") Google推出地標(biāo)實(shí)例識(shí)別和圖像檢索人物數(shù)據(jù)集
Google推出地標(biāo)實(shí)例識(shí)別和圖像檢索人物數(shù)據(jù)集
隨著圖像檢索和實(shí)例識(shí)別技術(shù)的迅速發(fā)展,急需有效的基準(zhǔn)數(shù)據(jù)來對不斷出現(xiàn)算法的性能進(jìn)行有效測評。來自谷歌的研究人員為此設(shè)計(jì)并推出了Google Landmarks Dataset v2(GLDv2)數(shù)據(jù)集用于大規(guī)模、細(xì)粒度的地標(biāo)實(shí)例識(shí)別和圖像檢索人物。這一數(shù)據(jù)集包含了200k個(gè)不同實(shí)例標(biāo)簽共5M張圖像,其中包括測試集為檢索人物標(biāo)注的118k張圖像。
這一數(shù)據(jù)集的特點(diǎn)不僅在于規(guī)模,而且在于考慮了許多真實(shí)應(yīng)用中會(huì)遇到的問題,包括長尾特性、域外圖像、類內(nèi)豐富多樣性等特點(diǎn)。這一數(shù)據(jù)集除了可以作為檢索和識(shí)別人物的有效基準(zhǔn)外,研究人員還通過學(xué)習(xí)圖像嵌入呈現(xiàn)了其用于遷移學(xué)習(xí)的潛力。
圖像檢索與實(shí)例識(shí)別
圖像檢索和實(shí)例識(shí)別是計(jì)算機(jī)視覺研究領(lǐng)域的基本課題已經(jīng)有很長的研究歷史。其中圖像檢索的目的是基于查詢圖像來排序出最為相關(guān)的圖像,而實(shí)例識(shí)別則是為了識(shí)別出目標(biāo)類別中的特定實(shí)例(例如從“油畫”類別中識(shí)別出“蒙娜麗莎”實(shí)例)。
但隨著技術(shù)的發(fā)展,兩種任務(wù)開始結(jié)合提高了技術(shù)額魯棒性和規(guī)模性,早期的數(shù)據(jù)集越來越不足以支撐算法的發(fā)展。此外在圖像分類、目標(biāo)檢測等領(lǐng)域都出現(xiàn)了像ImageNet、COCO、OpenImages等大規(guī)模的數(shù)據(jù)集,而圖像檢索領(lǐng)域還在使用Oxford5k和Paris6k等數(shù)據(jù)較少、時(shí)間較老的數(shù)據(jù)集。由于其大多只包含了單個(gè)城市的數(shù)據(jù),使其訓(xùn)練的結(jié)果難以大規(guī)模的泛化。
世界范圍內(nèi)的數(shù)據(jù)采集點(diǎn)的分布
很多現(xiàn)有的數(shù)據(jù)集都沒有涵蓋真實(shí)條件下的挑戰(zhàn)。例如用于視覺檢索的地標(biāo)識(shí)別app會(huì)收到大量非地標(biāo)的查詢圖像,包括動(dòng)植物或各類產(chǎn)品等,這些查詢圖像原則上不應(yīng)該得到任何查詢結(jié)果。此外絕大多數(shù)實(shí)例識(shí)別數(shù)據(jù)集僅僅有專題查詢能力,同時(shí)無法測量域外數(shù)據(jù)的假陽性率。
研究人員迫切需要更大、更具挑戰(zhàn)的數(shù)據(jù)來測評技術(shù)的發(fā)展,同時(shí)為將來的研究提供足夠的挑戰(zhàn)和動(dòng)力。這一領(lǐng)域缺乏大規(guī)模數(shù)據(jù)的原因在于上千個(gè)標(biāo)簽和上百萬圖像中進(jìn)行數(shù)千個(gè)標(biāo)簽的細(xì)粒度標(biāo)注十分耗費(fèi)人力,同時(shí)也不是簡單的外包可以完成,需要專業(yè)知識(shí)才能有效標(biāo)注。為了解決這些問題,新的數(shù)據(jù)呼之欲出!
