 DAC快速目標檢測算法優化和架構設計優化方案
DAC快速目標檢測算法優化和架構設計優化方案
1. 需求分析
1.1 背景
Design Automation Conference 自動設計大會是全球久負盛譽的產學研交流盛會,也是計算機學會推薦的A類會議之一。2019年第56屆DAC大會在拉斯維加斯舉行。其中系統設計競賽(System Design Contest, SDC)的任務為面向端側設備進行快速的目標檢測。該比賽由Xilinx、大疆和英偉達贊助。該比賽針對比賽方給定無人機視角的訓練數據集(9萬張分辨率為360x640的圖片,單目標標注)進行訓練,在比賽方自有的5萬張測試數據集上進行測試。最終檢測精度IoU(Intersection over Union)高、且能量消耗低者勝出。
2018年該比賽第一次舉行,當時提供了Pynq第一代平臺(Zynq7020),由清華大學汪玉教授團隊的曾書霖博士獲得了全球第一名。2019比賽繼續進行,Xilinx將平臺升級到了支持Pynq框架的Ultra96,該平臺搭載了Xilinx UltraScale+ ZU3器件。另一個賽道提供了Nivida的TX2。Ultra96是一款優秀的Xilinx ZYNQ的開發板。其PS側搭載四核ARM Cortex-A53 CPU,主頻為1.5GHz;軟件方面可以使用基于Python的PYNQ框架進行開發。Ultra96平臺以及ZU3的PL側資源如下圖所示。
1.2 動機
為了達到檢測精度與能耗的平衡,我們團隊選擇并優化了面向端側的輕量級神經網絡框架。并針對ZU3的資源限制,精簡了我們團隊設計的一個可以支持通用網絡的DNN加速器(HiPU),將其部署在ZU3的PL側。主要工作分為針對硬件平臺的算法優化和架構設計優化兩部分:
算法上的優化主要有:
1) 選擇ShuffleNet V2作為特征提取的主框架;
2) 選擇YOLO作為單目標位置的回歸框架;
3) 對神經網絡進行8bit量化。
HiPU的優化主要有:
1) 支持CONV,FC,Dep-wise CONV,Pooling,Ele-wise Add/Mul等操作,峰值算力為268Gops,效率大于80%;
2) 支持Channel shuffle、divide、concat操作,且不消耗額外時間;
