") 一文解析鴻蒙LiteOS和LINUX比較
一文解析鴻蒙LiteOS和LINUX比較
鴻蒙是一個(gè)面向場景的智能操作系統(tǒng)。很多人剛開始把它與Linux相比,這是不對(duì)的,首先Linux只是一個(gè)內(nèi)核,在Linux之上我們開發(fā)者還需要做很多的操作,比如驅(qū)動(dòng)開發(fā)和應(yīng)用開發(fā)才能讓用戶能夠正常的操作。鴻蒙的LiteOS才是用來對(duì)標(biāo)Linux的,值得注意的是LiteOS和Linux是一樣的,都是宏內(nèi)核而不是之前宣傳的微內(nèi)核,鴻蒙的微內(nèi)核可能要到過段時(shí)間才會(huì)發(fā)布。那么鴻蒙對(duì)標(biāo)的產(chǎn)品是什么呢?是安卓和Windows。這也讓安卓特別的難受,因?yàn)榕c它正在開發(fā)的Funchsia系統(tǒng)在地位上有較大的吻合,都是面向IOT設(shè)備的操作系統(tǒng)。我們可以看看這張圖,在鴻蒙的整個(gè)框架中內(nèi)核只是占比較小的一部分,而內(nèi)核這部分里還分了兩個(gè)內(nèi)核子系統(tǒng):Linux和LiteOS。所以內(nèi)核位于鴻蒙就像心臟位于人體,非常重要但占比很小。如果把內(nèi)核類比成系統(tǒng)就好像把心臟類比成人一樣,不合適。
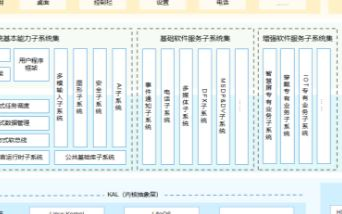
系統(tǒng)基本能力子系統(tǒng)集:為分布式應(yīng)用在 HarmonyOS 多設(shè)備上的運(yùn)行、調(diào)度、遷移等操作提供了基礎(chǔ)能力,由分布式軟總線、分布式數(shù)據(jù)管理、分布式任務(wù)調(diào)度、方舟多語言運(yùn)行時(shí)、公共基礎(chǔ)庫、多模輸入、圖形、安全、AI 等子系統(tǒng)組成。其中,方舟運(yùn)行時(shí)提供了 C / C++ / JS 多語言運(yùn)行時(shí)和基礎(chǔ)的系統(tǒng)類庫,也為使用方舟編譯器靜態(tài)化的 Java 程序(即應(yīng)用程序或框架層中使用 Java 語言開發(fā)的部分)提供運(yùn)行時(shí)。
基礎(chǔ)軟件服務(wù)子系統(tǒng)集:為 HarmonyOS 提供公共的、通用的軟件服務(wù),由事件通知、電話、多媒體、DFX、MSDP & DV 等子系統(tǒng)組成。
增強(qiáng)軟件服務(wù)子系統(tǒng)集:為 HarmonyOS 提供針對(duì)不同設(shè)備的、差異化的能力增強(qiáng)型軟件服務(wù),由智慧屏專有業(yè)務(wù)、穿戴專有業(yè)務(wù)、IoT 專有業(yè)務(wù)等子系統(tǒng)組成。
硬件服務(wù)子系統(tǒng)集:為 HarmonyOS 提供硬件服務(wù),由位置服務(wù)、生物特征識(shí)別、穿戴專有硬件服務(wù)、IoT 專有硬件服務(wù)等子系統(tǒng)組成。
剛剛講了一個(gè)宏內(nèi)核和微內(nèi)核的概念,那什么是宏內(nèi)核什么是微內(nèi)核呢?

這一張圖就是用來區(qū)分宏內(nèi)核和微內(nèi)核的,中間有一條橫線,橫線上面是運(yùn)行在應(yīng)用的,叫應(yīng)用(用戶)態(tài),應(yīng)用態(tài)是受操作系統(tǒng)限制的,只能在指定的內(nèi)存空間中運(yùn)行。橫線下面是運(yùn)行在內(nèi)核里面的,也叫內(nèi)核態(tài)。最左邊的是宏內(nèi)核,中間是微內(nèi)核,最右邊的是混合內(nèi)核。那么宏內(nèi)核和微內(nèi)核有什么區(qū)別,其實(shí)就是劃分的問題,簡單的說,宏內(nèi)核把大大小小的事情都劃分到內(nèi)核里面去處理,比如VFS虛擬文件系統(tǒng),系統(tǒng)調(diào)用,文件系統(tǒng)等等統(tǒng)統(tǒng)塞進(jìn)內(nèi)核,只有應(yīng)用程序才運(yùn)行在用戶態(tài)。而微內(nèi)核則是相反,除了核心的內(nèi)核,統(tǒng)統(tǒng)扔到用戶態(tài)里面去執(zhí)行,這兩個(gè)是完全的極端,這也帶來明顯不一樣的效果。首先比較明顯的不同就是微內(nèi)核比較容易擴(kuò)展,且內(nèi)核驅(qū)動(dòng)之間互不干擾,不會(huì)出現(xiàn)像宏內(nèi)核那樣,一個(gè)崩都得死的現(xiàn)象。微內(nèi)核里面比較有名的就是我們的國貨之光RT-Thread。那么比如說Mac OS X使用的就是比較中庸的混合內(nèi)核,讓驅(qū)動(dòng)程序員來決定這些東西到底放在用戶態(tài)還是內(nèi)核態(tài)。這樣在保護(hù)內(nèi)核同時(shí)給開發(fā)帶來比較大的靈活性。有些功能它需要用極致的處理速度,并且程序上穩(wěn)定不會(huì)太大改變,那么就可以把這塊的驅(qū)動(dòng)程序沉到內(nèi)核態(tài),有些東西它不需要很快的執(zhí)行速度,且因?yàn)闃I(yè)務(wù)問題需要經(jīng)常的變動(dòng),那么可以扔到用戶態(tài)。

