 if-else的效率有多低你知道嗎?
if-else的效率有多低你知道嗎?

首先看一段經典的代碼,并統計它的執行時間:
// test_predict.cc#include 《algorithm》#include 《ctime》#include 《iostream》
int main() { const unsigned ARRAY_SIZE = 50000; int data[ARRAY_SIZE]; const unsigned DATA_STRIDE = 256;
for (unsigned c = 0; c 《 ARRAY_SIZE; ++c) data[c] = std::rand() % DATA_STRIDE;
std::sort(data, data + ARRAY_SIZE);
{ // 測試部分 clock_t start = clock(); long long sum = 0;
for (unsigned i = 0; i 《 100000; ++i) { for (unsigned c = 0; c 《 ARRAY_SIZE; ++c) { if (data[c] 》= 128) sum += data[c]; } }
double elapsedTime = static_cast《double》(clock() - start) / CLOCKS_PER_SEC;
std::cout 《《 elapsedTime 《《 “
”; std::cout 《《 “sum = ” 《《 sum 《《 “
”; } return 0;}~/test$ g++ test_predict.cc ;。/a.out7.95312sum = 480124300000
此程序的執行時間是7.9秒,如果把排序那一行代碼注釋掉,即
// std::sort(data, data + ARRAY_SIZE);
結果為:
~/test$ g++ test_predict.cc ;。/a.out24.2188sum = 480124300000
改動后的程序執行時間變為了24秒。
其實只改動了一行代碼,程序執行時間卻有3倍的差距,而且看上去數組是否排序與程序執行速度貌似沒什么關系,這里面其實涉及到CPU分支預測的知識點。
提到分支預測,首先要介紹一個概念:流水線。
拿理發舉例,小理發店一般都是一個人工作,一個人洗剪吹一肩挑,而大理發店分工明確,洗剪吹都有特定的員工,第一個人在剪發的時候,第二個人就可以洗頭了,第一個人剪發結束吹頭發的時候,第二個人可以去剪發,第三個人就可以去洗頭了,極大的提高了效率。
這里的洗剪吹就相當于是三級流水線,在CPU架構中也有流水線的概念,如圖:
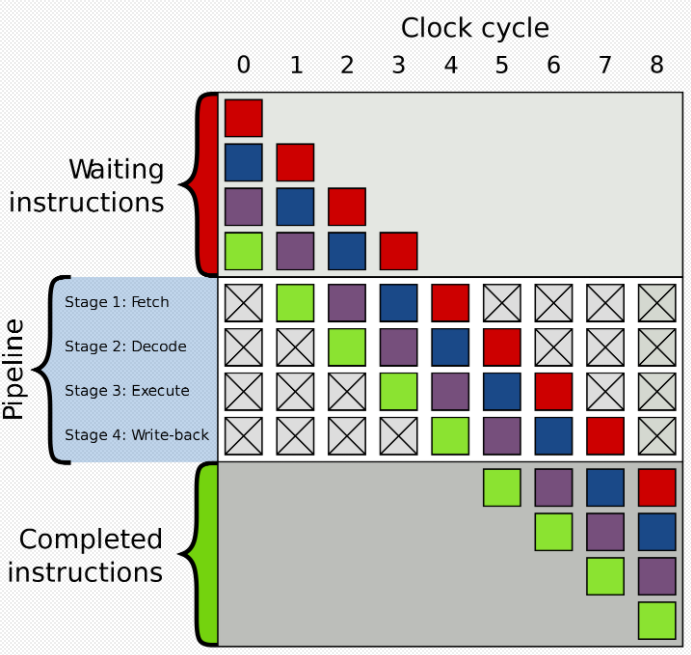
在執行指令的時候一般有以下幾個過程:
取指:Fetch
譯指:Decode
執行:execute
回寫:Write-back
流水線架構可以更好的壓榨流水線上的四個員工,讓他們不停的工作,使指令執行的效率更高。
再談分支預測,舉個經典的例子:
火車高速行駛的過程中遇到前方有個岔路口,假設火車內沒有任何通訊手段,那火車就需要在岔路口前停下,下車詢問別人應該選擇哪條路走,弄清楚路線后后再重新啟動火車繼續行駛。高速行駛的火車慢速停下,再重新啟動后加速,可以想象這個過程浪費了多少時間。
有個辦法,火車在遇到岔路口前可以猜一條路線,到路口時直接選擇這條路行駛,如果經過多個岔路口,每次做出選擇時都能選擇正確的路口行駛,這樣火車一路上都不需要減速,速度自然非常快。但如果火車開過頭才發現走錯路了,就需要倒車回到岔路口,選擇正確的路口繼續行駛,速度自然下降很多。所以預測的成功率非常重要,因為預測失敗的代價較高,預測成功則一帆風順。
