 select語句和update語句分別是怎么執行的
select語句和update語句分別是怎么執行的
最近有粉絲面試互聯網公司被問到:你知道select語句和update語句分別是怎么執行的嗎?,要我寫一篇這兩者執行SQL語句的區別,這不就來了。
總的來說,select和update執行的邏輯大體一樣,但是具體的實現還是有區別的。
當然深入了解select和update的具體區別并不是只為了面試,當希望Mysql能夠高效的執行的時候,最好的辦法就是清楚的了解Mysql是如何執行查詢的,只有更加全面的了解SQL執行的每一個過程,才能更好的進行SQl的優化。
select語句
當執行一條查詢的SQl的時候大概發生了以下的步驟:
客戶端發送查詢語句給服務器。
服務器首先進行用戶名和密碼的驗證以及權限的校驗。
然后會檢查緩存中是否存在該查詢,若存在,返回緩存中存在的結果。若是不存在就進行下一步。
接著進行語法和詞法的分析,對SQl的解析、語法檢測和預處理,再由優化器生成對應的執行計劃。
Mysql的執行器根據優化器生成的執行計劃執行,調用存儲引擎的接口進行查詢。
服務器將查詢的結果返回客戶端。
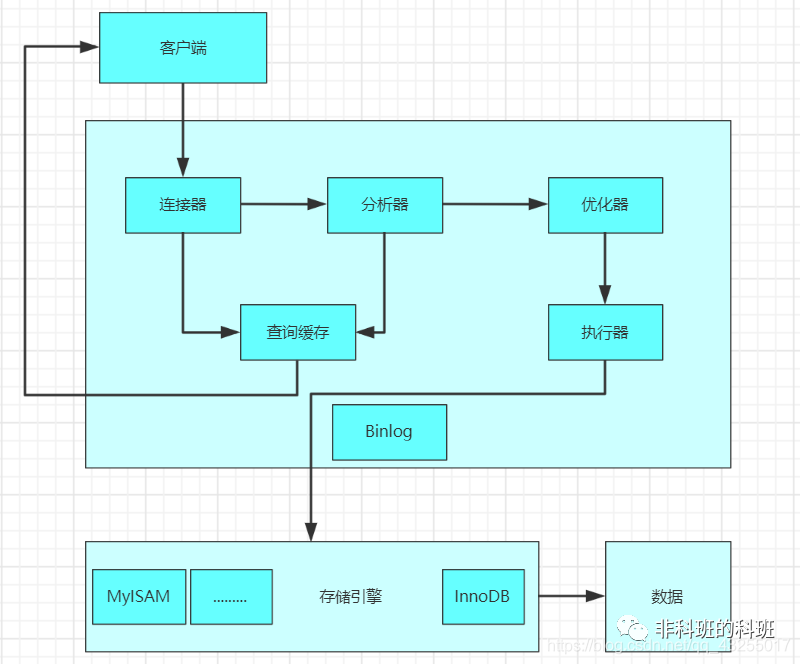
執行的流程
Mysql中語句的執行都是都是分層執行,每一層執行的任務都不同,直到最后拿到結果返回,主要分為Service層和引擎層,在Service層中包含:連接器、分析器、優化器、執行器。引擎層以插件的形式可以兼容各種不同的存儲引擎。
Mysql的執行的流程圖如下圖所示:
這里以一個實例進行說明Mysql的的執行過程,新建一個User表,如下:
//新建一個表 DROPTABLEIFEXISTSUser; CREATETABLE`User`( `id`int(11)NOTNULLAUTO_INCREMENT, `name`varchar(10)DEFAULTNULL, `age`intDEFAULT0, `address`varchar(255)DEFAULTNULL, `phone`varchar(255)DEFAULTNULL, `dept`int, PRIMARYKEY(`id`) )ENGINE=InnoDBAUTO_INCREMENT=40DEFAULTCHARSET=utf8; //并初始化數據,如下 INSERTINTOUser(name,age,address,phone,dept)VALUES('張三',24,'北京','13265543552',2); INSERTINTOUser(name,age,address,phone,dept)VALUES('張三三',20,'北京','13265543557',2); INSERTINTOUser(name,age,address,phone,dept)VALUES('李四',23,'上海','13265543553',2); INSERTINTOUser(name,age,address,phone,dept)VALUES('李四四',21,'上海','13265543556',2); INSERTINTOUser(name,age,address,phone,dept)VALUES('王五',27,'廣州','13265543558',3); INSERTINTOUser(name,age,address,phone,dept)VALUES('王五五',26,'廣州','13265543559',3); INSERTINTOUser(name,age,address,phone,dept)VALUES('趙六',25,'深圳','13265543550',3); INSERTINTOUser(name,age,address,phone,dept)VALUES('趙六六',28,'廣州','13265543561',3); INSERTINTOUser(name,age,address,phone,dept)VALUES('七七',29,'廣州','13265543562',4); INSERTINTOUser(name,age,address,phone,dept)VALUES('八八',23,'廣州','13265543563',4); INSERTINTOUser(name,age,address,phone,dept)VALUES('九九',24,'廣州','13265543564',4);
現在針對這個表發出一條SQl查詢:查詢每個部門中25歲以下的員工個數大于3的員工個數和部門編號,并按照人工個數降序排序和部門編號升序排序的前兩個部門。
SELECTdept,COUNT(phone)ASnumFROMUserWHEREage=3ORDERBYnumDESC,deptASCLIMIT0,2;
連接器
開始執行這條sql時,首先會校驗你的用戶名和密碼是否正確,若是不正確會返回錯誤信息:"Access denied for user";
若是用戶名和密碼校驗通過,然后就會到權限表獲取當前用戶擁有的權限,會檢查該語句是否有權限,若是沒有權限就直接返回錯誤信息,有權限會進行下一步,校驗權限的這一步是在圖一的連接器進行的,對連接用戶權限的校驗。
注意:后續的一些列操作都是依賴于這個權限的范圍內的。
檢索緩存
當建立連接,履行查詢語句的時候,會先行檢查在緩存區域看看這個sql與否履行過,若是之前執行過,它的執行結果會以Key-Value的形式緩存于內存中,Key是執行的sql,Value是結果集。
假如,緩存中key遭擊中,便會直接將結果返回給客戶端,假如沒命中,便會履行后續的操作,完工之后亦會將結果緩存起來以便再次查詢獲取,當下一次進行查詢的時候也是如此的循環操作。
注意:Mysql中的緩存比較適合于那些靜態的表,更新不頻繁的表,因為只要當前表有數據更新,有關于該表的緩存就會失效,若是表更新頻繁緩存頻繁的失效,這樣維護緩存的消耗的性能遠大于使用緩存帶來的性能優化,這樣就會得不償失,嚴重影響Mysql的性能,所以在Mysql 8版本中的時候把緩存這一塊給砍掉了。
在個人的觀點中對于緩存這一塊的看法是,沒必要砍掉,可以設置成默認關閉緩存,需要的時候再設置開啟,并且可以通過配置參數指定特定的表使用緩存,那些表不使用緩存,這樣或許使用緩存更有效。
分析器
分析器主要有兩步:(1)詞法分析(2)語法分析
詞法分析主要執行提煉關鍵性字,比如select,提交檢索的表,提交字段名,提交檢索條件,確定該語句是select還是update或者是delete語句。
語法分析主要執行辨別你輸出的sql與否準確,是否合乎mysql的語法,若是不符合sql語法就會拋出:You have an error in your SQL syntax。
優化器
查詢優化器會將解析樹轉化成執行計劃。一條查詢可以有多種執行方法,最后都是返回相同結果。優化器的作用就是找到這其中最好的執行計劃。
例如:在查詢語句中有多個索引的時候,優化器決定使用哪一個索引,或者有多表關聯的時候,決定表的連接順序等這些操作都是在優化器決定的。
生成執行計劃的過程會消耗較多的時間,特別是存在許多可選的執行計劃時。如果在一條SQL語句執行的過程中將該語句對應的最終執行計劃進行緩存。
當相似的語句再次被輸入服務器時,就可以直接使用已緩存的執行計劃,從而跳過SQL語句生成執行計劃的整個過程,進而可以提高語句的執行速度。
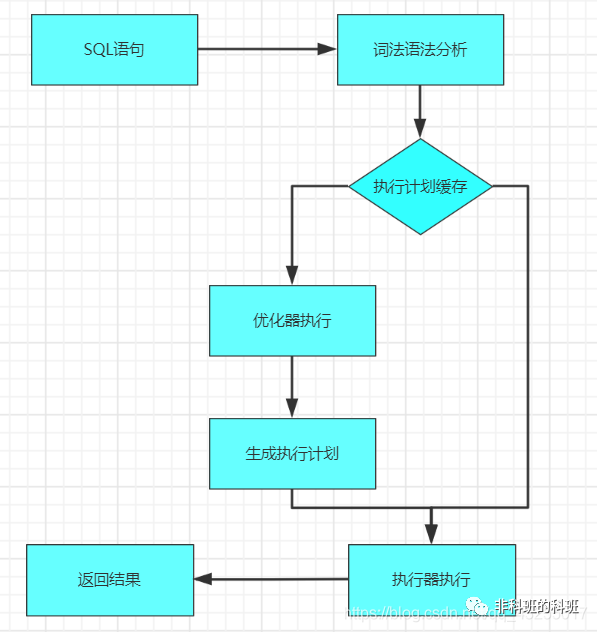
MySQL使用基于成本的查詢優化器。它會嘗試預測一個查詢使用某種執行計劃時的成本,并選擇其中成本最少的一個。
