") 語音識別技術(shù)的原理及研究難點(diǎn)
語音識別技術(shù)的原理及研究難點(diǎn)

在我們的生活中,語言是傳遞信息最重要的方式,它能夠讓人們之間互相了解。人和機(jī)器之間的交互也是相同的道理,讓機(jī)器人知道人類要做什么、怎么做。交互的方式有動作、文本或語音等等,其中語音交互越來越被重視,因?yàn)殡S著互聯(lián)網(wǎng)上智能硬件的普及,產(chǎn)生了各種互聯(lián)網(wǎng)的入口方式,而語音是最簡單、最直接的交互方式,是最通用的輸入模式。
在1952年,貝爾研究所研制了世界上第一個(gè)能識別10個(gè)英文數(shù)字發(fā)音的系統(tǒng)。1960年英國的Denes等人研制了世界上第一個(gè)語音識別(ASR)系統(tǒng)。大規(guī)模的語音識別研究始于70年代,并在單個(gè)詞的識別方面取得了實(shí)質(zhì)性的進(jìn)展。上世紀(jì)80年代以后,語音識別研究的重點(diǎn)逐漸轉(zhuǎn)向更通用的大詞匯量、非特定人的連續(xù)語音識別。
90年代以來,語音識別的研究一直沒有太大進(jìn)步。但是,在語音識別技術(shù)的應(yīng)用及產(chǎn)品化方面取得了較大的進(jìn)展。自2009年以來,得益于深度學(xué)習(xí)研究的突破以及大量語音數(shù)據(jù)的積累,語音識別技術(shù)得到了突飛猛進(jìn)的發(fā)展。
深度學(xué)習(xí)研究使用預(yù)訓(xùn)練的多層神經(jīng)網(wǎng)絡(luò),提高了聲學(xué)模型的準(zhǔn)確率。微軟的研究人員率先取得了突破性進(jìn)展,他們使用深層神經(jīng)網(wǎng)絡(luò)模型后,語音識別錯(cuò)誤率降低了三分之一,成為近20年來語音識別技術(shù)方面最快的進(jìn)步。
另外,隨著手機(jī)等移動終端的普及,多個(gè)渠道積累了大量的文本語料或語音語料,這為模型訓(xùn)練提供了基礎(chǔ),使得構(gòu)建通用的大規(guī)模語言模型和聲學(xué)模型成為可能。在語音識別中,豐富的樣本數(shù)據(jù)是推動系統(tǒng)性能快速提升的重要前提,但是語料的標(biāo)注需要長期的積累和沉淀,大規(guī)模語料資源的積累需要被提高到戰(zhàn)略高度。
今天,語音識別在移動端和音箱的應(yīng)用上最為火熱,語音聊天機(jī)器人、語音助手等軟件層出不窮。許多人初次接觸語音識別可能歸功于蘋果手機(jī)的語音助手Siri。
Siri技術(shù)來源于美國國防部高級研究規(guī)劃局(DARPA)的CALO計(jì)劃:初衷是一個(gè)讓軍方簡化處理繁重復(fù)雜的事務(wù),并具備認(rèn)知能力進(jìn)行學(xué)習(xí)、組織的數(shù)字助理,其民用版即為Siri虛擬個(gè)人助理。
Siri公司成立于2007年,最初是以文字聊天服務(wù)為主,之后與大名鼎鼎的語音識別廠商N(yùn)uance合作實(shí)現(xiàn)了語音識別功能。2010年,Siri被蘋果收購。2011年蘋果將該技術(shù)隨同iPhone 4S發(fā)布,之后對Siri的功能仍在不斷提升完善。現(xiàn)在,Siri成為蘋果iPhone上的一項(xiàng)語音控制功能,可以讓手機(jī)變身為一臺智能化機(jī)器人。通過自然語言的語音輸入,可以調(diào)用各種APP,如天氣預(yù)報(bào)、地圖導(dǎo)航、資料檢索等,還能夠通過不斷學(xué)習(xí)改善性能,提供對話式的應(yīng)答服務(wù)。
語音識別(ASR)原理
語音識別技術(shù)是讓機(jī)器通過識別把語音信號轉(zhuǎn)變?yōu)槲谋荆M(jìn)而通過理解轉(zhuǎn)變?yōu)橹噶畹募夹g(shù)。目的就是給機(jī)器賦予人的聽覺特性,聽懂人說什么,并作出相應(yīng)的行為。語音識別系統(tǒng)通常由聲學(xué)識別模型和語言理解模型兩部分組成,分別對應(yīng)語音到音節(jié)和音節(jié)到字的計(jì)算。一個(gè)連續(xù)語音識別系統(tǒng)(如下圖)大致包含了四個(gè)主要部分:特征提取、聲學(xué)模型、語言模型和解碼器等。

