 幾種流行的優化器的介紹以及優缺點分析
幾種流行的優化器的介紹以及優缺點分析
導讀
幾種流行的優化器的介紹以及優缺點分析,并給出了選擇優化器的幾點指南。
本文概述了計算機視覺、自然語言處理和機器學習中常用的優化器。此外,你會找到一個基于三個問題的指導方針,以幫助你的下一個機器學習項目選擇正確的優化器。
找一份相關的研究論文,開始使用相同的優化器。
參考表1并將數據集的屬性與不同優化器的優缺點進行比較。
根據可用的資源調整你的選擇。
介紹
為你的機器學習項目選擇一個好的優化器是非常困難的。熱門的深度學習庫,如PyTorch或TensorFlow,提供了廣泛的優化器的選擇,不同的優化器,每個都有自己的優缺點。然而,選擇錯誤的優化器可能會對你的機器學習模型的性能產生重大的負面影響,這使得優化器在構建、測試和部署機器學習模型的過程中成為一個關鍵的設計選擇。
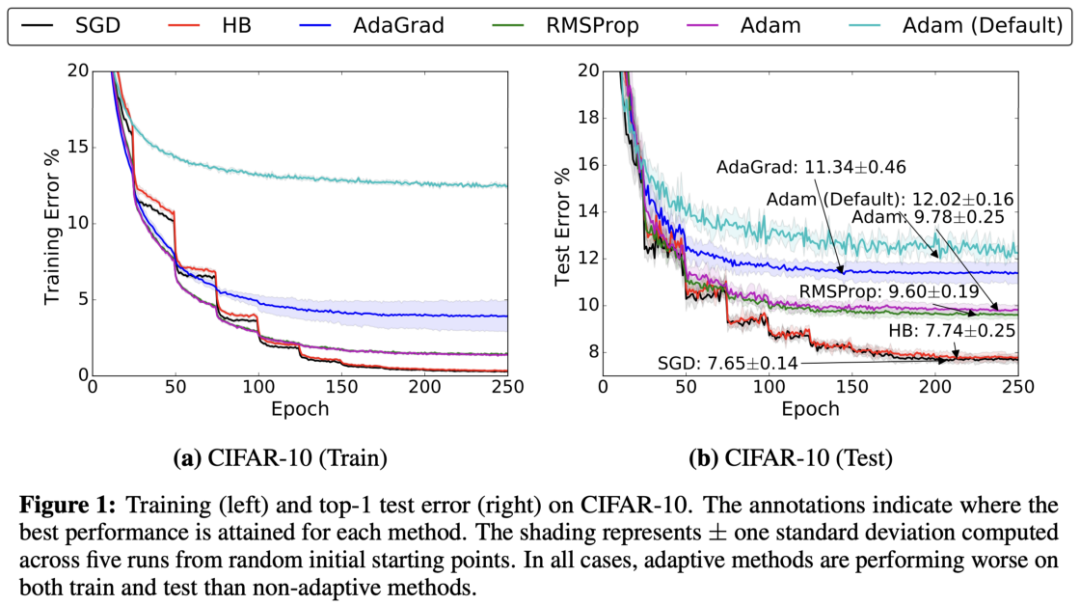
根據優化器的不同,模型的性能可能會有很大的不同。
選擇優化器的問題在于,由于no-free-lunch定理,沒有一個單一的優化器可以在所有場景中超越其他的。事實上,優化器的性能高度依賴于設置。所以,中心問題是:
哪個優化器最適合我的項目的特點?
