") AI環(huán)境探索模型升級(jí) 縮小搜索范圍效率更高
AI環(huán)境探索模型升級(jí) 縮小搜索范圍效率更高
近日,卡內(nèi)基·梅隆大學(xué)、臉書等機(jī)構(gòu)的研究人員提出了一個(gè)新的AI環(huán)境探索模型。這個(gè)新模型綜合了傳統(tǒng)環(huán)境探索模型和基于學(xué)習(xí)方法的環(huán)境探索模型的優(yōu)點(diǎn),更簡(jiǎn)單和不易出錯(cuò)。
這項(xiàng)研究已經(jīng)發(fā)表在學(xué)術(shù)網(wǎng)站arXiv上,論文標(biāo)題為《利用主動(dòng)神經(jīng)SLAM學(xué)習(xí)探索環(huán)境(Learning To Explore Using Active Neural SLAM)》。
論文鏈接:https://arxiv.org/pdf/2004.05155.pdf

一、ANS模型:真實(shí)模擬探索環(huán)境
導(dǎo)航能力是智能代理的核心能力之一。導(dǎo)航任務(wù)有許多形式,比如點(diǎn)目標(biāo)任務(wù)指導(dǎo)航到特定的坐標(biāo),語(yǔ)義導(dǎo)航任務(wù)指導(dǎo)航到去特定場(chǎng)景或?qū)ο蟮穆窂健?/p>
不論哪一種任務(wù),在未知環(huán)境中導(dǎo)航的核心問(wèn)題都是如何高效地探索盡可能多的環(huán)境。這樣才能擴(kuò)大在未知環(huán)境中找到目標(biāo)的機(jī)會(huì),或者在有限的時(shí)間里有效地預(yù)映射環(huán)境。
傳統(tǒng)的探索模型原理是用傳感器觀察幾何體。之后有研究者提出了基于學(xué)習(xí)的導(dǎo)航模型,該模型依據(jù)RGB圖像直接推測(cè)出幾何體。
基于學(xué)習(xí)的導(dǎo)航策略通過(guò)端到端(end-to-end)訓(xùn)練神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn),可以處理原始的傳感器數(shù)據(jù),直接輸出代理該執(zhí)行的操作。這種策略有3個(gè)優(yōu)勢(shì):
1、提高了輸入方式選擇的靈活性;
2、提高顯式狀態(tài)估計(jì)誤差的穩(wěn)健性;
3、通過(guò)學(xué)習(xí)掌握真實(shí)世界的結(jié)構(gòu)規(guī)律性,使代理更有目的性地行動(dòng)
理論上端到端的學(xué)習(xí)策略有上述優(yōu)勢(shì),但也有局限性。
首先,純粹從數(shù)據(jù)中學(xué)習(xí)映射、狀態(tài)評(píng)估、路徑規(guī)劃可能會(huì)非常昂貴。因此,以往的端到端學(xué)習(xí)依賴于模仿學(xué)習(xí)和以百萬(wàn)計(jì)的經(jīng)驗(yàn)框架。
其次,以往針對(duì)端到端學(xué)習(xí)策略的研究缺乏真實(shí)性。比如使用的是合成室內(nèi)環(huán)境數(shù)據(jù)庫(kù)SUNC、簡(jiǎn)化了代理動(dòng)作、運(yùn)行環(huán)境去除了傳感器噪音等。
從表現(xiàn)來(lái)說(shuō),端到端的學(xué)習(xí)策略也往往比不需要任何學(xué)習(xí)的傳統(tǒng)方法差。
為了解決全面端到端學(xué)習(xí)的局限性,卡內(nèi)基·梅隆大學(xué)、臉書、伊利諾大學(xué)厄巴納-香檳分校的研究人員推出了“主動(dòng)神經(jīng)即時(shí)定位與地圖構(gòu)建(ANS,Active Neural SLAM)模型”。
實(shí)驗(yàn)設(shè)計(jì)上,研究人員盡量使模型訓(xùn)練環(huán)境更真實(shí),用到了生境模擬器和兩個(gè)基于真實(shí)情景的數(shù)據(jù)庫(kù)(Gibson和Matterport),不限制代理的動(dòng)作,還模擬了傳感器噪音。