GLDv2
這一新數(shù)據(jù)集的主要目的是為了盡可能的模擬和覆蓋真實(shí)工業(yè)場景地標(biāo)識(shí)別系統(tǒng)所面臨的挑戰(zhàn)。為了盡可能地覆蓋真實(shí)世界,需要非常多的圖像,因此這一數(shù)據(jù)集首先需要滿足大規(guī)模的特性;其次為了適應(yīng)多種光照條件和視角,還需要每一個(gè)類別或?qū)嵗龢?biāo)簽中的圖像具有豐富的類內(nèi)多樣性。真實(shí)情況下絕大多數(shù)圖像來源于著名的地標(biāo),而還有很多來源于不那么知名的地點(diǎn),所以數(shù)據(jù)集還需要具備長尾特性。最后一個(gè)問題,在實(shí)際使用中,用戶會(huì)上傳各種各樣的查詢圖像,只有非常少的一部分圖像存在于數(shù)據(jù)集中,那么這些數(shù)據(jù)需要滿足域外查找特性(即能夠在不包含在訓(xùn)練集中的查詢圖像上依然有效運(yùn)行)。這些實(shí)際情況中的特點(diǎn)為識(shí)別算法的魯棒性提出了非常大的要求。
在這些因素的指導(dǎo)下,研究人員們開始收集對應(yīng)的圖像并進(jìn)行標(biāo)注。數(shù)據(jù)主要來源于Wikimedia Commons,這是Wikipedia背后支撐的媒體資源庫。