") 如何利用Tensorflow編寫一個(gè)基本的端到端自動(dòng)語(yǔ)音識(shí)別
如何利用Tensorflow編寫一個(gè)基本的端到端自動(dòng)語(yǔ)音識(shí)別
本文闡述了如何利用Tensorflow編寫一個(gè)基本的端到端自動(dòng)語(yǔ)音識(shí)別(Automatic Speech Recognition,ASR)系統(tǒng),詳細(xì)介紹了最小神經(jīng)網(wǎng)絡(luò)的各個(gè)組成部分以及可將音頻轉(zhuǎn)為可讀文本的前綴束搜索解碼器。
雖然當(dāng)下關(guān)于如何搭建基礎(chǔ)機(jī)器學(xué)習(xí)系統(tǒng)的文獻(xiàn)或資料有很多,但是大部分都是圍繞計(jì)算機(jī)視覺和自然語(yǔ)言處理展開的,極少有文章就語(yǔ)音識(shí)別展開介紹。本文旨在填補(bǔ)這一空缺,幫助初學(xué)者降低入門難度,提高學(xué)習(xí)自信。
前提
初學(xué)者需要熟練掌握:
· 如何訓(xùn)練神經(jīng)網(wǎng)絡(luò)
· 如何利用語(yǔ)言模型求得詞序的概率
概述
· 音頻預(yù)處理:將原始音頻轉(zhuǎn)換為可用作神經(jīng)網(wǎng)絡(luò)輸入的數(shù)據(jù)
· 神經(jīng)網(wǎng)絡(luò):搭建一個(gè)簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò),用于將音頻特征轉(zhuǎn)換為文本中可能出現(xiàn)的字符的概率分布
· CTC損失:計(jì)算不使用相應(yīng)字符標(biāo)注音頻時(shí)間步長(zhǎng)的損失
· 解碼:利用前綴束搜索和語(yǔ)言模型,根據(jù)各個(gè)時(shí)間步長(zhǎng)的概率分布生成文本
本文重點(diǎn)講解了神經(jīng)網(wǎng)絡(luò)、CTC損失和解碼。
音頻預(yù)處理
搭建語(yǔ)音識(shí)別系統(tǒng),首先需要將音頻轉(zhuǎn)換為特征矩陣,并輸入到神經(jīng)網(wǎng)絡(luò)中。完成這一步的簡(jiǎn)單方法就是創(chuàng)建頻譜圖。
def create_spectrogram(signals):
stfts = tf.signal.stft(signals, fft_length=256)
spectrograms = tf.math.pow(tf.abs(stfts), 0.5)
return spectrograms
這一方法會(huì)計(jì)算出音頻信號(hào)的短時(shí)傅里葉變換(Short-time Fourier Transform)以及功率譜,其最終輸出可直接用作神經(jīng)網(wǎng)絡(luò)輸入的頻譜圖矩陣。其他方法包括濾波器組和MFCC(Mel頻率倒譜系數(shù))等。
了解更多音頻預(yù)處理知識(shí):https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
神經(jīng)網(wǎng)絡(luò)
下圖展現(xiàn)了一個(gè)簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
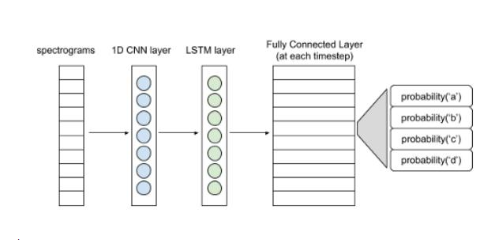
語(yǔ)音識(shí)別基本結(jié)構(gòu)
頻譜圖輸入可以看作是每個(gè)時(shí)間步長(zhǎng)的向量。1D卷積層從各個(gè)向量中提取出特征,形成特征向量序列,并輸入LSTM層進(jìn)一步處理。LSTM層(或雙LSTM層)的輸入則傳遞至全連接層。利用softmax激活函數(shù),可得出每個(gè)時(shí)間步長(zhǎng)的字符概率分布。整個(gè)網(wǎng)絡(luò)將會(huì)用CTC損失函數(shù)進(jìn)行訓(xùn)練(CTC即Connectionist Temporal Classification,是一種時(shí)序分類算法)。熟悉整個(gè)建模流程后可嘗試使用更復(fù)雜的模型。
class ASR(tf.keras.Model):
def __init__(self, filters, kernel_size, conv_stride, conv_border, n_lstm_units, n_dense_units):
