 低功耗計算機視覺的四類推理方法的介紹和優缺點
低功耗計算機視覺的四類推理方法的介紹和優缺點

深度學習在廣泛應用于目標檢測、分類等計算機視覺任務中。但這些應用往往需要很大的計算量和能耗。例如處理一張圖片分類,VGG-16需要做 150億次計算,而YOLOv3需要執行390億次計算。
這就帶來一個問題,如何在低功耗的嵌入式系統或移動設備中部署深度學習呢?一種解決辦法是將計算任務轉移到云側,但這并不能最終解決問題,因為許多深度學習應用程序需要在端側進行計算,例如部署在無人機(通常會在斷網情況下工作)或衛星上的應用。
從2016年起,業界便開始探索模型加速和小型化的研究,也提出了大量小型化方案。這些技術可以消除 DNNs 中的冗余,可將計算量減少75%以上,推理時間減少50%以上,而同時能夠保證精度無損。但要想大規模地在端側部署DNNs模型,仍然還需要繼續優化。
欲砥礪前行,還需要看下當前情況下低功耗計算機視覺的研究進展如何。普渡大學的Abhinav Goel 等人近日針對這一領域的研究進展做了值得參照的綜述。
在這篇文章中,Goel等人將低功耗推理方法分為四類,分別為:
1、參數量化和剪枝:通過減少用于存儲DNN模型參數的比特數來降低內存和計算成本。
2、壓縮卷積濾波器和矩陣分解:將大的DNN層分解成更小的層,以減少內存需求和冗余矩陣運算的數量。
3、網絡架構搜索:自動構建具有不同層次組合的DNN,從而找到期望性能的DNN架構。
4、知識遷移與蒸餾:訓練一個緊湊的DNN,來模仿一個計算量更大的DNN的輸出、特征和激活。
這四種方法的介紹和優缺點如下圖總結:
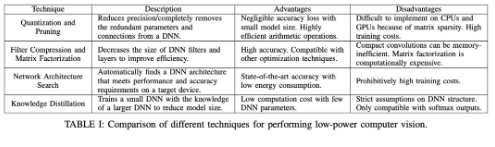
Goel等人的這篇綜述除了對這些方法進行優缺點總結外,更提出了一些可能的改進措施,同事還提出了一套評估指標以便指導未來的研究。
一、參數量化和剪枝
內存訪問對DNNs的能量消耗有重要影響。為了構建低功耗的DNNs,一個策略便是在性能和內存訪問次數之間進行權衡。針對這一策略,目前有兩種方法,一種是進行參數量化,即降低DNN參數的大小;另一種則是剪枝,從DNNs中刪除不重要的參數和連接。
1、參數量化
有研究表明(Courbariaux et. al.)以不同位寬定點格式存儲的參數進行訓練,歲參數位寬減小,盡管測試誤差有些微的增大(這種誤差的變化幾乎可以忽略不計),但能耗卻能夠大幅降低。如下圖所示:
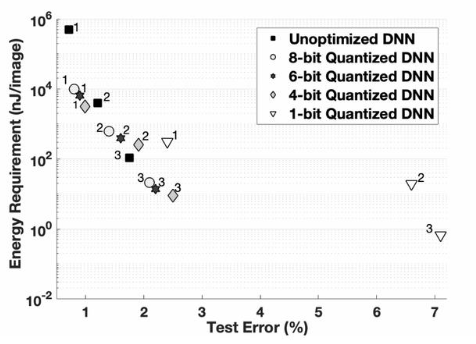
基于這種奠定性的研究,于是出現大量工作(例如LightNN、CompactNet、FLightNN等),它們在給定精度約束的情況下,嘗試為DNN的參數尋找最佳位寬。甚至Courbariaux、Rastegari等人提出了二值化的神經網絡。
為了進一步降低DNNs的內存需求,目前常采用的是參數量化和模型壓縮結合的方法。例如Han等人首先將參數量化到離散的bin中,然后使用Huffman編碼來壓縮這些bin,從而使模型大小減少89%,而精度卻基本不受影響。類似的,HashedNet會將DNN的連接量化到散列 bucket 中,這樣散列到同一個bucket的連接就會共享同一個參數。不過這種方法需要很高的訓練成本,因此它們的應用是有局限的。
優點:當參數的位寬減小時,DNNs的性能基本保持不變。這主要是因為約束參數在訓練過程中具有正則化的效果。
缺點及改進方向:1)使用量化技術的DNNs,往往需要進行多次再訓練,這使得訓練耗能非常大,因此如何降低訓練成本是這種技術必須要考慮的;2)DNNs中不同層對特征的敏感性是不同的,如果所有層的位寬都一樣,就會導致性能變差,因此如何為每個連接層選擇不同精度的參數是提升性能的關鍵一步,這可以在訓練過程中進行學習。
2、剪枝
從DNNs中刪除不重要的參數和連接可以減少內存訪問次數。
Hessian加權變形測量法(Hessian-weighted distortion measure)可以對DNN中參數的重要性進行評估,從而來去掉那些冗余參數,減小DNN模型大小,但這種基于測量的剪枝方法僅適用于全連接層。
為了將剪枝擴展到卷積層,許多學者各顯神通。Anwar等人提出了粒子濾波的方法;Polyak等人將樣本輸入數據,并剪掉哪些稀疏激活的連接;Han等人使用一種新的損失函數來學習DNN中的參數和連接;Yu等人使用一種傳播重要性分數的算法來測量每個參數相對于輸出的重要性。
也有人試圖將剪枝、量化和壓縮同時應用到模型當中,將模型大小減小了95%。

