 卡內基梅隆大學的研究人員開發了一種機器學習模型
卡內基梅隆大學的研究人員開發了一種機器學習模型

AI可能很快就會成為盟友,以消除語音助手的喚醒詞。卡內基梅隆大學的研究人員開發了一種機器學習模型,該模型可以估計語音的發出方向,無需特殊的短語或手勢即可表明您的意圖。該方法依賴于聲音在房間周圍反彈時的固有特性。
系統認識到,第一個,最響亮和最清晰的聲音始終是直接針對給定對象的聲音。其他任何事情都傾向于安靜,延遲和悶悶不樂。該模型還知道,人類的語音頻率會根據您所面對的方向而變化。較低的頻率傾向于全向。
研究人員補充說,這種方法基于軟件“輕巧”,不需要將音頻數據發送到云。
盡管團隊已經公開發布了代碼和數據來幫助其他人繼續工作,但是您可能還需要一段時間才能看到使用的技術。至少很容易看出這可能導致什么。您可以告訴智能揚聲器播放音樂,而無需使用喚醒詞或引起大量其他連接設備的騷擾。它可能需要您的身體狀態,而無需使用注視檢測相機,從而有助于保護隱私。換句話說,它將更接近“星際迷航”中語音助手的愿景,后者始終會在您與他們交談時知道。
責任編輯:lq
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
代碼
+關注
關注
30文章
4899瀏覽量
70638 -
機器學習
+關注
關注
66文章
8501瀏覽量
134537 -
語音助手
+關注
關注
7文章
241瀏覽量
27150
發布評論請先 登錄
相關推薦
熱點推薦
無刷直流電機雙閉環串級控制系統仿真研究
Madlab進行BLDC建模仿真的方法,并且也提出了很多的建模仿真方案。例如有研究人員提出采用節點電流法對電機控制系統進行分析,通過列寫m函數,建立BLDC控制系統真模型,這種方法實質上是一種整體建模
發表于 07-07 18:36
輪式移動機器人電機驅動系統的研究與開發
系統,開發了一套二輪差速驅動轉向移動機器人電機驅動系統,完成了系統各部件的整體裝配和調試。試驗結果表明,該設計方案可行、系統運行穩定可靠、成本低廉、所用元件易于購置,具有較好的實用的價值和應用前景。
純
發表于 06-11 14:30
研究人員開發出基于NVIDIA技術的AI模型用于檢測瘧疾
瘧疾曾一度在委內瑞拉銷聲匿跡,但如今正卷土重來。研究人員已經訓練出一個模型來幫助檢測這種傳染病。
NanoEdge AI Studio 面向STM32開發人員機器學習(ML)技術
NanoEdge? AI Studio*(NanoEdgeAIStudio)是一種新型機器學習(ML)技術,可以讓終端用戶輕松享有真正的創新成果。只需幾步,開發人員便可基于最少量的數據
機器學習模型市場前景如何
當今,隨著算法的不斷優化、數據量的爆炸式增長以及計算能力的飛速提升,機器學習模型的市場前景愈發廣闊。下面,AI部落小編將探討機器學習
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
的局限性以及衡量大模型的關鍵指標。閱讀了該部分后,我感受到了一種前所未有的震撼,這種震撼不僅來源于技術本身的先進性,更來源于它對傳統機器人控制方式的顛覆。
傳統機器人的局限性與大
發表于 12-29 23:04
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》 一書由甘一鳴、俞波、萬梓燊、劉少山老師共同編寫,其封面如圖1所示。
本書共由5部分組成,其結構和內容如圖2所示。
該書可作為高校和科研機構的教材,為學生和研究人員
發表于 12-20 19:17
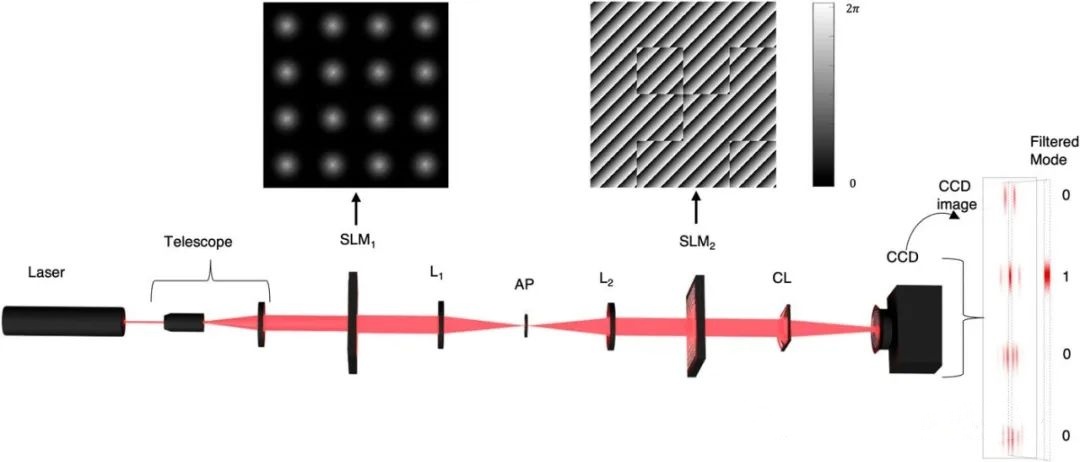
研究人員利用激光束開創量子計算新局面
演示設備 威特沃特斯蘭德大學(Wits)的物理學家利用激光束和日常顯示技術開發出了一種創新的計算系統,標志著在尋求更強大的量子計算解決方案方面取得了重大飛躍。 該大學結構光實驗室的
NaVILA:加州大學與英偉達聯合發布新型視覺語言模型
日前,加州大學的研究人員攜手英偉達,共同推出了一款創新的視覺語言模型——NaVILA。該模型在機器
一種信息引導的量化后LLM微調新算法IR-QLoRA
進行量化+LoRA的路線為例,有研究表明,現有方法會導致量化的LLM嚴重退化,甚至無法從LoRA微調中受益。 為了解決這一問題,來自蘇黎世聯邦理工學院、北京航空航天大學和字節跳動的研究人員