下面的內容給出了回答上述問題的一個指南。它由兩個主要段落組成:在第一部分,我將向你快速介紹最常用的優化器。在第二部分中,我將為你提供一個三步計劃來為你的項目選擇最好的優化器。
一些最常用的優化器
在深度學習中,幾乎所有流行的優化器都基于梯度下降。這意味著他們反復估計給定的損失函數L的斜率,并將參數向相反的方向移動(因此向下爬升到一個假設的全局最小值)。這種優化器最簡單的例子可能是隨機梯度下降(或SGD),自20世紀50年代以來一直使用。在2010年代,自適應梯度的使用,如AdaGrad或Adam已經變得越來越流行了。然而,最近的趨勢表明,部分研究界重新使用SGD而不是自適應梯度方法。此外,當前深度學習的挑戰帶來了新的SGD變體,如LARS或LAMB。例如,谷歌研究在其最新論文中使用LARS訓練了一個強大的自監督模型。
下面的部分將介紹最流行的優化器。如果你已經熟悉了這些概念,請轉到“如何選擇正確的優化器”部分。
我們將使用以下符號:用w表示參數,用g表示模型的梯度,α為每個優化器的全局學習率,t為時間步長。
Stochastic Gradient Descent (SGD)
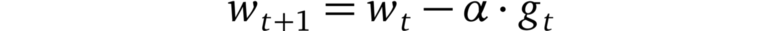
Stochastic Gradient Descent (SGD)的更新規則
在SGD中,優化器基于一個小batch估計最陡下降的方向,并在這個方向前進一步。由于步長是固定的,SGD會很快陷入平坦區或陷入局部極小值。
SGD with Momentum
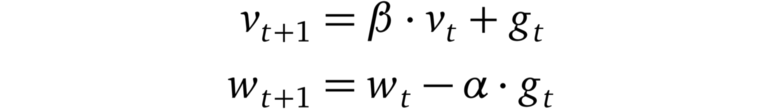
帶動量的SGD的更新規則
其中β < 1,使用了動量,SGD可以在持續的方向上進行加速(這就是為什么也被叫做“重球方法”)。這個加速可以幫助模型擺脫平坦區,使它更不容易陷入局部最小值。
AdaGrad
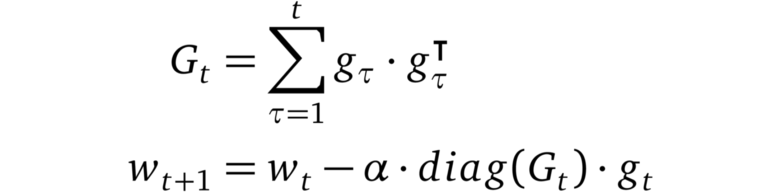
AdaGrad的更新規則
AdaGrad是首個成功的利用自適應學習率的方法之一(因此得名)。AdaGrad根據梯度的平方和的倒數的平方根來衡量每個參數的學習速率。這個過程將稀疏梯度方向上的梯度放大,從而允許在這些方向上執行更大的步驟。其結果是:AdaGrad在具有稀疏特征的場景中收斂速度更快。
RMSprop
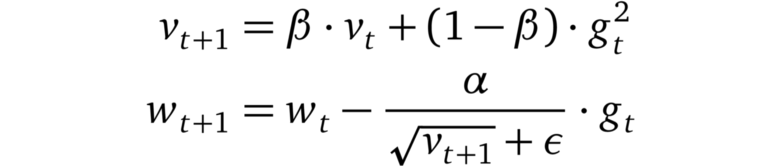
RMSprop的更新規則
