") 會(huì)話式機(jī)器閱讀理解概述
會(huì)話式機(jī)器閱讀理解概述

1
會(huì)話式機(jī)器閱讀理解是什么?
如何在會(huì)話式閱讀理解里面能夠建模它的implicative reasoning,即如何去學(xué)習(xí)會(huì)話與閱讀理解篇章之間的蘊(yùn)含關(guān)系。 在這篇文章中,講者概述了兩種常見(jiàn)閱讀理解的類型: 第一種是標(biāo)準(zhǔn)的閱讀理解,該模式是指,給定一篇描述型的文章和一個(gè)基于事實(shí)型的問(wèn)題,通過(guò)匹配文章和問(wèn)題,從文章中抽取一個(gè)span來(lái)回答這個(gè)問(wèn)題; 第二種是會(huì)話式的問(wèn)答,與標(biāo)準(zhǔn)的單輪問(wèn)答不同,需要追問(wèn)新問(wèn)題,即follow up question,同時(shí)問(wèn)題是以交互的形式出現(xiàn)。會(huì)話式問(wèn)答,存在兩個(gè)挑戰(zhàn),一個(gè)是需要能理解篇章,另一個(gè)是能夠理解交互的會(huì)話本身。 基于會(huì)話式問(wèn)答,講者引入一個(gè)例子簡(jiǎn)單說(shuō)明(圖1)。
比如,用戶簡(jiǎn)單描述了自己的情況(Scenario),但用戶的問(wèn)題并不能直接從文章(Rule Text)中獲取,往往這個(gè)文章可能是一個(gè)比較通用的、相當(dāng)于是一個(gè)法規(guī)或者法律的篇章。 比如,說(shuō)明能夠申請(qǐng)7a貸款的人,需要具備什么樣的條件,但針對(duì)用戶問(wèn)題在文章中沒(méi)有直接的答案,必須和用戶進(jìn)行一個(gè)交互,才能得到明確的回答。例子中,成功申請(qǐng)貸款的條件有三個(gè),所以還需再問(wèn)另外的條件。 比如,能不能夠在別的地方獲取它的資金來(lái)源,假如用戶說(shuō)no的話,這時(shí)候就可以給他一個(gè)答案,也就是說(shuō)你可以申請(qǐng)。 因此,在這種情形下,就需要既能夠讀懂這篇文章,理解文章中的規(guī)則,也要能夠主動(dòng)地和用戶交互,從用戶那邊獲取一些需要知道的信息,最終再給他一個(gè)決策。
圖1 定義該項(xiàng)任務(wù)常用的數(shù)據(jù)集是ShARC (shaping answers with rules through conversation 的簡(jiǎn)稱),數(shù)據(jù)集的設(shè)定是:給定Rule Text;用戶描述自己的Scenario(Background);用戶提出question;已有的問(wèn)答(Dialog History)。 整個(gè)過(guò)程可以概述為,由于用戶給定的background往往不明確,機(jī)器需要進(jìn)行幾輪交互,然后從交互中獲取一些跟規(guī)則有關(guān)的信息,然后告訴用戶具體答案。 整個(gè)任務(wù)有兩個(gè)子任務(wù): 任務(wù)一,整合Rule Text,Scenario,Question以及通過(guò)幾輪交互從用戶獲取的信息,作為模型輸入,然后做出決策(Decision Making)。
該決策包含四種類型:一種是根據(jù)現(xiàn)有的信息能夠作出yes or no 的決策;或者有些情況下,用戶的問(wèn)題可能與給定Rule Text無(wú)關(guān),或根據(jù)Rule Text并不能解決問(wèn)題,則會(huì)出現(xiàn)unanswerable的答案;另一種情況是Rule Text中需要滿足很多條件,但有些條件機(jī)器不確定是否滿足,需要作出inquire的決策,主動(dòng)從用戶那里獲取更多信息,直至幾輪交互后能夠作出yes or no的決策。 任務(wù)二,如果生成的決策是inquire,則需要機(jī)器問(wèn)一個(gè)follow-up question,該問(wèn)題能根據(jù)Rule Text引導(dǎo)用戶提供一些沒(méi)有提供的信息,便于進(jìn)一步的決策。