super(ASR, self).__init__()
self.conv_layer = tf.keras.layers.Conv1D(filters,
kernel_size,
strides=conv_stride,
padding=conv_border,
activation=‘relu’)
self.lstm_layer = tf.keras.layers.LSTM(n_lstm_units,
return_sequences=True,
activation=‘tanh’)
self.lstm_layer_back = tf.keras.layers.LSTM(n_lstm_units,
return_sequences=True,
go_backwards=True,
activation=‘tanh’)
self.blstm_layer = tf.keras.layers.Bidirectional(self.lstm_layer, backward_layer=self.lstm_layer_back)
self.dense_layer = tf.keras.layers.Dense(n_dense_units)
def call(self, x):
x = self.conv_layer(x)
x = self.blstm_layer(x)
x = self.dense_layer(x)
return x
為什么使用CTC呢?搭建神經(jīng)網(wǎng)絡(luò)旨在預(yù)測(cè)每個(gè)時(shí)間步長(zhǎng)的字符。然而現(xiàn)有的標(biāo)簽并不是各個(gè)時(shí)間步長(zhǎng)的字符,僅僅是音頻的轉(zhuǎn)換文本。而文本的各個(gè)字符可能橫跨多個(gè)步長(zhǎng)。如果對(duì)音頻的各個(gè)時(shí)間步長(zhǎng)進(jìn)行標(biāo)記,C-A-T就會(huì)變成C-C-C-A-A-T-T。而每隔一段時(shí)間,如10毫秒,對(duì)音頻數(shù)據(jù)集進(jìn)行標(biāo)注,并不是一個(gè)切實(shí)可行的方法。CTC則解決上了上述問題。CTC并不需要標(biāo)記每個(gè)時(shí)間步長(zhǎng)。它忽略了文本中每個(gè)字符的位置和實(shí)際相位差,把神經(jīng)網(wǎng)絡(luò)的整個(gè)概率矩陣輸入和相應(yīng)的文本作為輸入。
CTC 損失計(jì)算
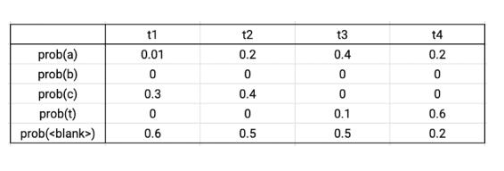
輸出矩陣示例
假設(shè)真實(shí)的數(shù)據(jù)標(biāo)簽為CAT,在四個(gè)時(shí)間步長(zhǎng)中,有序列C-C-A-T,C-A-A-T,C-A-T-T,_-C-A-T,C-A-T-_與真實(shí)數(shù)據(jù)相對(duì)應(yīng)。將這些序列的概率相加,可得到真實(shí)數(shù)據(jù)的概率。根據(jù)輸出的概率矩陣,將序列的各個(gè)字符的概率相乘,可得到單個(gè)序列的概率。則上述序列的總概率為0.0288+0.0144+0.0036+0.0576+0.0012=0.1056。CTC損失則為該概率的負(fù)對(duì)數(shù)。Tensorflow自帶損失函數(shù)文件。
解碼
由上文的神經(jīng)網(wǎng)絡(luò),可輸出一個(gè)CTC矩陣。這一矩陣給出了各個(gè)時(shí)間步長(zhǎng)中每個(gè)字符在其字符集中的概率。利用前綴束搜索,可從CTC矩陣中得出所需的文本。
除了字母和空格符,CTC矩陣的字符集還包括兩種特別的標(biāo)記(token,也稱為令牌)——空白標(biāo)記和字符串結(jié)束標(biāo)記。
空白標(biāo)記的作用:CTC矩陣中的時(shí)間步長(zhǎng)通常比較小,如10毫秒。因此,句子中的一個(gè)字符會(huì)橫跨多個(gè)時(shí)間步長(zhǎng)。如,C-A-T會(huì)變成C-C-C-A-A-T-T。所以,需要將CTC矩陣中出現(xiàn)該問題的字符串中的重復(fù)部分折疊,消除重復(fù)。那么像FUNNY這種本來就有兩個(gè)重復(fù)字符(N)的詞要怎么辦呢?在這種情況下,就可以使用空白標(biāo)記,將其插入兩個(gè)N中間,就可以防止N被折疊。而這么做實(shí)際上并沒有在文本中添加任何東西,也就不會(huì)影響其內(nèi)容或形式。因此,F(xiàn)-F-U-N-[空白]-N-N-Y最終會(huì)變成FUNNY。