AI大模型與深度學習的關系
AI大模型與深度學習之間存在著密不可分的關系,它們互為促進,相輔相成。以下是對兩者關系的介紹: 一、深度學習是AI大模型的基礎 技術支撐 :
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
案例,展示如何針對機器學習應用進行需求分析、設計與實現。
無論是高等院校計算機與人工智能等相關專業的本科生或研究生,還是對并行計算技術、云計算技術、高性能存儲及高性能網絡技術感興趣的研究人員
發表于 08-16 18:33
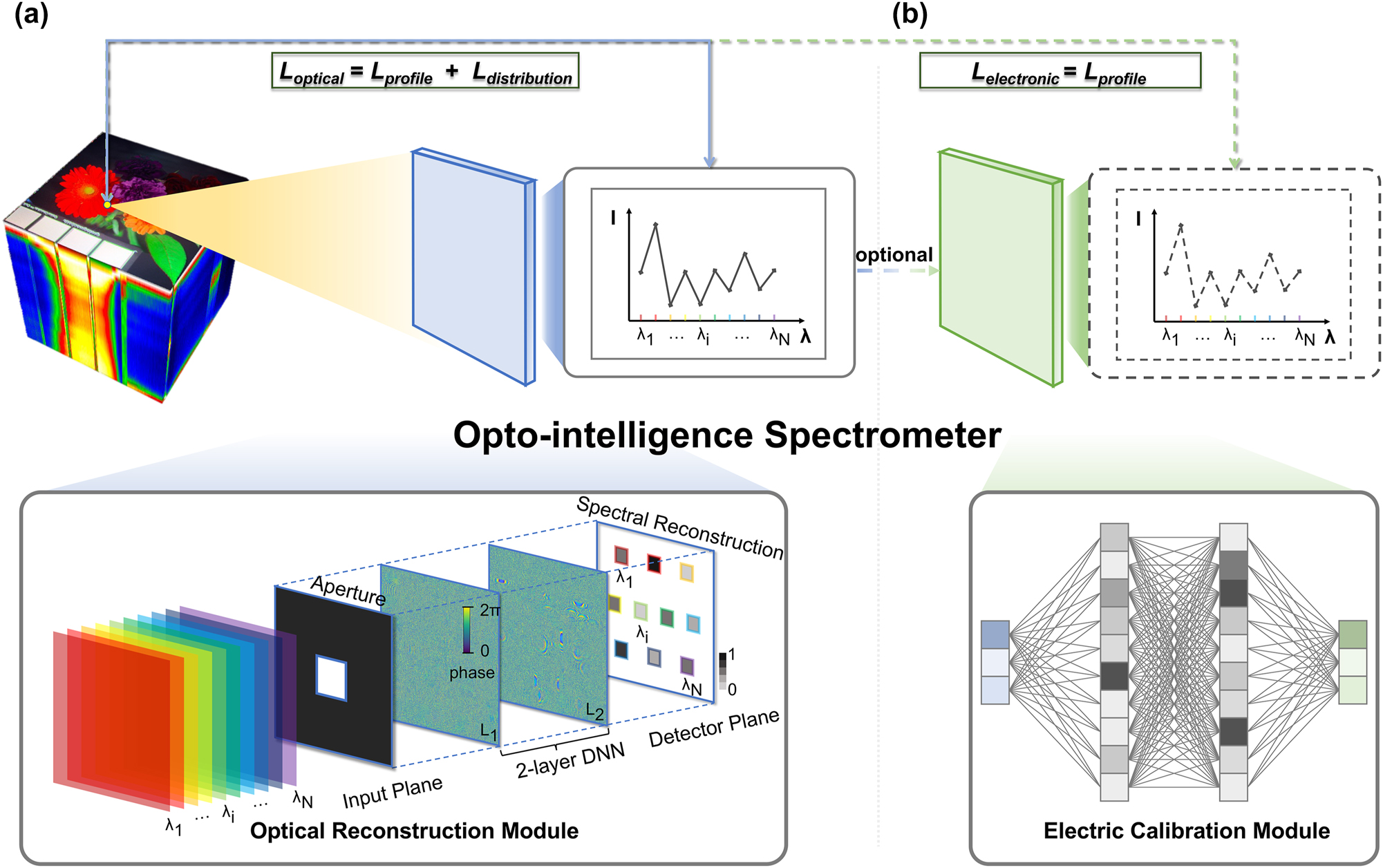
一種新型全光學智能光譜儀
近日,北京理工大學光電學院許廷發教授科研團隊與清華大學林星助理教授團隊聯合開發了一種新型全光學智能光譜儀(Opto-Intelligence Spectrometer, OIS)。
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
上周收到《大語言模型應用指南》一書,非常高興,但工作項目繁忙,今天才品鑒體驗,感謝作者編寫了一部內容豐富、理論應用相結合、印刷精美的著作,也感謝電子發燒友論壇提供了一個讓我了解大語言
發表于 07-21 13:35





 工商網監
工商網監
評論