") 三篇ACL2020論文即圍繞謠言判別中的可解釋性
三篇ACL2020論文即圍繞謠言判別中的可解釋性
引言
謠言始終與人類(lèi)社會(huì)的發(fā)展形影相隨,隨著互聯(lián)網(wǎng)的發(fā)展和網(wǎng)上言論的開(kāi)放,虛假的、未經(jīng)證實(shí)的信息極易在社交網(wǎng)絡(luò)平臺(tái)上廣泛傳播,帶來(lái)不良社會(huì)影響。目前,網(wǎng)絡(luò)謠言常被定義為“廣泛流傳的、真實(shí)性受到質(zhì)疑的、表面上可信但極具迷惑性難以辨別真?zhèn)蔚男畔ⅰ保╖ubiaga, 2018)。
對(duì)網(wǎng)絡(luò)謠言真實(shí)性進(jìn)行判別是較為復(fù)雜的系統(tǒng)性任務(wù),可粗粒度分為謠言檢測(cè)(rumor detection)、立場(chǎng)分類(lèi)(stance classification)、謠言判別(rumor verification)流程式子任務(wù)。同時(shí)社交網(wǎng)絡(luò)中可追蹤的文本內(nèi)容、用戶(hù)特征、信息傳播軌跡,為謠言檢測(cè)及真?zhèn)涡耘袆e提供了豐富的信息來(lái)源和建模思路,這也使得端到端的謠言判別更具挑戰(zhàn)。
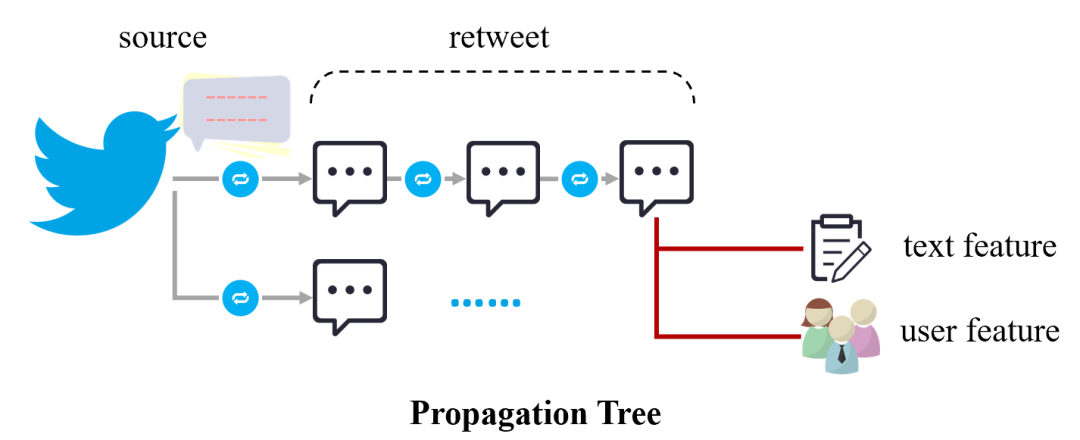
網(wǎng)絡(luò)謠言形成的信息傳播樹(shù)及特征來(lái)源
早期,學(xué)者們多采用從文本、用戶(hù)、傳播等方面提取特征的思路,盡可能的刻畫(huà)謠言傳播形態(tài)。隨著深度學(xué)習(xí)的發(fā)展,更具泛化性的文本表示方法(如詞向量、預(yù)訓(xùn)練模型),更適配于消息傳播的信息整合模型(如基于消息發(fā)布時(shí)間的序列化模型、基于信息傳播軌跡的樹(shù)結(jié)構(gòu)/圖結(jié)構(gòu)模型),更簡(jiǎn)便的子任務(wù)協(xié)同訓(xùn)練框架(如多任務(wù)學(xué)習(xí)),使得神經(jīng)網(wǎng)絡(luò)模型在謠言判別上的性能不斷提升。
然而,隨著深度模型復(fù)雜度增加,模型內(nèi)部的決策過(guò)程卻愈加難以解釋和驗(yàn)證,也對(duì)謠言判別的實(shí)際應(yīng)用推廣帶來(lái)了限制。本次DISC小編分享的三篇ACL2020論文即圍繞謠言判別中的可解釋性,介紹網(wǎng)絡(luò)謠言傳播中易感用戶(hù)及話(huà)題挖掘、判別線(xiàn)索取證、數(shù)據(jù)及模型不確定性衡量的相關(guān)工作。
文章概覽
基于圖網(wǎng)絡(luò)和協(xié)同注意力機(jī)制的用于可解釋社交媒體虛假新聞檢測(cè)的模型(Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.48.pdf
該篇文章延續(xù)了謠言判別中的傳統(tǒng)思路,盡可能準(zhǔn)確的刻畫(huà)謠言的傳播模式。主要圍繞信源文本和參與傳播用戶(hù)的特征進(jìn)行建模,并借助協(xié)同注意力機(jī)制捕捉信源文本中的敏感話(huà)題以及傳播過(guò)程中可疑度的用戶(hù)。
