") 應(yīng)用于CNN中卷積運(yùn)算的LUT乘法器設(shè)計(jì)
應(yīng)用于CNN中卷積運(yùn)算的LUT乘法器設(shè)計(jì)
卷積占據(jù)了CNN網(wǎng)絡(luò)中絕大部分運(yùn)算,進(jìn)行乘法運(yùn)算通常都是使用FPGA中的DSP,這樣算力就受到了器件中DSP資源的限制。比如在zynq7000器件中,DSP資源就較少,神經(jīng)網(wǎng)絡(luò)的性能就無法得到提升。利用xilinx器件中LUT的結(jié)構(gòu)特征,設(shè)計(jì)出的乘法器不但能靈活適應(yīng)數(shù)據(jù)位寬,而且能最大限度降低LUT資源使用。
Xilinx ultrascale器件LUT結(jié)構(gòu)
在這里簡要介紹一下ultrascale系列器件中的LUT結(jié)構(gòu),有助于后邊對(duì)乘法器設(shè)計(jì)思路的理解。CLB(configuratble logic block)是主要的資源模塊,其包含了8個(gè)LUT,16個(gè)寄存器,carry邏輯,以及多路選通器等。其中LUT可以用作6輸入1輸出,或者兩個(gè)5輸入LUT,但是這兩個(gè)LUT公用輸入,具有不同輸出。每個(gè)LUT輸出可以連接到寄存器或者鎖存器,或者從CLB輸出。LUT可以用于64x1和32X2的分布式RAM,一個(gè)CLB內(nèi)最大可以支持512X1大小的RAM。RAM的讀寫地址和輸入的讀寫數(shù)據(jù)是共享的,數(shù)據(jù)通道可以使用x和I接口。LUT還可以配置用于4:1選通器,CLB最大能夠支持到32:1的選通器。CLB中的carry邏輯含有異或門和產(chǎn)生進(jìn)位的門,用于生成進(jìn)位數(shù)據(jù)。

圖1.1 LUT結(jié)構(gòu)
LUT還可以被動(dòng)態(tài)配置成32bit移位寄存器,這個(gè)功能在乘法器設(shè)計(jì)中可以用于改變乘法器的乘數(shù)和被乘數(shù)。在寫入LUT數(shù)據(jù)的時(shí)候,每個(gè)時(shí)鐘周期從D接口進(jìn)入數(shù)據(jù),依次寫入32bit數(shù)據(jù)。讀數(shù)據(jù)的時(shí)候,可以通過地址來定位任何32bit中的數(shù)據(jù)。這樣就可以配置成任何小于32bit的移位寄存器。移位輸出Q31可以進(jìn)入下一級(jí)LUT用于串聯(lián)產(chǎn)生更大移位寄存器。在一個(gè)CLB中最大可以串聯(lián)產(chǎn)生256bit移位寄存器。
