") 文本分類(lèi)的一個(gè)大型“真香現(xiàn)場(chǎng)”來(lái)了
文本分類(lèi)的一個(gè)大型“真香現(xiàn)場(chǎng)”來(lái)了

文本分類(lèi)的一個(gè)大型“真香現(xiàn)場(chǎng)”來(lái)了:JayJay的推文《超強(qiáng)文本半監(jiān)督MixText》中告訴大家不要浪費(fèi)沒(méi)有標(biāo)注過(guò)的數(shù)據(jù),但還是需要有標(biāo)注數(shù)據(jù)的!但今天介紹的這篇paper,文本分類(lèi)居然不需要任何標(biāo)注數(shù)據(jù)啦!哇,真香!
當(dāng)前的文本分類(lèi)任務(wù)需要利用眾多標(biāo)注數(shù)據(jù),標(biāo)注成本是昂貴的。而半監(jiān)督文本分類(lèi)雖然減少了對(duì)標(biāo)注數(shù)據(jù)的依賴(lài),但還是需要領(lǐng)域?qū)<沂謩?dòng)進(jìn)行標(biāo)注,特別是在類(lèi)別數(shù)目很大的情況下。
試想一下,我們?nèi)祟?lèi)是如何對(duì)新聞文本進(jìn)行分類(lèi)的?其實(shí),我們不要任何標(biāo)注樣本,只需要利用和分類(lèi)類(lèi)別相關(guān)的少數(shù)詞匯就可以啦,這些詞匯也就是我們常說(shuō)的關(guān)鍵詞。
BUT!我們之前獲取分類(lèi)關(guān)鍵詞的方式,大多還是需要靠人工標(biāo)注數(shù)據(jù)、或者人工積累關(guān)鍵詞表的;而就算積累了某些關(guān)鍵詞,關(guān)鍵詞在不同上下文中也會(huì)代表不同類(lèi)別。
那么,有沒(méi)有一種方式,可以讓文本分類(lèi)不再需要任何標(biāo)注數(shù)據(jù)呢?
本文JayJay就介紹一篇來(lái)自「伊利諾伊大學(xué)香檳分校韓家煒老師課題組」的EMNLP20論文《Text Classification Using Label Names Only: A Language Model Self-Training Approach》。
這篇論文的最大亮點(diǎn)就是:不需要任何標(biāo)注數(shù)據(jù),只需利用標(biāo)簽名稱(chēng),就在四個(gè)分類(lèi)數(shù)據(jù)上獲得了近90%的準(zhǔn)確率!
為此,論文提出一種LOTClass模型,即Label-name-OnlyTextClassification,LOTClass模型的主要亮點(diǎn)有:
不需要任何標(biāo)注數(shù)據(jù),只需要標(biāo)簽名稱(chēng)!只依賴(lài)預(yù)訓(xùn)練語(yǔ)言模型(LM),不需要其他依賴(lài)!
提出了類(lèi)別指示詞匯獲取方法和基于上下文的單詞類(lèi)別預(yù)測(cè)任務(wù),經(jīng)過(guò)如此訓(xùn)練的LM進(jìn)一步對(duì)未標(biāo)注語(yǔ)料進(jìn)行自訓(xùn)練后,可以很好泛化!