基于決策樹(shù)和協(xié)同注意力機(jī)制的可解釋的謠言判別的模型(Decision Tree-based Co-Attention Networks for Explainable Claim Verification)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.97.pdf
該篇文章秉持謠言傳播中具有“自證性”,即假消息的相關(guān)評(píng)論或轉(zhuǎn)發(fā)中會(huì)出現(xiàn)對(duì)其真實(shí)性進(jìn)行佐證的內(nèi)容。通過(guò)決策樹(shù)篩選出可作為判別線(xiàn)索的消息,接著借助協(xié)同注意力機(jī)制探索信源文本與相關(guān)線(xiàn)索的交互關(guān)系,由此可呈現(xiàn)出模型在篩選佐證時(shí)的決策過(guò)程和更細(xì)粒度的關(guān)鍵文本和話(huà)題。
評(píng)估謠言判別模型中的預(yù)測(cè)不確定性(Estimating Predictive Uncertainty for Rumour Verification Models)
論文地址:https://www.aclweb.org/anthology/2020.acl-main.623.pdf
該篇文章立足于謠言判別的實(shí)際應(yīng)用場(chǎng)景,認(rèn)為訓(xùn)練完好的模型在面對(duì)突發(fā)謠言事件依然面對(duì)跨領(lǐng)域遷移的挑戰(zhàn),大部分現(xiàn)有模型泛化能力都較差,因此借助不確定性衡量及主動(dòng)學(xué)習(xí)的思路,提出了謠言判別中可衡量數(shù)據(jù)和模型不確定性的指標(biāo),并以此指標(biāo)拒絕對(duì)模型泛化不友好的訓(xùn)練樣本,探索對(duì)模型性能的影響。
數(shù)據(jù)概覽
早期與謠言檢測(cè)有關(guān)的工作多集中于通過(guò)事件關(guān)鍵詞檢索的方式,獲取討論激烈、事實(shí)性難辨的社交網(wǎng)絡(luò)短文本,文本之間相對(duì)較為孤立。后有學(xué)者提出根據(jù)消息的轉(zhuǎn)發(fā)關(guān)系形成完善的信息傳播樹(shù),從更為全局和全面的角度評(píng)估消息及相關(guān)討論的真?zhèn)涡裕∕ou, 2015)。目前,謠言判別常采用的數(shù)據(jù)集也均以信息傳播樹(shù)的方式進(jìn)行組織,每一個(gè)待判斷的傳播樹(shù)的完整的信息傳播結(jié)構(gòu)以及樹(shù)層面的類(lèi)別標(biāo)簽,以上三篇文章涉及的數(shù)據(jù)集羅列如下。
Twitter15(Liu, 2016):從國(guó)外謠言公布網(wǎng)站(如snopes.com, emergent.info)獲取已進(jìn)行判別的社交網(wǎng)絡(luò)信息,再由其發(fā)布的Twitter消息源爬取相關(guān)的轉(zhuǎn)發(fā)信息形成信息傳播樹(shù),共包含1374個(gè)信息傳播樹(shù);傳播樹(shù)標(biāo)簽包含非謠言/真實(shí)信息/虛假信息/未被證實(shí)信息,各個(gè)類(lèi)別比例較為均衡,訓(xùn)練、驗(yàn)證及測(cè)試集為隨機(jī)劃分。