圖示:不同DNN的模型壓縮率。其中P: Pruning, Q: Quantization, C: Compression.
優點:如上表所示,剪枝可以和量化、編碼相結合,從而能夠獲得更加顯著的性能收益。例如當三者一同使用時,VGG-16的大小能夠降低到原來大小的2%。此外,剪枝能夠減少DNN模型的復雜性,從而減少了過度擬合的情況。
缺點及改進方向:同樣,剪枝也會帶來訓練時間的增加。如上表,同時使用剪枝和量化,訓練時間增加了600%;如果使用稀疏約束對DNN進行剪枝時,這個問題會更加嚴重。此外,剪枝的優點,只有當使用自定義硬件或用于稀疏矩陣的特殊數據結構時才會顯現出來。因此相比于現在的連接剪枝技術,Channel級的剪枝可能是一個改進方向,因為它不需要任何特殊的數據結構,也不會產生矩陣稀疏。
二、壓縮卷積濾波器和矩陣分解
在DNNs中卷積操作占了很大一部分,以AlexNet為例,其中的全連接層占了近89%的參數。因此若想降低DNNs的功耗,應當減少卷積層的計算量和全連接層的參數量。這也有兩個技術方向,分別為:1)采用更小的卷積濾波器;2)將矩陣分解為參數量更小的矩陣。
1、壓縮卷積濾波器
與較大的濾波器相比,較小的卷積濾波器具有更少的參數,計算成本也較低。
但如果將所有大的卷積層都替換掉,會影響DNN的平移不變形,這將降低DNN模型的精度。因此有人嘗試去識別那些冗余的濾波器,并用較小的濾波器將它們替換掉。SqueezeNet正是這樣一種技術,它使用了三種策略來將 3×3 的卷積轉換成 1 × 1 卷積。