4) HiPU完全由PL側實現,不依賴PS側。PS主要工作負載為圖片預處理和結果輸出上。
經過上述優化,我們團隊的設計在比賽方的數據集上測得如下結果:準確率IoU為61.5%;能耗為9537J,幀率為50.91Hz,功率為9.248W。
2. 算法框架設計
2.1 任務分析
本次競賽的訓練集由大疆提供,部分圖片如下圖所示。在確定算法之前,我們團隊首先對訓練數據集的特點進行了分析:
1) 圖片尺寸均為360x640,不需要對圖片進行resize操作進行歸一化;
2) 所有測試圖片均是無人機視角。標定框的大小從36像素到7200像素不等,算法需要支持各種大小的目標檢測;
3) 所有圖片共12大類(95個子類),包括boat (7), building (3), car (24), drone (4), group (2), horse-ride(1), paraglider(1), person (29), riding (17), truck (2), wakeboard(4), whale(1)類別。算法在設計時需要對這12類物體進行分類;
4) 即使測試圖片中出現多個相似的目標,標定框也是指定固定的一個目標。即訓練時需要適當的過擬合。

圖 2 訓練集的部分圖片
2.2 單目標檢測網絡選擇
為滿足移動端的檢測實時性,我們團隊最終選定了YOLO作為基礎檢測算法。并將其中的特征提取網絡替換為輕量級的ShuffleNet V2,其參數規模略大于1X。如下圖所示為我們定制的單目標檢測網絡,ShuffleDet。
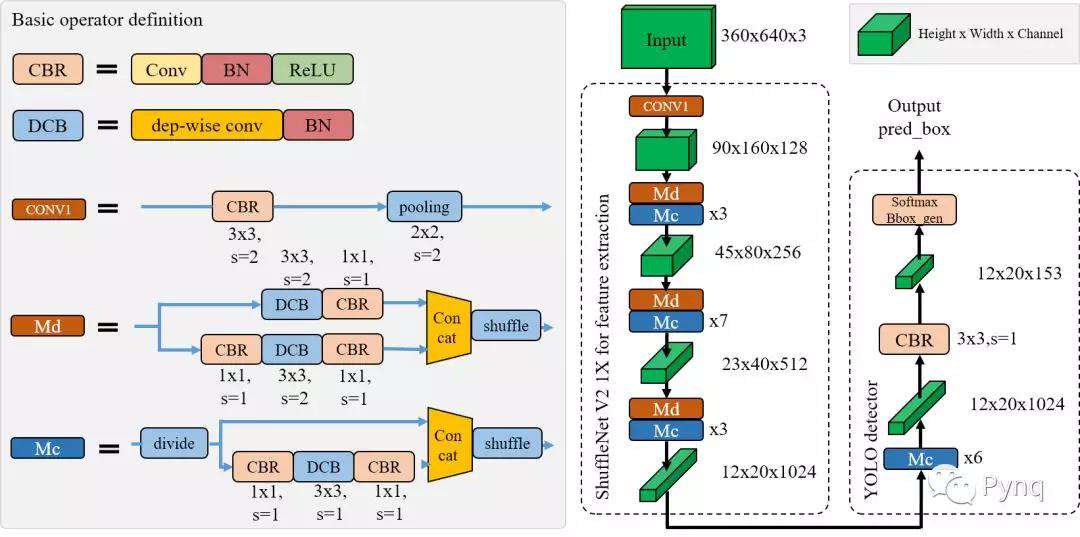
圖 3 ShuffleDet的網絡結構示意圖
2.3 神經網絡的訓練與量化
我們團隊首先在ImageNet數據集上預訓練一個標準的ShuffleNet V2分類網絡。待模型收斂后,將其中的特征提取部分的參數遷移到ShuffleDet網絡中。使用比賽方的訓練集進行其他層的參數的訓練。
為了適應FPGA的定點運算,待整體參數訓練完成后,需要對所有參數進行量化操作。我們團隊將網絡參數和feature map均量化為8bit定點。
量化過程主要分為以下幾步:
1) 將BN層合并到參數中;
2) 將合并后的參數進行對稱量化;
3) 量化后的參數如果直接使用,精度損失過于嚴重。因此量化后還需要對參數進行fine tune。