Twitter16(Ma, 2016):構(gòu)造思路與Twitter 15一致,根據(jù)當(dāng)年熱門(mén)事件進(jìn)行了擴(kuò)充,包含735個(gè)信息傳播樹(shù),每棵樹(shù)包含消息數(shù)目更少。
PHEME(Zubiaga, 2016; Zubiaga, 2017):從9個(gè)和政治、民生密切相關(guān)的主題出發(fā),搜集了與這些主題相關(guān)的Twitter內(nèi)容及其引發(fā)的討論信息,篩選社交討論性質(zhì)更明顯的形成信息傳播樹(shù),根據(jù)謠言檢測(cè)、立場(chǎng)分類(lèi)、謠言判別的任務(wù)流程由新聞從業(yè)者進(jìn)行標(biāo)注,通過(guò)謠言檢測(cè)將6425個(gè)信息傳播樹(shù)分類(lèi)為謠言/非謠言,對(duì)于2402個(gè)謠言信息傳播樹(shù)再判別為真實(shí)信息/虛假信息/未被證實(shí)信息;采用LOEO(leave one event out)的驗(yàn)證方式,使其更貼近實(shí)際應(yīng)用場(chǎng)景,但不同事件文本和類(lèi)別差異都很大,極具挑戰(zhàn)性。
RumourEval(Derczynski, 2017):是PHEME數(shù)據(jù)集的子集,篩選了立場(chǎng)標(biāo)簽較為完善的325個(gè)傳播樹(shù),作為Semeval-2017 task 8的評(píng)測(cè)數(shù)據(jù)集,訓(xùn)練、驗(yàn)證及測(cè)試集為隨機(jī)劃分。
論文細(xì)節(jié)
1

基于圖網(wǎng)絡(luò)和協(xié)同注意力機(jī)制的用于可解釋社交媒體虛假新聞檢測(cè)的模型
論文動(dòng)機(jī)
此前相關(guān)研究主要受到三方面的局限:
短文本社交網(wǎng)絡(luò)文本建模能力不足。大部分用戶(hù)在轉(zhuǎn)發(fā)信源時(shí)發(fā)表的言論都較為簡(jiǎn)短,且許多僅為轉(zhuǎn)發(fā)行為缺少實(shí)質(zhì)性新增話(huà)語(yǔ),基于信息傳播樹(shù)僅對(duì)消息文本進(jìn)行建模表示能力有限。
構(gòu)建準(zhǔn)確的信息傳播樹(shù)代價(jià)昂貴。部分社交網(wǎng)絡(luò)平臺(tái)對(duì)爬取轉(zhuǎn)發(fā)鏈數(shù)目進(jìn)行了限制,并且部分用戶(hù)設(shè)置了閱讀權(quán)限,獲取的傳播樹(shù)常存在缺失或截?cái)嗟默F(xiàn)象。
復(fù)雜模型的可解釋性不足。即使模型最終輸出真?zhèn)涡詷?biāo)簽,但內(nèi)部決策過(guò)程很難驗(yàn)證,并且對(duì)于進(jìn)一步實(shí)際應(yīng)用,如挖掘潛在惡意用戶(hù)、造謠慣用話(huà)術(shù)等沒(méi)有幫助。
因此文章在對(duì)信源建模后,僅使用涉及的傳播用戶(hù)對(duì)信息傳播樹(shù)進(jìn)行建模,并且融入?yún)f(xié)同注意力機(jī)制,對(duì)判決過(guò)程中的關(guān)鍵用戶(hù)和關(guān)鍵信息進(jìn)行呈現(xiàn)。