圖2 2
會(huì)話式機(jī)器閱讀理解的初探
2.1 模型介紹 負(fù)采樣 針對(duì)于該任務(wù),講者主要介紹了兩項(xiàng)工作,首先是發(fā)表于ACL2020的文章“Explicit Memory Tracker with Coarse-to-Fine Reasoning for Conversational Machine Reading”。 該工作的貢獻(xiàn)有兩個(gè): a. 針對(duì)決策,提出了explicit tracker,即能夠顯示的追蹤文章中條件是否被滿足; b. 采用coarse-to-fine方法抽取Rule Text中沒(méi)有被問(wèn)到的規(guī)則、條件等。
圖3 模型主要包括了四部分:1.Encoding→ 2.Explicit Memory Tracking→ 3.Decision Making→ 4.Question Generation,整體結(jié)構(gòu)如下:
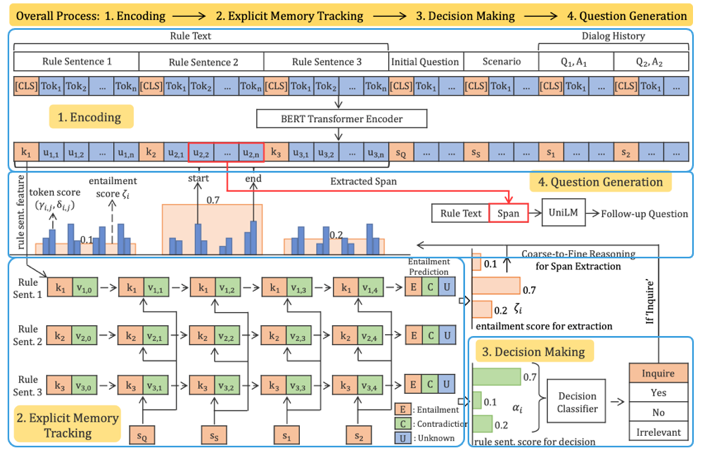
圖4 (1) Encoding 將Rule Text中的句子分開(kāi),比如分為三個(gè)句子,在每個(gè)句子前加一個(gè)[CLS]表征句子特征,同時(shí)把queestion,scenario以及用戶的會(huì)話歷史加起來(lái),也用[CLS]表征,拼接起全部特征后,通過(guò)BERT進(jìn)行encoding。
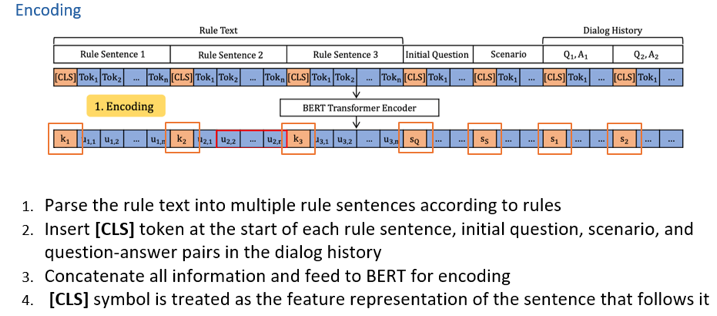
圖5 (2) Explicit Memory Tracking 該部分的目的在于挖掘出存在于Relu Text的句子中與用戶提供的信息(比如initial question 和dialog history)之間的implication。 針對(duì)于此,提出了explict memory tracker,類似于recurrent的思想,逐步的把用戶的信息和Relu Text中的規(guī)則進(jìn)行交互,從而更新每一個(gè)規(guī)則的memory里對(duì)應(yīng)的value,最終得到每一個(gè)條件滿足,不滿足或者不知道的一個(gè)狀態(tài)。 經(jīng)過(guò)n次更新完后,每一個(gè)rule 都會(huì)得到key-value對(duì)。
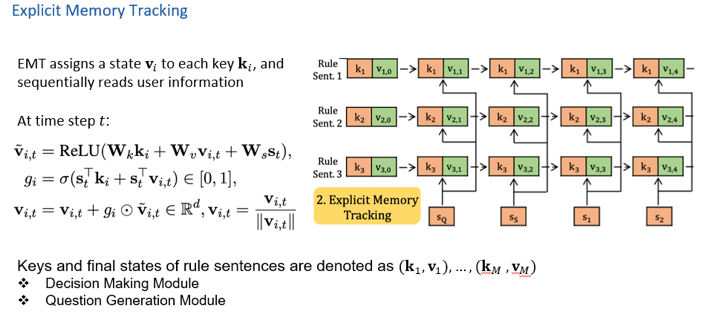
圖6 (3)Decision Making 對(duì)n次更新完后的key-value做self-attention,經(jīng)過(guò)一個(gè)線性層做四分類,即Yes, No, Irrelevant, Inquire。
圖7 同時(shí),還設(shè)計(jì)了一個(gè)subtask,即對(duì)最終更新完之后的key-value做一個(gè)預(yù)測(cè),顯示的預(yù)測(cè)該規(guī)則是Entailment,Prediction還是Unknown。該預(yù)測(cè)任務(wù)和Decision Making一起進(jìn)行訓(xùn)練。
圖8 (4)Question Generation 若得到的決策是Inquire,就要求繼續(xù)做一個(gè)follow-up question的generation。 主要包括兩個(gè)步驟: 第一步,從rule 中抽取一個(gè)span,具體是使用了一種coarse-to-fine 的做法,如下圖所示。由于在Entailment prediction,句子的unknown分?jǐn)?shù)越高,表示該句子越可能被問(wèn);若句子狀態(tài)是Entailment或者Contradiction,說(shuō)明該句子狀態(tài)已知,沒(méi)必要繼續(xù)問(wèn)下去。 因此,選擇每一個(gè)句子在Entailment prediction中unknown的分?jǐn)?shù),并在每一個(gè)句子中計(jì)算抽取start和end的分?jǐn)?shù),然后將這兩個(gè)分?jǐn)?shù)相乘,綜合判斷哪一個(gè)span最有可能被問(wèn)到。