(1)語音輸入的預(yù)處理模塊
對輸入的原始語音信號進(jìn)行處理,濾除掉其中的不重要信息以及背景噪聲,并進(jìn)行語音信號的端點(diǎn)檢測(也就是找出語音信號的始末)、語音分幀(可以近似理解為,一段語音就像是一段視頻,由許多幀的有序畫面構(gòu)成,可以將語音信號切割為單個(gè)的“畫面”進(jìn)行分析)等處理。
(2)特征提取
在去除語音信號中對于語音識別無用的冗余信息后,保留能夠反映語音本質(zhì)特征的信息進(jìn)行處理,并用一定的形式表示出來。也就是提取出反映語音信號特征的關(guān)鍵特征參數(shù)形成特征矢量序列,以便用于后續(xù)處理。
(3)聲學(xué)模型訓(xùn)練
聲學(xué)模型可以理解為是對聲音的建模,能夠把語音輸入轉(zhuǎn)換成聲學(xué)表示的輸出,準(zhǔn)確的說,是給出語音屬于某個(gè)聲學(xué)符號的概率。根據(jù)訓(xùn)練語音庫的特征參數(shù)訓(xùn)練出聲學(xué)模型參數(shù)。在識別時(shí)可以將待識別的語音的特征參數(shù)與聲學(xué)模型進(jìn)行匹配,得到識別結(jié)果。目前的主流語音識別系統(tǒng)多采用隱馬爾可夫模型HMM進(jìn)行聲學(xué)模型建模。
(4)語言模型訓(xùn)練
語言模型是用來計(jì)算一個(gè)句子出現(xiàn)概率的模型,簡單地說,就是計(jì)算一個(gè)句子在語法上是否正確的概率。因?yàn)榫渥拥臉?gòu)造往往是規(guī)律的,前面出現(xiàn)的詞經(jīng)常預(yù)示了后方可能出現(xiàn)的詞語。它主要用于決定哪個(gè)詞序列的可能性更大,或者在出現(xiàn)了幾個(gè)詞的時(shí)候預(yù)測下一個(gè)即將出現(xiàn)的詞語。它定義了哪些詞能跟在上一個(gè)已經(jīng)識別的詞的后面(匹配是一個(gè)順序的處理過程),這樣就可以為匹配過程排除一些不可能的單詞。
語言建模能夠有效的結(jié)合漢語語法和語義的知識,描述詞之間的內(nèi)在關(guān)系,從而提高識別率,減少搜索范圍。對訓(xùn)練文本數(shù)據(jù)庫進(jìn)行語法、語義分析,經(jīng)過基于統(tǒng)計(jì)模型訓(xùn)練得到語言模型。
(5)語音解碼和搜索算法
解碼器是指語音技術(shù)中的識別過程。針對輸入的語音信號,根據(jù)己經(jīng)訓(xùn)練好的HMM聲學(xué)模型、語言模型及字典建立一個(gè)識別網(wǎng)絡(luò),根據(jù)搜索算法在該網(wǎng)絡(luò)中尋找最佳的一條路徑,這個(gè)路徑就是能夠以最大概率輸出該語音信號的詞串,這樣就確定這個(gè)語音樣本所包含的文字了。所以,解碼操作即指搜索算法,即在解碼端通過搜索技術(shù)尋找最優(yōu)詞串的方法。
連續(xù)語音識別中的搜索,就是尋找一個(gè)詞模型序列以描述輸入語音信號,從而得到詞解碼序列。搜索所依據(jù)的是對公式中的聲學(xué)模型打分和語言模型打分。在實(shí)際使用中,往往要依據(jù)經(jīng)驗(yàn)給語言模型加上一個(gè)高權(quán)重,并設(shè)置一個(gè)長詞懲罰分?jǐn)?shù)。
語音識別本質(zhì)上是一種模式識別的過程,未知語音的模式與已知語音的參考模式逐一進(jìn)行比較,最佳匹配的參考模式被作為識別結(jié)果。當(dāng)今語音識別技術(shù)的主流算法,主要有基于動態(tài)時(shí)間規(guī)整(DTW)算法、基于非參數(shù)模型的矢量量化(VQ)方法、基于參數(shù)模型的隱馬爾可夫模型(HMM)的方法、以及近年來基于深度學(xué)習(xí)和支持向量機(jī)等語音識別方法。
站在巨人的肩膀上:開源框架
目前開源世界里提供了多種不同的語音識別工具包,為開發(fā)者構(gòu)建應(yīng)用提供了很大幫助。但這些工具各有優(yōu)劣,需要根據(jù)具體情況選擇使用。下表為目前相對流行的工具包間的對比,大多基于傳統(tǒng)的 HMM 和N-Gram 語言模型的開源工具包。

