") 如何搭建一個聊天機(jī)器人?
如何搭建一個聊天機(jī)器人?

顧名思義,“聊天機(jī)器人”是與您聊天的機(jī)器。訣竅是使它盡可能像人一樣。從“美國運(yùn)通客戶支持”到Google Pixel的呼叫篩選軟件聊天機(jī)器人,各種各樣。
它實(shí)際上如何運(yùn)作?
聊天機(jī)器人的早期版本使用一種稱為模式匹配的機(jī)器學(xué)習(xí)技術(shù)。與當(dāng)今使用的高級NLP技術(shù)相比,這要簡單得多。
什么是模式匹配?
要理解這一點(diǎn),請想象您會問一個書商,例如“ __本書的價格是多少?”或“您擁有____本書的哪幾本書?”這些斜體字中的每一個都是可以將來出現(xiàn)類似問題時進(jìn)行匹配。
模式匹配需要大量預(yù)先生成的模式。基于這些預(yù)先生成的模式,聊天機(jī)器人可以輕松地選擇與客戶查詢最匹配的模式并為其提供答案。
您不妨猜一下下面的聊天是如何實(shí)現(xiàn)的?
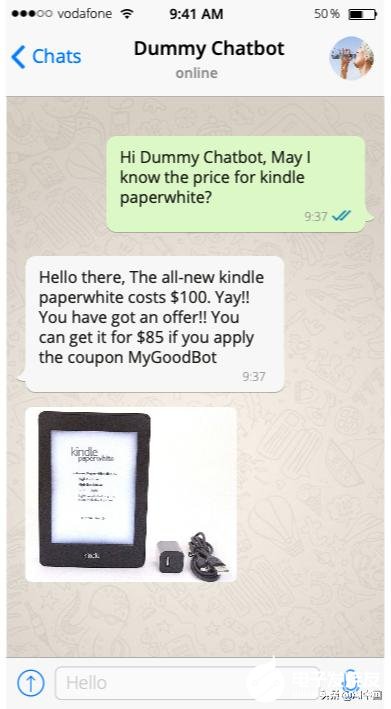
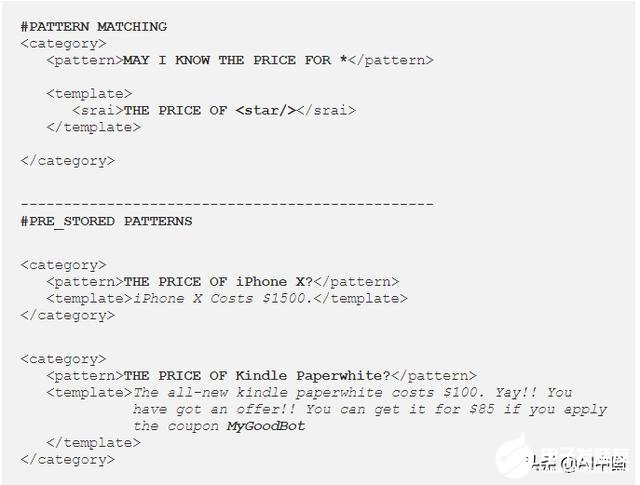
簡而言之,可以將我的價格知道的問題轉(zhuǎn)換為模板《star /》的價格。該模板就像一個密鑰,以后將使用它存儲所有答案。所以我們可以有以下內(nèi)容
·iPhone X的價格-1500美元
·Kindle Paperwhite的價格-100美元
NLP聊天機(jī)器人
模式匹配很容易實(shí)現(xiàn),但是只能走得很遠(yuǎn)。 它需要許多預(yù)先生成的模板,并且僅對期望數(shù)量有限的問題的應(yīng)用程序有用。

xkcd
輸入NLP! NLP是一些稍先進(jìn)的技術(shù)的集合,可以理解廣泛的問題。創(chuàng)建聊天機(jī)器人的NLP過程可以分為5個主要步驟
1)標(biāo)記化-標(biāo)記化是一種將文本切成小段的技術(shù),稱為標(biāo)記,并同時丟棄某些字符,例如標(biāo)點(diǎn)符號。這些標(biāo)記在語言上代表文本。

標(biāo)記句子
2)規(guī)范化-規(guī)范化處理文本以找出可能會改變用戶請求的預(yù)期含義的常見拼寫錯誤。一篇對推文進(jìn)行規(guī)范化的非常好的研究論文很好地解釋了這個概念

推文研究的句法規(guī)范化
3)識別實(shí)體-此步驟可幫助聊天機(jī)器人識別正在談?wù)摰氖挛铮缡菍ο筮€是國家/地區(qū)或數(shù)字還是用戶的地址。 在下面的示例中觀察到Google,IBM和Microsoft是如何組織在一起的。此步驟也稱為命名實(shí)體識別。

4)依存關(guān)系解析-在這一步中,我們將句子分為其名詞,動詞,賓語,常用短語和標(biāo)點(diǎn)符號。這項技術(shù)可幫助機(jī)器識別短語,進(jìn)而告訴用戶要傳達(dá)的內(nèi)容。

Stanford —依賴項解析示例
5)生成-最后,生成響應(yīng)的步驟。以上所有步驟都屬于NLU(自然語言理解)。這些步驟可幫助機(jī)器人理解所寫句子的含義。但是,此步驟屬于NLG(自然語言生成)。此步驟接收先前NLU步驟的輸出,并生成許多具有相同含義的句子。在以下方面,生成的句子通常相似
·詞序-“廚房燈”類似于“廚房燈”
·單數(shù)/復(fù)數(shù)-“廚房燈”類似于“廚房燈”
·問題-“關(guān)門”類似于“您介意關(guān)門嗎?”
·否定-“在19:00打開電視”類似于“在19:00不打開電視”
·禮貌-“打開電視”類似于“請您能開一個電視好嗎?”
根據(jù)用戶的問題,機(jī)器人可以使用上述選項之一進(jìn)行回復(fù),并且用戶會滿意地返回。在許多情況下,用戶無法區(qū)分機(jī)器人和人類。
自1995年AIML發(fā)明以來,聊天機(jī)器人一直在穩(wěn)步增長,并取得了長足的發(fā)展。即使在2016年,平均用戶花費(fèi)超過20分鐘的時間通過消息傳遞應(yīng)用程序進(jìn)行交互,其中Kakao,Whatsapp和Line是最受歡迎的。

相似的網(wǎng)絡(luò)
世界各地的企業(yè)都在尋求削減客戶服務(wù)成本,并通過使用這些漫游器來全天候提供客戶服務(wù)。
NLP還有很長的路要走,但是即使在目前的狀態(tài)下,NLP在聊天機(jī)器人領(lǐng)域也有很大的希望。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8502瀏覽量
134592 -
聊天機(jī)器人
+關(guān)注
關(guān)注
0文章
348瀏覽量
12795 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22621
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論