如下圖所示為量化操作的示意圖。
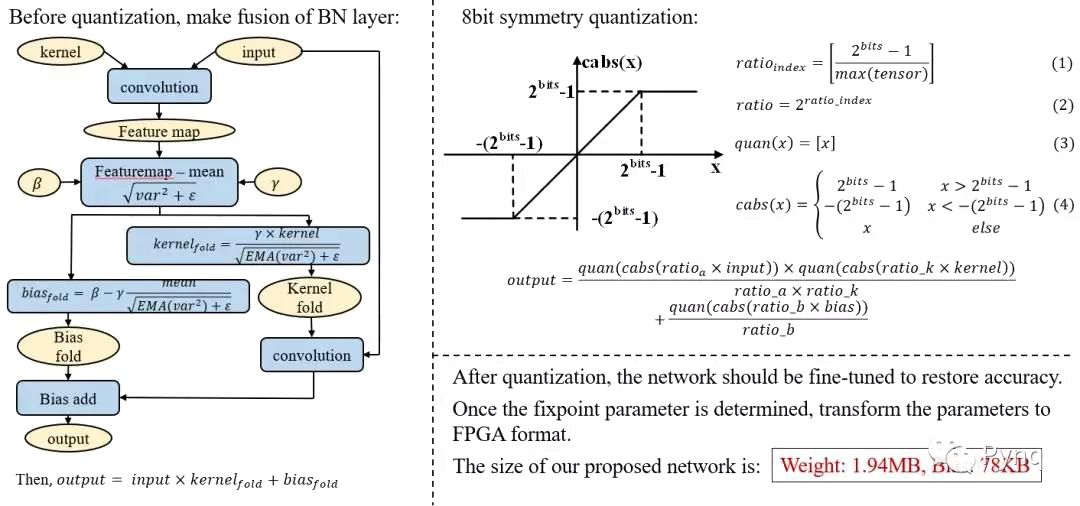
圖 4 網絡參數的量化流程
經過量化后,我們使用的ShuffleDet網絡的卷積層數約為74層,權重約為1.94MB,Bias約為78KB。
3. 計算架構框架設計
3.1 HiPU整體介紹
針對賽方提供的計算平臺,我們進行適當的裁剪,以適應ZU3的資源。如下圖所示為裁剪后的HiPU設計框圖,及其特性。HiPU工作在233MHz,其峰值算力為268Gops;采用C/RISC-V匯編作為編程接口,卷積效率平均在80%以上。
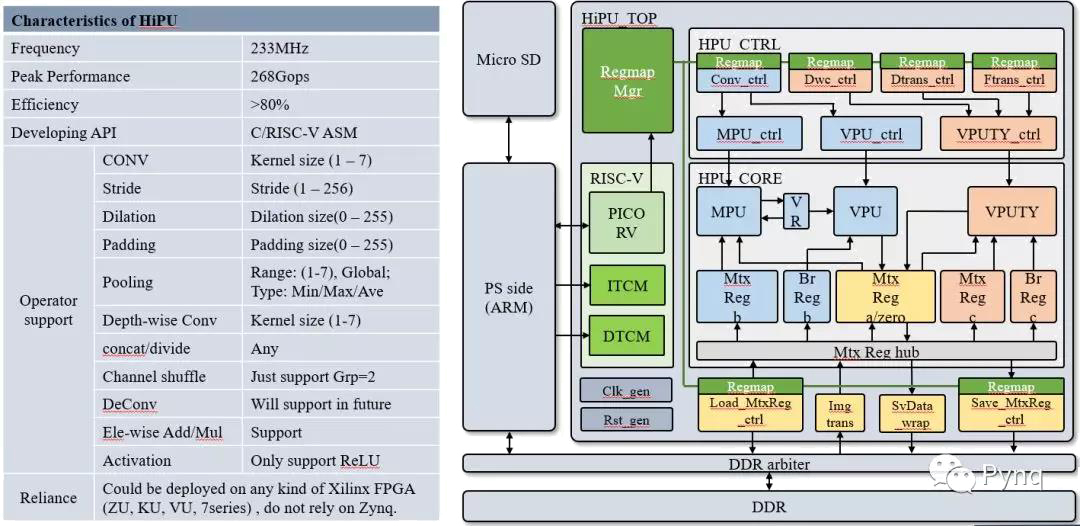
圖 5 HiPU的結構框圖與特性
HiPU支持各種常見的NN運算,包括:CONV,FC,Dep-wise CONV,Pooling,Ele-wise Add/Mul等運算。其中FC也可以做到接近100%的計算效率。
HiPU支持channel方向的shuffle,divide,concat操作。當這些操作緊接在卷積運算之后時,可以在硬件上進行合并,不消耗額外的時間。
HiPU可以工作在任何種類的Xilinx FPGA上,不受Zynq架構的限制。
HiPU底層實現矩陣運算,向量運算,以及標量運算。在做好調度的情況下,可以支持任意類型的并行計算。未來將實現稀疏矩陣運算的優化,從而支持高效率的DeCONV運算,feature map稀疏優化。
3.2 HiPU優化點分析
1) 通過層間級聯減少所需的DDR帶寬
HiPU設計性能有兩個重要的方面:一個方面是MAC運算單元的利用率;一個是數據傳輸網絡是否可以匹配MAC所需的數據。其中數據傳輸網絡的限制大多數來自DDR接口。本設計針對DDR接口進行專門的優化。
由于HiPU中SRAM的大小限制,無法將一層feature map的數據完全放在HiPU的SRAM中。采用平常的計算次序則需要將每一層的feature map計算結果返回到DDR中存儲。這樣一來每一層的feature map數據都需要一次DDR的訪問,對DDR的帶寬需求非常大,也會消耗額外的功耗
