") 基于UniSpeech芯片和語音識別算法實現(xiàn)嵌入式語音識別系統(tǒng)的設計
基于UniSpeech芯片和語音識別算法實現(xiàn)嵌入式語音識別系統(tǒng)的設計
介紹語音識別技術在嵌入式系統(tǒng)中的應用狀況與發(fā)展,以及在嵌入式系統(tǒng)中使用HMM語音識別算法的優(yōu)點,并對基于HMM語音識別技術的系統(tǒng)進行介紹。
語音識別ASR(Automatic Speech Recognition)系統(tǒng)的實用化研究是近十年語音識別研究的一個主要方向。近年來,消費類電子產(chǎn)品對低成本、高穩(wěn)健性的語音識別片上系統(tǒng)的需求快速增加,語音識別系統(tǒng)大量地從實驗室的PC平臺轉移到嵌入式設備中。
語音識別技術目前在嵌入式系統(tǒng)中的應用主要為語音命令控制,它使得原本需要手工操作的工作用語音就可以方便地完成。語音命令控制可廣泛用于家電語音遙控、玩具、智能儀器及移動電話等便攜設備中。使用語音作為人機交互的途徑對于使用者來說是最自然的一種方式,同時設備的小型化也要求省略鍵盤以節(jié)省體積。
嵌入式設備通常針對特定應用而設計,只需要對幾十個詞的命令進行識別,屬于小詞匯量語音識別系統(tǒng)。因此在語音識別技術的要求不在于大詞匯量和連續(xù)語音識別,而在于識別的準確性與穩(wěn)健性。
對于嵌入式系統(tǒng)而言,還有許多其它因素需要考慮。首先是成本,由于成本的限制,一般使用定點DSP,有時甚至只能考慮使用MPU,這意味著算法的復雜度受到限制;其次,嵌入式系統(tǒng)對體積有嚴格的限制,這就需要一個高度集成的硬件平臺,因此,SoC(System on Chip)開始在語音識別領域嶄露頭角。SoC結構的嵌入式系統(tǒng)大大減少了芯片數(shù)量,能夠提供高集成度和相對低成本的解決方案,同時也使得系統(tǒng)的可靠性大為提高。
語音識別片上系統(tǒng)是系統(tǒng)級的集成芯片。它不只是把功能復雜的若干個數(shù)字邏輯電路放入同一個芯片,做成一個完整的單片數(shù)字系統(tǒng),而且在芯片中還應包括其它類型的電子功能器件,如模擬器件(如ADC/DAC)和存儲器。
使用SoC芯片實現(xiàn)了一個穩(wěn)定、可靠、高性能的嵌入式語音識別系統(tǒng)。包括一套全定點的DHMM和CHMM嵌入式語音識別算法和硬件系統(tǒng)。
1 硬件平臺
本識別系統(tǒng)是在與Infineon公司合作開發(fā)的芯片UniSpeech上實現(xiàn)的。UniSpeech芯片是為語音信號處理開發(fā)的專用芯片,采用0.18μm工藝生產(chǎn)。它將雙核(DSP+MCU)、存儲器、模擬處理單元(ADC與DAC)集成在一個芯片中,構成了一種語音處理SoC芯片。這種芯片的設計思想主要是為語音識別和語音壓縮編碼領域提供一個低成本、高可靠性的硬件平臺。
該芯片為語音識別算法提供了相應的存儲量和運算能力。包括一個內(nèi)存控制單元MMU(Memory Management Unit)和104KB的片上RAM。其DSP核為16位定點DSP,運算速度可達到約100MIPS.MCU核是8位增強型8051,每兩個時鐘周期為一個指令周期,其時鐘頻率可達到50MHz。
