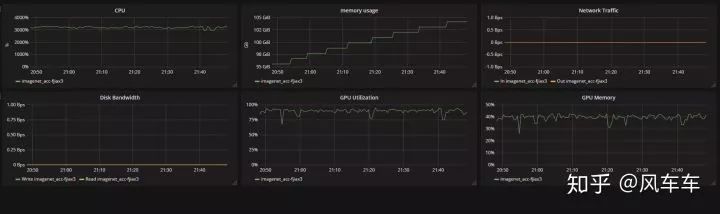
寫的 dataloader 放到了 github 上,我測試的精度跟 torchvision 的版本差不多,不過速度上會比 torchvision 快很多,后面有空也會寫一些其他常用 dataloader 的 dali 版本放上去。
-
gpu
+關(guān)注
關(guān)注
28文章
4794瀏覽量
129491 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1210瀏覽量
24861 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5521瀏覽量
121649
原文標(biāo)題:在深度學(xué)習(xí)中喂飽GPU
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
深度學(xué)習(xí)工作負載中GPU與LPU的主要差異

GPU在深度學(xué)習(xí)中的應(yīng)用 GPUs在圖形設(shè)計中的作用
NPU在深度學(xué)習(xí)中的應(yīng)用
pcie在深度學(xué)習(xí)中的應(yīng)用
AI干貨補給站 | 深度學(xué)習(xí)與機器視覺的融合探索

深度學(xué)習(xí)GPU加速效果如何
FPGA做深度學(xué)習(xí)能走多遠?
深度學(xué)習(xí)中的無監(jiān)督學(xué)習(xí)方法綜述
深度學(xué)習(xí)在視覺檢測中的應(yīng)用
深度學(xué)習(xí)在自動駕駛中的關(guān)鍵技術(shù)
新手小白怎么學(xué)GPU云服務(wù)器跑深度學(xué)習(xí)?
什么是RAG,RAG學(xué)習(xí)和實踐經(jīng)驗





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論