在四個(gè)分類(lèi)數(shù)據(jù)集上,LOTClass明顯優(yōu)于各弱監(jiān)督模型,并具有與強(qiáng)半監(jiān)督和監(jiān)督模型相當(dāng)?shù)男阅堋?/p>
本文的組織結(jié)構(gòu)為:
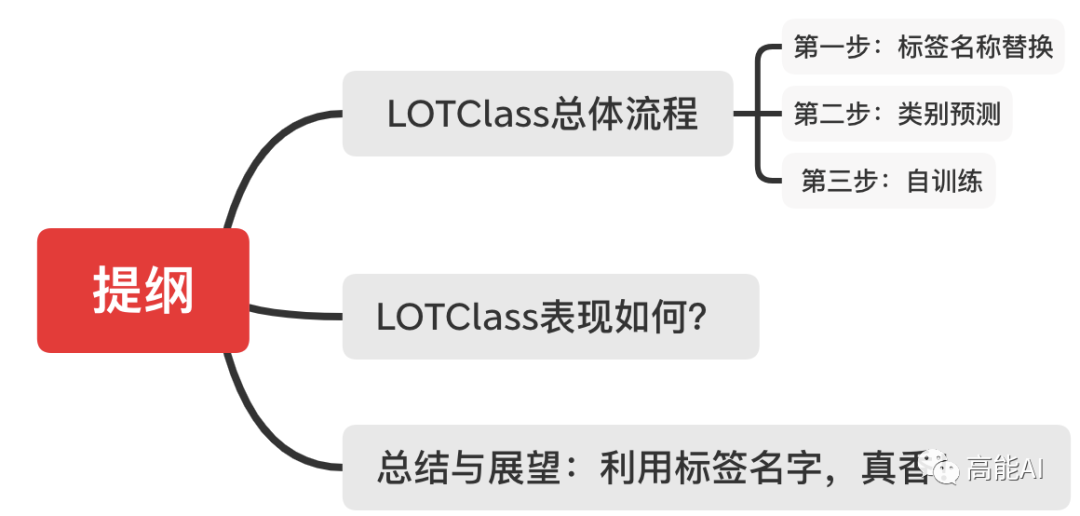
LOTClass總體流程
LOTClass將BERT作為其backbone模型,其總體實(shí)施流程分為以下三個(gè)步驟:
標(biāo)簽名稱(chēng)替換:利用并理解標(biāo)簽名稱(chēng),通過(guò)MLM生成類(lèi)別詞匯;
類(lèi)別預(yù)測(cè):通過(guò)MLM獲取類(lèi)別指示詞匯集合,并構(gòu)建基于上下文的單詞類(lèi)別預(yù)測(cè)任務(wù),訓(xùn)練LM模型;
自訓(xùn)練:基于上述LM模型,進(jìn)一步對(duì)未標(biāo)注語(yǔ)料進(jìn)行自訓(xùn)練后,以更好泛化!
下面我們就詳細(xì)介紹上述過(guò)程。
第一步:標(biāo)簽名稱(chēng)替換
在做文本分類(lèi)的時(shí)候,我們可以根據(jù)標(biāo)簽名稱(chēng)聯(lián)想到與之相關(guān)聯(lián)的其他關(guān)鍵詞,這些關(guān)鍵詞代表其類(lèi)別。當(dāng)然,這就需要我們從一個(gè)蘊(yùn)含常識(shí)的模型去理解每個(gè)標(biāo)簽的語(yǔ)義。很明顯,BERT等預(yù)訓(xùn)練LM模型就是一個(gè)首選!
論文采取的方法很直接:對(duì)于含標(biāo)簽名稱(chēng)的文本,通過(guò)MLM來(lái)預(yù)測(cè)其可以替換的其他相似詞匯。
如上圖展示了AG新聞?wù)Z料(體育新聞)中,對(duì)于標(biāo)簽名稱(chēng)“sports”,可通過(guò)MLM預(yù)測(cè)出替換「sports」的相似詞匯。
具體地,每一個(gè)標(biāo)簽名稱(chēng)位置通過(guò)MLM預(yù)測(cè)出TOP-50最相似的替換詞,然后再整體對(duì)每一個(gè)類(lèi)別的標(biāo)簽名稱(chēng)(Label Name)根據(jù)詞頻大小、結(jié)合停用詞共選取TOP-100,最終構(gòu)建類(lèi)型詞匯表(Category Vocabulary)。
通過(guò)上述方式找出了AG新聞?wù)Z料每一個(gè)類(lèi)別-標(biāo)簽名稱(chēng)對(duì)應(yīng)的類(lèi)別詞匯表,如上圖所示。
第二步:類(lèi)別預(yù)測(cè)
像人類(lèi)如何進(jìn)行分類(lèi)一樣,一種直接的方法是:利用上述得到的類(lèi)型詞匯表,然后統(tǒng)計(jì)語(yǔ)料中類(lèi)別詞匯出現(xiàn)的次數(shù)。但這種方式存在2個(gè)缺陷:
不同詞匯在不同的上下文中代表不同意思,不是所有在語(yǔ)料中出現(xiàn)的類(lèi)型詞匯都指示該類(lèi)型。在第一幅圖中,我們就可以清晰發(fā)現(xiàn):?jiǎn)卧~「sports」在第2個(gè)句子并不代表體育主題。
類(lèi)型詞匯表的覆蓋范圍有限:在特定上下文中,某些詞匯與類(lèi)別關(guān)鍵詞具有相似的含義,但不包含在類(lèi)別詞匯表中。
為了解決上述缺陷,論文構(gòu)建了一個(gè)新的MCP任務(wù)——基于MASK的類(lèi)別預(yù)測(cè)任務(wù)(Masked Category Prediction,MCP),如下圖所示:
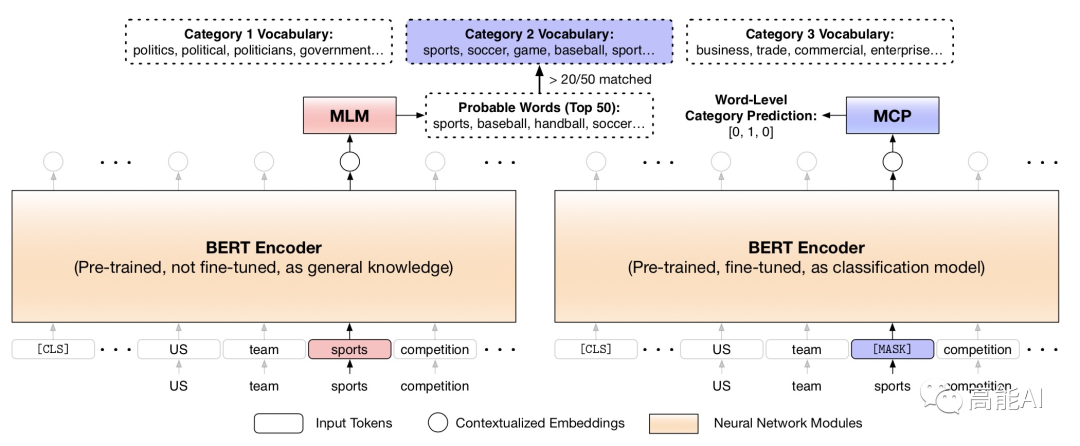
MCP任務(wù)共分為兩步:
獲取類(lèi)別指示詞:上述已經(jīng)提到,類(lèi)別詞匯表中不同的詞匯在不同上下文會(huì)指代不同類(lèi)別。論文建立了一種獲取類(lèi)別詞匯指示的方法(如上圖左邊所示):對(duì)于當(dāng)前詞匯,首先通過(guò)BERT的MLM任務(wù)預(yù)測(cè)當(dāng)前詞匯可替代的TOP50相似詞,然后TOP50相似詞與每個(gè)類(lèi)別詞匯表進(jìn)行比對(duì),如果有超過(guò)20個(gè)詞在當(dāng)前類(lèi)別詞匯表中,則選取當(dāng)前詞匯作為該類(lèi)別下的「類(lèi)別指示詞」。
進(jìn)行遮蔽類(lèi)別預(yù)測(cè):通過(guò)上一步,遍歷語(yǔ)料中的每一個(gè)詞匯,我們就可得到類(lèi)別指示詞集合和詞匯所對(duì)應(yīng)的標(biāo)簽。對(duì)于類(lèi)別指示詞集合中每一個(gè)的單詞,我們將其替換為「MASK」然后對(duì)當(dāng)前位置進(jìn)行標(biāo)簽分類(lèi)訓(xùn)練。
值得注意的是:MASK類(lèi)別指示詞、進(jìn)行類(lèi)別預(yù)測(cè)至關(guān)重要,因?yàn)檫@會(huì)迫使模型根據(jù)單詞上下文來(lái)推斷類(lèi)別,而不是簡(jiǎn)單地記住無(wú)上下文的類(lèi)別關(guān)鍵字。通過(guò)MCP任務(wù),BERT將更好編碼類(lèi)別判斷信息。
第三步:自訓(xùn)練
論文將通過(guò)MCP任務(wù)訓(xùn)練好的BERT模型,又對(duì)未標(biāo)注語(yǔ)料進(jìn)行了自訓(xùn)練。這樣做的原因?yàn)椋?/p>
仍有大規(guī)模語(yǔ)料未被MCP任務(wù)利用,畢竟不是每一個(gè)語(yǔ)料樣本含有類(lèi)別指示詞。
MCP任務(wù)進(jìn)行類(lèi)別預(yù)測(cè)不是在「CLS」位置,「CLS」位置更利于編碼全局信息并進(jìn)行分類(lèi)任務(wù)。
論文采取的自訓(xùn)練方式很簡(jiǎn)單,如上圖所示,每50個(gè)batch通過(guò)軟標(biāo)簽方式更新一次標(biāo)簽類(lèi)別。
LOTClass表現(xiàn)如何?