那既然Linux是宏內(nèi)核,LiteOS搞了半天還是宏內(nèi)核,為啥鴻蒙還要搞一個(gè)LiteOS呢?
Linux的強(qiáng)大在于它支持的硬件非常多,但是它過于龐大,啟動(dòng)慢、耗電,這些缺點(diǎn)導(dǎo)致它不適合用在資源比較受限的物聯(lián)網(wǎng)硬件設(shè)備領(lǐng)域。
Liteos-a為物聯(lián)網(wǎng)而生,與其他RTOS(實(shí)時(shí)操作系統(tǒng))不同,LiteOS支持MMU,支持內(nèi)核/APP空間隔離、支持各個(gè)APP空間隔離,系統(tǒng)更健壯;啟動(dòng)快,省電。等下我們可以稍微體驗(yàn)一下他開機(jī)能有多快,快到我都覺得他是關(guān)機(jī)其實(shí)只是待機(jī)。
除了Liteos-a,還有一個(gè)Liteos-m,后者運(yùn)行在沒有MMU的芯片上,也就是運(yùn)行在MCU上,就是傳統(tǒng)的單片機(jī)。
講回鴻蒙系統(tǒng),鴻蒙有啥不一樣的呢?官方的回答是:作為面向未來的全場景分布式OS:它具有多端統(tǒng)一OS、硬件虛擬化互助(也就是分布式)以及一次開發(fā)多端部署的優(yōu)點(diǎn)。
什么叫多端統(tǒng)一OS ?鴻蒙在開發(fā)者大會(huì)上提出1+8+N的一個(gè)硬件生態(tài)理念,就是圍繞著以手機(jī)為中心,開展8個(gè)領(lǐng)域的華為自研產(chǎn)品,包括 PC、平板、車機(jī)、運(yùn)動(dòng)健康、穿戴、AR/VR、智慧大屏、智能音響。同時(shí)打造大量的IoT設(shè)備,也就是里面的N,比如:耳機(jī),打印機(jī),電子秤等等。而這些設(shè)備都將使用鴻蒙OS來開發(fā)。全部使用鴻蒙OS就能為第二步:硬件虛擬化互助帶來可能性。
什么叫硬件虛擬化互助,即分布式任務(wù)調(diào)度?我們先想象這么一個(gè)場景:假設(shè)我們開車使用車上的車載導(dǎo)航到達(dá)目的地附近,接著要使用手機(jī)導(dǎo)航到目的地需要幾個(gè)步驟:首先打開手機(jī)里的導(dǎo)航軟件-》輸入目的地-》選擇步行導(dǎo)航-》開始導(dǎo)航。現(xiàn)在我們覺得這些操作合情合理,但是如果手機(jī)和車載都搭載了鴻蒙系統(tǒng),這個(gè)步驟將會(huì)縮短成一步:拿出手機(jī)就可以繼續(xù)導(dǎo)航,真正實(shí)現(xiàn)無縫銜接,而這一過程里車載上的導(dǎo)航將會(huì)移到手機(jī)上,并顯示。這就是為應(yīng)用提供多設(shè)備協(xié)同的能力。
那這個(gè)分布式架構(gòu)有什么優(yōu)勢(shì)?以及它是如何實(shí)現(xiàn)硬件虛擬化互助的這個(gè)功能呢?
分布式架構(gòu)在設(shè)計(jì)之初就考慮了多設(shè)備移植和部署的這個(gè)需求,這也就剛剛說的第三點(diǎn)好處(一次開發(fā)多端部署),它是分布式架構(gòu)設(shè)計(jì)帶來的一個(gè)結(jié)果之一,只要一次開發(fā)就可以在上面所說的1+8+N上跑自己的應(yīng)用程序。那么在鴻蒙底層也為這種協(xié)同工作帶來一些組件上的支持。像我們現(xiàn)在的分立式設(shè)備,兩個(gè)不同的設(shè)備是如何建立連接的?需要用到藍(lán)牙或者wifi,以及一些相關(guān)的協(xié)議。那么這是建立在雙方有藍(lán)牙或者wifi的前提下,以及協(xié)議必須相同的前提下,如果其中一方不支持,那么它們就不可能建立起連接,所以在開發(fā)過程中,你既要跟APP廠家近進(jìn)行協(xié)同,又要跟另外一個(gè)硬件廠家進(jìn)行協(xié)同,這樣的成本其實(shí)是非常的高昂的。所以鴻蒙的出現(xiàn)首先要降低這種協(xié)同上的成本。我覺得也是大家以后會(huì)使用鴻蒙比較重要的原因之一。
那么鴻蒙是如何做到分布式智能互聯(lián)的呢?這里有一張圖,這張圖模擬了兩個(gè)設(shè)備之間的互聯(lián)情況,我們假設(shè)設(shè)備1是一個(gè)手機(jī),設(shè)備2是一個(gè)手表。那么這兩個(gè)設(shè)備是如何連接的呢?鴻蒙提供兩種解決方案,一種就是傳統(tǒng)的物理層連接,也就是通過藍(lán)牙-藍(lán)牙、wifi-wifi等方式進(jìn)行連接。一種就是軟總線連接,
什么叫軟總線?傳統(tǒng)的連接方式要求雙方必須要有相同的傳輸設(shè)備,比如都有藍(lán)牙設(shè)備。但是軟總線可以做到使用設(shè)備1由藍(lán)牙設(shè)備發(fā)送數(shù)據(jù),設(shè)備2使用wifi接收,在開發(fā)過程中不再需要關(guān)心網(wǎng)絡(luò)協(xié)議差異。鴻蒙
所以我們可以使用軟總線在兩個(gè)設(shè)備之間快速的通信。在軟總線之上是鴻蒙提供的一個(gè)分布式執(zhí)行框架,這一套框架可以允許我們通過軟總線與多個(gè)設(shè)備進(jìn)行連接。同時(shí)分布式執(zhí)行框架也是用來區(qū)分?jǐn)?shù)據(jù)要發(fā)給哪個(gè)設(shè)備,假如說,我一臺(tái)手機(jī)連接好幾個(gè)智能手表,那么怎么知道我手機(jī)上的一張照片是發(fā)給哪個(gè)智能手表的?就可以在分布式執(zhí)行框架進(jìn)行判斷。在往上走是用戶程序框架,這個(gè)框架是鴻蒙給APP開發(fā)著提供的統(tǒng)一的調(diào)用接口,這樣APP開發(fā)者就不需要去考慮這個(gè)分布式互聯(lián)是如何實(shí)現(xiàn)的。在開發(fā)中,你要運(yùn)行到設(shè)備1和設(shè)備2的應(yīng)用是一起開發(fā)的,也就是說你一次就可以開發(fā)完兩個(gè)設(shè)備上的應(yīng)用。