圖9 第二步,就是把span和rule 拼接起來(lái),經(jīng)過(guò)一個(gè)預(yù)訓(xùn)練模型將其rephrase一個(gè)question。
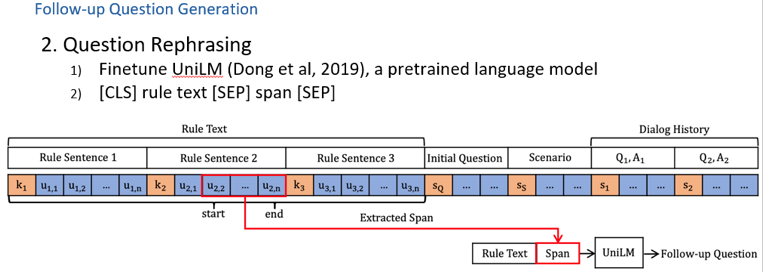
圖10 2.2 實(shí)驗(yàn)驗(yàn)證 負(fù)采樣 使用ShARC數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)驗(yàn)證,包含了兩個(gè)任務(wù)的評(píng)價(jià):分別為對(duì)于Decision Making任務(wù)采用 Marco-Accuracy 和Micro-Accuracy評(píng)價(jià);以及對(duì)于問(wèn)題生成采用BLEU Score評(píng)價(jià)。 此外,講者考慮到在end-to-end evaluation時(shí),存在一個(gè)缺點(diǎn),也就是說(shuō),對(duì)于評(píng)價(jià)問(wèn)題生成時(shí),模型是基于決策這部分的水平去做問(wèn)題生成的評(píng)價(jià),這使得每個(gè)模型之間問(wèn)題生成的表現(xiàn)不好比較,因此提出一個(gè)oracle question generation evaluation,即只要當(dāng)Ground truth decision 是inquire,就對(duì)其問(wèn)題生成的水平進(jìn)行評(píng)價(jià)。 在測(cè)試集上得到的結(jié)果驗(yàn)證了所提出的Entailnment Memory Tracker(EMT)模型較其他模型效果有很大提升,尤其在問(wèn)題生成方面效果顯著。
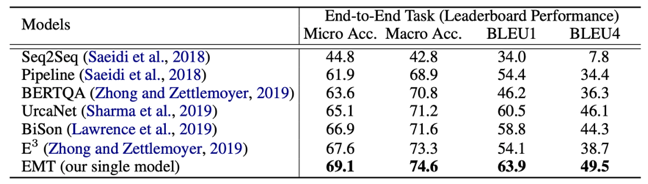
表1 具體分析每一類決策的準(zhǔn)確率,可驗(yàn)證Inquire的效果要更好,主要因?yàn)槟P湍茱@式的追蹤模型的一些狀態(tài),而不是簡(jiǎn)單的學(xué)習(xí)模型中一些Pattern。 此外,在oracle question generation evaluation數(shù)據(jù)集上,與之前最好的模型E3,以及加上UniLM的模型進(jìn)行對(duì)比,同樣也證明了采用Coarse-to-Fine的方法抽取span,在問(wèn)題生成方面具有更好的效果。
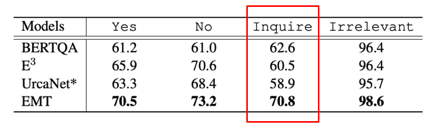
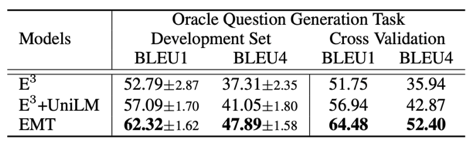
表2 同時(shí),講者給出了一個(gè)例子,更形象明白的說(shuō)明了所提出的模型具備可解釋性。
圖11 3
如何更好地進(jìn)行會(huì)話式機(jī)器閱讀理解
3.1 問(wèn)題提出負(fù)采樣 進(jìn)一步,講者介紹了第二項(xiàng)工作,該工作與前者的側(cè)重點(diǎn)有所不同,存在兩個(gè)差異: 第一,document interpretation,主要由于第一項(xiàng)工作只是簡(jiǎn)單的對(duì)句子進(jìn)行了一個(gè)切分,但實(shí)際上有些conditions(比如,上述例子中的American small business for profit business)是長(zhǎng)句子中從句的條件,因此,第二項(xiàng)工作側(cè)重如何去理解這樣的條件。比如,能申請(qǐng)7(a)貸款,需要滿足(①==True and ②==True and ③==True)的條件,這在第一項(xiàng)工作中是沒(méi)有被建模的。