我們團隊通過層間級聯的方式降低DDR的帶寬需求。以ShuffleNet的bottleneck為分界,從每個bottleneck的輸入處從DDR讀取一行feature map,依次計算完所有的層后,輸出的一行feature map才寫回到DDR。依次計算完所有行。如下圖所示為Module C的層間級聯計算次序。
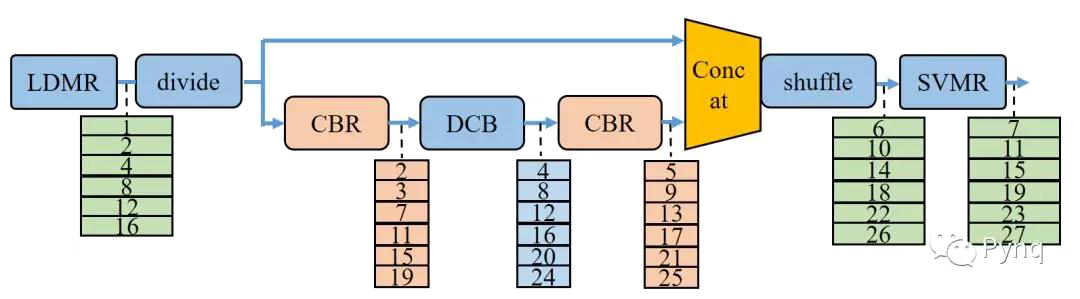
圖 6 Module-C采用層間級聯計算方式
2) 輸入圖像格式轉換以提升處理效率
HiPU一次并行計算8個輸入channel。然而網絡第一層輸入圖像僅有RGB這3個通道,導致HiPU計算效率僅為3/8。因此,我們團隊針對輸入圖像設計了一個轉換模塊。如果Conv1的kernel的width為3,則將輸入圖像的通道從3擴展到9。最終使得第一層的處理效率從0.38提升到了0.56,其轉換示意圖如下圖所示。
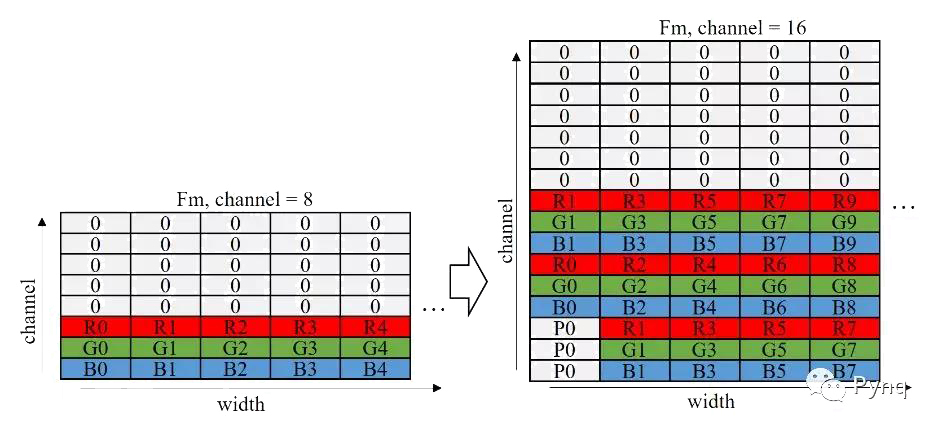
圖 7 輸入圖像在行方向上的轉換
3.3 系統優化設計
1) 圖像解碼與卷積神經網絡計算并行化
由于HiPU僅僅依賴Zynq的PL側的資源進行設計,PS側的資源可以空出來做系統IO相關的工作。我們團隊在處理當前圖片的檢測運算時,在PS側預讀并解碼下一幅圖片,提高處理的并行度,從而使整體檢測幀率從30.3Hz提高到50.9Hz。
如下圖所示為圖像解碼與卷積神經網絡并行化的示意圖。

(a) 并行化之前的工作流程
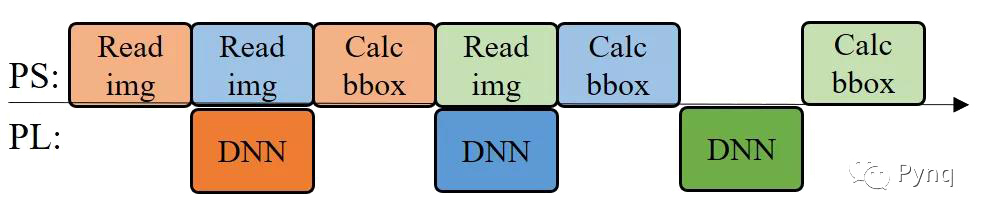
(b) 并行化之后的工作流程 圖 8 圖像解碼與卷積神經網絡并行化的示意圖
2) 使用C代碼加速PS側原來的Python代碼
使用C代碼重構PS側比較耗時的操作,并在Pynq框架中采用ctypes接口調用重構的C代碼:
① 預先計算PL側數據中置信度和bbox坐標的地址指針;
② 找到最大的置信度和對應的BBox的坐標,然后根據相對坐標計算出絕對坐標;
3) 使用門控時鐘降低PL側的能耗
為了降低系統的能量消耗,設計了門控時鐘策略。當HiPU計算完一張圖片的時候自動關閉時鐘,下一張圖片開始計算的時候再激活時鐘。設置這個策略主要基于以下兩個原因:
首先,系統對jpg格式圖片解算的時間不固定,當SD卡型號不固定的時候,其均值在7ms-12ms之間,部分圖片解算時間最大值可以到達100ms;