設(shè)備1里還有一個(gè)FA和設(shè)備2里面還有一個(gè)AA,它們分別是什么呢?AA(Atomic Ability)是不帶界面的功能單元,AA是鴻蒙中不可缺少的且不能分割的能力,所以也叫元能力。而FA(Feature Ability)就是帶界面的AA。AA和FA都是由鴻蒙框架去實(shí)現(xiàn)的,然后通過統(tǒng)一的接口供開發(fā)者使用。那么這些AA和FA是什么呢?這些都是一些簡單的小功能,當(dāng)我們要去實(shí)現(xiàn)一個(gè)功能的時(shí)候,需要去調(diào)用不同的AA或者FA。比如說我要實(shí)現(xiàn)一個(gè)拍照功能,或者音樂播放的功能就需要調(diào)用這兩個(gè)AA或者FA。同時(shí)不同的設(shè)備之前也可以相互調(diào)用AA或者FA,也就是跨設(shè)備調(diào)用。我們可以想象一下,現(xiàn)在的我們開發(fā)應(yīng)用要調(diào)用某個(gè)設(shè)備,比如說攝像頭,那必須是這個(gè)設(shè)備擁有攝像頭這個(gè)功能,所以在開發(fā)過程中程序員必須充分了解這點(diǎn)。但是在鴻蒙里它是面向場景的操作系統(tǒng),開發(fā)者無需考慮自己運(yùn)行的這個(gè)設(shè)備是否有攝像頭,只需要考慮當(dāng)前環(huán)境下會(huì)出現(xiàn)哪些帶有攝像頭的設(shè)備然后調(diào)用它的AA。
那么實(shí)現(xiàn)這些功能的原理還是剛剛說的軟總線和分布式調(diào)度。
那么至此北向的應(yīng)用開發(fā)就是這些內(nèi)容的介紹。現(xiàn)在就講一下
鴻蒙LiteOS和LINUX比較
基礎(chǔ)知識(shí)
LiteOS與Linux的啟動(dòng)區(qū)別
LiteOS以上電后會(huì)跳轉(zhuǎn)到reset_vector復(fù)位向量表這里,在reset_vector中會(huì)執(zhí)行關(guān)中斷、設(shè)置ICache、重定位、
然后會(huì)看到PAGE_TABLE_SET,這是一個(gè)宏,用來設(shè)置頁表的 ,設(shè)置完頁表之后就會(huì)啟動(dòng)MMU,一旦啟動(dòng)MMU,CPU就沒辦法通過物理地址訪問設(shè)備。只能用虛擬地址
啟動(dòng)MMU之后初始化棧、然后調(diào)用main函數(shù)
那Linux在啟動(dòng)內(nèi)核的時(shí)候做了哪些操作呢?如下圖,可以看出還是非常的相似的

MMU
先舉個(gè)例子,編寫兩個(gè)測試demo:main_world.c和main_leleen.c
1、main_world.c
#include 《stdio.h》
int main(void)
{
printf(“Hello World!!!!!\r\n”);
}
2、main_leleen.c
#include 《stdio.h》
int main(void)
{
printf(“Hello Leleen!!!!!\r\n”);
}
將其進(jìn)行編譯得到可執(zhí)行文件:
arm-linux-gnueabihf-gcc -g -o main_world main_world.c
arm-linux-gnueabihf-gcc -g -o main_leleen main_leleen.c
再將其進(jìn)行反編譯
arm-linux-gnueabihf-objdump -S -d main_world 》 main_world.txt
arm-linux-gnueabihf-objdump -S -d main_leleen 》 main_leleen.txt
會(huì)發(fā)現(xiàn)他們的起始地址都是一樣的:0x0102c8

很顯然,這個(gè)地址不應(yīng)該是物理地址,理由有一點(diǎn)是可以確認(rèn)的:當(dāng)前我們的應(yīng)用程序并沒有在開發(fā)板子上跑起來。所以這個(gè)地址應(yīng)該是一個(gè)虛擬的地址。
上面是通過代碼來查看地址,那如果在硬件上,假設(shè)當(dāng)前RAM運(yùn)行了多個(gè)APP,它們的運(yùn)行狀態(tài)保存在RAM中,此時(shí)它們的地址應(yīng)該各不相同,比如app1的地址是addr4,app2所處的地址是addr1。這些地址是app所處的物理地址。所以在編譯某個(gè)app時(shí),需要單獨(dú)指定它的鏈接地址,也就是指定它去哪里運(yùn)行。如下面這張圖,但這是一個(gè)不可能完成的任務(wù)。因?yàn)閍pp眾多且運(yùn)行時(shí)保存在哪個(gè)地址是完全不可以預(yù)料的。所以這里必須引入虛擬地址。CPU只需要通過虛擬地址就能控制某個(gè)應(yīng)用程序。

除此之外,引入虛擬地址還有一個(gè)作用,在資源少的硬件上運(yùn)行容量大的應(yīng)用,比如說一個(gè)10G的應(yīng)用在只有512M的RAM上運(yùn)行。應(yīng)用程序不可能一次性跑完,它會(huì)分段加載,假如說先運(yùn)行片段1,那么就會(huì)先把片段1的程序先加載到RAM上運(yùn)行,依次這樣操作,當(dāng)運(yùn)行到片段5的時(shí)候,此時(shí)RAM已經(jīng)滿了, 這個(gè)時(shí)候,系統(tǒng)會(huì)將RAM中先運(yùn)行的片段1擦除,然后將片段5拷貝到運(yùn)來片段1的RAM空間上運(yùn)行。

CPU是如何處理和管理這些虛擬地址,這就是MMU的工作,MMU是硬件,不是軟件。對(duì)內(nèi)存的管理屬于硬件管理,從應(yīng)用程序的角度看,MMU是完全透明且不被感知的,所以在日常開發(fā)中都不會(huì)引起注意。
當(dāng)CPU發(fā)出0x0102c8這個(gè)虛擬地址的時(shí)候,會(huì)通過MMU進(jìn)行分析。MMU通過分析CPU發(fā)來的虛擬地址去調(diào)用不同的APP。既然MMU會(huì)去分析虛擬地址并轉(zhuǎn)換成物理地址,那么在MMU內(nèi)部一定存在一個(gè)虛擬地址和物理地址的對(duì)應(yīng)關(guān)系,這個(gè)對(duì)應(yīng)關(guān)系就是頁表。

