 如何在不需要特殊庫或類的情況下實現C代碼并行性?
如何在不需要特殊庫或類的情況下實現C代碼并行性?
提取實現任務級 (task_level) 的硬件并行算法是設計高效的HLS IP內核的關鍵。
在本文中,我們將重點放在如何能夠在不需要特殊的庫或類的情況下修改代碼風格以實現C代碼實現并行性。Xilinx HLS 編譯器的顯著特征是能夠將任務級別的并行性和流水線與可尋址的存儲器 PIPO或 FIFO相結合。本文首先概述可以獲取任務并行的前提條件,然后以DAG(directedacyclic graph) 代碼為例,挖掘其中使用 fork-join 并行性,并結合使用 ping- pong buffer 啟用了一種基于握手的任務級粗粒度的流水線形式。
我們理解任務級并行的時候可以想象成這樣一個場景,每一個計算任務都是時間軸上向前奔跑的馬車,馬車與馬車之間傳輸的貨物就像是計算數據,他們需要管道去連接即 FIFO 和 PIPO ,FIFO 是一個先進先出存儲器也就是說使用這樣的管道傳輸數據的時候,數據進出的順序不可以改變。而 PIPO 就是一個可尋址的存儲器管道,數據在任務之間進出的順序可以改變。
最糟糕的狀態是什么?馬車在時間線上順序出發,A 馬車到達終點后 B 再出發以此類推,就像是 CPU 中的單進程順序執行模式一樣,而FPGA中有可供并行化執行的數據傳輸管道,更多的資源就像是跑道一樣,所以這個狀態效率是最低的。
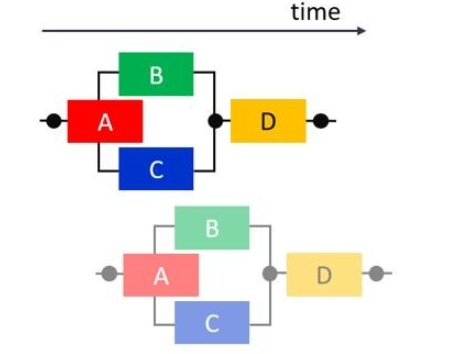
那么先做一點點改進,我們分析發現 B 和 C 馬車不享有任何公用的數據或存儲計算資源,也就是他們完全可以在 A 結束后并行執行,最后再執行 D,這種并行情況中含有順序和并行兩種模式,我們稱之為交叉并行 (fork-joinparallelism)。但是下一次進程仍然是順序執行的。
繼續深入可以發現,四輛馬車在跑完各自的任務后都有一段的閑置時間,提高吞吐量和資源重復利用也很明顯是息息相關的。實現了進程之間的流水線執行的結果就如下圖,每一輛馬車在不同的進程中連續執行任務,向前奔跑,重復利用資源的同時它提升了吞吐量進而極大的減小了完成多個進程后的延遲。
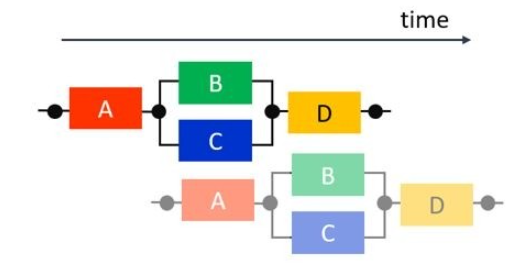
最理想的狀態時什么?就是馬車盡可能的一個挨著一個一起出發,并行奔跑,大家先后到達終點完成計算,在奔跑的過程中數據通過管道也完成了遷移,最終計算完的數據在最后一輛馬車到達終點的時候產出。下圖我們可以看到 B 和 C 開始執行的時間提前了,并沒有等到A完全執行完畢,這和數據依賴息息相關,也就是說我們進一步挖掘并行性的路上發現:ABC 三輛馬車都可以在增加馬車數量 (擴增資源) ,建立數據管道的并行執行的前提下實現了。我們用資源換取了更大的并行性,這就是繼續挖掘并行性上需要付出的代價。
奔跑的馬車帶著我們理解了任務級流水線的優化之路,下面我們結合代碼看一看HLS工具會在哪些情況下阻止 dataflow 的實現。
在我們談及 dataflow 的優化之前,我們先去了解在 HLS 提醒你報錯的方式,其中修改屬性config_dataflow-strict_mode (off | error | warning) 指令可以控制報錯指令的級別,一般情況下默認是 warning 級別的報錯,主要看我們的并行性需求。
以下是阻止任務級別并行性的常見情況:
1. 單產出單消耗模型違例(Single-producer-consumerviolations)
為了使 VitisHLS 執行 DATAFLOW 優化,任務之間傳遞的所有元素都必須遵循單產出單消耗模型。每個變量必須從單個任務驅動,并且只能由單個任務使用。在下面的代碼示例中是典型的單產出單消耗模型違例,單一的數據流 temp1 同時被 Loop2 和 Loop3 消耗。要解決這個問題很容易,就是將兩個任務都要消耗的數據流復制成兩個,如右圖的 Split 函數。當 temp1數據流被復制為 temp2 和 temp3 后,LOOP1,2,3 就可以實現任務級流水線了。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N];
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
}
Loop2: for(int j = 0; j < N; j++) {
data_out1[j] = temp1[j] * 123;
}
Loop3: for(int k = 0; k < N; k++) {
data_out2[k] = temp1[k] * 456;
}
}
void Split (in[N], out1[N], out2[N]) {
// Duplicated data
L1:for(int i=1;i
out1[i] = in[i];
out2[i] = in[i];
}
}
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]. temp3[N];
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
}
Split(temp1, temp2, temp3);