其次,系統的功耗測量進程和其他額外開銷會占用一部分的cpu時間,并且PS和PL共享DDR帶寬,這導致了HiPU在166Mhz的時幀率到達約50hz,但是升高HiPU到200Mhz時,系統處理幀率仍然保持在50hz左右。
上述兩個原因會導致HiPU處理時間和圖片jpeg解算時間匹配變得不固定;當HiPU處理圖像時間比圖像解算時間短時, HiPU會“空跑”浪費能量。另外,針對搶占DDR帶寬的情況,還需繼續優化。
4. 競賽結果分析
如下表所示為DAC19的競賽結果,全球共有58支隊伍注冊了FPGA比賽任務。最終我們團隊獲得了第2名的成績。冠軍為iSmart3,由UIUC、IBM、Inspirit IoT公司聯合組隊,季軍為SystemsETHZ來自ETH Zurich的隊伍。通過與其他團隊的交流,我們團隊使用的神經網絡規模是最大的,優勢是高性能的DNN加速器,遺憾是算法方面的優化還不到位,最終競賽成績如下:
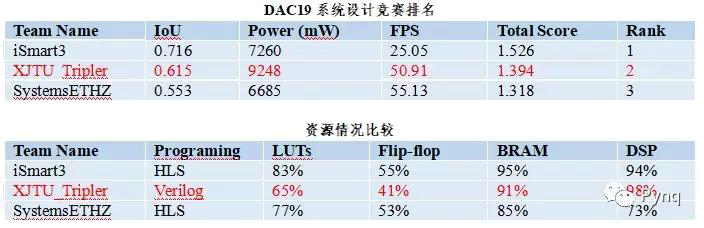
我們設計的ShuffleDet算法同時在TX2平臺上也進行了部署,下表是兩者的分析對比。可以看出8bits量化后造成了0.056的IoU損失(-8.3%),但帶來了28.87的幀率提升(+131%)和8309J的能量減少(-46.56%)。
XJTU-Tripler是由西安交通大學 人工智能與機器人研究所 任鵬舉副教授所在的認知計算架構小組完成的設計。
團隊成員:趙博然,趙文哲,夏天,陳飛,樊瓏,宗鵬陳,魏亞東,涂志俊,趙之旭,董志偉等
編輯:hfy
-
機器人
+關注
關注
211文章
28745瀏覽量
208872 -
Xilinx
+關注
關注
71文章
2172瀏覽量
122323 -
人工智能
+關注
關注
1797文章
47867瀏覽量
240781
發布評論請先 登錄
相關推薦
人臉檢測算法及新的快速算法
汽車電子電氣架構設計及優化措施
雷達目標檢測算法研究及優化
雷達目標檢測算法研究及優化
PowerPC小目標檢測算法怎么實現?
【HarmonyOS HiSpark AI Camera】基于深度學習的目標檢測系統設計
多目標優化算法有哪些
分享一款高速人臉檢測算法
基于YOLOX目標檢測算法的改進
基于閾值優化的圖像模糊邊緣檢測算法


基于Transformer的目標檢測算法






 工商網監
工商網監
評論