它覆蓋了世界范圍內(nèi)大部分的地標(biāo),同時(shí)還包括了Wiki Loves Monuments來自世界各地的文化遺跡高質(zhì)量細(xì)粒度照片。此外研究人員還從眾包中獲取了真實(shí)的查詢照片。
在獲取了圖像后就需要標(biāo)記數(shù)據(jù)集建立索引了。下圖顯示了從Wikimedia Commons中挖掘地標(biāo)圖像的流程。
Wikimedia Commons中是按照分類學(xué)的方式組織資源。每一個(gè)分類有獨(dú)特的URL其中包含了所有相關(guān)的圖像列表。但這種方式并沒有合適的頂級(jí)分類來映射人造和自然地標(biāo)的,于是研究人員采用了谷歌知識(shí)圖譜來發(fā)掘世界范圍內(nèi)的地標(biāo)。
為了獲取WikiCommons中與地標(biāo)相關(guān)的分類,研究人員從谷歌知識(shí)圖譜中查詢了“l(fā)andmarks”,“tourist attractions”,“points of interest”等等詞條,每次查詢都會(huì)返回圖譜實(shí)體,利用這一實(shí)體來獲取Wikipedia中的文章,并跟隨文章中的鏈接找到Wikimedia Commons分類頁面。隨后將所有圖像下載下來,并利用嚴(yán)格的分類來確定每一張圖像對應(yīng)一種分類,并利用Wikimedia Commons中的url作為典型的類別標(biāo)簽。