 一種新型解決方案:將表征學習和分類器學習分開
一種新型解決方案:將表征學習和分類器學習分開
在圖像分類任務中類別不均衡問題一直是個難點,在實際應用中大部分的分類樣本很可能呈現長尾分布。新加坡國立大學和 Facebook AI 的研究者提出了一種新型解決方案:將表征學習和分類器學習分開,從而尋找合適的表征來最小化長尾樣本分類的負面影響。該論文已被 ICLR 2020 接收。
圖像分類一直是深度學習領域中非常基本且工業應用廣泛的任務,然而如何處理待分類樣本中存在的類別不均衡問題是長期困擾學界與工業界的一個難題。相對來說,學術研究提供的普通圖像分類數據集維持了較為均衡的不同類別樣本分布;然而在實際應用中,大部分的分類樣本很可能呈現長尾分布(long-tail distribution),這很有可能導致分類模型效果偏差:對于尾部的類別分類準確率不高。 針對長尾分布的圖像識別任務,目前的研究和實踐提出了大致幾種解決思路,比如分類損失權重重分配(loss re-weighting)、數據集重采樣、尾部少量樣本過采樣、頭部過多樣本欠采樣,或者遷移學習。 在 ICLR 2020 會議上,新加坡國立大學與 Facebook AI 合著了一篇論文《Decoupling Representation and classifier for long-tailed recognition》,提出了一個新穎的解決角度:在學習分類任務的過程中,將通常默認為聯合起來學習的類別特征表征與分類器解耦(decoupling),尋求合適的表征來最小化長尾樣本分類的負面影響。