為了驗(yàn)證LOTClass的效果,論文在4個(gè)分類(lèi)數(shù)據(jù)集上與監(jiān)督、半監(jiān)督和弱監(jiān)督進(jìn)行了對(duì)比。
對(duì)于弱監(jiān)督方法,則將整個(gè)訓(xùn)練集作為未標(biāo)注數(shù)據(jù);對(duì)于半監(jiān)督方法,每個(gè)類(lèi)別選舉10個(gè)樣本作為標(biāo)注數(shù)據(jù);對(duì)于監(jiān)督方法,則全部訓(xùn)練集就是標(biāo)注數(shù)據(jù)。
如上圖所示,沒(méi)有自訓(xùn)練的LOTClass方法就超過(guò)了一眾弱監(jiān)督方法,而利用自訓(xùn)練方法后LOTClass甚至在AG-News上可以與半監(jiān)督學(xué)習(xí)的SOTA——谷歌提出的UDA相媲美了,與有監(jiān)督的char-CNN方法也相差不多啦!自訓(xùn)練self-trainng為何如此強(qiáng)大?我們將在接下來(lái)的推文中會(huì)進(jìn)一步介紹。
也許你還會(huì)問(wèn):LOTClass相當(dāng)于使用多少標(biāo)注數(shù)據(jù)呢?
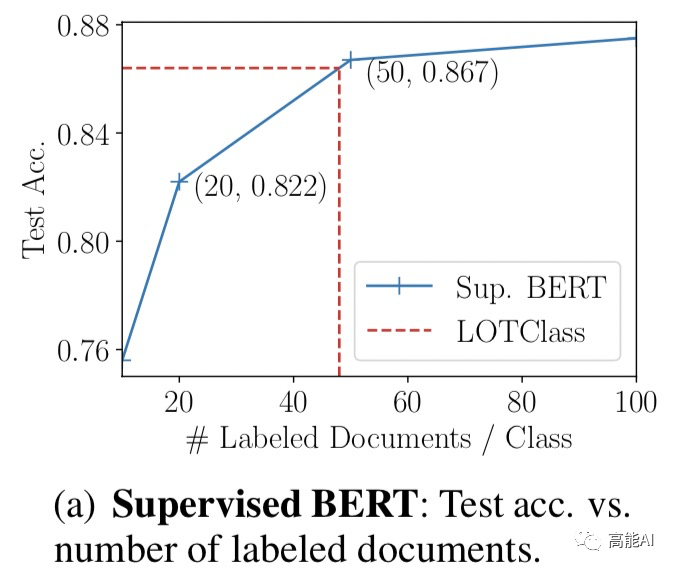
如上圖,論文給出了答案,那就是:LOTClass效果相當(dāng)于 每個(gè)類(lèi)別使用48個(gè)標(biāo)注文檔的有監(jiān)督BERT模型!