Loop2: for(int j = 0; j < N; j++) {
data_out1[j] = temp2[j] * 123;
}
Loop3: for(int k = 0; k < N; k++) {
data_out2[k] = temp3[k] * 456;
}
}
2. 旁路任務 Bypassing Tasks
正常情況下我們期望流水線任務是一個接著一個的產出并消耗,然而像下面這個例子中,Loop1 產生了 Temp1和Temp2 兩個數據流,但是在下一個任務 Loop2 中只有 temp1 參與了運算,而 temp2 就被旁支了。Loop3 任務的執行依賴 Loop2 任務產生的 temp3 數據,所以 Loop2 和 Loop3 因為數據依賴的關系無法并行執行。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]. temp3[N];
Loop1: for(int i = 0; i < N; i++) {?
temp1[i] = data_in[i] * scale;
temp2[i] = data_in[i] >> scale;
}
Loop2: for(int j = 0; j < N; j++) {?
temp3[j] = temp1[j] + 123;
}
Loop3: for(int k = 0; k < N; k++) {?
data_out[k] = temp2[k] + temp3[k];
}
}
3. 任務間雙向反饋 Feedbackbetween Tasks
假如說當前任務的結果,需要作為之前一個任務的輸入的話,就形成了任務之間的數據反饋,它打亂了流水線從上級一直往下級輸送數據流的規則。這時候HLS就會給出警告或者報錯,有可能完成不了dataflow優化了。有一種特例是支持的:使用hls::stream格式的數據流反饋。
我們分析以下代碼的內容:
當第一個程序 firstProc 執行的時候,hls::stream 格式的數據流 forwardOUT 被寫入了初始化為10的數值 fromSecond 。由于 hls::stream 格式的數據本身不支持初始化操作,所以這樣的操作避免了違反單產出單消耗原則。之后的迭代里,firstProc 通過 backwardIN 接口從 hls :: stream 讀取數值寫入 forwardOUT 中。
在第二個程序 secondProc 執行的時候,secondProc 讀取 forwardIN 上的值,將其加1,然后通過按執行順序倒退的反饋流將其發送回 FirstProc。從第二次執行開始,firstProc 將使用從流中讀取的值進行計算,并且兩個過程可以使用第一次執行的初始值,通過正向和反饋通信永遠保持下去。這種交互式的反饋中,包含數據流的雙向反饋機制,但是它就像貨物一直在從左手倒到右手再從右手倒到左手一樣,可以不違反 Dataflow 的規范,一直進行下去。
#include "ap_axi_sdata.h"
#include "hls_stream.h"
void firstProc(hls::stream
static bool first = true;
int fromSecond;
//Initialize stream
if (first)
fromSecond = 10; // Initial stream value
else
//Read from stream
fromSecond = backwardIN.read(); //Feedback value
first = false;
//Write to stream
forwardOUT.write(fromSecond*2);
}
void secondProc(hls::stream
{
backwardOUT.write(forwardIN.read() + 1);
}
void top(...) {
#pragma HLS dataflow
hls::stream
firstProc(forward, backward);
secondProc(forward, backward);
}
4. 含有條件判斷的任務流水
DATAFLOW 優化不會優化有條件執行的任務。下面的示例展現了這個違例。在此示例中,有條件地執行 Loop1 和 Loop2 會阻止 Vitis HLS 優化這些循環之間的數據流,因為 sel 條件直接控制了任務中的數據有可能不會從一個循環流到下一個循環。
void foo(int data_in1[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
if (sel) {
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * 123;
temp2[i] = data_in[i];
}
} else {
Loop2: for(int j = 0; j < N; j++) {
temp1[j] = data_in[j] * 321;
temp2[j] = data_in[j];
}
}
Loop3: for(int k = 0; k < N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}