模型
整體模型大致可拆解為4部分:
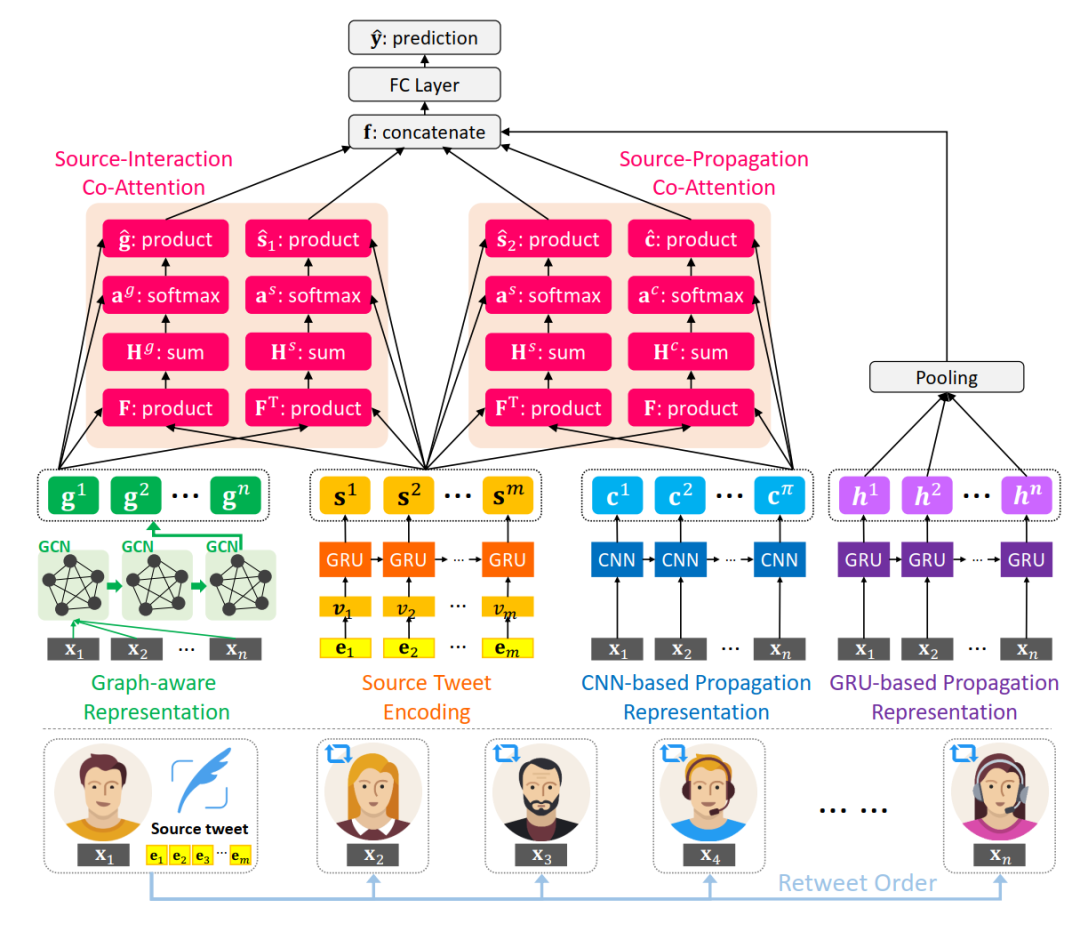
1. 信源文本表示
對(duì)原始消息文本中的詞語(yǔ)進(jìn)行one-hot編碼,再使用GRU序列模型進(jìn)行表示:
2. 用戶(hù)傳播特征表示
根據(jù)用戶(hù)的個(gè)人資料(個(gè)人簡(jiǎn)介字?jǐn)?shù)、昵稱(chēng)字?jǐn)?shù)、關(guān)注數(shù)、被關(guān)注數(shù)、是否認(rèn)證、是否開(kāi)啟地理定位、距離傳播樹(shù)中上一條消息的時(shí)間間隔、轉(zhuǎn)發(fā)所在樹(shù)的深度)提取用戶(hù)特征,根據(jù)用戶(hù)的發(fā)文時(shí)間形成序列,分別使用CNN和GRU得到傳播序列的表示。
分別使用兩個(gè)模型進(jìn)行建模,經(jīng)過(guò)CNN得到的序列表示在進(jìn)行協(xié)同注意力融合時(shí)更為友好,而GRU能體現(xiàn)傳播過(guò)程中參與用戶(hù)類(lèi)型的變化。
3. 用戶(hù)潛在交互網(wǎng)絡(luò)表示
除了在時(shí)間軸上用戶(hù)參與較為宏觀的表示,用戶(hù)之間點(diǎn)對(duì)點(diǎn)的交互關(guān)系也能刻畫(huà)信息的傳播模式。為了簡(jiǎn)化傳播樹(shù)構(gòu)造過(guò)程,文章直接將傳播樹(shù)內(nèi)涉及的用戶(hù)組成全連接圖,以用戶(hù)之間的余弦相似度初始化邊權(quán)重以及圖的鄰接矩陣
,接著使用GCN得到具有交互特征的用戶(hù)表示。
4. 協(xié)同注意力網(wǎng)絡(luò)及預(yù)測(cè)
使用協(xié)同注意力機(jī)制得到融合表示,其中對(duì)信源和用戶(hù)傳播表示的融合表示計(jì)算如下:
對(duì)信源和用戶(hù)交互表示的融合計(jì)算方式類(lèi)似。
再將信源和用戶(hù)交互表示的融合表示、信源和用戶(hù)傳播表示的融合表示、用戶(hù)傳播的序列化表示拼接,通過(guò)全連接層得到最終預(yù)測(cè)結(jié)果,以交叉熵?fù)p失函數(shù)作為優(yōu)化目標(biāo)來(lái)訓(xùn)練。
結(jié)果
模型在Twitter15、Twitter16兩個(gè)數(shù)據(jù)集上都取得了更優(yōu)的性能。
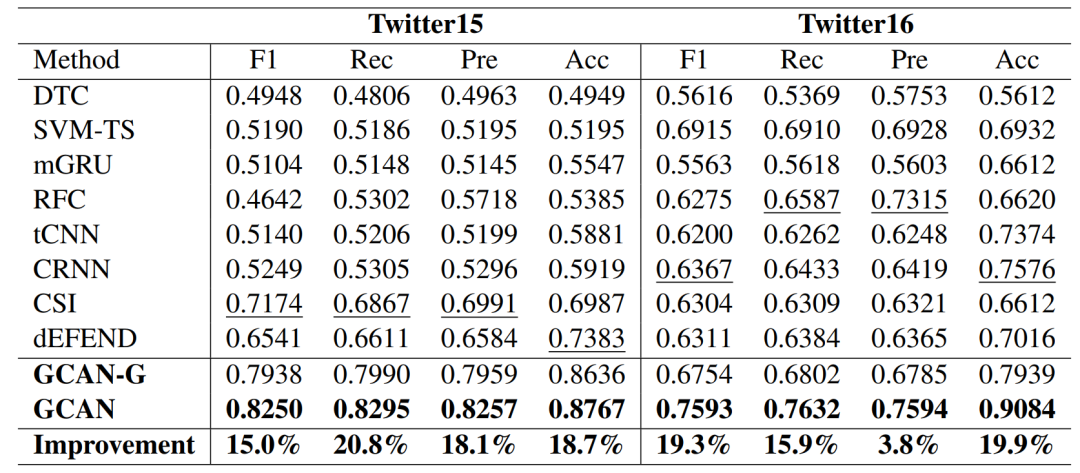
消融實(shí)驗(yàn)也驗(yàn)證了各個(gè)部件的有效性。
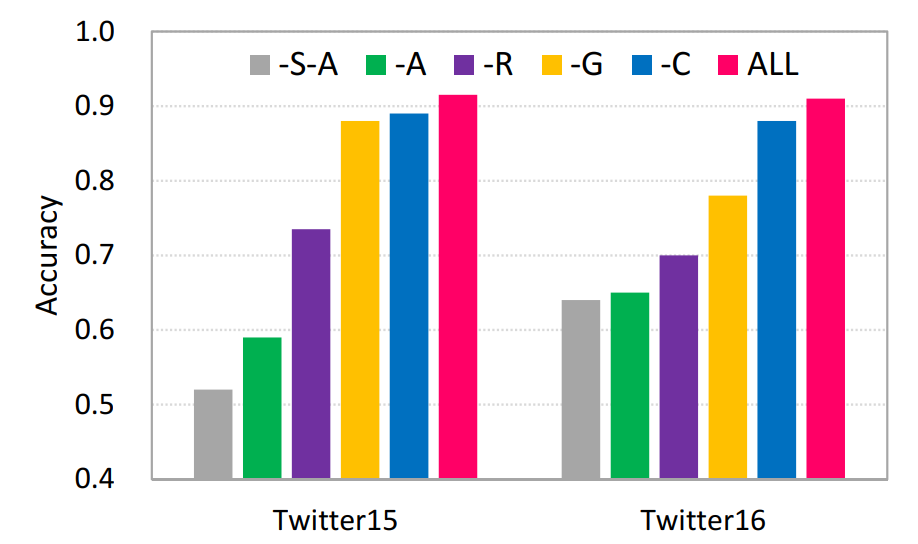
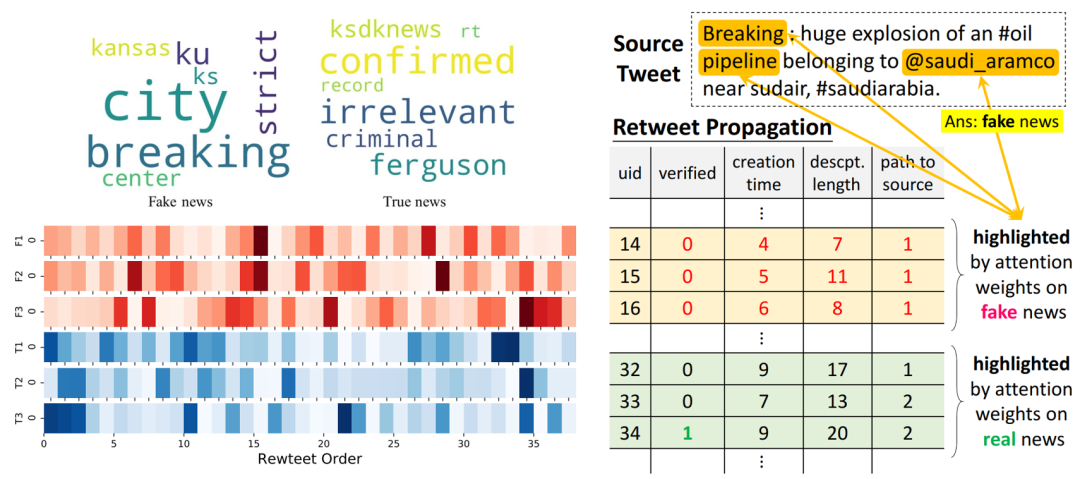
在可解釋性的論證方面,分別提取關(guān)于信源中基于詞的注意力權(quán)重、在用戶(hù)傳播表示中基于用戶(hù)的注意力權(quán)重,分析真實(shí)信息/虛假信息案例中的關(guān)鍵詞、傳播判別模式和更易參與虛假信息傳播的用戶(hù)特征。
2

基于決策樹(shù)和協(xié)同注意力機(jī)制的可解釋的謠言判別模型
論文動(dòng)機(jī)
