") 深度學(xué)習(xí)基本概念總結(jié)
深度學(xué)習(xí)基本概念總結(jié)

卷積神經(jīng)網(wǎng)絡(luò)(CNN) 具有局部互聯(lián)、權(quán)值共享、下采樣(池化)和使用多個(gè)卷積層的特點(diǎn)。
局部互聯(lián) 是指每個(gè)神經(jīng)元只感受局部的圖像區(qū)域,也就是卷積操作。
權(quán)值共享 是指當(dāng)前層所有特征圖共用一個(gè)卷積核,每個(gè)卷積核提取一種特征,參數(shù)量明顯下降;使用多個(gè)卷積核可以提取多種特征。
下采樣 每次對輸入的特征圖錯(cuò)開一行或一列,能夠壓縮特征圖大小,特征降維,提取主要特征,將語義相似的特征融合,對平移形變不敏感,提高模型泛化能力。
使用多個(gè)卷積層 能夠提取更深層次的特征,組合特征實(shí)現(xiàn)從低級到高級、局部到整體的特征提取。
卷積層 任務(wù)是檢測前一層的局部特征,即用來進(jìn)行特征提取,用不同的卷積核卷積得到不同的特征,通過多層卷積實(shí)現(xiàn)特征的組合,完成從低級到高級、局部與整體的特征提取。例如,圖像先提取邊緣特征,組合成形狀特征,再得到更高級的特征;語音和文本具有相似特征,從聲音到語音,再到音素、音節(jié)、單詞、句子。
下采樣(池化)層 對輸入的特征圖錯(cuò)開行或列,壓縮特征圖大小,降低參數(shù)量和計(jì)算復(fù)雜度,也對特征進(jìn)行了壓縮,提取主要特征,將語義相似的特征融合起來,對微小的平移和形變不敏感。包括平均池化和最大池化和隨機(jī)池化,平均池化領(lǐng)域內(nèi)方差小,更多的保留圖像的背景信息,最大池化領(lǐng)域內(nèi)均值偏移大,更多的保留圖像的紋理信息,隨機(jī)池化(Stochastic Pooling)則介于兩者之間。
全連接層 將二維空間轉(zhuǎn)化成一維向量,將全連接層的輸出送入分類器或回歸器來做分類和回歸。
在卷積神經(jīng)網(wǎng)絡(luò)中,前面的卷積層的參數(shù)少但計(jì)算量大,后面的全連接層則相反,因此加速優(yōu)化重心放在前面的卷積層,參數(shù)調(diào)優(yōu)的重心放在后面的全連接層。
全卷積網(wǎng)絡(luò) 將一般的卷積神經(jīng)網(wǎng)絡(luò)的全連接層替換成1x1的卷積層,使得網(wǎng)絡(luò)可以接受任意大小的輸入圖像,網(wǎng)絡(luò)輸出的是一張?zhí)卣鲌D,特征圖上的每個(gè)點(diǎn)對應(yīng)其輸入圖像上的感受野區(qū)域。
多個(gè)3x3卷積比7x7卷積的優(yōu)點(diǎn)在于,參數(shù)量減少并且非線性表達(dá)能力增強(qiáng);1x1卷積的作用在于,可以用于特征降維與升維,各通道特征融合,以及全卷積網(wǎng)絡(luò)(支持任意輸入圖像大小)。
深度神經(jīng)網(wǎng)絡(luò)具有從低級到高級、局部到整體的特征表達(dá)和學(xué)習(xí)能力,相比于淺層網(wǎng)絡(luò)能更簡潔緊湊的提取特征,但訓(xùn)練時(shí)容易發(fā)生過擬合、梯度彌散和局部極值的問題。
過擬合(Overfitting) 一般發(fā)生在數(shù)據(jù)量較少而模型參數(shù)較多時(shí),其表現(xiàn)是模型在訓(xùn)練時(shí)變現(xiàn)的很好(error和loss很低)、但在測試時(shí)較差(error和loss較大),使得模型的泛化能力不行。歸根結(jié)底是數(shù)據(jù)量不夠多不夠好,最好的辦法是通過增加數(shù)據(jù)量(更多更全的數(shù)據(jù)、數(shù)據(jù)增廣、數(shù)據(jù)清洗),還可以通過使用dropout、BN、正則化等來防止過擬合,訓(xùn)練時(shí)的trick是適當(dāng)增加訓(xùn)練時(shí)的batchsize、適當(dāng)降低學(xué)習(xí)率。
梯度彌散(Gradient Vanish) 是指在靠近輸出層的隱層訓(xùn)練的好,但在靠近輸入層的隱層幾乎無法訓(xùn)練,是多層使用sigmoid激活函數(shù)所致(sigmoid函數(shù)在接近1的部分梯度下降的太快),用ReLu激活函數(shù)可以緩解這個(gè)問題。