結(jié)束標(biāo)記的作用:字符串的結(jié)束表示著一句話的結(jié)束。對(duì)字符串結(jié)束標(biāo)記后的時(shí)間步長(zhǎng)進(jìn)行解碼不會(huì)給候選字符串增加任何內(nèi)容。
步驟
初始化
· 準(zhǔn)備一個(gè)初始列表。列表包括多個(gè)候選字符串,一個(gè)空白字符串,以及各個(gè)字符串在不同時(shí)間步長(zhǎng)以空白標(biāo)記結(jié)束的概率,和以非空白標(biāo)記結(jié)束的概率。在時(shí)刻0,空白字符串以空白標(biāo)記結(jié)束的概率為1,以非空白標(biāo)記結(jié)束的概率則為0。
迭代
· 選擇一個(gè)候選字符串,將字符一個(gè)一個(gè)添加進(jìn)去。計(jì)算拓展后的字符串在時(shí)刻1以空白標(biāo)記和非空白標(biāo)記結(jié)束的概率。將拓展字符串及其概率記錄到列表中。將拓展字符串作為新的候選字符串,在下一時(shí)刻重復(fù)上述步驟。
· 情況A:如果添加的字符是空白標(biāo)記,則保持候選字符串不變。
· 情況B:如果添加的字符是空格符,則根據(jù)語(yǔ)言模型將概率與和候選字符串的概率成比例的數(shù)字相乘。這一步可以防止錯(cuò)誤拼寫變成最佳候選字符串。如,避免COOL被拼成KUL輸出。
· 情況C:如果添加的字符和候選字符串的最后一個(gè)字符相同,(以候選字符串FUN和字符N為例),則生成兩個(gè)新的候選字符串,F(xiàn)UNN和FUN。生成FUN的概率取決于FUN以空白標(biāo)記結(jié)束的概率。生成FUNN的概率則取決于FUN以非空白標(biāo)記結(jié)束的概率。因此,如果FUN以非空白標(biāo)記結(jié)束,則去除額外的字符N。
輸出
經(jīng)過所有時(shí)間步長(zhǎng)迭代得出的最佳候選字符串就是輸出。
為了加快這一過程,可作出如下兩個(gè)修改。
1.在每一個(gè)時(shí)間步長(zhǎng),去除其他字符串,僅留下最佳的K個(gè)候選字符串。具體操作為:根據(jù)字符串以空白和非空白標(biāo)記結(jié)束的概率之和,對(duì)候選字符串進(jìn)行分類。
2.去除矩陣中概率之和低于某個(gè)閾值(如0.001)的字符。
具體操作細(xì)節(jié)可參考如下代碼。
def prefix_beam_search(ctc,
alphabet,
blank_token,
end_token,
space_token,
lm,
k=25,
alpha=0.30,
beta=5,
prune=0.001):
‘’‘
function to perform prefix beam search on output ctc matrix and return the best string
:param ctc: output matrix
:param alphabet: list of strings in the order their probabilties are present in ctc output
:param blank_token: string representing blank token
:param end_token: string representing end token
:param space_token: string representing space token
:param lm: function to calculate language model probability of given string
:param k: threshold for selecting the k best prefixes at each timestep
:param alpha: language model weight (b/w 0 and 1)
:param beta: language model compensation (should be proportional to alpha)
:param prune: threshold on the output matrix probability of a character.