執行器
優化器生成得執行計劃,交由執行器進行執行,執行器調用存儲引擎得讀接口,執行器中循環的調用存儲引擎的讀接口,以此換取滿足條件的數據行,并把它放在一個結果集中,遍歷并獲取了所有滿足條件的數據行,最后將結果集返回,結束整個查詢得過程。
update語句
上面我們說完了select語句,select語句的執行過程會經過連接器、分析器、優化器、執行器、存儲引擎,同樣的update語句也會同樣走一遍select語句的執行過程。
但是和select最大不同的是,update語句會涉及到兩個日志的操作redo log(重做日志)和binlog(歸檔日志)。對于這兩個日志的詳細介紹,我之前寫過一篇文章進行介紹,有興趣的可以看一看[]:
那么Mysql中又是怎么使用redo log和binlog?為什么要使用redo log和binlog呢?直接執行更新然后存庫不就行了嗎?還要放在redo log和binlog中,這不是多此一舉嗎?且聽我慢慢道來,這里面大有文章。
redo log
大家都是知道Mysql是關系型數據庫,用來存儲數據的,在訪問數據庫量大的時候,Mysql讀寫磁盤訪問的效率是非常低的,加上sql中的條件對數據的篩選過濾,那么效率就更低了。
這也是為什么引入非關系型數據庫作為作為數據緩存原因,例如:Redis、MongoDB等,就是為了減少sql執行期間的數據庫io操作。
同樣的道理,若是每次執行update語句都要進行磁盤的io操作、以及數據的過濾篩選,小量的訪問和數據量數據庫還可以撐住,那么訪問量一大以及數據量一大,這樣數據庫肯定頂不住。
基于上面的問題于是出現了redo log日志,redo log日志也叫做WAL技術(Write- Ahead Logging),他是一種先寫日志,并更新內存,最后再更新磁盤的技術,并且更新磁盤往往是在Mysql比較閑的時候,這樣就大大減輕了Mysql的壓力。
redo log的特點就是:redo log是固定大小,是物理日志,屬于InnoDB引擎的,并且寫redo log是環狀寫日志的形式:
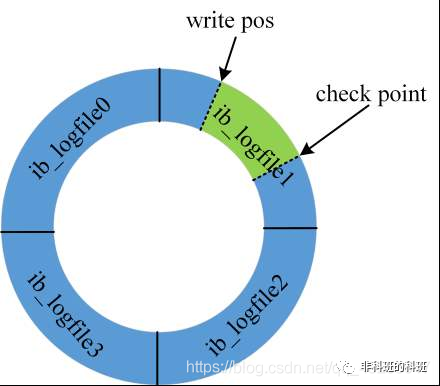
如上圖所示:若是四組的redo log文件,一組為1G的大小,那么四組就是4G的大小,其中write pos是記錄當前的位置,有數據寫入當前位置,那么write pos就會邊寫入邊往后移。
而check point是擦除的位置,因為redo log是固定大小,所以當redo log滿的時候,也就是write pos追上check point的時候,需要清除redo log的部分數據,清除的數據會被持久化到磁盤中,然后將check point向前移動。
redo log日志實現了即使在數據庫出現異常宕機的時候,重啟后之前的記錄也不會丟失,這就是crash-safe能力。
binlog
binlog稱為歸檔日志,是邏輯上的日志,它屬于Mysql的Server層面的日志,記錄著sql的原始邏輯,主要有兩種模式,一個是statement格式記錄的是原始的sql,而row格式則是記錄行內容。
那么這樣看來redo log和binlog雖然記錄的形式、內容不同,但是這兩者日志都能通過自己記錄的內容恢復數據,那么為什么還要這兩個日志同時存在呢?只要其中一個不就行了嘛,兩個同時存在不就多此一舉了嘛。且聽我慢慢道來,這里面也大有文章。
因為剛開Mysql自帶的引擎MyISAM就沒有crash-safe功能的,并且在此之前Mysql還沒有InnoDB引擎,Mysql自帶的binlog日志只是用來歸檔日志的,所以InnoDB引擎也就通過自己redo log日志來實現crash-safe功能。
update執行過程
上面說了那么久兩種日志的作用和特點,那么這兩種日志究竟和update執行語句有什么關系呢?