鴻蒙使用的二級(jí)頁表,頁表的分析有點(diǎn)麻煩,時(shí)間問題我也沒有很仔細(xì)的去理解,為了方便后面的理解,我自己暫且把它理解一本新華字典,當(dāng)CPU發(fā)過來虛擬地址的時(shí)候,MMU就去翻這本新華字典,先從偏旁部首的目錄開始找,找到了就跳到那一頁查看是哪個(gè)地址,以及這個(gè)地址有哪些權(quán)限。
那如何使用MMU?大致需要以下步驟:在內(nèi)存中創(chuàng)建頁表-》把頁表基地址告訴MMU-》啟動(dòng)MMU
所以等下在LiteOS移植前需要先去設(shè)置它的MMU的頁表,讓它指向開發(fā)板內(nèi)存的首地址,并且設(shè)置大小。這樣就能建立虛擬地址和物理地址的映射,LiteOS就能正確的去訪問物理地址。
最后MMU除了管理虛擬地址和物理地址之外,還有一種功能就是保護(hù)內(nèi)存,防止數(shù)據(jù)被篡改。比如說我們寫的一個(gè)APP,當(dāng)CPU發(fā)出APP的虛擬地址給MMU時(shí),MMU會(huì)判斷這個(gè)APP是否有權(quán)限訪問內(nèi)核空間,當(dāng)發(fā)現(xiàn)只是一個(gè)普通的APP的時(shí)候,只可以讓它訪問自己的空間,而不能訪問其他內(nèi)核空間和其他APP的空間。
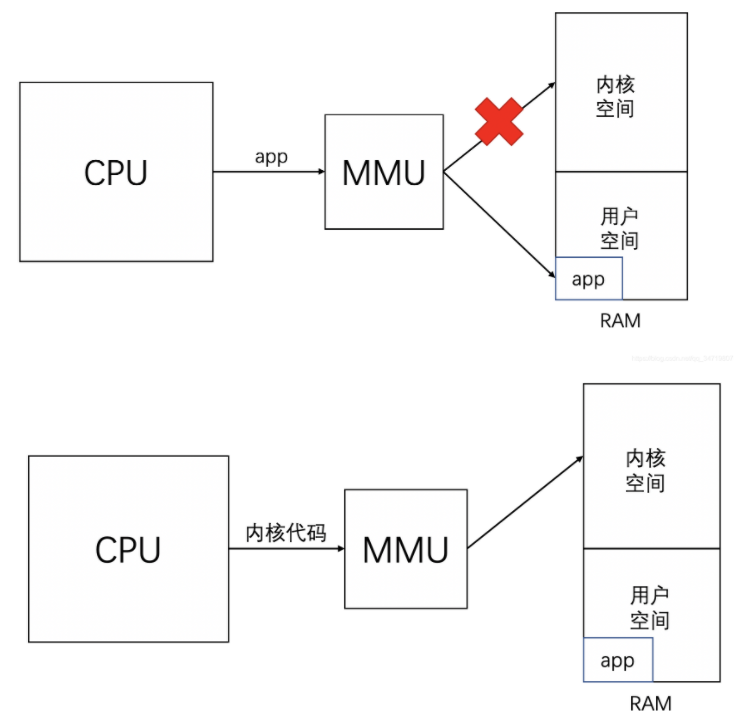
在reset_vector_up.S中設(shè)置MMU的地方:SYS_MEM_BASE是物理地址,KERNEL_VMM_BASE是虛擬地址,SYS_MEM_BASE點(diǎn)進(jìn)去SYS_MEM_BASE指向-》DDR_MEM_ADDR,我們需要更改DDR_MEM_ADDR,讓它指向6ull的內(nèi)存基地址(物理地址)0x80000000
那0x80000000這個(gè)值是從哪里來的呢?需要去6ull的芯片手冊(cè)查找,同時(shí)我們要找到等會(huì)要實(shí)現(xiàn)的串口物理地址

找到了這兩個(gè)值就可以設(shè)置頁表了
將PERIPH_PMM_BASE設(shè)置為0x02020000,SYS_MEM_BASE設(shè)置為0x80000000
但這么設(shè)置會(huì)有問題,因?yàn)長iteOS的映射是段映射,也就是說必須是整M的映射,所以我們將PERIPH_PMM_BASE設(shè)置為0x02000000

那么PERIPH_PMM_BASE的物理地址會(huì)映射到PERIPH_DEVICE_BASE,打開PERIPH_DEVICE_BASE,以后就可以通過
UART_Type* uart0 = IO_DEVICE_ADDR(0x02020000);來獲取設(shè)備的虛擬地址
設(shè)置完這些我們就可以來實(shí)現(xiàn)串口輸出了
串口輸出的實(shí)現(xiàn)
PRINT_RELEASE -》 LOS_LkPrint(los_printf.c)-》OsVprintf(los_printf.c)-》UartPuts(amba_pl011.c)-》UartPutsReg(amba_pl011.c)-》UartPutStr(amba_pl011.c)
amba_pl011.c這是華為用于他們開發(fā)板的代碼,要使用它得去修改這個(gè)代碼
修改UartPutsReg
STATIC VOID UartPutcReg(UINTPTR base, CHAR c) { UART_Type *uartRegs = (UART_Type *)base; while (!((uartRegs-》USR2) & (1《《3))); /*等待上個(gè)字節(jié)發(fā)送完畢*/ uartRegs-》UTXD = (unsigned char)c; }
設(shè)置完這些我們要進(jìn)行編譯一下,首先先進(jìn)入liteos_a所在的文件夾下,拷貝一下3518的配置文件到我們的目錄下配置一下
cp tools/build/config/debug/hi3518ev300_clang.config .config
make clean
make -j 8
中斷子系統(tǒng)
當(dāng)我們點(diǎn)擊觸摸屏等外設(shè)的時(shí)候,會(huì)產(chǎn)生一個(gè)中斷,這個(gè)中斷是如何到達(dá)CPU的呢?在ARM芯片上由一個(gè)通用的中斷控制器,叫GIC。這個(gè)中斷控制器主要是來決定發(fā)過來的中斷哪個(gè)優(yōu)先級(jí)更高,發(fā)送給CPU,如下圖
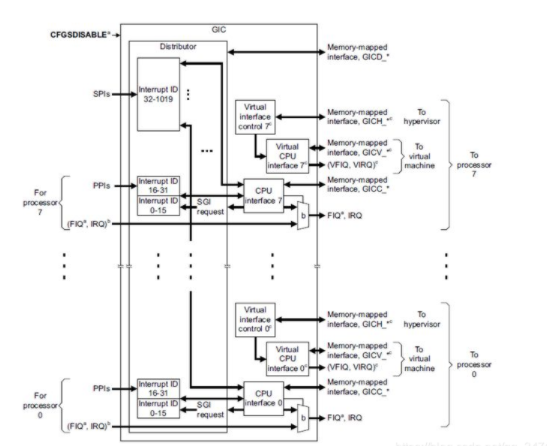
這張圖是GIC的詳細(xì)流程,里面有很多細(xì)節(jié),簡單來看就是下面這張

