 9個為人工智能、機器學習和深度學習準備數據中心的優秀實踐
9個為人工智能、機器學習和深度學習準備數據中心的優秀實踐

圍繞圖形處理單元(GPU)計算的生態系統如今正在迅速發展,以提高GPU工作負載的效率和可擴展性。然而,在避免存儲和網絡中潛在的瓶頸的同時,也有一些技巧可以很大限度地提高GPU的利用率。
人工智能、機器學習、深度學習應用程序的密集需求對數據中心的性能、可靠性和可擴展性提出了挑戰,尤其是在IT架構師模仿公共云的設計以簡化向混合云和內部部署的過渡時。
Excelero公司首席技術官Sven Breuner和首席架構師Kirill Shoikhet為此分享了9個為人工智能、機器學習和深度學習準備數據中心的優秀實踐。
數據點1:了解目標系統性能、投資回報率和可擴展性計劃。
隨著人工智能成為核心業務的重要組成部分,大多數組織都從最初的少量預算和少量培訓數據集入手,并為無縫快速的系統增長準備基礎設施。需要構建所選的硬件和軟件基礎設施,以實現靈活的橫向擴展,以避免在每個新的增長階段產生破壞性的變化。數據科學家與系統管理員之間的密切協作對于了解性能要求,并了解基礎設施可能需要隨著時間的發展而變得至關重要。
數據點2:現在或將來評估集群多個GPU系統。
在一臺服務器中采用多個GPU可以在系統內部實現有效的數據共享和通信,并具有成本效益,參考設計假定將來可以集群使用,并且在單個服務器中最多支持16個GPU。多個GPU服務器需要準備好以很高的速率讀取傳入的數據,以使GPU高效運行,這意味著它需要一個超高速的網絡連接,以及用于訓練數據庫的存儲系統。但是在某個時候,單臺服務器將不再足以在合理的時間內處理增長的訓練數據庫,因此在設計中構建共享存儲基礎設施將使隨著人工智能、機器學習、深度學習使用的擴展,添加GPU服務器變得更容易。
數據點3:評估人工智能工作流程各個階段的瓶頸。
數據中心基礎設施需要能夠同時處理人工智能工作流程的所有階段。對于具有成本效益的數據中心來說,擁有一個可靠的資源調度和共享概念是至關重要的。因此,盡管數據科學家獲得了需要攝取和準備的新數據,但其他人將訓練他們的可用數據,而其他人則使用先前生成的模型進行訓練用于生產。Kubernetes已成為解決這一問題的一種主要解決方案,使云計算技術易于在內部部署使用,并使混合部署變得可行。
數據點4:查看用于優化GPU利用率和性能的策略。
許多人工智能、機器學習、深度學習應用程序的計算密集型性質使基于GPU的服務器成為常見選擇。但是,盡管GPU可以有效地從內存加載數據,但是訓練數據集通常遠遠超過內存,并且涉及的大量文件變得更加難以攝取。在GPU服務器之間以及與存儲基礎設施之間,實現GPU數量與可用CPU功率、內存和網絡帶寬之間的優秀平衡至關重要。
數據點5:支持訓練和推理階段的需求。
在訓練系統“看貓”的經典示例中,計算機執行一個數字游戲,需要查看大量不同顏色的貓。由于包含大量并行文件讀取的訪問的性質,NVMe閃存通過提供超低的訪問延遲和每秒的大量讀取操作很好地滿足了這些要求。在推理階段,挑戰是相似的,因為對象識別通常是實時發生的——另一個使用案例中,NVMe閃存也提供了延遲優勢。
數據點6:考慮并行文件系統和替代方案。
諸如IBM公司的SpectrumScale或BeeGFS之類的并行文件系統可以幫助有效地處理大量小文件的元數據,并通過在網絡上每秒交付數萬個小文件,從而使機器學習數據集的分析速度提高3到4倍。鑒于訓練數據的只讀性質,因此在將數據卷直接提供給GPU服務器并通過Kubernetes之類的框架以共享方式共享它們時,也可以完全避免使用并行文件系統。
數據點7:選擇正確的網絡主干。
人工智能、機器學習、深度學習通常是一種新的工作負載,將其重新安裝到現有的網絡基礎設施中通常無法支持復雜計算和快速高效數據傳輸所需的低延遲、高帶寬、高消息速率和智能卸載。基于RDMA的網絡傳輸RoCE(融合以太網上的RDMA)和InfiniBand已成為滿足這些新需求的標準。
數據點8:考慮四個存儲系統的性價比杠桿。
(1)高讀取吞吐量和低延遲,不限制混合部署,可以在云平臺或內部部署資源上運行。
(2)數據保護。人工智能、機器學習、深度學習存儲系統通常比數據中心中的其他系統要快得多,因此在發生故障后從備份中恢復可能會花費很長時間,并且會中斷正在進行的操作。深度學習訓練的只讀性質使其非常適合于分布式擦除編碼,在這種存儲中,最高容錯能力已經內置在主存儲系統中,原始容量和可用容量之間的差異很小。
(3)容量彈性可適應任何大小或類型的驅動器,以便隨著閃存介質的發展和閃存驅動器特性的擴展,數據中心可以在最重要的情況下很大限度地提高性價比。
(4)性能。由于人工智能數據集需要隨著時間的推移而增長,以進一步提高模型的準確性,因此存儲基礎設施應實現接近線性的縮放系數,在這種情況下,每增加一次存儲都會帶來同等的增量性能。這使得組織可以從小規模開始,并根據業務需要而無中斷地增長。
數據點9:設置基準和性能指標以幫助實現可擴展性。
例如,對于深度學習存儲,一個重要指標可能是每個GPU每秒處理X個文件(通常為數千或數萬個),其中每個文件的平均大小為Y(從幾十個到數千個)kB 。預先建立適當的基準和性能指標有助于從一開始就確定架構方法和解決方案,并指導后續擴展。
責編AJX
-
AI
+關注
關注
88文章
34936瀏覽量
278367 -
機器學習
+關注
關注
66文章
8500瀏覽量
134476 -
深度學習
+關注
關注
73文章
5559瀏覽量
122732
發布評論請先 登錄
如何有效地管理人工智能數據中心的電源

數學專業轉人工智能方向:考研/就業前景分析及大學四年學習路徑全揭秘

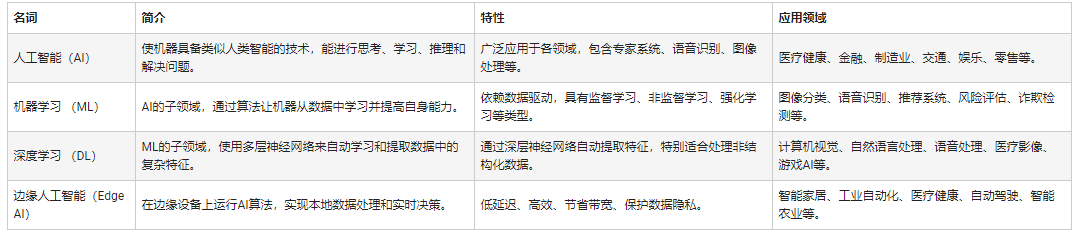
人工智能和機器學習以及Edge AI的概念與應用
人工智能對數據中心基礎設施帶來了哪些挑戰
【「具身智能機器人系統」閱讀體驗】+數據在具身人工智能中的價值
人工智能工程師高頻面試題匯總——機器學習篇

嵌入式和人工智能究竟是什么關系?
人工智能對數據中心的挑戰
具身智能與機器學習的關系
人工智能、機器學習和深度學習存在什么區別






 工商網監
工商網監
評論