先來看圖:
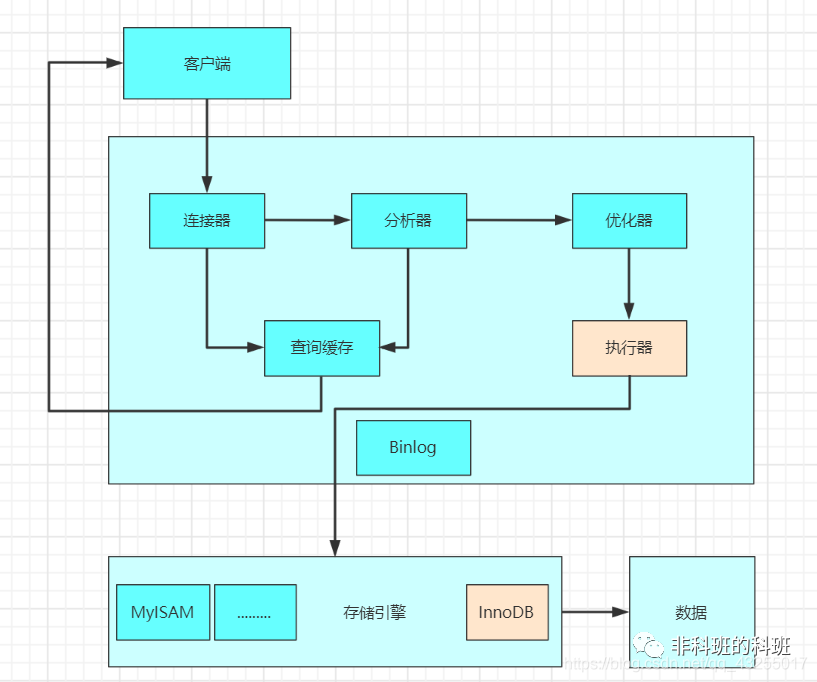
前提:當前的引擎是使用InnoDB,update語句與select語句區別主要是這兩日志的使用主要是在執行器和引擎之間進行交互時體現的區別。假如執行如下一條簡單的更新語句是:
updateusersetage=age+1whereid =2;
上面說過select語句走過的流程update語句也會走一遍,當來到執行器的時候:
執行器會調用引擎的讀接口,然后找到id=2的數據行,因為id是主鍵索引,索引按照樹的搜索找到這一行,若是數據行已經存在于內存的數據頁中就會立即將結果返回,若是不在內存中,就會從磁盤中進行加載到內存中,然后將查詢的結果返回。
然后,執行器將返回的結果的age字段+1,并調用引擎的寫接口寫入更新后的數據行。
引擎獲取到更新后的數據行更新到內存和redo log中,并告訴執行器可以隨時提交事務,此時的redo log處于prepare階段。
執行器收到引擎的告知后,生成binlog日志,并且調用引擎的接口提交事務,引擎將redo log的狀態修改為commit狀態,這樣這個更新操作算是完成。
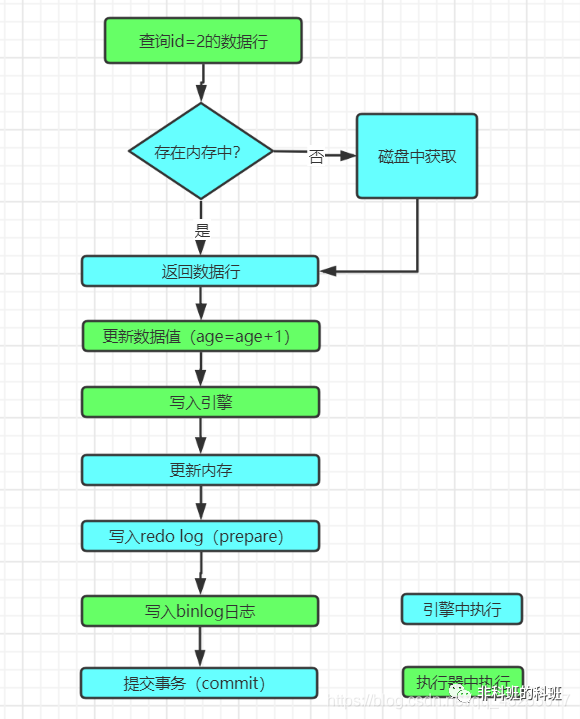
與select語句相比,因為select沒有更新數據,只是將引擎查詢的數據返回給執行器就算是完后,而update涉及數據的更新并且重新調用引擎接口寫會存儲引擎中的交互過程。
兩階段提交
上面詳細的說了update語句的執行流程,提到了redo log的prepare和commit兩個階段,這就是兩階段提交,兩階段提交的目的是為了保證redo log日志與binlog日志保持數據的一致性。
若是redo log寫成功binlog寫失敗,或者redo log寫失敗binlog寫成功,最后使用這兩者日志進行數據恢復得到的結果數據都是不一致性的,所以為了保證兩個日志邏輯上的一致,使用兩階段進行提交。
redo log與binlog的總結
最后來對比一下這兩種日志:redo是物理的,binlog是邏輯的,redo的大小固定,并且以環狀的形式寫入數據,數據滿的時候需要將redo日志中擦除數據,并且將擦除的數據持久化到磁盤中。