依照這樣的方式獲取了訓(xùn)練和索引集。而查詢數(shù)據(jù)集的構(gòu)建則包含了包含地標(biāo)的positive查詢和不包含地標(biāo)的negative查詢。
由于視覺上的檢查發(fā)現(xiàn)檢索和識(shí)別結(jié)果出現(xiàn)了一些錯(cuò)誤,主要由于遺漏了基準(zhǔn)標(biāo)注,原因源于以下幾個(gè)方面:眾包帶來的錯(cuò)誤和遺漏、某些查詢圖像包含多個(gè)地標(biāo),但基準(zhǔn)只有一個(gè)結(jié)果、某一圖像在不同層次具有不同的標(biāo)簽、某些negative查詢圖像實(shí)際上是地標(biāo)圖像。為了解決這些問題,需要對測試集進(jìn)行重新標(biāo)注。
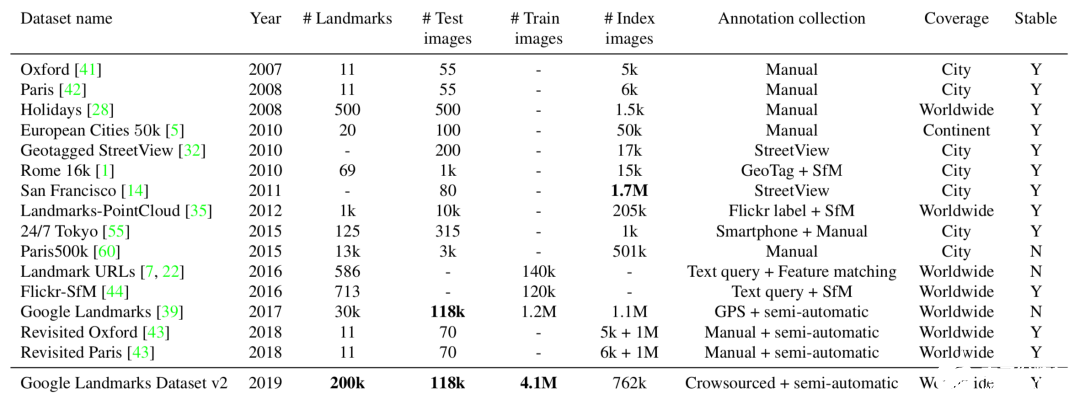
GLDv2數(shù)據(jù)集與其他數(shù)據(jù)的比較
最終研究人員得到了五百萬張超過二十萬個(gè)不同實(shí)例地點(diǎn)的數(shù)據(jù)集,成為了目前領(lǐng)域內(nèi)最大的實(shí)例識(shí)別數(shù)據(jù)。