那么CPU如何去訪問GIC?CPU發(fā)送虛擬地址到MMU從而訪問到外設(shè),比如DDR、UART,同樣的,CPU要訪問GIC也必須通過MMU去訪問,通過芯片手冊(cè)可以知道GIC的物理地址是0xa00000,這個(gè)地址比我們剛剛設(shè)置的URAT的物理地址還要低,所以我們等會(huì)要去設(shè)置PERIPH_PMM_BASE,將它設(shè)置成0x00a00000。那么映射多大空間呢?因?yàn)槲覀儸F(xiàn)在只使用到了URAT和中斷,那么PERIPH_PMM_SIZE可以設(shè)置為0x00a00000 - 0x02000000 = 0x1600000
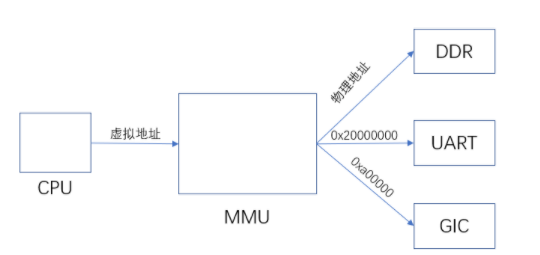
那么有哪些使用虛擬地址去調(diào)用GIC呢?
LITE_OS_SEC_TEXT_INIT INT32 main(VOID);
LITE_OS_SEC_TEXT_INIT VOID OsSystemInfo(VOID);
CHAR *HalIrqVersion(VOID);
UINT32 pidr = GIC_REG_32(GICD_PIDR2V2);
#define GIC_REG_32(reg) (*(volatile UINT32 *)((UINTPTR)(GIC_BASE_ADDR + (reg))))
我們要去設(shè)置這個(gè)GIC_BASE_ADDR
將#define GIC_BASE_ADDR IO_DEVICE_ADDR(0x10300000)
改為#define GIC_BASE_ADDR IO_DEVICE_ADDR(0xa00000)
那中斷產(chǎn)生的時(shí)候是從哪里進(jìn)來的呢?總要有一個(gè)入口吧?其實(shí)不管什么處理器,都有中斷(異常)向量表,在中斷總?cè)肟谥校械闹袛喽紩?huì)調(diào)用到這里,也就是說,作為一個(gè)管家,它需要分辨出調(diào)用它的是哪個(gè)中斷,然后調(diào)用對(duì)應(yīng)的中斷函數(shù)。而這對(duì)應(yīng)的中斷函數(shù)由我們提供。如何提供這樣的函數(shù)呢?可能是LiteOS在這一塊還不夠完善或者為了減少我們開發(fā)者的使用成本,內(nèi)部機(jī)制中還兼容著老款Linux的體系,使用request_irq,也可以使用鴻蒙LiteOS自己使用的OsalRegisterIrq,接下來我們分別講講從Linux和鴻蒙是如何處理中斷的。

先來講講Linux是如何處理中斷的。
在講中斷之前,我們先引入一個(gè)生活場景,假如我們現(xiàn)在回家口很渴,想燒水來喝,于是就去廚房燒了水,那么我們有以下幾種等待方式,1、盯著這壺水硬等,我就站在熱水壺旁邊看著它燒開;2、同樣在旁邊,但是我刷起了抖音,等它燒開發(fā)出響聲的時(shí)候我在過去沖。3、我先去洗個(gè)澡,20分鐘后這壺水肯定燒開了;4、回到客廳開始刷劇,等到水燒開的時(shí)候它就會(huì)發(fā)出響聲,同時(shí)熱水壺還是智能的,可以通過手機(jī)APP通知我燒開了。
這4個(gè)操作分別對(duì)應(yīng)著我們程序中的“查詢機(jī)制”、“休眠-喚醒機(jī)制”、“poll方式”、“異步通知”,除了第一種,剩下的都是我們常說的中斷機(jī)制。
了解了中斷機(jī)制,我們來看看CPU通常會(huì)發(fā)生哪些意想不到的異常而產(chǎn)生的中斷: ① 指令未定義 ② 指令、數(shù)據(jù)訪問有問題 ③ SWI(軟中斷) ④ 快中斷 ⑤ 中斷。那么這些是如何而來的?不管是uboot、Linux還是鴻蒙,都會(huì)有像上面那樣的異常向量表,每一個(gè)跳轉(zhuǎn)都對(duì)應(yīng)著一個(gè)異常中斷。
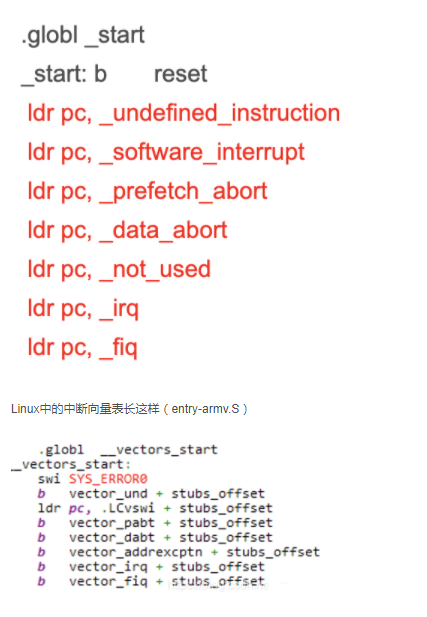
Linux中的中斷向量表長這樣(entry-armv.S)
我們引入一個(gè)場景,當(dāng)前有一個(gè)進(jìn)程A,在他運(yùn)行中產(chǎn)生了一個(gè)中斷

那么進(jìn)程間的切換時(shí)候,中斷還會(huì)做什么事情呢?1、保存當(dāng)前A進(jìn)程的現(xiàn)場,2、執(zhí)行中斷,3、恢復(fù)A現(xiàn)場。這切換過程中保存的數(shù)據(jù)全部放在棧中。那么當(dāng)A產(chǎn)生中斷的時(shí)候,這個(gè)時(shí)候能不能再產(chǎn)生一個(gè)中斷呢?并不可以。我們假設(shè)可以,當(dāng)A在執(zhí)行中斷程序的時(shí)候,發(fā)生了另外一個(gè)中斷2,此時(shí)要保存中斷程序中的現(xiàn)場,然后跳去2執(zhí)行中斷函數(shù),當(dāng)2執(zhí)行中斷函數(shù)的時(shí)候又產(chǎn)生了3中斷,……周而復(fù)始,保存在棧中的數(shù)據(jù)會(huì)越來越多,最后把整個(gè)棧都撐爆了。
除此之外,中斷處理函數(shù)還必須快速開始快速結(jié)束,如果中斷函數(shù)里面有大量的耗時(shí)運(yùn)算,此時(shí)進(jìn)程A會(huì)處于一種假死狀態(tài),這種現(xiàn)象是非常難以忍受的。但很顯然,在顯示開發(fā)中很難避免會(huì)在中斷函數(shù)中處理一些耗時(shí)的操作,那么應(yīng)該怎么辦?先把這個(gè)問題放一邊。
我們來看看硬件上是如何產(chǎn)生一個(gè)中斷的。假設(shè)一個(gè)GPIO0中接有兩個(gè)外部物理設(shè)備,設(shè)備1和設(shè)備2,當(dāng)設(shè)備1從高電平變成低電平的時(shí)候產(chǎn)生一個(gè)中斷信號(hào),同理,如果設(shè)備2也這樣操作,也會(huì)產(chǎn)生一個(gè)中斷信號(hào),中斷信號(hào)通過GIC通用中斷控制器傳給CPU來執(zhí)行不同的中斷處理函數(shù)。那么CPU如何去知道哪個(gè)設(shè)備觸發(fā)了這個(gè)中斷呢?CPU可以去GIC中讀取寄存器的值來確定是哪個(gè)模塊發(fā)生了中斷。假設(shè)知道了是A號(hào)發(fā)生了中斷,A號(hào)中斷對(duì)應(yīng)的是GPIO的中斷,但GPIO中又有很多GPIO中斷,假設(shè)除了剛剛說的那個(gè),還有GPIO0、1、2都可以產(chǎn)生中斷。那么還要繼續(xù)讀取GPIO中的寄存器進(jìn)行判斷是誰出發(fā)了中斷,假設(shè)讀到了剛剛說的那個(gè)B號(hào)中斷。那么對(duì)于這個(gè)B號(hào)中斷呢,它有可能是設(shè)備1發(fā)出的中斷,有可能是設(shè)備2發(fā)出的中斷。那么就需要去調(diào)用設(shè)備1的中斷處理函數(shù)和設(shè)備2的中斷處理函數(shù)來判斷下。