圖12 第二,dialogs understanding,即對(duì)于會(huì)話并沒(méi)有做特別顯式的理解。比如,在會(huì)話第一輪發(fā)現(xiàn)rule之間是and的關(guān)系,并且在Scenairo中抽取出條件,說(shuō)明第一個(gè)rule是true,但還要繼續(xù)問(wèn)第二個(gè)和第三個(gè)rule,所以給定Inquire的決策,直至滿足所有的rule后,才能給一個(gè)“You can apply the loan”的回答。
3.2 模型介紹負(fù)采樣 因此,該項(xiàng)工作主要基于這兩點(diǎn),提出先采用Discourse Segmentation的方法顯式的把條件更好地抽取出來(lái),之后做Entailment Reasoning 顯式地預(yù)測(cè)每一個(gè)狀態(tài)是否被滿足,如果預(yù)測(cè)結(jié)果是Inquire,還需要做一個(gè)Follow-up Question Generation。
具體的,在discourse segmentation 中主要有兩個(gè)目標(biāo):其一是明白R(shí)ule Text中的邏輯關(guān)系;其二是將句子中的條件更好地抽取出來(lái)。比如,對(duì)于一個(gè)rule采用Discourse Segmentation的方法將其抽取成三個(gè)elementary discourse unit (EDU),比如,下圖中EDU1 ,EDU3是條件,然后EDU2是一個(gè)結(jié)果,這樣的一個(gè)關(guān)系。
圖15 如何實(shí)現(xiàn)Entailment Reasoning? 與工作一類似,在EDU抽取之后,將其與之前的用戶Question,Scenairo 以及Dialog History拼接起來(lái),經(jīng)過(guò)預(yù)訓(xùn)練模型,得到每一個(gè)phrase的表征。然后采用多層transformer模型預(yù)測(cè)rule中每一個(gè)EDU 的狀態(tài),是Entailment、Contradiction,或者Neutral。 多層transformer模型較之前recurrent思想的模型更優(yōu)秀,其不僅能在用戶信息與rule之間做交互,也能更好的理解rule本身的邏輯結(jié)構(gòu)(比如,conjunction,disconjunction等 )。 進(jìn)一步,如何實(shí)現(xiàn)Decision Making? 在做決策時(shí),根據(jù)學(xué)習(xí)到的Entailment、 Contradiction、Neutral向量,去映射前一步做Entailment Prediction的三個(gè)分?jǐn)?shù),得到每一個(gè)EDU的狀態(tài)vector,同時(shí)拼接該狀態(tài)vector與EDU本身的語(yǔ)義表示,作為Decision Classifier 輸入,從而得到?jīng)Q策。
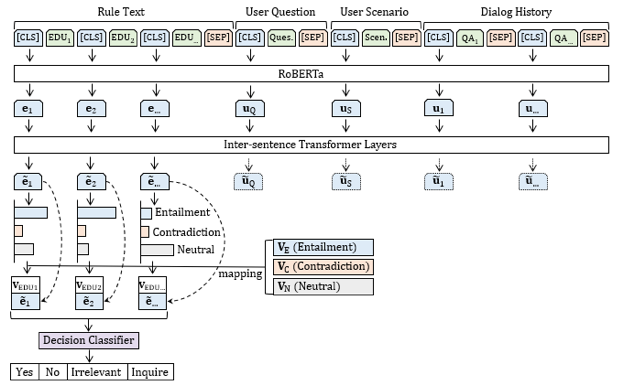
圖163.3實(shí)驗(yàn)驗(yàn)證及結(jié)論負(fù)采樣 同樣地,實(shí)驗(yàn)也是在ShARC數(shù)據(jù)集上進(jìn)行。實(shí)驗(yàn)結(jié)果表明,使用discourse segmentation加上更好的更顯式的Reasoning的模式,較之前使用EMT模型具有更好的性能表現(xiàn),在Micro Accuracy和Macro Accuracy上差不多高出4%。