對于普通用戶而言,大多數(shù)人都會知道 Siri 或 Cortana 這樣的產(chǎn)品。而對于研發(fā)工程師來說,更靈活、更具專注性的解決方案更符合需求,很多公司都會研發(fā)自己的語音識別工具。
(1)CMU Sphinix是卡內(nèi)基梅隆大學(xué)的研究成果。已有 20 年歷史了,在 Github和 SourceForge上都已經(jīng)開源了,而且兩個(gè)平臺上都有較高的活躍度。
(2)Kaldi 從 2009 年的研討會起就有它的學(xué)術(shù)根基了,現(xiàn)在已經(jīng)在 GitHub上開源,開發(fā)活躍度較高。
(3)HTK 始于劍橋大學(xué),已經(jīng)商用較長時(shí)間,但是現(xiàn)在版權(quán)已經(jīng)不再開源軟件了。它的最新版本更新于 2015 年 12 月。
(4)Julius起源于 1997 年,最后一個(gè)主版本發(fā)布于2016 年 9 月,主要支持的是日語。
(5)ISIP 是第一個(gè)最新型的開源語音識別系統(tǒng),源于密西西比州立大學(xué)。它主要發(fā)展于 1996 到 1999 年間,最后版本發(fā)布于 2011 年,遺憾的是,這個(gè)項(xiàng)目已經(jīng)不復(fù)存在。
語音識別技術(shù)研究難點(diǎn)
目前,語音識別研究工作進(jìn)展緩慢,困難具體表現(xiàn)在:
(1)輸入無法標(biāo)準(zhǔn)統(tǒng)一
比如,各地方言的差異,每個(gè)人獨(dú)有的發(fā)音習(xí)慣等,如下圖所示,口腔中元音隨著舌頭部位的不同可以發(fā)出多種音調(diào),如果組合變化多端的輔音,可以產(chǎn)生大量的、相似的發(fā)音,這對語音識別提出了挑戰(zhàn)。除去口音參差不齊,輸入設(shè)備不統(tǒng)一也導(dǎo)致了語音輸入的不標(biāo)準(zhǔn)。
(2)噪聲的困擾
噪聲環(huán)境的各類聲源處理是目前公認(rèn)的技術(shù)難題,機(jī)器無法從各層次的背景噪音中分辨出人聲,而且,背景噪聲千差萬別,訓(xùn)練的情況也不能完全匹配真實(shí)環(huán)境。因而,語音識別在噪聲中比在安靜的環(huán)境下要難得多。
目前主流的技術(shù)思路是,通過算法提升降低誤差。首先,在收集的原始語音中,提取抗噪性較高的語音特征。然后,在模型訓(xùn)練的時(shí)候,結(jié)合噪聲處理算法訓(xùn)練語音模型,使模型在噪聲環(huán)境里的魯棒性較高。最后,在語音解碼的過程中進(jìn)行多重選擇,從而提高語音識別在噪聲環(huán)境中的準(zhǔn)確率。完全消除噪聲的干擾,目前而言,還停留在理論層面。
(3)模型的有效性