上面可以看到有兩個(gè)中斷,一個(gè)是A號(hào)中斷和B號(hào)中斷。它們?cè)贚inux中是通過一個(gè)irq_desc數(shù)組進(jìn)行保存的,在irq_desc數(shù)組中有兩個(gè)比較關(guān)鍵的點(diǎn),一個(gè)是 handle_irq,一個(gè)是 irqaction。
A號(hào)中斷的handle_irq主要會(huì)做哪些事情呢?首先會(huì)讀取GPIO的寄存器確認(rèn)是GPIO發(fā)出來的中斷。當(dāng)確認(rèn)了GPIO是由GPIO發(fā)出的中斷的時(shí)候回去調(diào)用GPIO的中斷處理函數(shù)handle_irq,那么GPIO是如何知道是設(shè)備1還是設(shè)備2發(fā)出的中斷呢?很簡單粗暴,直接調(diào)用兩個(gè)設(shè)備的處理函數(shù),由它們的處理函數(shù)handler來判斷自己有沒有發(fā)出中斷信號(hào)。
那么還有一個(gè)irqaction結(jié)構(gòu)體,這個(gè)action結(jié)構(gòu)體是用來做什么的呢? 當(dāng)調(diào)用 request_irq、 request_threaded_irq 注冊(cè)中斷處理函數(shù)時(shí),內(nèi)核就會(huì)構(gòu)造一個(gè) irqaction 結(jié)構(gòu)體。在里面保存 handler函數(shù),如果是共享中斷,里面會(huì)放有多個(gè)設(shè)備的處理函數(shù)講他們鏈起來。當(dāng)指定到GPIO處理函數(shù)的時(shí)候,系統(tǒng)會(huì)去irqaction下講設(shè)備1和設(shè)備2的處理函數(shù)都執(zhí)行一遍。
我們接著往下看會(huì)看到handler下還有一個(gè)thread_fun。還記得我們剛才留下的一個(gè)問題嗎?如果我必須在中斷處理函數(shù)中執(zhí)行很耗時(shí)間的操作該怎么辦?我們可以在handler中執(zhí)行一些最核心的代碼,在這一部分執(zhí)行的代碼是不可以被再次中斷的,然后講不那么重要但需要時(shí)間去運(yùn)算的操作放在thread_fun去操作。當(dāng)handler執(zhí)行完成之后就會(huì)去調(diào)用thread,當(dāng)thread判斷有機(jī)會(huì)執(zhí)行時(shí)候就會(huì)去調(diào)用thread_fun里面的函數(shù)。
上面就是使用request_irq注冊(cè)一個(gè)中斷處理函數(shù)的一個(gè)大致概念,下面鴻蒙的部分我們分析它的調(diào)用流程即可,因?yàn)闀?huì)發(fā)現(xiàn)鴻蒙LiteOS把這一塊處理的十分的簡單
假設(shè)系統(tǒng)發(fā)生中斷,那么會(huì)跳來執(zhí)行b OsIrqHandler。 在OsIrqHandler中會(huì)保存環(huán)境然后禁止中斷等等,然后調(diào)用HalIrqHandler,在HalIrqHandler中
UINT32 iar = GIC_REG_32(GICC_IAR);//讀取GIC里面的寄存器,就可以知道你發(fā)生的是哪一號(hào)中斷。
然后調(diào)用OsInterrupt(vector);來處理這一號(hào)中斷。如何處理呢?
在OsInterrupt里面使用vector取出它的hook函數(shù),這個(gè)hook函數(shù)是什么呢?在我們注冊(cè)的調(diào)用OsHwiCreateShared的時(shí)候會(huì)將hook指向我們的我們的處理函數(shù)

總結(jié)一下

講了中斷這個(gè)概念,是為了解決一個(gè)疑問,就是鴻蒙LiteOS是如何實(shí)現(xiàn)多任務(wù)實(shí)時(shí)操作系統(tǒng)的,所謂的多任務(wù)實(shí)時(shí)操作系統(tǒng)就是在同一個(gè)時(shí)間內(nèi)同時(shí)存在多個(gè)任務(wù)在運(yùn)行。這里的同時(shí)是相對(duì)我們?nèi)烁兄臅r(shí)間,實(shí)際上在操作系統(tǒng)中是通過不斷的任務(wù)切換來分配CPU資源的,只是這種切換的速度足夠的快,以至于人感受不到。那誰來觸發(fā)這個(gè)中斷呢?時(shí)鐘中斷,時(shí)鐘中斷每隔一段時(shí)間就會(huì)觸發(fā)一次來判斷當(dāng)前任務(wù)執(zhí)行的時(shí)間片是否用完,如果用完就切換到下一個(gè)任務(wù)。當(dāng)一個(gè)任務(wù)的時(shí)間全部用完時(shí)候就從執(zhí)行隊(duì)列里面徹底的刪除。