論文鏈接:https://openreview.net/pdf?id=r1gRTCVFvB
GitHub 鏈接:https://github.com/facebookresearch/classifier-balancing
該研究系統性地探究了不同的樣本均衡策略對長尾型數據分類的影響,并進行了詳實的實驗,結果表明:a) 當學習到高質量的類別表征時,數據不均衡很可能不會成為問題;b) 在學得上述表征后,即便應用最簡單的樣本均衡采樣方式,也一樣有可能在僅調整分類器的情況下學習到非常魯棒的長尾樣本分類模型。 該研究將表征學習和分類器學習分離開來,分別進行了延伸探究。 表征學習 對于表征學習來說,理想情況下好的類別表征能夠準確識別出各種待分類類別。目前針對長尾類型數據分類任務,不同的采樣策略、損失權重重分配,以及邊界正則化(margin regularization)都可用于改善類別不均。 假設 p_j 為樣本來自類別 j 中的概率,則 p_j 可用如下公式表示:
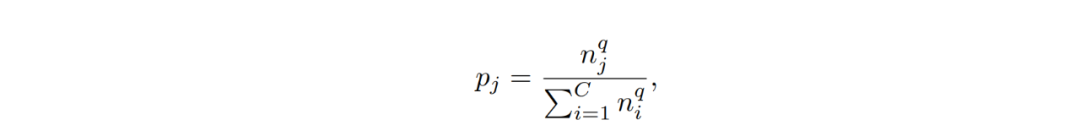
其中 n 為訓練樣本總數,C 為訓練類別總數,而 q 為 [0,1] 其中一個值。 采樣策略包含以下幾種常用采樣方式:
樣本均衡采樣(Instance-balanced sampling):該方法最為常見,即每一個訓練樣本都有均等的機會概率被選中,即上述公式中 q=1 的情況。
類別均衡采樣(Class-balanced sampling):每個類別都有同等的概率被選中,即公平地選取每個類別,然后再從類別中進行樣本選取,即上述公式中 q=0 的情況。
平方根采樣(Square-root sampling):本質上是之前兩種采樣方式的變種,通常是將概率公式中的 q 定值為 0.5。
漸進式均衡采樣(Progressively-balanced sampling):根據訓練中的迭代次數 t(epoch)同時引入樣本均衡(IB)與類別均衡(CB)采樣并進行適當權重調整的一種新型采樣模式,公式為
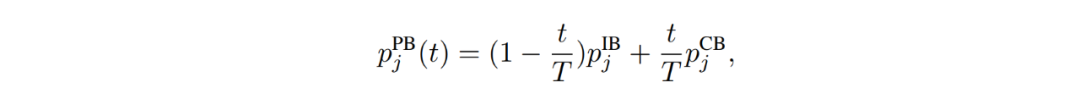
其中 T 為數據集訓練迭代總數。 分類器學習 該研究也針對單獨拆分出來的分類器訓練進行了調研和分類概括:
重訓練分類器(Classifier Re-training, cRT):保持表征固定不變,隨機重新初始化分類器并進行訓練。
最近類別平均分類器(Nereast Class Mean classifier, NCM):首先計算學習到的每個類別特征均值,然后執行最近鄰搜索來確定類別。
τ-歸一化分類器(τ-normalized classifier):作者提出使用該方法對分類器中的類別邊界進行重新歸一化,以取得均衡。
實驗結果 通過以上觀察和學習拆分,該研究在幾個公開的長尾分類數據集上重新修改了頭部類別和尾部類別的分類決策邊界,并且搭配不同的采樣策略進行交叉訓練實驗。訓練出的不同分類器之間的對比結果如下圖所示:
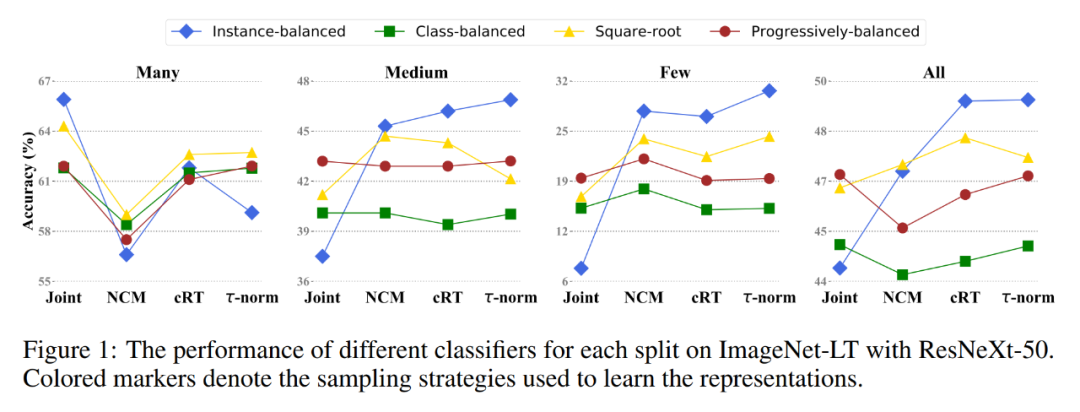
同時,在 Places-LT、Imagenet-LT 和 iNaturalist2018 三個公開標準數據集上,該研究提出的策略也獲得了同比更高的分類準確率,實現了新的 SOTA 結果:
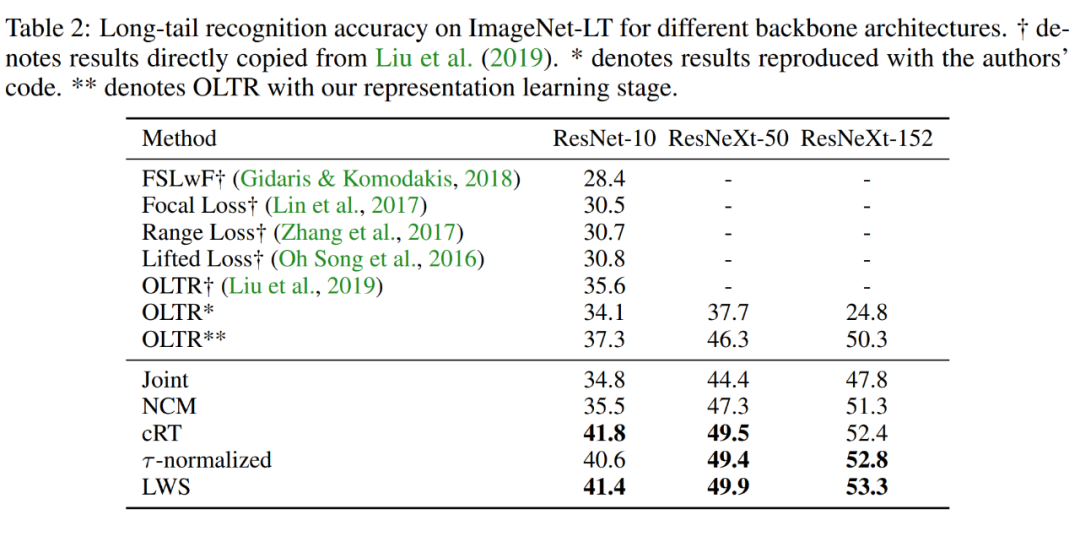
通過各類對比實驗,該研究得到了如下觀察: 1. 解耦表征學習與分類為兩個過程均取得了非常好的效果,并且打破了人們對長尾分類固有的「樣本均衡采樣學習效果最好,擁有最具泛化性的特征表示」這一經驗之談。 2. 重新調整分類邊界對于長尾分布的物體識別來說是非常有效的。 3. 將該研究提出的解耦學習規則應用到傳統網絡(如 ResNeXt)中,仍能取得很好的效果,這說明該策略確實對長尾分類具備一定指導意義。 該研究針對業界和學界頻繁遇到的長尾樣本分類難題,提出解構傳統的「分類器表征聯合學習」范式,從另一個角度提供了新思路:調整它們在表征空間的分類邊界或許是更加高效的方法。 該研究思路比較新穎,實驗結果也具有一定的代表性。對于研究長尾分類的學者或者業界工程師而言,這在傳統采樣方式下「面多了加水,水多了加面」的經驗之外,提供了額外思路。目前該研究的相關代碼已在 GitHub 上開源,感興趣的讀者可以下載進行更多的嘗試。 代碼實現 研究者在 GitHub 項目中提供了對應的訓練代碼和必要的訓練步驟。代碼整體是相對基本的分類訓練代碼,比較容易實現。具體到復現模型訓練,作者也給出了幾點注意事項。 1. 表征學習階段
學習過程中保持網絡結構(比如 global pooling 之后不需要增加額外的全連接層)、超參數選擇、學習率和 batch size 的關系和正常分類問題一致(比如 ImageNet),以確保表征學習的質量。
類別均衡采樣:采用多 GPU 實現的時候,需要考慮使得每塊設備上都有較為均衡的類別樣本,避免出現樣本種類在卡上過于單一,從而使得 BN 的參數估計不準。
漸進式均衡采樣:為提升采樣速度,該采樣方式可以分兩步進行。第一步先從類別中選擇所需類別,第二步從對應類別中隨機選擇樣本。
2. 分類器學習階段
重新學習分類器(cRT):重新隨機初始化分類器或者繼承特征表示學習階段的分類器,重點在于保證學習率重置到起始大小并選擇 cosine 學習率。
τ-歸一化(tau-normalization):τ 的選取在驗證集上進行,如果沒有驗證集可以從訓練集模仿平衡驗證集,可參考原論文附錄 B.5。
可學習參數放縮(LWS):學習率的選擇與 cRT 一致,學習過程中要保證分類器參數固定不變,只學習放縮因子。
-
圖像分類
+關注
關注
0文章
93瀏覽量
11963 -
深度學習
+關注
關注
73文章
5521瀏覽量
121636
原文標題:ICLR 2020 | 如何解決圖像分類中的類別不均衡問題?不妨試試分開學習表征和分類器
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
常見xgboost錯誤及解決方案
xgboost在圖像分類中的應用
一種使用LDO簡單電源電路解決方案
NPU在深度學習中的應用
一種基于深度學習的二維拉曼光譜算法

靈活多元的EMC學習方案


深度學習中的時間序列分類方法
深度學習與nlp的區別在哪
人工智能數據中心的新型連接解決方案

一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
深度學習與度量學習融合的綜述
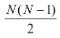





 工商網監
工商網監
評論