UniSpeech芯片集成了2路8kHz采樣12bit精度的ADC和2路8kHz采樣11bit的DAC,采樣后的數(shù)據(jù)在芯片內(nèi)部均按16bit格式保存和處理。對于語音識別領域,這樣精度的ADC/DAC已經(jīng)可以滿足應用。ADC/DAC既可以由MCU核控制,也可以由DSP核控制。
2 嵌入式語音識別系統(tǒng)比較
以下就目前基于整詞模型的語音識別的主要技術作一比較。
(1)基于DTW(Dynamic Time Warping)和模擬匹配技術的語音識別系統(tǒng)。目前,許多移動電話可以提供簡單的語音識別功能,幾乎都是甚至DTM和模板匹配技術。
DTW和模板匹配技術直接利用提取的語音特征作為模板,能較好地實現(xiàn)孤立詞識別。由于DTW模版匹配的運算量不大,并且限于小詞表,一般的應用領域孤立數(shù)碼、簡單命令集、地名或人名集的語音識別。為減少運算量大多數(shù)使用的特征是LPCC(Linear Predictive Cepstrum Coefficient)運算。
DTW和模板匹配技術的缺點是只對特定人語音識別有較好的識別性能,并且在使用前需要對所有詞條進行訓練。這一應用從20世紀90年代就進入成熟期。目前的努力方向是進一步降低成本、提高穩(wěn)健性(采用雙模板)和抗噪性能。
(2)基于隱含馬爾科夫模型HMM(Hidden Markov Model)的識別算法。這是Rabiner等人在20世紀80年代引入語音識別領域的一種語音識別算法。該算法通過對大量語音數(shù)據(jù)進行數(shù)據(jù)統(tǒng)計,建立識別條的統(tǒng)計模型,然后從待識別語音中提取特征,與這些模型匹配,通過比較匹配分數(shù)以獲得識別結果。通過大量的語音,就能夠獲得一個穩(wěn)健的統(tǒng)計模型,能夠適應實際語音中的各種突發(fā)情況。因此,HMM算法具有良好的識別性能和抗噪性能。
基于HMM技術的識別系統(tǒng)可用于非特定人,不需要用戶事先訓練。它的缺點在于統(tǒng)計模型的建立需要依賴一個較大的語音庫。這在實際工作中占有很大的工作量。且模型所需要的存儲量和匹配計算(包括特征矢量的輸出概率計算)的運算量相對較大,通常需要具有一定容量SRAM的DSP才能完成。
在嵌入式語音識別系統(tǒng)中,由于成本和算法復雜度的限制,HMM算法特別CHMM(Continuous density HMM)算法尚未得到廣泛的應用。
(3)人工神經(jīng)網(wǎng)絡ANN(Artificial Neural Network)。ANN在語音識別領域的應用是在20世紀80年代中后期發(fā)展起來的。其思想是用大量簡單的處理單元并行連接構成一種信息處理系統(tǒng)。這種系統(tǒng)可以進行自我更新,且有高度的并行處理及容錯能力,因而在認知任務中非常吸引人。但是ANN相對于模式匹配而言,在反映語音的動態(tài)特性上存在重大缺陷。單獨使用ANN的系統(tǒng)識別性能不高,所以目前ANN通常在多階段識別中與HMM算法配合使用。
3 基于HMM的語音識別系統(tǒng)
下面詳細介紹基于HMM的語音識別系統(tǒng)。首先在UniSpeech芯片上實現(xiàn)了基于DHMM的識別系統(tǒng),然后又在同一平臺上實現(xiàn)了基于CHMM的識別系統(tǒng)。
3.1 前端處理
語音的前端處理主要包括對語音的采樣、A/D變換、分幀、特片提取和端點檢測。