If the probability of a character is less than this threshold, we do not extend the prefix with it
:return: best string
’‘’
zero_pad = np.zeros((ctc.shape[0]+1,ctc.shape[1]))
zero_pad[1:,:] = ctc
ctc = zero_pad
total_timesteps = ctc.shape[0]
# #### Initialization ####
null_token = ‘’
Pb, Pnb = Cache(), Cache()
Pb.add(0,null_token,1)
Pnb.add(0,null_token,0)
prefix_list = [null_token]
# #### Iterations ####
for timestep in range(1, total_timesteps):
pruned_alphabet = [alphabet[i] for i in np.where(ctc[timestep] 》 prune)[0]]
for prefix in prefix_list:
if len(prefix) 》 0 and prefix[-1] == end_token:
Pb.add(timestep,prefix,Pb.get(timestep - 1,prefix))
Pnb.add(timestep,prefix,Pnb.get(timestep - 1,prefix))
continue
for character in pruned_alphabet:
character_index = alphabet.index(character)
# #### Iterations : Case A ####
if character == blank_token:
value = Pb.get(timestep,prefix) + ctc[timestep][character_index] * (Pb.get(timestep - 1,prefix) + Pnb.get(timestep - 1,prefix))
Pb.add(timestep,prefix,value)
else:
prefix_extended = prefix + character
# #### Iterations : Case C ####
if len(prefix) 》 0 and character == prefix[-1]:
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * Pb.get(timestep-1,prefix)
Pnb.add(timestep,prefix_extended,value)
value = Pnb.get(timestep,prefix) + ctc[timestep][character_index] * Pnb.get(timestep-1,prefix)
Pnb.add(timestep,prefix,value)
# #### Iterations : Case B ####
elif len(prefix.replace(space_token, ‘’)) 》 0 and character in (space_token, end_token):
lm_prob = lm(prefix_extended.strip(space_token + end_token)) ** alpha
value = Pnb.get(timestep,prefix_extended) + lm_prob * ctc[timestep][character_index] * (Pb.get(timestep-1,prefix) + Pnb.get(timestep-1,prefix))
Pnb.add(timestep,prefix_extended,value)
else:
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * (Pb.get(timestep-1,prefix) + Pnb.get(timestep-1,prefix))
Pnb.add(timestep,prefix_extended,value)
if prefix_extended not in prefix_list:
value = Pb.get(timestep,prefix_extended) + ctc[timestep][-1] * (Pb.get(timestep-1,prefix_extended) + Pnb.get(timestep-1,prefix_extended))
Pb.add(timestep,prefix_extended,value)
value = Pnb.get(timestep,prefix_extended) + ctc[timestep][character_index] * Pnb.get(timestep-1,prefix_extended)
Pnb.add(timestep,prefix_extended,value)
prefix_list = get_k_most_probable_prefixes(Pb,Pnb,timestep,k,beta)
# #### Output ####
return prefix_list[0].strip(end_token)
這樣,一個(gè)基礎(chǔ)的語(yǔ)音識(shí)別系統(tǒng)就完成了。對(duì)上述步驟進(jìn)行復(fù)雜化,可以得到更優(yōu)的結(jié)果,如,搭建更大的神經(jīng)網(wǎng)絡(luò)和利用音頻預(yù)處理技巧。
完整代碼:https://github.com/apoorvnandan/speech-recognition-primer
注意事項(xiàng):
1. 文中代碼使用的是TensorFlow2.0系統(tǒng),舉例使用的音頻文件選自LibriSpeech數(shù)據(jù)庫(kù)(http://www.openslr.org/12)。
2. 文中代碼并不包括訓(xùn)練音頻數(shù)據(jù)集的批量處理生成器。讀者需要自己編寫。
3. 讀者亦需自己編寫解碼部分的語(yǔ)言模型函數(shù)。最簡(jiǎn)單的方法就是基于語(yǔ)料庫(kù)生成一部二元語(yǔ)法字典并計(jì)算字符概率。
-
語(yǔ)音識(shí)別
+關(guān)注
關(guān)注
39文章
1774瀏覽量
114023 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8497瀏覽量
134231 -
tensorflow
+關(guān)注
關(guān)注
13文章
330瀏覽量
61071
發(fā)布評(píng)論請(qǐng)先 登錄
一文帶你厘清自動(dòng)駕駛端到端架構(gòu)差異
自動(dòng)駕駛中基于規(guī)則的決策和端到端大模型有何區(qū)別?
小米汽車端到端智駕技術(shù)介紹

端到端自動(dòng)駕駛技術(shù)研究與分析
端到端在自動(dòng)泊車的應(yīng)用
階躍星辰發(fā)布國(guó)內(nèi)首個(gè)千億參數(shù)端到端語(yǔ)音大模型
準(zhǔn)確性超Moshi和GLM-4-Voice,端到端語(yǔ)音雙工模型Freeze-Omni

爆火的端到端如何加速智駕落地?
連接視覺語(yǔ)言大模型與端到端自動(dòng)駕駛

Waymo利用谷歌Gemini大模型,研發(fā)端到端自動(dòng)駕駛系統(tǒng)
Mobileye端到端自動(dòng)駕駛解決方案的深度解析

端到端測(cè)試用例怎么寫
實(shí)現(xiàn)自動(dòng)駕駛,唯有端到端?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論