RMSprop是一個未發布的優化器,在過去幾年中被過度使用。這個想法與AdaGrad相似,但是梯度的重新縮放不那么激進:梯度的平方的總和被梯度平方的移動平均值所取代。RMSprop通常與動量一起使用,可以理解為Rprop對mini-batch設置的適應。
Adam
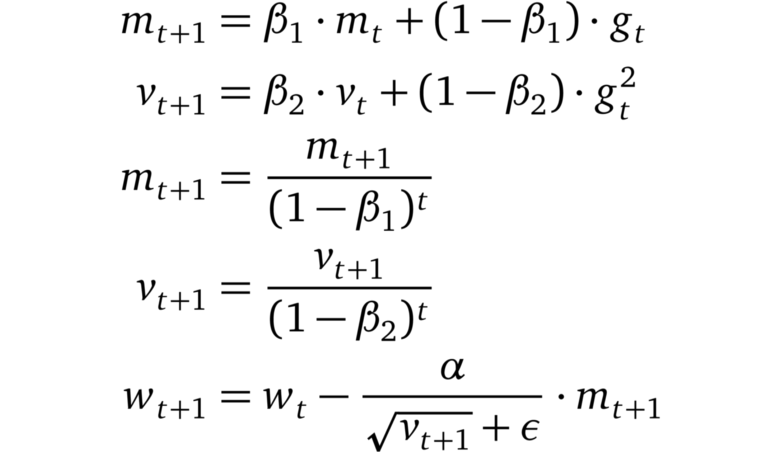
Adam的更新規則
Adam將AdaGrad,RMSprop和動量法結合在一起。步長方向由梯度的移動平均值決定,步長約為全局步長的上界。此外,梯度的每個維度都被重新縮放,類似于RMSprop。Adam和RMSprop(或AdaGrad)之間的一個關鍵區別是,矩估計m和v被糾正為偏向于零。Adam以通過少量的超參數調優就能獲得良好性能而聞名。
LARS
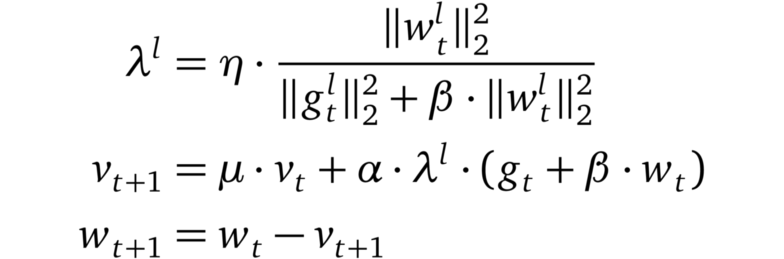
LARS的更新規則
LARS是使用動量的SGD的一種擴展,具有適應每層學習率的能力。它最近引起了研究界的注意。原因是由于可用數據量的穩步增長,機器學習模型的分布式訓練已經流行起來。其結果是批大小開始增長。然而,這導致了訓練中的不穩定。Yang等人認為,這些不穩定性源于某些層的梯度范數和權重范數之間的不平衡。因此,他們提出了一個優化器,該優化器基于一個“trust”參數η < 1和該層的梯度的范數的倒數,對每一層的學習率進行縮放。
如何選擇正確的優化器?
如上所述,為你的機器學習問題選擇正確的優化器是困難的。更具體地說,沒有一勞永逸的解決方案,必須根據手頭的特定問題仔細選擇優化器。在下一節中,我將提出在決定使用某個優化器之前應該問自己的三個問題。
與你的數據集和任務類似的state-of-the-art的結果是什么?使用過了哪些優化器,為什么?
如果你正在使用新的機器學習方法,可能會有一篇或多篇涵蓋類似問題或處理類似數據的可靠論文。通常,論文的作者已經做了廣泛的交叉驗證,并且只報告了最成功的配置。試著理解他們選擇優化器的原因。
舉例:假設你想訓練生成對抗性網絡(GAN)來對一組圖像執行超分辨率。在一些研究之后,你偶然發現了一篇論文:”Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network,” ,其中研究人員使用Adam優化器來解決完全相同的問題。Wilson等人認為,訓練GANs并不等于解決最優化問題,Adam可能非常適合這樣的場景。因此,在這種情況下,Adam是優化器的一個很好的選擇。
你的數據集是否具有某些優化器的優勢?如果有,是哪些,如何利用這些優勢?