它最終分為三個(gè)部分,一部分是118k包含基準(zhǔn)標(biāo)注的查詢數(shù)據(jù)、4.1M圖像包含203k地標(biāo)標(biāo)簽的訓(xùn)練數(shù)據(jù)、包含101k地標(biāo)的762k張索引圖像。此外還給出了一個(gè)小型的數(shù)據(jù)集包括1.2M圖像和15k地標(biāo)。與其他數(shù)據(jù)集相比,這一新數(shù)據(jù)集的規(guī)模和多樣性都是無可比擬的:
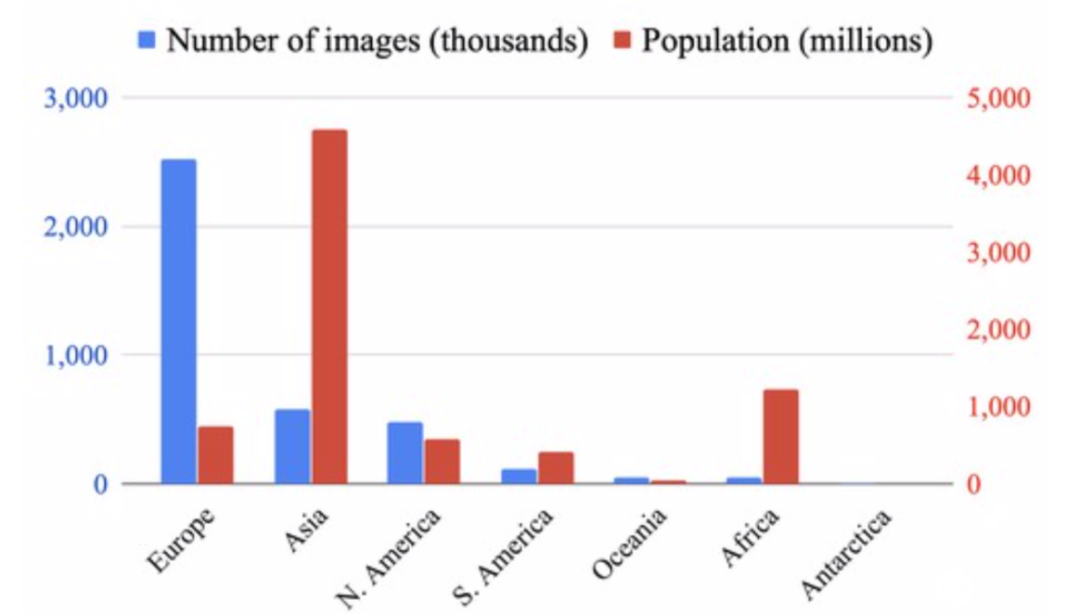
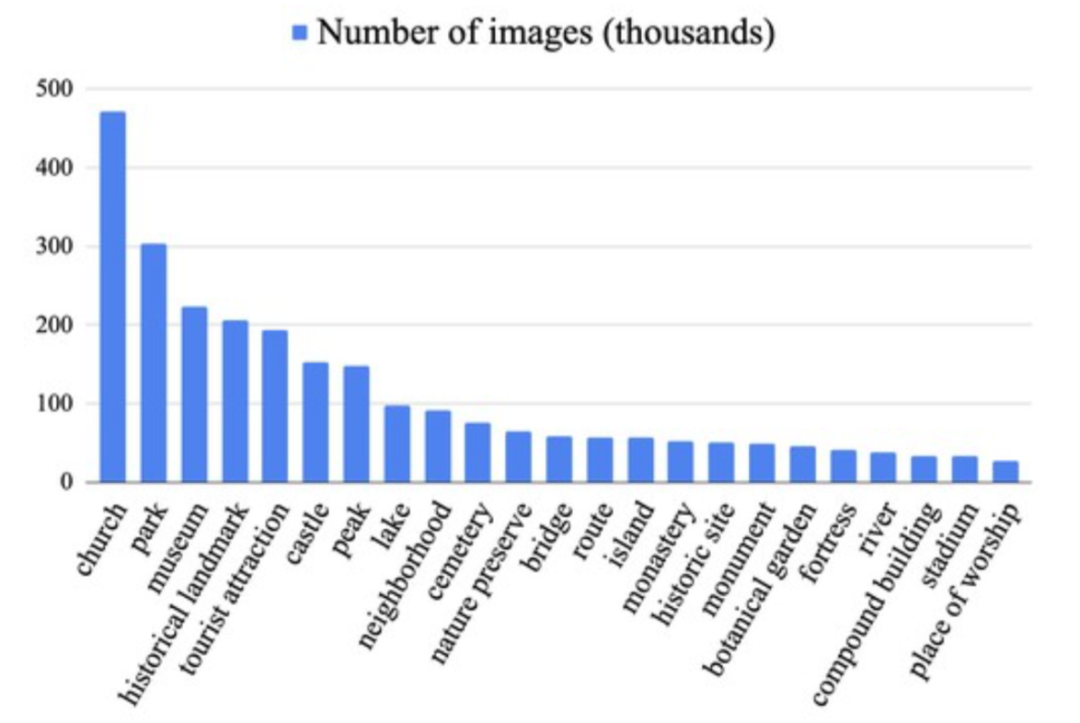
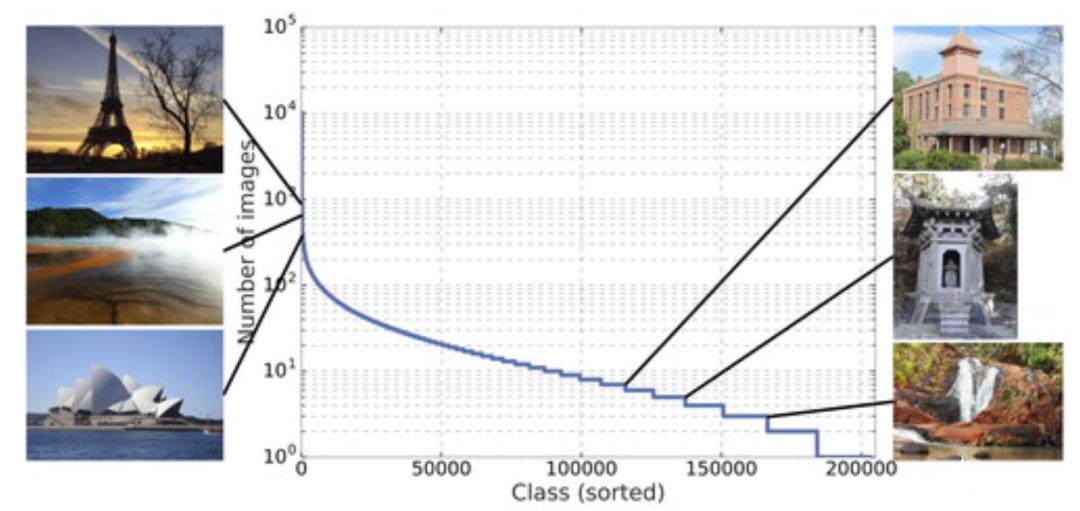
采集自世界范圍內(nèi)的圖像,分類圖顯示了超過25k地點(diǎn)類別直方圖
強(qiáng)有力的數(shù)據(jù)集
為了檢驗(yàn)這一數(shù)據(jù)集的能力,研究人員進(jìn)行了一系列實(shí)驗(yàn)。首先在GLDv2數(shù)據(jù)上進(jìn)行訓(xùn)練,測試了模型的遷移能力。通過學(xué)習(xí)全局描述子并測評他們在獨(dú)立地標(biāo)檢索數(shù)據(jù)中的表現(xiàn)(Revisited Oxford,ROxf 和 Revisited Paris, RPar) 。下表顯示了這一數(shù)據(jù)集可以顯著提高模型的性能,mAP的提升將近5%。