識別系統(tǒng)中的語言模型、詞法模型在大詞匯量、連續(xù)語音識別中還不能完全正確的發(fā)揮作用,需要有效地結(jié)合語言學(xué)、心理學(xué)及生理學(xué)等其他學(xué)科的知識。并且,語音識別系統(tǒng)從實(shí)驗(yàn)室演示系統(tǒng)向商品的轉(zhuǎn)化過程中還有許多具體細(xì)節(jié)技術(shù)問題需要解決。
智能語音識別系統(tǒng)研發(fā)方向
今天,許多用戶已經(jīng)能享受到語音識別技術(shù)帶來的方便,比如智能手機(jī)的語音操作等。但是,這與實(shí)現(xiàn)真正的人機(jī)交流還有相當(dāng)遙遠(yuǎn)的距離。目前,計(jì)算機(jī)對用戶語音的識別程度不高,人機(jī)交互上還存在一定的問題,智能語音識別系統(tǒng)技術(shù)還有很長的一段路要走,必須取得突破性的進(jìn)展,才能做到更好的商業(yè)應(yīng)用,這也是未來語音識別技術(shù)的發(fā)展方向。
在語音識別的商業(yè)化落地中,需要內(nèi)容、算法等各個(gè)方面的協(xié)同支撐,但是良好的用戶體驗(yàn)是商業(yè)應(yīng)用的第一要素,而識別算法是提升用戶體驗(yàn)的核心因素。目前語音識別在智能家居、智能車載、智能客服機(jī)器人方面有廣泛的應(yīng)用,未來將會深入到學(xué)習(xí)、生活、工作的各個(gè)環(huán)節(jié)。許多科幻片中的場景正在逐步走入我們的平常生活。
責(zé)任編輯:wv
-
語音識別
+關(guān)注
關(guān)注
39文章
1779瀏覽量
114192
發(fā)布評論請先 登錄
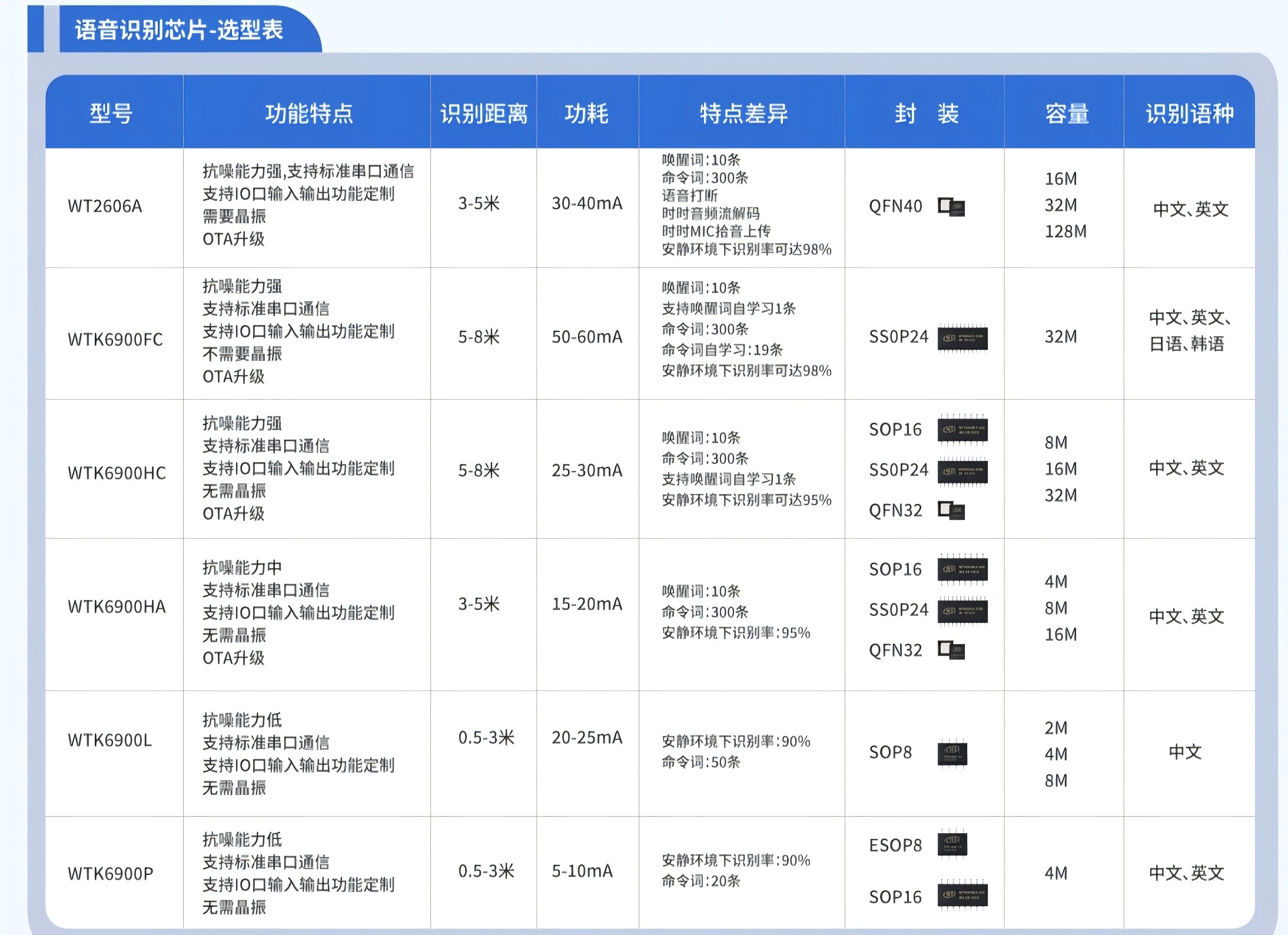
語音識別芯片選型有哪些技術(shù)參數(shù)要注意
普強(qiáng)信息入選2024語音識別技術(shù)公司TOP30榜單
廠家芯資訊|廣州唯創(chuàng)電子語音識別芯片技術(shù)解析

語音識別技術(shù)在通信領(lǐng)域中的應(yīng)用實(shí)例
詳解語音識別技術(shù)在通信領(lǐng)域中的應(yīng)用

基于語音識別的智能會議系統(tǒng)具備哪些交互功能
NRK3502系列芯片 | 制氧機(jī)離線語音識別方案

語音識別技術(shù)在醫(yī)療領(lǐng)域的應(yīng)用
語音識別與自然語言處理的關(guān)系
語音識別技術(shù)的應(yīng)用與發(fā)展
ASR與傳統(tǒng)語音識別的區(qū)別
ASR語音識別技術(shù)應(yīng)用







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論