模擬語音信號的數(shù)字化由A/D變換器實現(xiàn)。ADC集成在片內(nèi),它的采樣頻率固定為8kHz。
特征提取基于語音幀,即將語音信號分為有重疊的若干幀,對每一幀提取一次語音特片。由于語音特征的短時平穩(wěn)性,幀長一般選取20ms左右。在分幀時,前一幀和后一幀的一部分是重疊的,用來體現(xiàn)相鄰兩幀數(shù)據(jù)之間的相關性,通常幀移為幀長的1/2。對于本片上系統(tǒng),為了方便做FFT,采用的幀長為256點(32ms),幀移為128點(16ms)。
特征的選擇需要綜合考慮存儲量的限制和識別性能的要求。在DHMM系統(tǒng)中,使用24維特征矢量,包括12維MFCC(Mel Frequency Cepstrum Coefficient)和12維一階差分MFCC;在CHMM系統(tǒng)中,在DHMM系統(tǒng)的基礎上增加了歸一化能量、一階差分能量和二階差分能量3維特征,構成27維特征矢量。對MFCC和能量分別使用了倒譜均值減CMS(Cepstrum Mean Subtraction)和能量歸一化ENM(Energy Normalization)的處理方法提高特征的穩(wěn)健性。
3.2 聲學模型
在HMM模型中,首先定義了一系列有限的狀態(tài)S1…SN,系統(tǒng)在每一個離散時刻n只能處在這些狀態(tài)當中的某一個Xn。在時間起點n=0時刻,系統(tǒng)依初始概率矢量π處在某一個狀態(tài)中,即:
πi=P{X0=Si},i=1..N
以后的每一個時刻n,系統(tǒng)所處的狀態(tài)Xn僅與前一時刻系統(tǒng)的狀態(tài)有關,并且依轉移概率矩陣A跳轉,即:
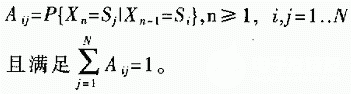
系統(tǒng)在任何時刻n所處的狀態(tài)Xn隱藏在系統(tǒng)內(nèi)部,并不為外界所見,外界只能得到系統(tǒng)在該狀態(tài)下提供的一個Rq空間隨機觀察矢量On。On的分布B稱為輸出概率矩陣,只取決于Xn所處狀態(tài):
Pxn=Si{On}=P{On|Si}
因為該系統(tǒng)的狀態(tài)不為外界所見,因此稱之為“穩(wěn)含馬爾科夫模型”,簡稱HMM。
在識別中使用的隨機觀察矢量就是從信號中提取的特征矢量。按照隨機矢量Qn的概率分布形時,其概率密度函數(shù)一般使用混合高斯分布擬合。
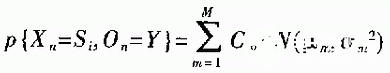
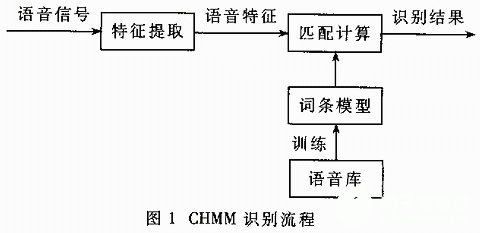
其中,M為使用的混合高斯分布的階數(shù),Cm為各階高期分布的加權系數(shù)。此時的HMM模型為連續(xù)HMM模型(Continuous density HMM),簡稱CHMM模型。在本識別系統(tǒng)中,采用整詞模型,每個詞條7個狀態(tài)同,包括首尾各一個靜音狀態(tài);每個狀態(tài)使用7階混合高斯分布擬合。CHMM識別流程如圖1所示。
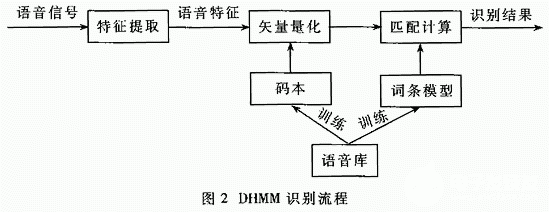
由于CHMM模型的復雜性,也可以假定On的分布是離散的。通常采用分裂式K-Mean算法得到碼本,然后對提取的特征矢量根據(jù)碼本做一次矢量量化VQ(Vector Quantization)。這樣特征矢量的概率分布上就簡化為一個離散的概率分布矩陣,此時的HMM模型稱為離散HMM模型(Discrete density HMM),簡稱DHMM模型。本DHMM識別系統(tǒng)使用的碼本大小為128。DHMM識別流程如圖2所示。