雖然此前研究大多表明信息傳播樹(shù)中的后續(xù)討論內(nèi)容(如話(huà)題爭(zhēng)議點(diǎn)、對(duì)原始信息真實(shí)的質(zhì)疑等)對(duì)于整體判斷有幫助,但缺少定位到具體有所呼應(yīng)、有所論證單條消息的過(guò)程。此外,后續(xù)討論內(nèi)容與原始消息之間具體的詞級(jí)別的交互未進(jìn)行深入探索。
因此文章使用決策樹(shù)具有解釋性的呈現(xiàn)出篩選佐證的過(guò)程,并基于協(xié)同注意力機(jī)制探索信源與相關(guān)佐證之間詞級(jí)別的關(guān)聯(lián),形成對(duì)信息傳播樹(shù)真?zhèn)涡耘袆e可解釋性的邏輯鏈條。
模型
模型可分為2個(gè)部件:
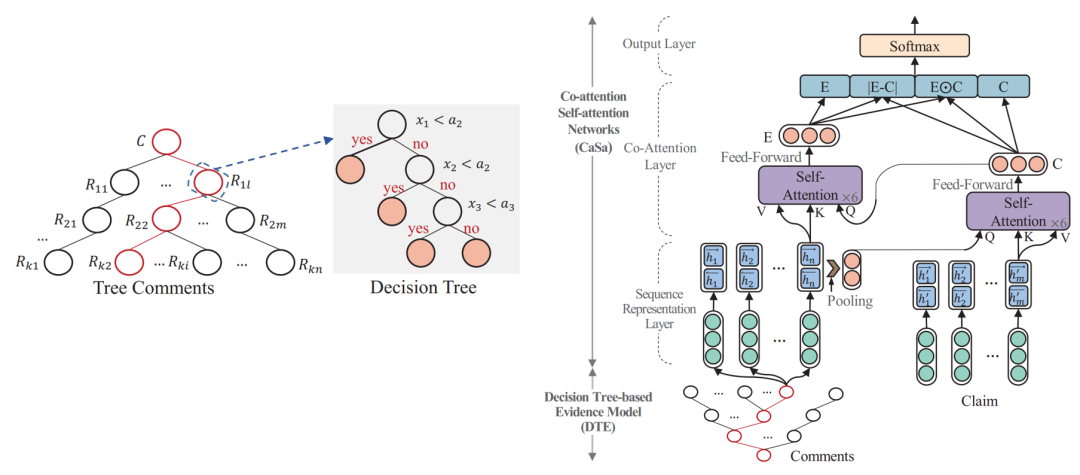
1. 基于決策樹(shù)模型篩選佐證信息
根據(jù)以往研究構(gòu)造與后續(xù)討論相關(guān)性、可信度相關(guān)的3個(gè)數(shù)值型特征:消息與信源之間的語(yǔ)義相似度,發(fā)表消息用戶(hù)的可信度,該條的可信度。
多次試驗(yàn),分別設(shè)置3個(gè)數(shù)值特征的臨界值條件,只要3個(gè)特征之一小于其閾值則將該條消息納入佐證集合。
2. 基于協(xié)同注意力機(jī)制進(jìn)行預(yù)測(cè)
對(duì)信息源文本使用雙向LSTM更新詞語(yǔ)表示;接著將第1步中提取出的佐證拼接起來(lái),同樣使用雙向LSTM更新詞表示。
基于協(xié)同注意力機(jī)制或者兩者互相融合的表示。即在注意力權(quán)重計(jì)算公式中,保持關(guān)鍵字矩陣K、值矩陣V本身表示,將查詢(xún)矩陣Q更換為需要進(jìn)行交互的表示。
以計(jì)算O的方式獲得兩者交互融合的表示E和C后,進(jìn)行求差、求內(nèi)積并拼接的操作,得到信息傳播樹(shù)的表示,最后使用全連接層輸出類(lèi)別標(biāo)簽,并使用交叉熵?fù)p失函數(shù)進(jìn)行訓(xùn)練。
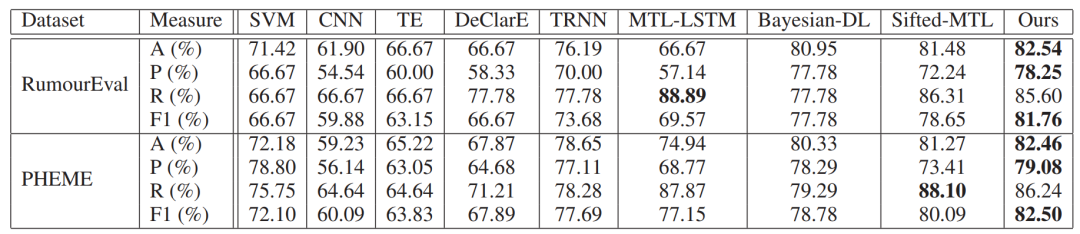
結(jié)果
文章在RumourEval和PHEME數(shù)據(jù)集上進(jìn)行測(cè)試(隨機(jī)劃分訓(xùn)練、驗(yàn)證、測(cè)試集),在大多數(shù)分類(lèi)評(píng)價(jià)指標(biāo)上都優(yōu)于已有模型。
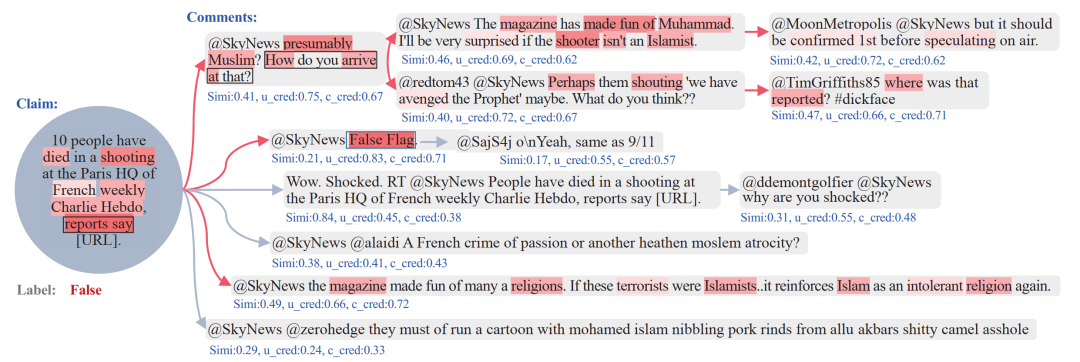
在可解釋性的論證方面,文章抽取出1個(gè)信息傳播樹(shù)的案例,可視化了提出模型的決策過(guò)程。圖中藍(lán)色文本代表決策樹(shù)模型中3個(gè)特征的具體數(shù)值,根據(jù)這些特征篩選出的佐證由紅色箭頭標(biāo)記出來(lái)。同時(shí),不同深色的紅色陰影代表了計(jì)算的協(xié)同注意力權(quán)重,可以看到一些與謠言判別更相關(guān)的事件描述詞。
3

評(píng)估謠言判別模型中的預(yù)測(cè)不確定性
論文動(dòng)機(jī)