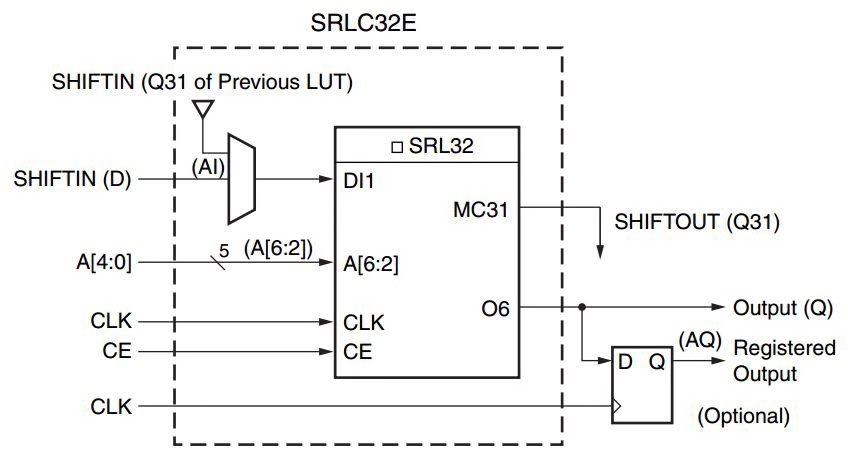
圖1.2 移位寄存器配置
LUT乘法器原理
首先假設(shè)我們處理整數(shù)乘法,小數(shù)乘法也可以用這樣的方法。基本思想就是將m bit大小的數(shù)據(jù)進(jìn)行分割表示:

這樣就將兩個(gè)數(shù)據(jù)乘法分解成低bit數(shù)據(jù)乘法,結(jié)果是一個(gè)常數(shù)K和di相乘,然后再進(jìn)行移位求和。M bit數(shù)據(jù)分解后的低bit數(shù)據(jù)位寬通常都適配LUT輸入寬度,這樣能最大利用LUT資源。現(xiàn)在乘法只有K*di,由于bit位寬較小,這部分可以用LUT查找表的形式來。預(yù)先將0K到(2^q-1)K的數(shù)據(jù)存儲(chǔ)到LUT中,然后通過di來選擇對(duì)應(yīng)的數(shù)據(jù)。如果是負(fù)數(shù)乘法,那么數(shù)據(jù)使用補(bǔ)碼表示,那么LUT中存儲(chǔ)的數(shù)據(jù)是從-2^(q-1)K到(2^(q-1)-1)K。針對(duì)以上介紹的ultrascale器件的LUT6,q可以選擇為5。但是在本論文中使用的是LUT4器件,其只有4輸入,因此選擇了q=3,為什么沒有選擇4呢?另外1bit是為了用于半加器的實(shí)現(xiàn)。
基本結(jié)構(gòu)
實(shí)現(xiàn)上述累加的方法有很多種,論文中采用了進(jìn)位鏈加法器。圖2.1中是m bit和n bit數(shù)據(jù)乘法,每個(gè)E結(jié)構(gòu)計(jì)算di*K,并且和上一個(gè)結(jié)構(gòu)求和,輸出的低3bit直接作為最終結(jié)果,而n bit傳輸?shù)较乱患?jí)進(jìn)行計(jì)算。q=3的計(jì)算單元E有[m/3]個(gè)。K*di是有n+3bit的查找表實(shí)現(xiàn)的。