那么鴻蒙是怎么做到這一點(diǎn)的呢?
打開arm_generic_timer.c
在HalClockInit中使用HalClockFreqRead(VOID)讀取時(shí)鐘的頻率。
HalClockFreqRead(VOID)中通過一條協(xié)處理的匯編指令來讀取當(dāng)前的時(shí)鐘頻率
mrc:協(xié)處理器,MCR指令用于將ARM處理器寄存器中的數(shù)據(jù)傳送到協(xié)處理器寄存器中
獲取到時(shí)鐘的頻率之后LOS_HwiCreate(OS_TICK_INT_NUM, MIN_INTERRUPT_PRIORITY, 0, OsTickEntry, 0);來注冊(cè)中斷處理函數(shù)。OsTickEntry是系統(tǒng)時(shí)鐘的滴答中斷,每隔十毫秒產(chǎn)生一次,多任務(wù)的調(diào)度就依賴于這個(gè)系統(tǒng)中斷。
在OsTickEntry中會(huì)調(diào)用到OsTickHandler();里面會(huì)使用OsTaskScan對(duì)多個(gè)任務(wù)進(jìn)行系統(tǒng)掃描,如果當(dāng)前任務(wù)執(zhí)行的時(shí)間已經(jīng)用完就使用LOS_ListDelete移除出去0
字符設(shè)備
在這里我們用內(nèi)存來模擬存儲(chǔ)設(shè)備,存儲(chǔ)設(shè)備就是塊設(shè)備,在Linux中字符設(shè)備和塊設(shè)備,LiteOS也是采用這種模式。
那什么叫字符設(shè)備。簡單的說一個(gè)字節(jié)一個(gè)字節(jié)進(jìn)行讀寫操作的設(shè)備,不能隨機(jī)讀取設(shè)備中的某一數(shù)據(jù)、讀取數(shù)據(jù)要按照先后數(shù)據(jù)。字符設(shè)備是面向流的設(shè)備,常見的字符設(shè)備有鼠標(biāo)、鍵盤、串口、控制臺(tái)和LED等
當(dāng)我們應(yīng)用想去訪問某個(gè)硬件的時(shí)候:使用open、read、write、ioctrl等,比如我要操作一盞燈,如下代碼:
int main(){ int fd1,fd2; int val = 1; fd1 = open(“dev/led”,O_RDWR); write(fd1,&val,4); }
這里的open、write是誰實(shí)現(xiàn)的,在應(yīng)用層下還有一層:C庫,由它來實(shí)現(xiàn),它和應(yīng)用一起都屬于應(yīng)用層,那么C庫是怎么進(jìn)入到內(nèi)核的呢?當(dāng)我們調(diào)用open、read的時(shí)候?qū)嶋H上是執(zhí)行了一個(gè)swi val指令,這條指令會(huì)產(chǎn)生一個(gè)異常(也就是中斷),當(dāng)產(chǎn)生這個(gè)異常時(shí)就會(huì)觸發(fā)內(nèi)核的異常處理函數(shù)。
那么誰來處理這個(gè)異常指令呢,在內(nèi)核里面有一個(gè)系統(tǒng)調(diào)用接口,它用來處理swi val指令,通過value來判斷中斷發(fā)生的原因調(diào)用對(duì)應(yīng)的處理函數(shù)。比如說應(yīng)用層調(diào)用open的時(shí)候傳進(jìn)來的val值為1,read的值為2 ,那么系統(tǒng)調(diào)用就會(huì)根據(jù)1和2分別調(diào)用sys_open,sys_read,這個(gè)sys_open,sys_read隸屬于VFS虛擬文件系統(tǒng)這一層
那么當(dāng)我應(yīng)用使用open(“/dev/led0”,XXX)的時(shí)候,系統(tǒng)是如何判斷“/dev/led0”是字符設(shè)備還是后面要說的塊設(shè)備呢?
在Linux中我們可以通過ls -l來列出當(dāng)前目錄下的所有東西,cd到/dev/目錄下,這里存放設(shè)備中的驅(qū)動(dòng)程序。
使用ls -l就可以看到這些設(shè)備的詳細(xì)信息,最左側(cè)c、d、b代表的是對(duì)應(yīng)的設(shè)備類型:c表示字符設(shè)備、d表示目錄、b表示塊設(shè)備。系統(tǒng)通過這個(gè)來判斷要調(diào)用的是那種類型的設(shè)備驅(qū)動(dòng)。但是有這個(gè)還不夠,區(qū)分完是字符設(shè)備驅(qū)動(dòng)后,我們?cè)趺床拍苤朗悄膫€(gè)驅(qū)動(dòng)程序呢?這就需要主設(shè)備號(hào),內(nèi)核通過一個(gè)散列表(哈希表)來記錄設(shè)備編號(hào),哈希表由數(shù)組和鏈表組成,里面存放著一堆驅(qū)動(dòng)程序的結(jié)構(gòu)體file_operation。系統(tǒng)通過主設(shè)備號(hào)通過一個(gè)計(jì)算公式獲得這個(gè)數(shù)組的下標(biāo),取出結(jié)構(gòu)體。然后就執(zhí)行這個(gè)file_operation下的驅(qū)動(dòng)程序。那誰來填充這個(gè)數(shù)組呢?當(dāng)編寫完驅(qū)動(dòng)程序里file_operation中的所有函數(shù)的時(shí)候,會(huì)使用register_chrdev(主設(shè)備號(hào),次設(shè)備號(hào),“/dev/led0“,file_operation),向上注冊(cè)這個(gè)結(jié)構(gòu)體。

塊設(shè)備
那么什么叫做塊設(shè)備驅(qū)動(dòng)呢?
塊設(shè)備對(duì)應(yīng)的就是磁盤、FLASH,你要去讀寫它的時(shí)候需要以一個(gè)扇區(qū)為讀寫單位。對(duì)于這個(gè)設(shè)備、Linux里面采用了一個(gè)叫做電梯原理的算法,如下圖,假設(shè)先要讀取扇區(qū)1的數(shù)據(jù)、然后到扇區(qū)3中寫數(shù)據(jù)、再到扇區(qū)2讀數(shù)據(jù)。如果使用字符設(shè)備驅(qū)動(dòng),就是這么個(gè)流程,此時(shí)磁頭要跳轉(zhuǎn)兩次,效率很低,塊設(shè)備將其進(jìn)行優(yōu)化,同個(gè)扇區(qū)先操作,其他扇區(qū)的操作先放到隊(duì)列里面,等執(zhí)行完后再跳轉(zhuǎn)到另一個(gè)扇區(qū)進(jìn)行操作,這樣整體的操作就會(huì)提高。
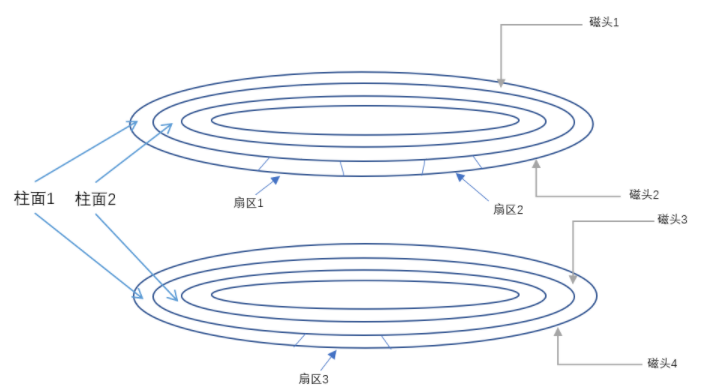
上面是硬盤,那么對(duì)于FLASH,塊設(shè)備是如何進(jìn)行操作的呢