在實(shí)際應(yīng)用場(chǎng)景下,謠言判別是極為復(fù)雜的系統(tǒng)性任務(wù),智能化的謠言判別方法還不能完全取代人的細(xì)致全面的判斷,但能縮小人工核查的范圍。如果能更準(zhǔn)確的找出對(duì)于模型難以判別的樣例,再交由人工判斷,將更加優(yōu)化實(shí)際生活中對(duì)謠言的發(fā)現(xiàn)和判別。
另外,由于大多數(shù)模型是基于歷史數(shù)據(jù)進(jìn)行訓(xùn)練的,面對(duì)新產(chǎn)生的突發(fā)事件,模型的泛化能力往往不佳。若能剔除對(duì)整體泛化性能影響較大的訓(xùn)練樣例,則有望進(jìn)一步提升模型對(duì)新事件的泛化能力。
因此,文章借鑒在不確定性衡量方面相關(guān)工作以及主動(dòng)學(xué)習(xí)的實(shí)驗(yàn)設(shè)置,提出了一系列用于衡量數(shù)據(jù)和模型不確定性的指標(biāo),并探索這些指標(biāo)與模型預(yù)測(cè)能力、訓(xùn)練數(shù)據(jù)篩選之間的關(guān)聯(lián)。
方法
文章先基于謠言判別的基線(xiàn)模型獲取可比較的基礎(chǔ)性能,接著計(jì)算不同類(lèi)型的不確定性指標(biāo),并以此剔除訓(xùn)練樣本再次訓(xùn)練,分析基線(xiàn)模型性能變化。
1. 基線(xiàn)模型
基線(xiàn)模型采用在RumourEval 2019任務(wù)上具有不錯(cuò)性能的枝化LSTM模型(branchLSTM),即根據(jù)信息傳播的方向,將每條傳播序列抽取出來(lái),對(duì)每個(gè)序列使用LSTM進(jìn)行表示得到預(yù)測(cè)標(biāo)簽后,再對(duì)所涉及的所有序列結(jié)果進(jìn)行大多數(shù)投票得到傳播樹(shù)的預(yù)測(cè)標(biāo)簽。
2. 不確定性衡量
不確定性可從數(shù)據(jù)和模型兩個(gè)層面進(jìn)行考慮。數(shù)據(jù)的不確定性主要與所訓(xùn)模型的分類(lèi)邊界有關(guān),距離分類(lèi)邊界越近,數(shù)據(jù)層面的不確定性就越高,加入輕微擾動(dòng)則容易使得分類(lèi)結(jié)果轉(zhuǎn)變。模型的不確定性主要與各維表示對(duì)模型分類(lèi)結(jié)果的代表性能相關(guān),若僅保留部分維度的表示,預(yù)測(cè)結(jié)果依然穩(wěn)定,則表明模型的不確定性較低。
在衡量模型不確定性(epistemic uncertainty)時(shí),重復(fù)輸出預(yù)測(cè)結(jié)果前的dropout層N次,由于dropout具有隨機(jī)性,則每次預(yù)測(cè)結(jié)果將有所差異,用以下三個(gè)指標(biāo)進(jìn)行衡量:
變異比(variation ratio),即和主要預(yù)測(cè)類(lèi)別不同的類(lèi)別所占的比例,
熵(entropy),由于預(yù)測(cè)類(lèi)別時(shí)得到的one-hot向量,對(duì)每一維度的概率求熵:
方差(variance),對(duì)于N次dropout的結(jié)果,計(jì)算代表類(lèi)別概率的每一維度的方差,取最大值作為模型不確定衡量指標(biāo)。
3. 數(shù)據(jù)篩選