DHMM雖然增加了矢量量化這一步驟,但是由于簡化了模型的復雜度,從而減少了占用計算量最大的匹配計算。當然,這是以犧牲一定的識別性能為代價。
筆者先后自己的硬件平臺上完成了基于DHMM和CHMM的識別系統(tǒng)。通過比較發(fā)現(xiàn),對于嵌入式平臺而言,實現(xiàn)CHMM識別系統(tǒng)的關鍵在于芯片有足夠運算太多的增加。因為詞條模型存儲在ROM中,在匹配計算時是按條讀取的。
3.3 識別性能
筆者使用自己的識別算法分別對11詞的漢語數(shù)碼和一個59詞的命令詞集作了實際識別測試,識別率非常令人滿意,如表1所示。
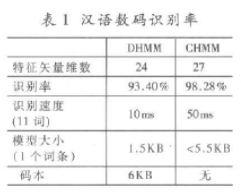
對于59詞命令詞集的識別,還增加了靜音模型。由于基線的識別率已經(jīng)很高,所以靜音模型的加入對于識別率的進一步提高作用不大,如表2所示。但靜音模型的加入可以降低對端點判斷的依賴。這在實際使用中對系統(tǒng)的穩(wěn)健性有很大的提高。
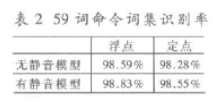
可以看到,在硬件能夠支持的情況下,CHMM的識別率比DHMM有很大的提高,同時識別速度也完全可以滿足使用要求。
目前嵌入式語音識別領域使用HMM模型的還比較少,使用通常限于DHMM。由于集成電路制造技術的發(fā)展,目前主流DSP都可以提供100MIPS以上的運算速度,完全可以滿足CHMM對計算能力的要求。
筆者在使用SoC芯片的硬件平臺上實現(xiàn)了DHMM和CHMM算法。其中定點CHMM語音識別算法在16位定點DSP硬件平臺上達到很高的識別率,同時系統(tǒng)資源消耗也比較合理,安全可以替代DHMM算法。非常適合50詞以內(nèi)的命令詞識別。以上算法已經(jīng)在芯片上實現(xiàn),該方案在家電語音遙控、玩具、PDA、智能儀器以及移動電話等領域內(nèi)有非常好的應用前景。
責任編輯:gt
-
芯片
+關注
關注
459文章
51925瀏覽量
433628 -
嵌入式
+關注
關注
5125文章
19438瀏覽量
313038 -
語音識別
+關注
關注
39文章
1770瀏覽量
113703
發(fā)布評論請先 登錄
相關推薦
怎么設計基于嵌入式系統(tǒng)的語音口令識別系統(tǒng)?
嵌入式語音識別系統(tǒng)與PC機語音識別系統(tǒng)相比有什么優(yōu)點?
怎樣去設計基于LD3320的嵌入式語音識別系統(tǒng)
基于STM32嵌入式的孤立詞語音識別系統(tǒng)設計
怎樣去設計基于嵌入式Linux的語音識別系統(tǒng)
嵌入式語音識別系統(tǒng)中的電路設計是如何的
怎樣去設計一種基于LD3320芯片的嵌入式語音識別系統(tǒng)呢
STM32嵌入式平臺上的實現(xiàn)孤立詞語音識別系統(tǒng)
基于嵌入式系統(tǒng)的語音口令識別系統(tǒng)的實現(xiàn)

一種基于嵌入式系統(tǒng)的語音口令識別系統(tǒng)的設計






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論