局部極值 是指在訓(xùn)練深度網(wǎng)絡(luò)時(shí)求解一個(gè)高度非凸的優(yōu)化問題如最小化訓(xùn)練誤差loss可能會(huì)得到壞的局部極值而非全局極值。采用梯度下降法也可能存在這種問題。
Dropout 是在訓(xùn)練時(shí)隨機(jī)拋棄隱層中的部分神經(jīng)元,在某次訓(xùn)練時(shí)不更新權(quán)值,防止過擬合(過擬合發(fā)生在模型參數(shù)遠(yuǎn)大于數(shù)據(jù)量時(shí),而dropout變相的減少了模型參數(shù)),提高泛化能力,在全連接層使用。感覺是模仿了生物神經(jīng)系統(tǒng)。Dropout使得隨機(jī)拋棄的神經(jīng)元既不參加前向計(jì)算,也不需要反向傳播。
歸一化(Normalization) 用于加速收斂,提高模型精度,包括LRN(Local Response Normalization)、BN(Batch Normalization)等,有助于模型泛化。
BN(Batch Normalization) 希望激活函數(shù)的輸出盡量滿足高斯分布,可以在全連接層后、激活層前加上BN,本質(zhì)目的是促進(jìn)模型收斂,降低初始值對模型訓(xùn)練的影響,提高模型精度和泛化能力。使用了BN,就不需要使用LRN(AlexNet中用到的局部響應(yīng)歸一化),也不需要過多的考慮權(quán)重初始值、Dropout和權(quán)重懲罰項(xiàng)的參數(shù)設(shè)置問題。
正則化(Regularization)包括L1、L2范數(shù)正則化,加入正則化懲罰項(xiàng),能夠防止過擬合,提高模型泛化能力。
梯度下降 包括批量梯度下降、隨機(jī)梯度下降。可以比作下山問題,下山方向永遠(yuǎn)是梯度下降最快的方向,學(xué)習(xí)率即下山的步長。
批量梯度下降 每次迭代使用全部訓(xùn)練樣本來計(jì)算損失函數(shù)和梯度,來更新模型參數(shù)。每次迭代都朝著正確的方向進(jìn)行,保證收斂于極值點(diǎn)(也可能是局部極值點(diǎn)。.),但迭代太慢,計(jì)算冗余,消耗大量內(nèi)存。
隨機(jī)梯度下降 實(shí)際上是小批量梯度下降,每次迭代隨機(jī)使用小批量例如k個(gè)訓(xùn)練樣本計(jì)算損失函數(shù)和梯度,來更新模型參數(shù)。每次迭代不一定會(huì)朝著正確方向進(jìn)行,可能會(huì)有波動(dòng),但也會(huì)收斂于極值點(diǎn),即保證收斂性又保證收斂速度。
激活函數(shù) 主要有ReLu激活函數(shù)、Sigmoid激活函數(shù)、Tanh激活函數(shù)。它們都是非線性激活函數(shù)(ReLu是規(guī)整化線性函數(shù)),比線性激活函數(shù)具有更強(qiáng)的特征表達(dá)能力。Sigmoid函數(shù)的x越大,導(dǎo)數(shù)越接近0,反向傳播到遠(yuǎn)離輸出層時(shí)容易出現(xiàn)梯度彌散,現(xiàn)在一般用ReLu用作激活函數(shù)來防止梯度彌散。
數(shù)據(jù)預(yù)處理 數(shù)據(jù)歸一化(去均值歸一化)、PCA主成分分析、ZCA白化。數(shù)據(jù)歸一化的好處在于使得訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)具有一致的數(shù)據(jù)分布,增強(qiáng)模型的泛化能力。
PCA主分量分析 用于數(shù)據(jù)降維和降低特征間相關(guān)度,需要特征均值接近0且各特征的方差接近,因此需要先做去均值,一般情況下都不需要做方差歸一化。
ZCA白化 用于降低特征冗余度(不降維),需要特征間相關(guān)度較低且特征具有相同的方差,因此ZCA白化一般是在PCA白化的基礎(chǔ)上做的,可以看做是各個(gè)特征的幅度歸一化。
圖像處理與數(shù)據(jù)增廣 顏色轉(zhuǎn)換、對比度拉伸、直方圖均衡、局部直方圖均衡、加隨機(jī)噪聲、平移、縮放、旋轉(zhuǎn)、鏡像、投影變換、隨機(jī)裁剪等。
如何提高深度學(xué)習(xí)算法性能?