但是我們都知道,其實這些任務之間存在條件判斷和選擇是非常常見的情況,只需要稍微改變代碼風格就可以既保留條件判斷,又完成任務流水。為了確保在所有情況下都執行每個循環,我們將條件語句下變化的 Temp1 移入第一個循環。這兩個循環始終執行,并且數據始終從一個循環流向下一個循環。
void foo(int data_in[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
Loop1: for(int i = 0; i < N; i++) {
if (sel) {
temp1[i] = data_in[i] * 123;
} else {
temp1[i] = data_in[i] * 321;
}
}
Loop2: for(int j = 0; j < N; j++) {
temp2[j] = data_in[j];
}
Loop3: for(int k = 0; k < N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}
5. 有多種退出機制的循環
含有多種退出機制的循環不能被包含在流水線區域內,我們來數一數 Loop2 一共有多少種循環退出條件:
1. 由 for 循環定義的 K>N 的情況;
2. 由 switch 條件定義的 default 情況;
3. 由 switch 條件定義的 continue 情況
由于循環的退出條件始終由循環邊界定義,因此使用 break 或 continue 語句將禁止在DATAFLOW 區域中使用循環。
void multi_exit(din_t data_in[N], dsc_t scale, dsel_t select, dout_t
data_out[N]) {
dout_t temp1[N], temp2[N];
int i,k;
Loop1:
for(i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
temp2[i] = data_in[i] >> scale;
}
Loop2:
for(k = 0; k < N; k++) {
switch(select) {
case 0: data_out[k] = temp1[k] + temp2[k];
case 1: continue;
default: break;
}
}
}
我們理解了可能阻止任務流水線的 5 種經典情況后,我們最后推出適用于 Vitis HLS 的Dataflow 優化的兩種規范形式 (canonical forms) ,一種直接應用于函數,一種應用于 for循環。我們可以發現規范形式嚴格遵守了單產出單消耗的規則。
1. 適用于子程序沒有被內聯 (inline) 的規范形式
void dataflow(Input0, Input1, Output0, Output1)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
2. 適用于循環體內的任務流水的規范形式:
對于 for 循環 (其中沒有內聯函數的地方),循環變量應具有:
a. 在 for 循環的標題中聲明初始值,并設置為 0。
b. 循環條件N是一個正數值常數或常數函數參數。
c. 循環的遞增量為1。
d. Dataflow 指令必須位于循環內部。
void dataflow(Input0, Input1, Output0, Output1)
{
for (int i = 0; i < N; i++)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
}
原文標題:Dataflow | 粗粒度并行優化的任務級流水
文章出處:【微信公眾號:FPGA開發圈】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
硬件
+關注
關注
11文章
3443瀏覽量
66945 -
代碼
+關注
關注
30文章
4871瀏覽量
69909
原文標題:Dataflow | 粗粒度并行優化的任務級流水
文章出處:【微信號:FPGA-EETrend,微信公眾號:FPGA開發圈】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
是否可以在不需要TSW3100的情況下單獨使用TSW3070軟件?
包裝印刷企業實現性生產中不需要點表工業網關部署架構是怎樣的?

不需要點表的工業網關應用案例:如何提升工業企業生產效率與質量?

C語言為什么不需要包含stdio.h
“不需要點表的工業網關”如何實現松下FPG-C32T2H數據采集和遠程維護的物聯網解決方案
網線那幾根線不需要

THS3095不需要使用PD功能,在采用雙電源供電的情況下,是否可以將REF接地,PD懸空?
ESP8266如何在沒有SNTP的情況下寫入當前的系統時間?
什么情況下需要使用接地電阻柜
請問如何在不使用代碼配置的情況下閃爍LED指示燈?
想用單芯片實現HDMI轉LVDS信號或eDP轉LVDS信號芯片不需要燒固件,哪個芯片可以實現?
什么情況下需要申請T-mobile認證?T-mobile的優勢是什么?






 工商網監
工商網監
評論