假設(shè)我要去 扇區(qū)0中寫數(shù)據(jù),寫完之后再去扇區(qū)1寫數(shù)據(jù),那么使用字符設(shè)備會(huì)有怎么個(gè)操作呢,因?yàn)镕LASH要先擦除才能夠?qū)懀脸钦麎K整塊擦除的,那么為了保證其他的數(shù)據(jù)不被意外擦除,就要先把整塊數(shù)據(jù)讀到一個(gè)buffer里面,修改buffer里的扇區(qū)0,然后擦除整塊,再把這塊buffer燒寫進(jìn)去,寫扇區(qū)1也是如此
整個(gè)流程即:讀整塊數(shù)據(jù)到buffer ---》 修改扇區(qū)0的數(shù)據(jù) ---》 擦除塊里面的數(shù)據(jù) ---》 燒寫數(shù)據(jù)到塊里面 ---》 讀整塊數(shù)據(jù)到buffer ---》 修改扇區(qū)1的數(shù)據(jù) ---》 擦除塊里面的數(shù)據(jù) ---》 燒寫數(shù)據(jù)到塊里面
這樣非常的麻煩,那么塊設(shè)備是如何去操作的呢?
首先,先把所有操作放入隊(duì)列,然后進(jìn)行優(yōu)化:讀整塊數(shù)據(jù)到buffer ---》 修改扇區(qū)0和1的數(shù)據(jù) ---》 擦除塊里面的數(shù)據(jù) ---》 燒寫數(shù)據(jù)到塊里面
上面的操作和生活中的坐電梯很像,這次先把要上去的通通一層一層的送到,等上電梯的這批人都上樓了,再到各層把要下樓的乘客運(yùn)下去,這就是電梯算法(Noop)。所以可以先總結(jié)一下塊設(shè)備的操作是:先把所有的“讀寫”操作放入隊(duì)列里面,再其優(yōu)化后再執(zhí)行。
然而Linux對(duì)IO的操作不止使用了這一種算法,還有電梯算法里還包含了另外兩種常見的算法CFQ 和DeadLine。
那么塊設(shè)備驅(qū)動(dòng)的框架是什么呢?如下圖:
假設(shè)我現(xiàn)在要通過open、read、write一個(gè)普通的文本文件“1.txt”,操作這個(gè)文本文件其實(shí)最終是操作某個(gè)硬件,那對(duì)這個(gè)文本文件的讀寫怎么轉(zhuǎn)換成對(duì)塊設(shè)備也就是硬盤或FLASH等里面扇區(qū)的讀寫?這里面肯定需要一個(gè)轉(zhuǎn)換,這里就需要一個(gè)文件系統(tǒng):vfat、ext2、ext3、yaffs等等各種文件系統(tǒng)。
那么ll_rw_block主要是干什么的呢?就是我們上面說的:把“讀寫”放入隊(duì)列 -- 》 調(diào)用隊(duì)列的處理函數(shù),優(yōu)化執(zhí)行

Linux源碼分析:
那么Linux是如何寫塊設(shè)備驅(qū)動(dòng)程序
1、分配gendisk:alloc_disk
2、分配/設(shè)置隊(duì)列:request_queue_t
blk_init_queue
3、設(shè)置gendisk其他信息
4、注冊(cè):add_disk
HDF分析

再來回顧一下鴻蒙的整個(gè)框架,我們剛剛講了應(yīng)用層框架是如何實(shí)現(xiàn)跨平臺(tái)調(diào)度的,也就是系統(tǒng)基本能力子系統(tǒng)集中的分布式任務(wù)調(diào)度和軟總線。也講了Linux和LiteOS內(nèi)核的一些知識(shí)點(diǎn)和差異,那么在右下角還有一個(gè)HDF(鴻蒙驅(qū)動(dòng)框架),這個(gè)HDF是什么呢?它的全稱是Harmony Driver Framework。HDF的提出也是為剛剛所說的一次開發(fā)多端部署做準(zhǔn)備的,舉個(gè)例子,我開發(fā)了一套點(diǎn)燈的應(yīng)用程序,那么我在不同板子上可能使用的是不同的內(nèi)核,那么肯定就會(huì)有不同的庫。HDF就是抽象出這些不同中的共性。
我們可以回憶一下單片機(jī)開發(fā)的一個(gè)場景,當(dāng)你要去操作某個(gè)引腳,那么需要做到的步驟就是:查閱手冊(cè)(這是必須操作)-》在程序中指定這個(gè)引腳然后初始化它-》賦值。當(dāng)我們變更了芯片或者板子的時(shí)候,引腳的作用可能會(huì)發(fā)生改變,這時(shí)候,你又需要去修改程序中的引腳。這樣是非常麻煩的。在Linux3.x之前的內(nèi)核源碼中,也是這樣存在大量對(duì)板級(jí)細(xì)節(jié)信息描述的代碼。這些代碼充斥在/arch/arm/plat-xxx和/arch/arm/mach-xxx目錄,這種編寫方式被Linux之父托瓦茲怒斥為辣雞代碼。自此之后,Linux內(nèi)核引入了設(shè)備樹機(jī)制以描述計(jì)算機(jī)板機(jī)底層硬件信息。
編輯:hfy
-
Linux
+關(guān)注
關(guān)注
87文章
11479瀏覽量
213053 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
7113瀏覽量
125117 -
鴻蒙系統(tǒng)
+關(guān)注
關(guān)注
183文章
2641瀏覽量
67839
發(fā)布評(píng)論請(qǐng)先 登錄
【精品連載】韋東山老師帶你上手鴻蒙內(nèi)核Liteos-a開發(fā)
鴻蒙介紹--韋東山老師帶你上手鴻蒙內(nèi)核Liteos-a開發(fā)
韋東山老師B站鴻蒙OS系統(tǒng)移植直播答疑問題錦集
鴻蒙是一套龐大的體系,底層支持很多內(nèi)核吧?liteos-m, liteos-a,linux 都支持?
【HarmonyOS】鴻蒙Liteos-a內(nèi)核移植手冊(cè)(PDF下載)
【HarmonyOS】鴻蒙HarmonyOS系統(tǒng)開源地址,鴻蒙OS、LiteOS和智慧屏三者關(guān)系
如何修改uboot引導(dǎo)鴻蒙內(nèi)核liteos.bin
鴻蒙liteos-m移植
鴻蒙liteos-m移植2
制作一個(gè)在qemu上運(yùn)行鴻蒙的liteos-m內(nèi)核
鴻蒙跟Linux的關(guān)系以及什么是Liteos-a
鴻蒙系統(tǒng) IO棧和Linux IO棧對(duì)比分析
如何區(qū)分鴻蒙跟 Linux ?Liteos-a 是什么?

鴻蒙liteos-a系統(tǒng)入門實(shí)戰(zhàn)直播亮點(diǎn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論