1.通過數(shù)據(jù)
更多的數(shù)據(jù)樣本
數(shù)據(jù)的代表性、全面性
數(shù)據(jù)預(yù)處理
圖像處理與數(shù)據(jù)增廣
數(shù)據(jù)清洗
難例
2.通過算法
選擇合適的網(wǎng)絡(luò)模型(包括網(wǎng)絡(luò)結(jié)構(gòu)和網(wǎng)絡(luò)參數(shù))
在已有模型上進(jìn)行fine-tune
dropout、normalization、正則化
合理調(diào)節(jié)訓(xùn)練參數(shù)(學(xué)習(xí)率、batchsize等)
根據(jù)具體應(yīng)用場景還可能需要修改損失函數(shù)
-
卷積
+關(guān)注
關(guān)注
0文章
95瀏覽量
18752 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5560瀏覽量
122765
發(fā)布評論請先 登錄
BP神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)的關(guān)系
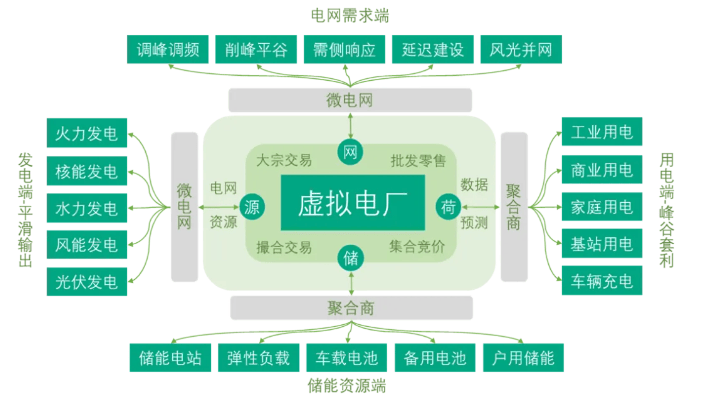
了解虛擬電廠的基本概念
自然語言處理與機(jī)器學(xué)習(xí)的關(guān)系 自然語言處理的基本概念及步驟
NPU在深度學(xué)習(xí)中的應(yīng)用
GPU深度學(xué)習(xí)應(yīng)用案例
Linux應(yīng)用編程的基本概念
AI大模型與深度學(xué)習(xí)的關(guān)系
X電容和Y電容的基本概念
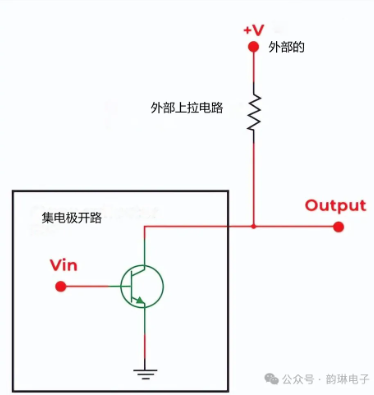
集電極開路的基本概念與原理
DDR4的基本概念和特性
伺服系統(tǒng)基本概念和與變頻的關(guān)系
socket的基本概念和原理
AI入門之深度學(xué)習(xí):基本概念篇






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論