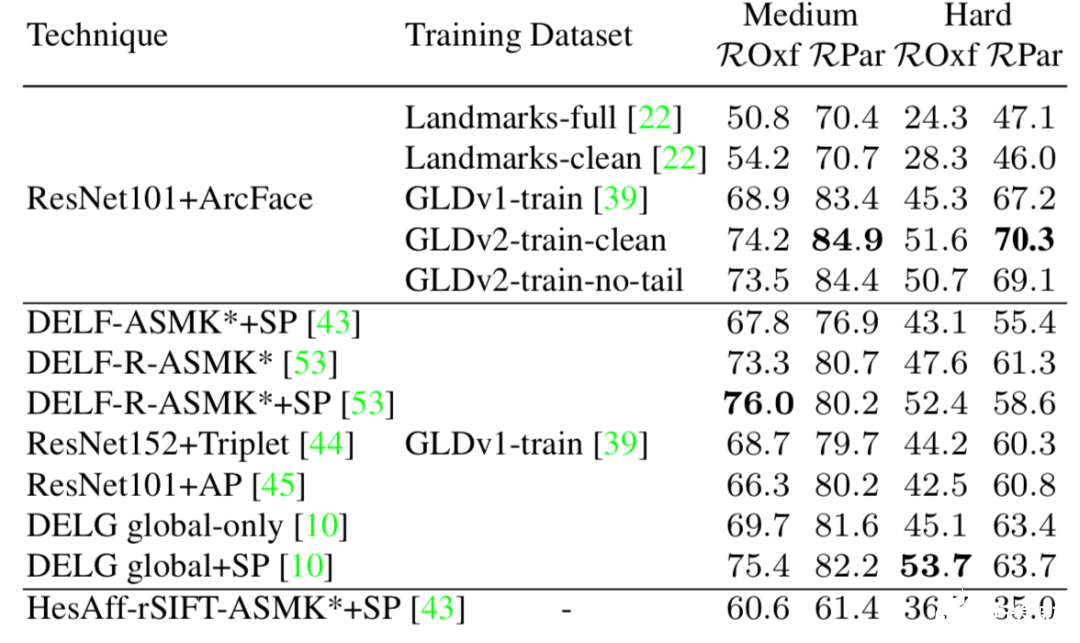
針對識(shí)別和檢索任務(wù)下面兩個(gè)表展示了基于不同模型和數(shù)據(jù)集上的比較結(jié)果可以看到基于GLDv2數(shù)據(jù)集的模型性能得到了顯著提升。
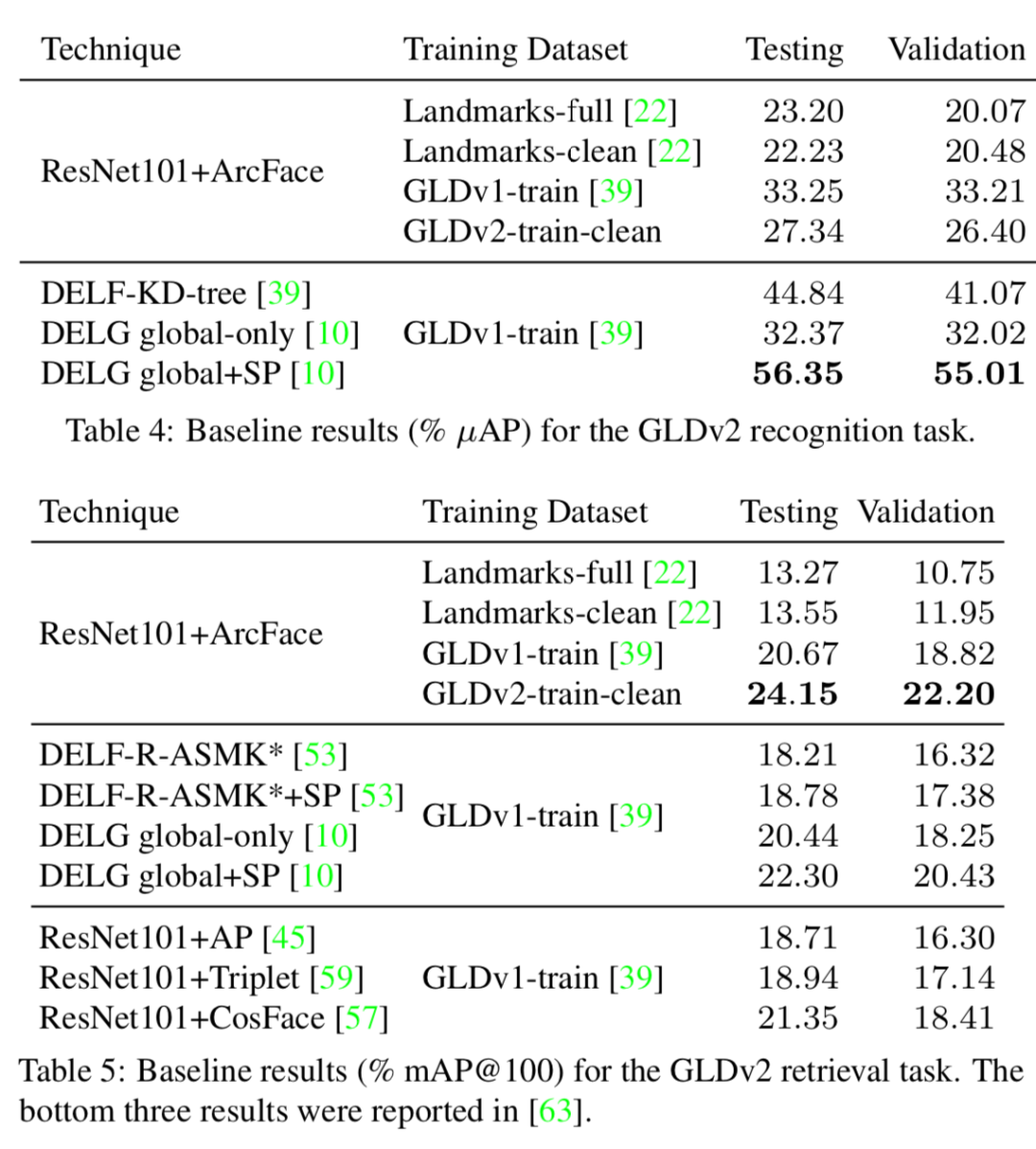
此外在檢索挑戰(zhàn)任務(wù)上進(jìn)行了測評,包括了全局特征搜索和局域特征匹配重排等技術(shù)。結(jié)果顯示,即使使用了復(fù)雜的技術(shù),這一數(shù)據(jù)集仍然具有可以挖掘提升的空間。
-
谷歌
+關(guān)注
關(guān)注
27文章
6219瀏覽量
107259 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25229
發(fā)布評論請先 登錄
請問NanoEdge AI數(shù)據(jù)集該如何構(gòu)建?
海康威視文搜存儲(chǔ)系列:跨模態(tài)檢索,安防新境界
AI大模型在圖像識(shí)別中的優(yōu)勢
軟件系統(tǒng)的數(shù)據(jù)檢索設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論