計算機的分支預測就如同火車行駛中遇到了岔路口,預測成功則程序的執行效率大幅提高,預測失敗程序的執行效率則大幅下降。
CPU都是多級流水線架構運行,如果分支預測成功,很多指令都提前進入流水線流程中,則流水線中指令運行的非常順暢,而如果分支預測失敗,則需要清空流水線中的那些預測出來的指令,重新加載正確的指令到流水線中執行,然而現代CPU的流水線級數非常長,分支預測失敗會損失10-20個左右的時鐘周期,因此對于復雜的流水線,好的分支預測方法非常重要。
預測方法主要分為靜態分支預測和動態分支預測:
靜態分支預測:聽名字就知道,該策略不依賴執行環境,編譯器在編譯時就已經對各個分支做好了預測。
動態分支預測:即運行時預測,CPU會根據分支被選擇的歷史紀錄進行預測,如果最近多次都走了這個路口,那CPU做出預測時會優先考慮這個路口。
tips:這里只是簡單的介紹了分支預測的方法,更多的分支預測方法資料大家可關注公眾號回復分支預測關鍵字領取。
了解了分支預測的概念,我們回到最開始的問題,為什么同一個程序,排序和不排序的執行速度相差那么多。
因為程序中有個if條件判斷,對于不排序的程序,數據散亂分布,CPU進行分支預測比較困難,預測失敗的頻率較高,每次失敗都會浪費10-20個時鐘周期,影響程序運行的效率。而對于排序后的數據,CPU根據歷史記錄比較好判斷即將走哪個分支,大概前一半的數據都不會進入if分支,后一半的數據都會進入if分支,預測的成功率非常高,所以程序運行速度很快。
如何解決此問題?總體思路肯定是在程序中盡量減少分支的判斷,方法肯定是具體問題具體分析了,對于該示例程序,這里提供兩個思路削減if分支。
方法一:使用位操作:
int t = (data[c] - 128) 》》 31;sum += ~t & data[c];
方法二:使用表結構:
#include 《algorithm》#include 《ctime》#include 《iostream》
int main() { const unsigned ARRAY_SIZE = 50000; int data[ARRAY_SIZE]; const unsigned DATA_STRIDE = 256;
for (unsigned c = 0; c 《 ARRAY_SIZE; ++c) data[c] = std::rand() % DATA_STRIDE;
int lookup[DATA_STRIDE]; for (unsigned c = 0; c 《 DATA_STRIDE; ++c) { lookup[c] = (c 》= 128) ? c : 0; }
std::sort(data, data + ARRAY_SIZE);
{ // 測試部分 clock_t start = clock(); long long sum = 0;
for (unsigned i = 0; i 《 100000; ++i) { for (unsigned c = 0; c 《 ARRAY_SIZE; ++c) { // if (data[c] 》= 128) sum += data[c]; sum += lookup[data[c]]; } }
double elapsedTime = static_cast《double》(clock() - start) / CLOCKS_PER_SEC; std::cout 《《 elapsedTime 《《 “
”; std::cout 《《 “sum = ” 《《 sum 《《 “
”; } return 0;}
其實Linux中有一些工具可以檢測出分支預測成功的次數,有valgrind和perf,使用方式如圖:
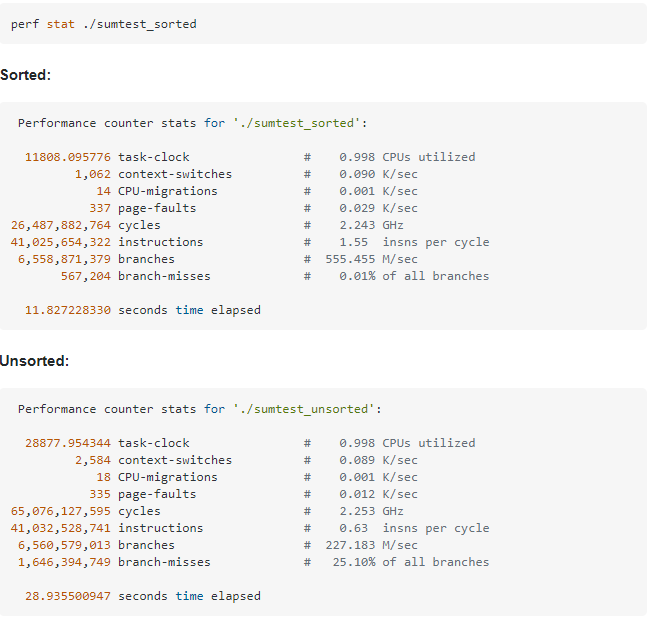
圖片截自下方參考資料中
條件分支的使用會影響程序執行的效率,我們平時開發過程中應該盡可能減少在程序中隨意使用過多的分支,能避免則避免。
更多的分支預測方法資料大家可關注公眾號回復分支預測關鍵字領取。
拓展閱讀:
《虛函數真的就那么慢嗎?它的開銷究竟在哪里?來看這4段代碼!》
想必很多人都聽說過虛函數開銷大,貌似很多答案都說是因為虛函數表導致的那一次間接調用,真的如此嗎?
直接看下面這兩段代碼:
#include 《cmath》#include “timer.h”struct Base { public: virtual int f(double i1, int i2) { return static_cast《int》(i1 * log(i1)) * i2; }};
int main() { TimerLog t(“timer”); Base *a = new Base(); int ai = 0; for (int i = 0; i 《 1000000000; i++) { ai += a-》f(i, 10); } cout 《《 ai 《《 endl;}
執行時間:12.895s
#include 《cmath》#include “timer.h”struct Base { public: int f(double i1, int i2) { return static_cast《int》(i1 * log(i1)) * i2; }};
int main() { TimerLog t(“timer”); Base *a = new Base(); int ai = 0; for (int i = 0; i 《 1000000000; i++) { ai += a-》f(i, 10); } cout 《《 ai 《《 endl;}
執行時間:12.706s
這兩段代碼的執行時間幾乎沒有區別,可見虛函數表導致的那一次函數間接調用并不浪費時間,所以虛函數的開銷并不在重定向上,這一次重定向基本上不影響程序性能。
那它的開銷究竟在哪里呢?看下面兩段代碼,這兩段代碼和上面相比只改動了一行:
#include 《cmath》#include “timer.h”struct Base { public: virtual int f(double i1, int i2) { return static_cast《int》(i1 * log(i1)) * i2; }};
int main() { TimerLog t(“timer”); Base *a = new Base(); int ai = 0; for (int i = 0; i 《 1000000000; i++) { ai += a-》f(10, i); // 這里有改動 } cout 《《 ai 《《 endl;}
執行時間:436ms
#include 《cmath》#include “timer.h”struct Base { public: int f(double i1, int i2) { return static_cast《int》(i1 * log(i1)) * i2; }};
int main() { TimerLog t(“timer”); Base *a = new Base(); int ai = 0; for (int i = 0; i 《 1000000000; i++) { ai += a-》f(10, i); // 這里有改動 } cout 《《 ai 《《 endl;}
執行時間154ms
這里看到,僅僅改變了一行代碼,虛函數調用就比普通函數慢了幾倍,為什么?