查找表的結(jié)果由di選擇,然后再通過一個(gè)求和器和之前數(shù)據(jù)求和。這是一個(gè)最基本的結(jié)構(gòu),論文又針對(duì)這個(gè)結(jié)構(gòu)做了優(yōu)化,用一個(gè)LUT同時(shí)實(shí)現(xiàn)了一個(gè)查找表和半加器。具體來講,其中3bit輸入用于di,還有1bit用于上一次輸出,LUT中存放數(shù)據(jù)是di*K和上一次結(jié)果第j bit的半加結(jié)果,實(shí)際上是第j bit數(shù)據(jù)LUT中結(jié)果的異或。而進(jìn)位數(shù)據(jù)由CLB中相應(yīng)的carry邏輯來計(jì)算。相比于粗暴的進(jìn)行數(shù)據(jù)求和,這樣精確的來控制LUT能夠大大節(jié)省資源。
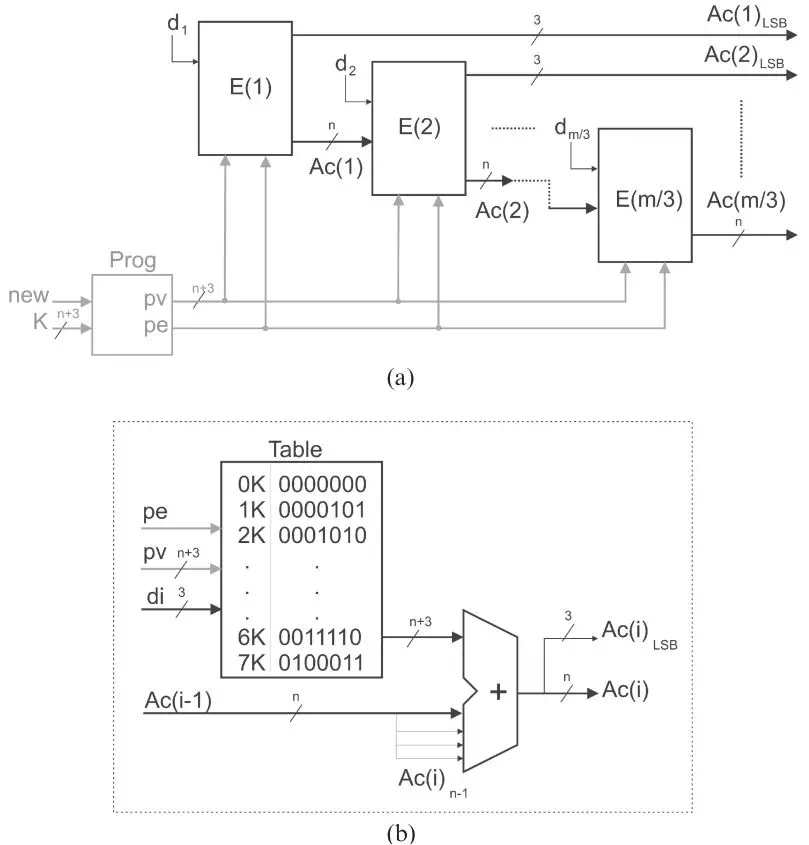
圖2.1 基本結(jié)構(gòu)
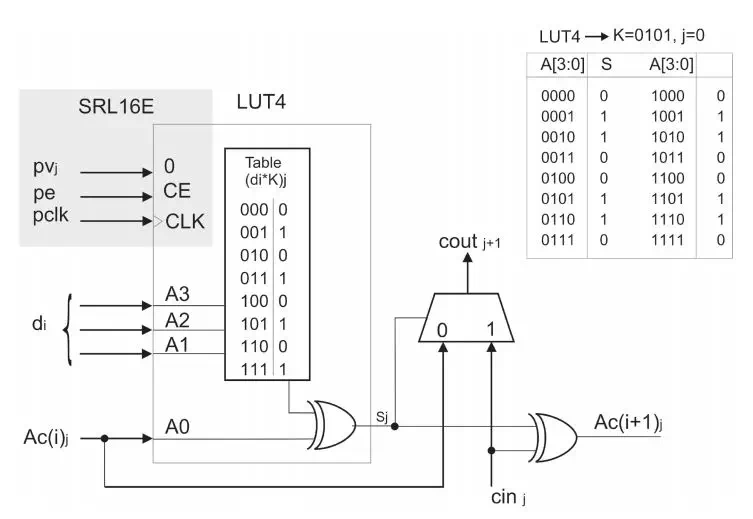
圖2.2 LUT實(shí)現(xiàn)乘法和半加,外圍carry邏輯實(shí)現(xiàn)進(jìn)位
動(dòng)態(tài)配置LUT內(nèi)容
Xilinx的LUT結(jié)構(gòu)允許在運(yùn)行過程中改變LUT中的內(nèi)容,這樣的乘法器就能改變被乘數(shù)據(jù)K。這可以實(shí)現(xiàn)在神經(jīng)網(wǎng)絡(luò)計(jì)算中需要更新權(quán)重參數(shù)。論文中使用的是LUT4,所以一個(gè)LUT可以被配置成16bit移位寄存器。通過這16bit寄存器可以來配置LUT中的內(nèi)容,每個(gè)時(shí)鐘周期更新1bit數(shù)據(jù),16個(gè)時(shí)鐘周期可以完成一個(gè)LUT中數(shù)據(jù)更新。是否進(jìn)行LUT內(nèi)容更新通過CE使能信號(hào)控制。