在獲得每個(gè)樣例的數(shù)據(jù)和模型方面的不確定性數(shù)值指標(biāo)后,通過(guò)非監(jiān)督和監(jiān)督方式舍棄樣本。
非監(jiān)督的舍棄即根據(jù)樣本某一類(lèi)型的不確定性進(jìn)行排序,按一定比例舍棄掉不確定性高的樣本。
監(jiān)督的舍棄即從訓(xùn)練數(shù)據(jù)中再劃分一小部分?jǐn)?shù)據(jù)訓(xùn)練一個(gè)較為簡(jiǎn)單的預(yù)分類(lèi)器(SVM或隨機(jī)森林),輸入特征為各種類(lèi)型的不確定性指標(biāo),原有的one-hot預(yù)測(cè)結(jié)果和真實(shí)標(biāo)簽,分類(lèi)錯(cuò)誤的數(shù)據(jù)則打上被拒絕的標(biāo)簽。由此對(duì)剩下的訓(xùn)練數(shù)據(jù)通過(guò)預(yù)分類(lèi)器判斷是否需要舍棄。監(jiān)督的舍棄方法能盡可能的利用到不同類(lèi)型的不確定性衡量指標(biāo),且舍棄數(shù)目由預(yù)分類(lèi)器給出而不需要人為試驗(yàn)多次。
結(jié)果
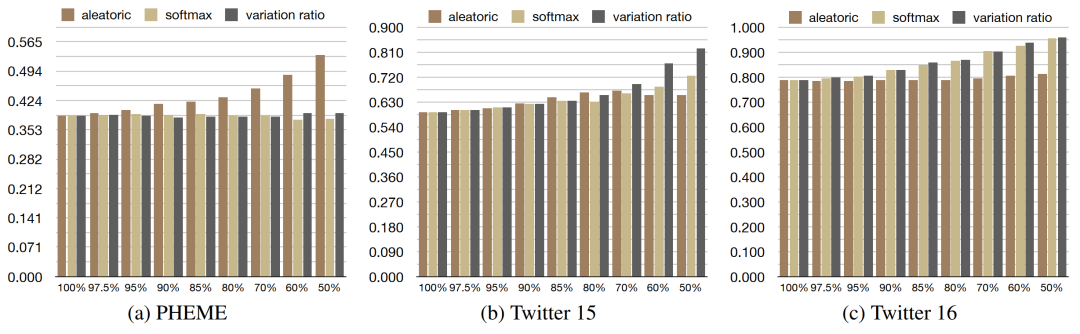
文章在PHEME、Twitter15、Twitter16數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),結(jié)果表明在進(jìn)行了數(shù)據(jù)舍棄后,模型的性能均有提升,尤其采用有監(jiān)督方式的舍棄,提升更為顯著。

在不同數(shù)據(jù)上,根據(jù)不同類(lèi)型不確定性指標(biāo)進(jìn)行非監(jiān)督的數(shù)據(jù)舍棄有明顯差別。由于PHEME數(shù)據(jù)集驗(yàn)證方式為L(zhǎng)OEO,測(cè)試集與驗(yàn)證集語(yǔ)義差距、類(lèi)別比例都較大,因此根據(jù)數(shù)據(jù)不確定性效果提升更為明顯。而Twitter15、Twitter16數(shù)據(jù)集較為均衡,針對(duì)模型不確定性的數(shù)據(jù)舍棄更為有效。
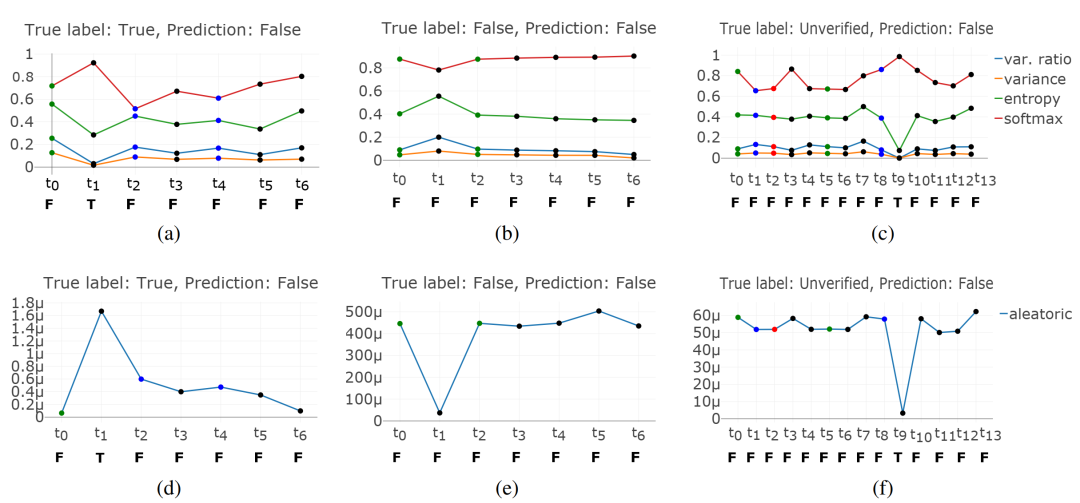
同時(shí)文章借助PHEME數(shù)據(jù)中傳播樹(shù)中部分消息的立場(chǎng)標(biāo)簽,探究了隨時(shí)間變化,不斷增多傳播樹(shù)相關(guān)的討論,模型預(yù)測(cè)結(jié)果和不確定性的變化。圖中展示了3個(gè)真實(shí)標(biāo)簽分別為真實(shí)/虛假/未經(jīng)證實(shí)而預(yù)測(cè)標(biāo)簽均為虛假的樣例,橫軸代表該傳播樹(shù)不同時(shí)刻的消息,橫軸下方的大寫(xiě)字母代表僅將該時(shí)刻前數(shù)據(jù)輸入模型得到的預(yù)測(cè)標(biāo)簽;縱軸表示僅將該時(shí)刻前數(shù)據(jù)輸入模型得到的不確定性的具體數(shù)值,圖中上半部分代表模型不確定性,下半部分代表數(shù)據(jù)不確定性,并且圖中每個(gè)圓點(diǎn)顏色代表不同立場(chǎng)(綠色-支持/紅色-反對(duì)/藍(lán)色-質(zhì)疑/黑色-評(píng)論)。