如上圖所示,相比于AlexNet,SqueezeNet減少了98%的參數(當然操作數稍微變多了一些),而性能卻并沒有受到影響。
MobileNets 在瓶頸層(bottleneck layers )使用深度可分離卷積,來減少計算、延遲和參數量。在使用深度可分離卷積(epthwise separable convolutions)時,通過保持較小的特征尺寸,并只擴展到較大的特征空間,從而實現了較高的精度。
優點:瓶頸卷積濾波器大大降低了DNNs的內存和延遲需求。對于大多數計算機視覺任務,這些方法能夠獲得SOTA性能。濾波壓縮與剪枝和量化技術正交(互不影響),因此這三種技術可以一起使用,從而進一步降低能耗。
缺點及改進方向:已經證明 1×1卷積在小型DNN中計算開銷很大,導致精度較差,這主要是因為運算強度太低,無法有效利用硬件。通過對內存的有效管理,可以提高深度可分離卷積的運算強度;通過優化緩存中參數的空間和時間局域性,可以減少內存訪問次數。
2、矩陣分解
通過將張量或矩陣分解為合積形式(sum-product form),將多維張量分解為更小的矩陣,從而可以消除冗余計算。一些因子分解方法可以將DNN模型加速4 倍以上,因為它們能夠將矩陣分解為更密集的參數矩陣,且能夠避免非結構化稀疏乘法的局部性問題。
為了最小化精度損失,可以按層進行矩陣分解:首先對一層的參數進行因子分解,然后根據重構誤差對后續的層再進行因子分解。但逐層優化的方法使得難以將這些方法應用到大型的DNN模型中,因為分解超參的數量會隨著模型深度成指數增長。Wen等人使用了緊湊的核形狀和深度結構來減少因子分解超參的數量。
關于矩陣分解,有多種技術。Kolda等人證明,大多數因子分解技術都可以用來做DNN模型的加速,但這些技術在精度和計算復雜度之間不一定能夠取得最佳的平衡。例如,CPD(典型聚并分解)和BMD(批量歸一化分解)在精度上能夠做的非常好,但Tucker-2分解和奇異值分解的精度就不怎么樣。CPD在壓縮上要比BMD好,但CPD相關的優化問題有時卻并不可解,這就會導致沒法分解,而BMD的因子分解卻始終存在。
優點:矩陣分解可以降低DNN的計算成本,無論在卷積層還是全連接層都可以使用相同的因子分解。
缺點及改進方向:由于缺乏理論解釋,因此很難解釋為什么一些分解(例如CPD、BMD)能夠獲得較高的精度,而其他分解卻不能;另外,與矩陣分解相關的計算常常與模型獲得的性能增益相當,造成收益與損耗抵消。此外,矩陣分解很難在大型DNN模型中實現,因為隨著深度增加分解超參會呈指數增長,訓練時間主要耗費在尋找正確的分解超參;事實上,超參不需要從整個空間中進行搜索,因此可以在訓練時學習如何找到更優的搜索空間,從而來加速對大型DNN模型的訓練。
三、網絡架構搜索
在設計低功耗計算機視覺程序時,針對不同的任務可能需要不同的DNN模型架構。但由于存在許多這種結構上的可能性,通過手工去設計一個最佳DNN模型往往是困難的。最好的辦法就是將這個過程自動化,即網絡架構搜索技術(Network Architecture Search)。
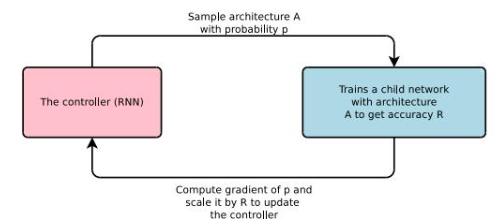
NAS使用一個遞歸神經網絡(RNN)作為控制器,并使用增強學習來構建候選的DNN架構。對這些候選DNN架構進行訓練,然后使用驗證集進行測試,測試結果作為獎勵函數,用于優化控制器的下一個候選架構。
NASNet 和AmoebaNet 證明了NAS的有效性,它們通過架構搜索獲得DNN模型能夠獲得SOTA性能。
為了獲得針對移動設備有效的DNN模型,Tan等人提出了MNasNet,這個模型在控制器中使用了一個多目標獎勵函數。在實驗中,MNasNet 要比NASNet快2.3倍,參數減少4.8倍,操作減少10倍。此外,MNasNet也比NASNet更準確。
不過,盡管NAS方法的效果顯著,但大多數NAS算法的計算量都非常大。例如,MNasNet需要50,000個GPU 時才能在ImageNet數據集上找到一個高效的DNN架構。
為了減少與NAS相關的計算成本,一些研究人員建議基于代理任務和獎勵來搜索候選架構。例如在上面的例子中,我們不選用ImageNet,而用更小的數據集CIFAR-10。FBNet正是這樣來處理的,其速度是MNasNet的420倍。
但Cai等人表明,在代理任務上優化的DNN架構并不能保證在目標任務上是最優的,為了克服基于代理的NAS解決方案所帶來的局限性,他們提出了Proxyless-NAS,這種方法會使用路徑級剪枝來減少候選架構的數量,并使用基于梯度的方法來處理延遲等目標。他們在300個GPU時內便找到了一個有效的架構。此外,一種稱為單路徑NAS(Single-Path NAS)的方法可以將架構搜索時間壓縮到 4 個GPU時內,不過這種加速是以降低精度為代價的。