如何產(chǎn)生LUT中數(shù)據(jù)的值呢?如果上一次輸出數(shù)據(jù)對(duì)應(yīng)bit為0,那么LUT中就存放0*K到7*K的值,如果上一次對(duì)應(yīng)bit為1,那么存放值為對(duì)以上數(shù)據(jù)取反。圖4.1表示了獲得LUT中內(nèi)容的電路圖。首先數(shù)據(jù)被初始化為0*K,下一次對(duì)應(yīng)著求和進(jìn)位為1的情況,取反,然后再加K得到1*K的值,這樣每隔兩個(gè)時(shí)鐘周期就得到下一個(gè)乘法的數(shù)據(jù)值,依次對(duì)LUT進(jìn)行更新。上述中針對(duì)的是正整數(shù),如果對(duì)于負(fù)數(shù)乘法更新,可以在上述求整數(shù)乘法的電路基礎(chǔ)上做一下改進(jìn),如圖4.2。當(dāng)最高位為0的時(shí)候,輸出結(jié)果就是之前求得的乘法結(jié)果。如果最高位是1,那么負(fù)數(shù)的補(bǔ)碼表示是乘法的原碼結(jié)果減去最高位數(shù)值。
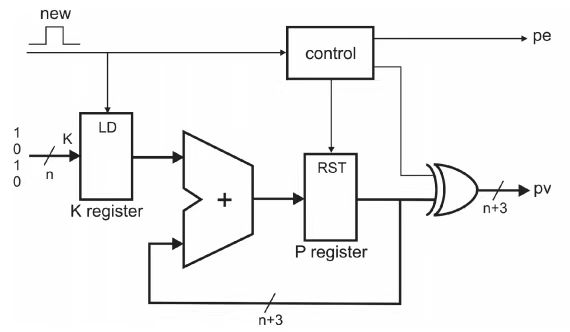
圖4.1 LUT中內(nèi)容更新電路圖
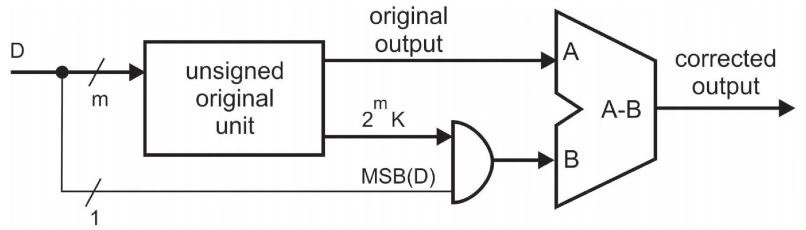
圖4.2 負(fù)數(shù)乘法結(jié)果更新電路
結(jié)果分析
最后我們來看看這種乘法器的實(shí)現(xiàn)效果,圖5.1表示對(duì)多級(jí)進(jìn)位不適用pipeline結(jié)構(gòu)的時(shí)鐘頻率隨著被乘數(shù)K位寬變化,可以看到隨著級(jí)數(shù)E的增加,頻率降低很多,這主要是進(jìn)位鏈邊長導(dǎo)致。而隨著K位寬增加,頻率也有降低,這主要是因?yàn)閷?shí)現(xiàn)di*K乘法的LUT資源增加導(dǎo)致。
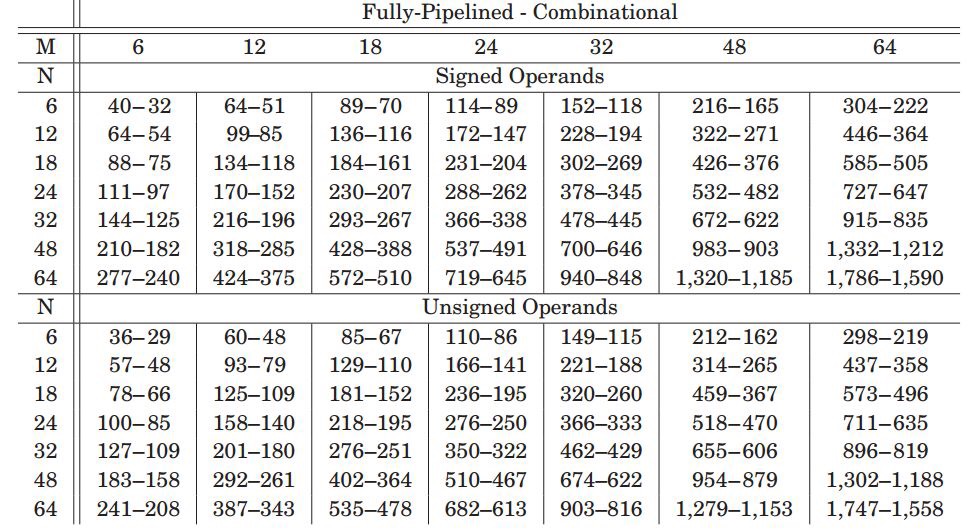
圖5.1 沒有pipeline下頻率MHz
圖5.2是不同乘法位寬下的使用slice數(shù)量。論文中考慮了兩種極端情況,一種是完全pipeline下,即每級(jí)計(jì)算單元都經(jīng)過寄存器,另外一種是完全沒有pipeline,所有級(jí)E都是串聯(lián)。
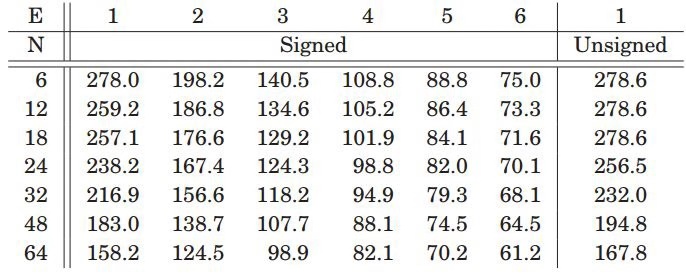
圖5.2 slice資源
結(jié)論