表1顯示了不同優化器及其優缺點的概述。嘗試找到與數據集的特征、訓練設置和目標相匹配的優化器。
某些優化器在具有稀疏特征的數據上表現得非常好,而另一些優化器在將模型應用于之前未見過的數據時可能表現得更好。一些優化器在大batch中工作得很好,而另一些優化器可以收斂到很陡峭的極小值但是泛化效果不好。
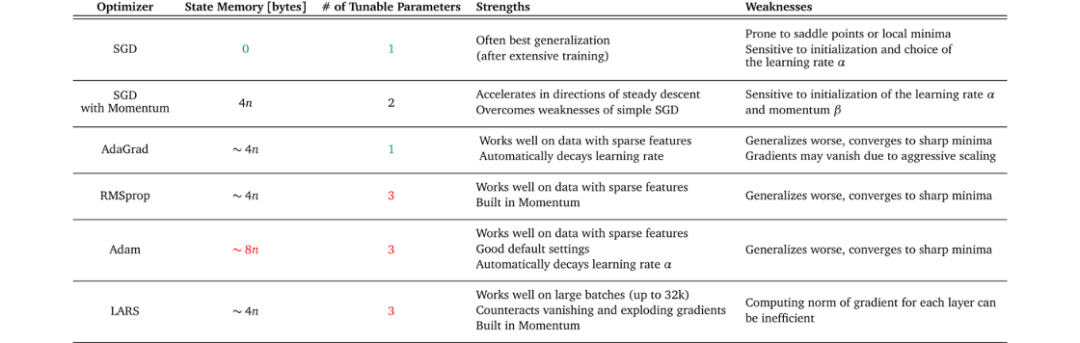
表1:流行的優化器的總結,突出它們的優點和缺點。state memory列表示優化器所需的字節數 —— 除了梯度所需的內存之外。其中,n為機器學習模型的參數個數。例如,沒有動量的SGD只需要內存來存儲梯度,而有動量的SGD也需要存儲梯度的移動平均值。
例子:對于你當前工作的項目,你必須將用戶反饋分為積極反饋和消極反饋。你考慮使用bag-of-words作為機器學習模型的輸入特征。由于這些特征可能非常稀疏,你決定使用自適應梯度的方法。但是你想用哪一種呢?考慮表1,你看到看到AdaGrad具有自適應梯度方法中最少的可調參數。看到你的項目有限的時間表,你選擇了AdaGrad作為優化器。
你的項目所具有資源是什么?
項目中可用的資源也會影響選擇哪個優化器。計算限制或內存約束,以及項目的時間表可以縮小可行選擇的范圍。再次查看表1,你可以看到不同的內存需求和每個優化器的可調參數數量。此信息可以幫助你評估你的設置是否支持優化器所需的資源。
例子:你在做一個項目,在該項目中,你想在家用計算機上的圖像數據集上訓練一個自監督模型(例如SimCLR)。對于SimCLR這樣的模型,性能隨著batch size大小的增加而增加。因此,你希望盡可能地節省內存,以便能夠進行大batch的訓練。你選擇一個簡單的不帶動量的隨機梯度下降作為你的優化器,因為與其他優化器相比,它需要最少的額外內存來存儲狀態。
總結
嘗試所有可能的優化器來為自己的項目找到最好的那一個并不總是可能的。在這篇博客文章中,我概述了最流行的優化器的更新規則、優缺點和需求。此外,我列出了三個問題來指導你做出明智的決定,即機器學習項目應該使用哪個優化器。
作為一個經驗法則:如果你有資源找到一個好的學習率策略,帶動量的SGD是一個可靠的選擇。如果你需要快速的結果而不需要大量的超參數調優,請使用自適應梯度方法。
責任編輯:lq
-
函數
+關注
關注
3文章
4371瀏覽量
64280 -
機器學習
+關注
關注
66文章
8493瀏覽量
134156 -
數據集
+關注
關注
4文章
1223瀏覽量
25291
原文標題:在機器學習項目中該如何選擇優化器
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
PCBA 表面處理:優缺點大揭秘,應用場景全解析

惠斯通電橋的優缺點分析
硅谷物理服務器的優缺點分析
東京站群服務器有哪些優缺點
SSM框架的優缺點分析 SSM在移動端開發中的應用
不同類型ACDC轉換器優缺點 ACDC轉換器負載能力分析
不同類型adc的優缺點分析
幾種常見的控制方法及其優缺點






 工商網監
工商網監
評論