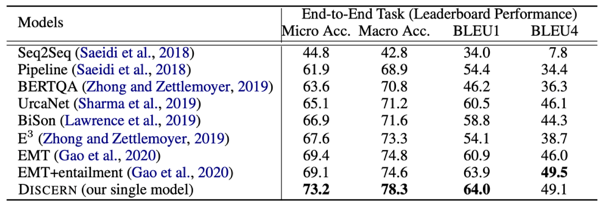
表3 在Ablation Study中,首先對(duì)比了RoBERTa和BERT之間的區(qū)別,表明了RoBERTa對(duì)于Reasoning的任務(wù)具有一定的貢獻(xiàn);其次,說(shuō)明了采用discourse segmentation劃分一個(gè)句子為多個(gè)EDU形式的效果優(yōu)于僅對(duì)句子進(jìn)行劃分的結(jié)果;然后,證明了采用Transformer顯示地對(duì)用戶信息和問(wèn)題之間做交互是有必要的;最后,證明了拼接Entailment vector和EDU本身的語(yǔ)義表示,對(duì)最終決策具有相當(dāng)大的貢獻(xiàn)。
表4 進(jìn)一步,分析了不同邏輯結(jié)構(gòu)下模型的結(jié)果表現(xiàn)。這里粗略分成4種規(guī)則的邏輯結(jié)構(gòu),即Simple、Disjunction、Conjunction以及Other。結(jié)果表示,模型在Simple形式下具有最好效果,然而在Disjunction形式下效果較差。
圖17 為什么模型對(duì)于Disjunction,做出的決策效果較差? 考慮到模型涉及兩部分內(nèi)容,一是dialogue understanding;二是對(duì) scenario的理解。 因此,講者進(jìn)一步做了如下實(shí)驗(yàn),就是把這兩塊內(nèi)容分開(kāi),選擇一個(gè)只用到dialogue understanding 的子集,再選擇一個(gè)只用到scenario Interpretation的子集,進(jìn)行實(shí)驗(yàn)。 結(jié)果表明,只用到dialogue understanding 的子集的模型效果要優(yōu)于用到整個(gè)數(shù)據(jù)集的效果,但在scenario Interpretation的子集上,實(shí)驗(yàn)效果差了很多。 該現(xiàn)象的原因在于,用戶自己的background (scenario)可能用到了很多reasoning的方式,與rule 不完全一樣,因此對(duì)scenario的理解是比較差的。很多時(shí)候scenario里提到了關(guān)鍵信息但是模型并沒(méi)有抽取成功,從而繼續(xù)做出inquire的決策。這也可能是導(dǎo)致Disjunction決策效果較差的原因。
圖18 4
總結(jié)
綜上,講者團(tuán)隊(duì)分別提出了Explicit Memory Tracker with Coarse-to-Fine Reasoning 以及Discourse aware Entailment Reasoning的方法,并且在ShARC數(shù)據(jù)集上效果很好,同時(shí)設(shè)計(jì)實(shí)驗(yàn)分析了數(shù)據(jù)集本身的難點(diǎn)以及模型的缺陷,為后續(xù)研究指明可拓展方向。
責(zé)任編輯:xj
原文標(biāo)題:香港中文大學(xué)高一帆博士:會(huì)話式機(jī)器閱讀理解
文章出處:【微信公眾號(hào):通信信號(hào)處理研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
閱讀
+關(guān)注
關(guān)注
0文章
10瀏覽量
11627 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8501瀏覽量
134550
原文標(biāo)題:香港中文大學(xué)高一帆博士:會(huì)話式機(jī)器閱讀理解
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論