總結(jié)與展望:利用標(biāo)簽名稱(chēng),真香!
首先對(duì)本文總結(jié)一下:本文提出的LOTClass模型僅僅利用標(biāo)簽名稱(chēng),無(wú)需任務(wù)標(biāo)注數(shù)據(jù)!在四個(gè)分類(lèi)數(shù)據(jù)上獲得了近90%的準(zhǔn)確率,與相關(guān)半監(jiān)督、有監(jiān)督方法相媲美!LOTClass模型總體實(shí)施流程分三個(gè)步驟:標(biāo)簽名稱(chēng)替換,MASK類(lèi)別預(yù)測(cè),自訓(xùn)練。
本文提出的LOTClass模型只是基于BERT,并沒(méi)有采取更NB的LM模型,每個(gè)類(lèi)別最多使用3個(gè)單詞作為標(biāo)簽名稱(chēng),沒(méi)有依賴(lài)其他工具(如回譯方式)。我們可以預(yù)測(cè):隨著LM模型的升級(jí),數(shù)據(jù)增強(qiáng)技術(shù)的使用,指標(biāo)性能會(huì)更好!
利用標(biāo)簽名稱(chēng),我們是不是還可以暢想一些“真香現(xiàn)場(chǎng)”呢?例如:
應(yīng)用于NER任務(wù):發(fā)現(xiàn)實(shí)體類(lèi)別下的更多指示詞,如「PERSON」類(lèi)別;嗯嗯,再好好想象怎么把那套MCP任務(wù)嵌入到NER任務(wù)中吧~
與半監(jiān)督學(xué)習(xí)更好協(xié)作:1)沒(méi)有標(biāo)注數(shù)據(jù)時(shí),可以通過(guò)LOTClass構(gòu)建初始標(biāo)注數(shù)據(jù)再進(jìn)行半監(jiān)督流程;2)將MCP任務(wù)設(shè)為半監(jiān)督學(xué)習(xí)的輔助任務(wù)。
原文標(biāo)題:韓家煒課題組重磅發(fā)文:文本分類(lèi)只需標(biāo)簽名稱(chēng),不需要任何標(biāo)注數(shù)據(jù)!
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7256瀏覽量
91838 -
人工智能
+關(guān)注
關(guān)注
1806文章
49012瀏覽量
249382
原文標(biāo)題:韓家煒課題組重磅發(fā)文:文本分類(lèi)只需標(biāo)簽名稱(chēng),不需要任何標(biāo)注數(shù)據(jù)!
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
耐達(dá)訊CAN轉(zhuǎn)EtherCAT網(wǎng)關(guān),變頻器通信升級(jí)的“真香”指南
海辰儲(chǔ)能與Schoenergie開(kāi)啟德國(guó)首個(gè)大型儲(chǔ)能項(xiàng)目
如何使用ddc進(jìn)行數(shù)據(jù)分類(lèi)
LDC1000evm上線(xiàn)圈不變,再并聯(lián)一個(gè)大電容的話(huà),會(huì)怎么樣?
如何使用自然語(yǔ)言處理分析文本數(shù)據(jù)
如何在文本字段中使用上標(biāo)、下標(biāo)及變量

從零開(kāi)始訓(xùn)練一個(gè)大語(yǔ)言模型需要投資多少錢(qián)?

使用LLM進(jìn)行自然語(yǔ)言處理的優(yōu)缺點(diǎn)
RK3588 技術(shù)分享 | 在Android系統(tǒng)中使用NPU實(shí)現(xiàn)Yolov5分類(lèi)檢測(cè)
用兩個(gè)OPA695和一個(gè)VCA821構(gòu)成一個(gè)大約60db的放大電路,增益下降的原因?
谷歌擬在越南建立其首個(gè)大型數(shù)據(jù)中心
RK3588 技術(shù)分享 | 在Android系統(tǒng)中使用NPU實(shí)現(xiàn)Yolov5分類(lèi)檢測(cè)
如何訓(xùn)練一個(gè)有效的eIQ基本分類(lèi)模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論