優點:NAS通過在所有可能的架構空間中進行搜索,而不需要任何人工干預,自動平衡準確性、內存和延遲之間的權衡。NAS能夠在許多移動設備上實現準確性、能耗的最佳性能。
缺點及改進方向:計算量太大,導致很難去搜索大型數據集上任務的架構。另外,要想找到滿足性能需求的架構,必須對每個候選架構進行訓練,并在目標設備上運行來生成獎勵函數,這會導致較高的計算成本。其實,可以將候選DNN在數據的不同子集上進行并行訓練,從而減少訓練時間;從不同數據子集得到的梯度可以合并成一個經過訓練的DNN。不過這種并行訓練方法可能會導致較低的準確性。另一方面,在保持高收斂率的同時,利用自適應學習率可以提高準確性。
四、知識遷移和蒸餾
大模型比小模型更準確,因為參數越多,允許學習的函數就可以越復雜。那么能否用小的模型也學習到這樣復雜的函數呢?
一種方式便是知識遷移(Knowledge Transfer),通過將大的DNN模型獲得的知識遷移到小的DNN模型上。為了學習復雜函數,小的DNN模型會在大的DNN模型標記處的數據上進行訓練。其背后的思想是,大的DNN標記的數據會包含大量對小的DNN有用的信息。例如大的DNN模型對一個輸入圖像在一些類標簽上輸出中高概率,那么這可能意味著這些類共享一些共同的視覺特征;對于小的DNN模型,如果去模擬這些概率,相比于直接從數據中學習,要能夠學到更多。
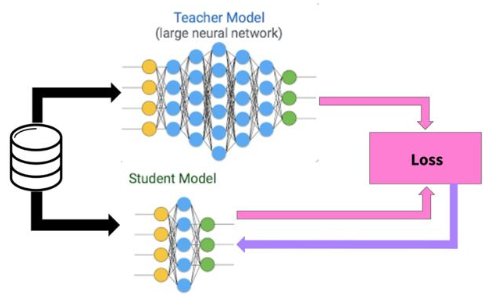
另一種技術是Hinton老爺子在2014年提出的知識蒸餾(Knowledge Distillation),這種方法的訓練過程相比于知識遷移要簡單得多。在知識蒸餾中,小的DNN模型使用學生-教師模式進行訓練,其中小的DNN模型是學生,一組專門的DNN模型是教師;通過訓練學生,讓它模仿教師的輸出,小的DNN模型可以完成整體的任務。但在Hinton的工作中,小的DNN模型的準確度卻相應有些下降。Li等人利用最小化教師與學生之間特征向量的歐氏距離,進一步提高的小的DNN模型的精度。類似的,FitNet讓學生模型中的每一層都來模仿教師的特征圖。但以上兩種方法都要求對學生模型的結構做出嚴格的假設,其泛化性較差。為了解決這一問題,Peng等人使用了指標間的相關性作為優化問題。
優點:基于知識遷移和知識蒸餾的技術可以顯著降低大型預訓練模型的計算成本。有研究表明,知識蒸餾的方法不僅可以在計算機視覺中應用,還能用到許多例如半監督學習、域自適應等任務中。
缺點及改進方向:知識蒸餾通常對學生和教師的結構和規模有嚴格的假設,因此很難推廣到所有的應用中。此外目前的知識蒸餾技術嚴重依賴于softmax輸出,不能與不同的輸出層協同工作。作為改進方向,學生可以學習教師模型的神經元激活序列,而不是僅僅模仿教師的神經元/層輸出,這能夠消除對學生和教師結構的限制(提高泛化能力),并減少對softmax輸出層的依賴。
五、討論
事實上,沒有任何一種技術能夠構建出最有效的DNN模型,以上提到的大多數技術是互補的,可以同時來使用,從而降低能耗、減小模型,并提高精度。基于對上述內容的分析,作者在文章最后提煉出5個結論:
1)量化和降低參數精度可以顯著降低模型的大小和算術運算的復雜度,但大多數機器學習庫很難手工實現量化。英偉達的TensorRT庫為這種優化提供了一個接口。
2)在優化大型預訓練DNN時,剪枝和模型壓縮是有效的選擇。
3)當從零開始訓練一個新的DNN模型時,應該使用壓縮卷積濾波器和矩陣分解來減少模型的大小和計算量。
4)NAS可以用來尋找針對單個設備的最優DNN模型。具有多個分支的DNN(如Proxyless-NAS, MNasNet等)常需要昂貴的內核啟動以及 GPU、CPU同步。
5)知識蒸餾能夠應用到中小型數據集,因為這對學生和教師的DNN架構要求的假設較少,能夠有更高的準確性。
責任編輯:gt
-
嵌入式
+關注
關注
5152文章
19678瀏覽量
317800 -
計算機
+關注
關注
19文章
7667瀏覽量
90868 -
低功耗
+關注
關注
11文章
2810瀏覽量
104967
發布評論請先 登錄
大模型推理顯存和計算量估計方法研究
英飛凌邊緣AI平臺通過Ultralytics YOLO模型增加對計算機視覺的支持
AR和VR中的計算機視覺

工業中使用哪種計算機?

量子計算機與普通計算機工作原理的區別
不同類型adc的優缺點分析
工業計算機類型介紹

【小白入門必看】一文讀懂深度學習計算機視覺技術及學習路線

計算機接口位于什么之間
內存控制器有哪些優缺點
晶體管計算機和電子管計算機有什么區別
計算機視覺有哪些優缺點
計算機視覺中的圖像融合





 工商網監
工商網監
評論