虛函數其實最主要的性能開銷在于它阻礙了編譯器內聯函數和各種函數級別的優化,導致性能開銷較大,在普通函數中log(10)會被優化掉,它就只會被計算一次,而如果使用虛函數,log(10)不會被編譯器優化,它就會被計算多次。如果代碼中使用了更多的虛函數,編譯器能優化的代碼就越少,性能就越低。
虛函數通常通過虛函數表來實現,在虛表中存儲函數指針,實際調用時需要間接訪問,這需要多一點時間。
然而這并不是虛函數速度慢的主要原因,真正原因是編譯器在編譯時通常并不知道它將要調用哪個函數,所以它不能被內聯優化和其它很多優化,因此就會增加很多無意義的指令(準備寄存器、調用函數、保存狀態等),而且如果虛函數有很多實現方法,那分支預測的成功率也會降低很多,分支預測錯誤也會導致程序性能下降。
如果你想要寫出高性能代碼并頻繁的調用虛函數,注意如果用其它的方式(例如if-else、switch、函數指針等)來替換虛函數調用并不能根本解決問題,它還有可能會更慢,真正的問題不是虛函數,而是那些不必要的間接調用。
正常的函數調用:
復制棧上的一些寄存器,以允許被調用的函數使用這些寄存器;
將參數復制到預定義的位置,這樣被調用的函數可以找到對應參數;
入棧返回地址;
跳轉到函數的代碼,這是一個編譯時地址,因為編譯器/鏈接器硬編碼為二進制;
從預定義的位置獲取返回值,并恢復想要使用的寄存器。
而虛函數調用與此完全相同,唯一的區別就是編譯時不知道函數的地址,而是:
從對象中獲取虛表指針,該指針指向一個函數指針數組,每個指針對應一個虛函數;
從虛表中獲取正確的函數地址,放到寄存器中;
跳轉到該寄存器中的地址,而不是跳轉到一個硬編碼的地址。
通常,使用虛函數沒問題,它的性能開銷也不大,而且虛函數在面向對象代碼中有強大的作用。
但是不能無腦使用虛函數,特別是在性能至關重要的或者底層代碼中,而且大項目中使用多態也會導致繼承層次很混亂。
那么有什么好方法替代虛函數呢?這里提供幾個思路,讀者請持續關注,后續會具體講解:
使用訪問者模式來使類層次結構可擴展;
使用普通模板替代繼承和虛函數;
C++20中的concepts用來替代面向對象代碼;
使用variants替代虛函數或模板方法。
這幾種方法是Michael Spertus大佬介紹的,各有各的優缺點,作者都會用,但什么情況下使用哪個,取決于你自己的判斷,這里只是教你了一個工具,什么時候用都取決于你自己。
原文標題:少寫點if-else吧,它的效率有多低你知道嗎?
文章出處:【微信公眾號:嵌入式ARM】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
cpu
+關注
關注
68文章
11080瀏覽量
217138 -
編程
+關注
關注
88文章
3689瀏覽量
95275 -
代碼
+關注
關注
30文章
4900瀏覽量
70768
原文標題:少寫點if-else吧,它的效率有多低你知道嗎?
文章出處:【微信號:gh_c472c2199c88,微信公眾號:嵌入式微處理器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
你知道船用變壓器有哪些嗎?

超低功耗藍牙模組的功耗到底有多低
低、中、高頻段 (LMH) 多模/多頻段功率放大器模塊 skyworksinc

LED戶外顯示屏的五大優勢,你知道嗎?
這些電源常用仿真軟件,你都知道嗎?
晶振怎么用,你真的知道嗎?

電源的這些常識你知道嗎?
你知道嗎:怎么選擇RC低通濾波阻容值?
在光端機應用中,晶振的核心作用你知道嗎

隨意更換熱敏電阻有什么后果你知道嗎?

隨意更換熱敏電阻有什么后果你知道嗎?






 工商網監
工商網監
評論