二、縮小搜索范圍,兼顧搜索性能和效率
本項(xiàng)研究中,導(dǎo)航模型的任務(wù)是在固定時(shí)間內(nèi)覆蓋最大范圍。覆蓋范圍定義為地圖中已知被穿越的總面積。
ANS模型包括一個(gè)學(xué)習(xí)神經(jīng)即時(shí)定位與地圖構(gòu)建(SLAM,Simultaneous localization and mapping)模塊,一個(gè)全局策略(global policy)和一個(gè)局部策略(local policy)。它們通過(guò)地圖和一個(gè)分析路徑規(guī)劃器相連。
層次化和模塊化的設(shè)計(jì)和分析規(guī)劃的使用,大大減小了訓(xùn)練過(guò)程中的搜索范圍,同時(shí)提高了性能和樣本效率。
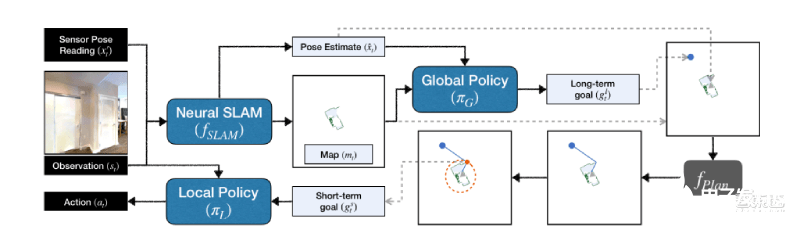
▲模型示意圖
訓(xùn)練過(guò)程中,學(xué)習(xí)神經(jīng)SLAM模塊產(chǎn)生自由空間地圖,并依據(jù)輸入的RGB圖像和運(yùn)動(dòng)傳感器數(shù)據(jù)預(yù)測(cè)代理的姿勢(shì)。SLAM模塊的學(xué)習(xí)提升了輸入方式的靈活性。
全局策略利用代理的姿勢(shì)來(lái)占據(jù)自由空間地圖,并把學(xué)習(xí)現(xiàn)實(shí)世界環(huán)境布局的結(jié)構(gòu)性規(guī)則作為長(zhǎng)期目標(biāo)。全局策略可以探索真實(shí)世界環(huán)境的布局。
長(zhǎng)期目標(biāo)可以為局部策略生成短期目標(biāo)。局部策略通過(guò)學(xué)習(xí),直接從RGB圖像中映射出代理應(yīng)該做出的動(dòng)作,呈現(xiàn)可視化反饋。
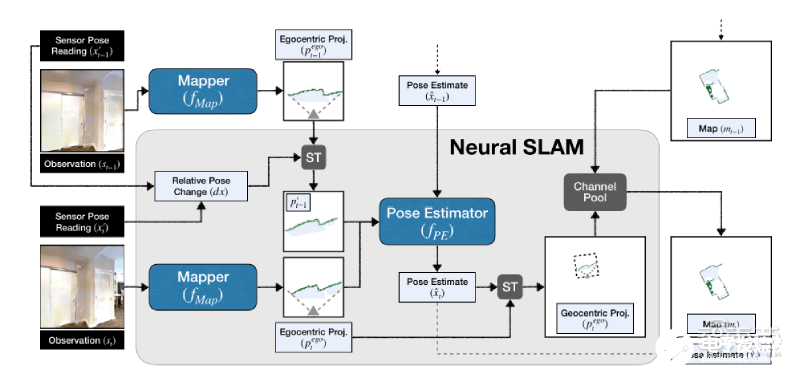
▲模型運(yùn)行過(guò)程示意圖
三、ANS模型能探索更大范圍,比基線模型性能優(yōu)秀
利用Gibson訓(xùn)練集,研究人員完成了對(duì)ANS模型的訓(xùn)練,運(yùn)行了1000萬(wàn)幀探索任務(wù)的所有基線。結(jié)果如下表。
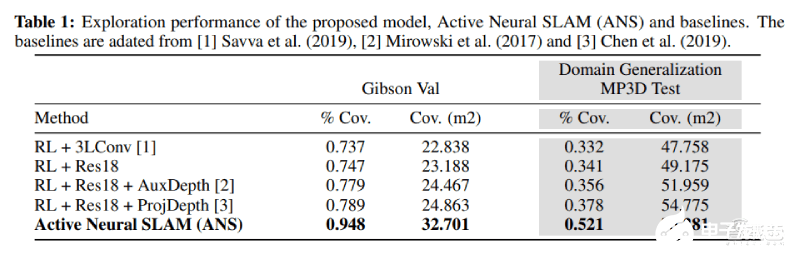
運(yùn)行結(jié)果基于模型在14個(gè)未知場(chǎng)景中994次運(yùn)行的結(jié)果進(jìn)行平均。與最佳基線的24.863m^2/0.789相比,模型的覆蓋率為32.701m^2/0.948。這個(gè)數(shù)值說(shuō)明,與基線相比,ANS模型在窮盡探索上更有效。
研究人員還對(duì)比了模型和基線在較大訓(xùn)練集、較小訓(xùn)練集、全部Gibson訓(xùn)練集中的運(yùn)行效果。
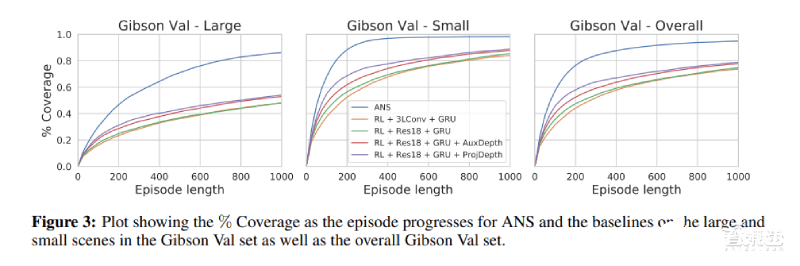
較小訓(xùn)練集中,ANS模型能在500步探索完未知環(huán)境,而基線運(yùn)行1000步后仍只探索了位置環(huán)境的85~90%(上圖中)。
較大訓(xùn)練集中,隨著情節(jié)的發(fā)展,ANS模型與基線之間的差距會(huì)擴(kuò)大(上圖左)。
基線模型中,代理經(jīng)常只探索局部區(qū)域,這說(shuō)明它們無(wú)法記住長(zhǎng)期視野的探索區(qū)域,不能進(jìn)行長(zhǎng)期規(guī)劃。相比之下,ANS采用全局策略,可以記憶探索過(guò)的區(qū)域,有效地規(guī)劃并實(shí)現(xiàn)長(zhǎng)期目標(biāo)。
受到結(jié)果鼓舞,研究人員用ANS模型部署了一個(gè)環(huán)境探索機(jī)器人。通過(guò)調(diào)整攝相機(jī)的高度和垂直視野,并匹配棲息地模擬器,機(jī)器人成功探索出一個(gè)公寓的生活區(qū)域。