可以看到,隨著傳播樹(shù)信息的不斷豐富,不確定性指標(biāo)呈現(xiàn)出下降趨勢(shì);觀察每一時(shí)刻的預(yù)測(cè)標(biāo)簽,預(yù)測(cè)結(jié)果和僅利用原始消息差別不多,說(shuō)明在此模型下信源信息對(duì)謠言判別尤為重要。
總結(jié)
以上三篇文章均為社交網(wǎng)絡(luò)謠言判別中可解釋性探索提供了不同的解決思路。其中,協(xié)同注意力機(jī)制的廣泛應(yīng)用能有效的融合不同來(lái)源的信息(如信源和用戶(hù)之間,信源和佐證之間),并定位對(duì)于謠言判別更為關(guān)鍵的部分。另外,對(duì)數(shù)據(jù)和模型不確定性的細(xì)化衡量能使人更加認(rèn)識(shí)數(shù)據(jù)集的內(nèi)置偏差或是模型的自身缺陷。
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25321 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122583 -
cnn
+關(guān)注
關(guān)注
3文章
354瀏覽量
22669
原文標(biāo)題:【論文分享】ACL 2020 社交網(wǎng)絡(luò)謠言判別中可解釋性相關(guān)研究
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
機(jī)器學(xué)習(xí)模型可解釋性的結(jié)果分析
什么是“可解釋的”? 可解釋性AI不能解釋什么
斯坦福探索深度神經(jīng)網(wǎng)絡(luò)可解釋性 決策樹(shù)是關(guān)鍵

機(jī)器學(xué)習(xí)模型的“可解釋性”的概念及其重要意義
神經(jīng)網(wǎng)絡(luò)可解釋性研究的重要性日益凸顯
深度理解神經(jīng)網(wǎng)絡(luò)黑盒子:可驗(yàn)證性和可解釋性
機(jī)器學(xué)習(xí)模型可解釋性的介紹
圖神經(jīng)網(wǎng)絡(luò)的解釋性綜述
《計(jì)算機(jī)研究與發(fā)展》—機(jī)器學(xué)習(xí)的可解釋性

關(guān)于機(jī)器學(xué)習(xí)模型的六大可解釋性技術(shù)
機(jī)器學(xué)習(xí)模型的可解釋性算法詳解
可以提高機(jī)器學(xué)習(xí)模型的可解釋性技術(shù)
文獻(xiàn)綜述:確保人工智能可解釋性和可信度的來(lái)源記錄
云知聲四篇論文入選自然語(yǔ)言處理頂會(huì)ACL 2025

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線(xiàn)
- 接口/總線(xiàn)/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車(chē)電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專(zhuān)欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線(xiàn)研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論