而binlog以追加日志的形式寫入,也就是當日志寫到一定大小后,就會切換到下一個,并不會覆蓋以前寫的日志。
binlog是在Mysql的Server層中使用,因為binlog沒有crash-safe功能,所以InnoDB引擎自己實現了redo log日志的crash-safe的功能,為了保證這兩個日志邏輯上的一致使用兩階段提交。
在使用redo和binlog這兩種日志的時候,可以將參數innodb_flush_log_at_trx_commit和sync_binlog都設置為1,它表示每次事務提交的時候,都會將日志持久化到磁盤中。
責任編輯:xj
原文標題:面試官:你知道 select 語句和 update 語句分別是怎么執行的嗎?
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
-
MySQL
+關注
關注
1文章
849瀏覽量
27661 -
SQL語句
+關注
關注
0文章
19瀏覽量
7157 -
select
+關注
關注
0文章
28瀏覽量
4073
原文標題:面試官:你知道 select 語句和 update 語句分別是怎么執行的嗎?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
《ESP32S3 Arduino開發指南》第三章 C/C++語言基礎
詳解TIA Portal SCL編程語言中的IF語句
深入理解C語言:C語言循環控制

如何一眼定位SQL的代碼來源:一款SQL染色標記的簡易MyBatis插件

深入理解C語言:循環語句的應用與優化技巧

技術干貨驛站 ▏深入理解C語言:掌握C語言條件判斷,從if到switch的應用
Linux--IO多路復用(select,poll,epoll)
LTspice的編程語句應該怎么寫?
負載均衡服務由幾部分組成?分別是什么
域名、IP 地址、網址分別是什么?有什么區別呢?

嵌入式學習-飛凌嵌入式ElfBoard ELF 1板卡-shell腳本編寫之流程控制
計算機程序的三種基本控制結構是什么
飛凌嵌入式ElfBoard ELF 1板卡-shell腳本編寫之流程控制
使用ChatGPT解決開發問題






 工商網監
工商網監
評論