結(jié)語(yǔ):ANS模型效率更高,未來(lái)或有更多應(yīng)用
ANS導(dǎo)航模型克服了之前的基于端對(duì)端學(xué)習(xí)策略的缺陷,基于更真實(shí)的數(shù)據(jù)庫(kù)進(jìn)行訓(xùn)練,最終探索效率有所提升。
研究人員認(rèn)為這個(gè)模型在未來(lái)或許會(huì)有更多應(yīng)用。“未來(lái),ANS模型可以擴(kuò)展到復(fù)雜的語(yǔ)義任務(wù),比如語(yǔ)義目標(biāo)導(dǎo)航和回答具體問(wèn)題,這將創(chuàng)建出一個(gè)能捕獲對(duì)象語(yǔ)義屬性的地圖。”
另外,這個(gè)模型也可以與先前的本地化工作結(jié)合,在此前創(chuàng)建的地圖中重新定位,使之后的導(dǎo)航更高效。
責(zé)任編輯:PSY
-
AI
+關(guān)注
關(guān)注
87文章
31711瀏覽量
270511 -
搜索
+關(guān)注
關(guān)注
0文章
69瀏覽量
16688 -
模型
+關(guān)注
關(guān)注
1文章
3342瀏覽量
49272 -
SLAM
+關(guān)注
關(guān)注
23文章
427瀏覽量
31938
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
企業(yè)AI模型部署攻略
昆侖萬(wàn)維天工AI發(fā)布升級(jí)版AI高級(jí)搜索功能
英偉達(dá)發(fā)布AI模型 Llama-3.1-Nemotron-51B AI模型
月訪問(wèn)量超2億,增速113%!360AI搜索成為全球增速最快的AI搜索引擎
電商搜索革命:大模型如何重塑購(gòu)物體驗(yàn)?
ai大模型和傳統(tǒng)ai的區(qū)別在哪?
AI搜索新貴彎道超車難

STM CUBE AI錯(cuò)誤導(dǎo)入onnx模型報(bào)錯(cuò)的原因?
OpenAI的AI搜索也要來(lái)了,但我們需要這么多AI搜索么
【大語(yǔ)言模型:原理與工程實(shí)踐】探索《大語(yǔ)言模型原理與工程實(shí)踐》2.0
搭載星火認(rèn)知大模型的AI鼠標(biāo):一鍵呼出AI助手,辦公更高效

AI大模型將如何推動(dòng)中國(guó)產(chǎn)業(yè)升級(jí)?華為盤古大模型深耕千行萬(wàn)業(yè)
防止AI大模型被黑客病毒入侵控制(原創(chuàng))聆思大模型AI開(kāi)發(fā)套件評(píng)測(cè)4
使用cube-AI分析模型時(shí)報(bào)錯(cuò)的原因有哪些?
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型開(kāi)發(fā)效率提升10倍





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論