上述通過LUT來設(shè)計(jì)乘法器的方法,可以應(yīng)用于CNN中的卷積運(yùn)算當(dāng)中,因?yàn)闄?quán)重可以被當(dāng)做被乘數(shù),用于LUT內(nèi)容的配置,在更換權(quán)重時(shí),可以對(duì)LUT內(nèi)容更新,這樣就能避免了DSP資源的限制,不失為一種增加算力的方法。
文獻(xiàn)
1. Hormigo, J.C., Gabriel Oliver, Juan P.Boemo, Eduardo, Self-Reconfigurable Constant Multiplier for FPGA. ACM Transactions on Reconfigurable Technology and Systems, 2013. 6
編輯:hfy
-
dsp
+關(guān)注
關(guān)注
556文章
8148瀏覽量
355586 -
FPGA
+關(guān)注
關(guān)注
1643文章
21983瀏覽量
614741 -
寄存器
+關(guān)注
關(guān)注
31文章
5425瀏覽量
123574 -
cnn
+關(guān)注
關(guān)注
3文章
354瀏覽量
22659
發(fā)布評(píng)論請(qǐng)先 登錄
ADL5390 RF矢量乘法器技術(shù)手冊(cè)
ADA-28F00WG乘法器Marki
求助,LMX2572LP參考時(shí)鐘路徑中的乘法器MULT的輸入頻率范圍問題求解
MPY634做基本乘法器遇到的疑問求解
請(qǐng)問如何用VCA810實(shí)現(xiàn)模擬乘法器?
請(qǐng)問VCA822做成四象限乘法器的帶寬是多少?
CDCS504-Q1時(shí)鐘緩沖器和時(shí)鐘乘法器數(shù)據(jù)表

CDCVF25084時(shí)鐘乘法器數(shù)據(jù)表
CDCF5801A具有延遲控制和相位對(duì)準(zhǔn)的時(shí)鐘乘法器數(shù)據(jù)表
CDCF5801時(shí)鐘乘法器數(shù)據(jù)表
CDCE906 PLL頻率合成器/乘法器/分頻器數(shù)據(jù)表
CDCS503帶可選SSC的時(shí)鐘緩沖器/時(shí)鐘乘法器數(shù)據(jù)表





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論