 人工智能計算體系與通訊架構的革新展望
人工智能計算體系與通訊架構的革新展望

人工智能從20世紀50年代開始,經歷了60年起伏的發展歷程。其中,AI共經歷了2次發展的春天和冬天,現在正在經歷第3個春天,即以數據為驅動力的深度學習。谷歌的AlphaGo、AlphaZero、AlphaFold是很好的標志性產品。
佩德羅多明戈斯曾總結了 AI 的五大流派,包括符號、進化學派、類比學派、貝葉斯學派和連接機制。未來AI的發展 趨勢最大的可能是借各種流派之長創造新的AI算法,既包含邏輯符號也有數據和知識,還要借鑒人類的進化和大腦的特點。所以,當前無論是科學研究還是產業發展,都在思考下一輪AI的突破點在什么地方。
算力需求飛速增長的瓶頸
對深度學習來說,半導體與芯片架構領域的進步是不可或缺的發展動力。谷歌公司的杰夫狄恩曾說過:“數據+算法+算力=數據+100×算力”。也就是說,他認為在數據、算法和算力三大因素中,算力占據著絕對的主導地位,算法則相對來說沒有那么重要。
隨著時代的發展,深度學習在訓練過程中產生的計算量可以分成兩個階段:在深度學習發展的初期階段,訓練產生的計算量的增長速率相對較慢;近10年間,計算量以每年10倍的速率增長,遠遠超過摩爾定律每18~24個月提高2倍的增長速率。
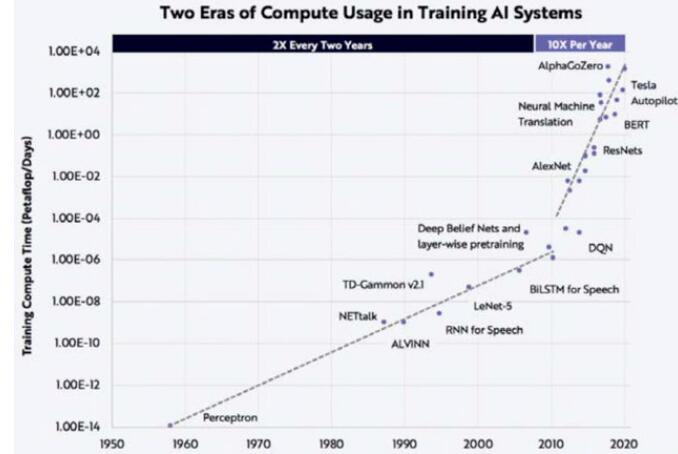
深度學習訓練過程中計算量需求的發展
以OpenAI發布的預訓練模型GPT為例,來說明近幾年來機器學習領域對算力需求的飛速增長。2018年6月發布的GPT-1是在約5GB的文本上進行無監督訓練,針對具體任務,在小的有監督數據集上做微調,得到包含1.1億參數的預訓練模型;而2019年2月發布的GPT-2則是在約40GB文本上進行無監督訓練,得到具有15億參數的預訓練模型;而2020年5月公布的GPT-3則是在 499B tokens(令牌)的數據基礎上訓練,得到包含1750億參數的模型。在不到2年的時間內,模型參數從1.1億的規模增長至1750億,而單次訓練GPT-3就需要花費1200萬美元,模型在飛速發展的同時,帶來的是巨大的算力要求和高成本的代價。
傳統計算與通訊范式的瓶頸
人工智能領域對算力的需求驅動了新算力的發展。要想謀求更高效率的計算,就需要回到計算和通訊領域最基本的理論和范式。在過去的幾十年間,涌現出了許許多多的定律和體系,而其中有三個定律和體系被視為計算與通訊范式的根本。
第一個是香農定律(Shannon Theroy)。香農是信息論的奠基者,他引入了信息熵的概念,為數字通信奠定了基矗其實香農定律定義了三個極限,分別為無損壓縮極限E、信道傳輸極限C、有損壓縮極限R(D)。目前,我們已經接近這些極限。
第二個是馮諾伊曼架構(Von neumann Structure)。在馮諾伊曼架構中,計算機由運算器、控制器、存儲器、輸入設備和輸出設備5個基本部分組成,具有程序存儲、共享數據、順序執行的特點。馮諾伊曼架構簡單且漂亮,是圖靈機的優秀范例,至今仍被廣泛地應用。然而,馮諾伊曼架構的設計構成了運算器和存儲器間的瓶頸,這對深度學習的發展造成了一定的限制。
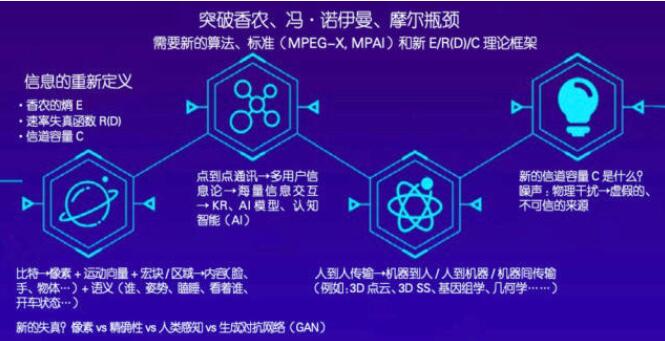
信息論的研究方向
第三個是摩爾定律(Moore‘s Law)。戈登摩爾(Gordon Moore)總結認為,集成電路上可以容納的晶體管數目大約在18 個月左右便會增加一倍。而現在晶體管數目的增長越來越慢,摩爾定律逐步趨向于飽和階段,而我們對計算能力的需求卻飛速 提升,不斷提升的算力需求與芯片技術發展趨緩的矛盾日趨顯現。
計算體系與通訊架構的革新展望
在過去的60年里,這三個基本理論在計算和 通訊領域建立了決定性的基礎,然而日趨逼近的極限也使得當前AI技術的發展逐步接近瓶頸。為了避免技術的停滯不前,產業界或許可以從以下三個方面做出一些突破和革新。
首先,對信息重新定義。香農于上世紀40年代對信息熵、速率失真函數R(D)和信道容量C做出了定義,而這些定義是基于比特的基礎實現的。以視頻圖像舉例,過去我們一直采用比特來描述信息;后來我們從數字的層面使用像素、運動向量、宏塊(macroblock)和區域(regions)結合的方式來描述圖像;之后我們上升到從內容層面來描述圖像,比如一個身體部位是臉部還是手部等;現在我們對圖像的描述上升到語義層面,比如“是誰”“在做什么動作”“是否在睡覺”“眼睛在看什么”等,這些問題從語義的層面描述了圖像傳達的信息。當信息的描述方式發生變化時,熵的概念也發生了變化。比方說,過去我們用比特的形式來描述圖像失真現象,而現在我們用生成對抗網絡(Generative Adversarial Networks,GAN)生成圖像,用肉眼來看GAN輸入的圖片和生成的圖像幾乎是一致的,但是從比特層面 來比較,會發現二者十分不同。因此,如何從語義、特征和內容的角度來定義熵與速率失真函數是我們未 來需要研究的問題。另外,香農理論從最開始的點到點通訊,擴展到后來的多用戶信息論。但是在當下的互聯網時代,面對海量的交互信息,部分香農理論已不再適用,學術界卻沒有提出一個新的完善的理論。 過去的信息更多的是人與人之間的傳輸,而現在的信息則更多地面向機器,比如3D Point Cloud、3D SS、Genomics、Geometry等,所以我們需要新的算法和新的標準。
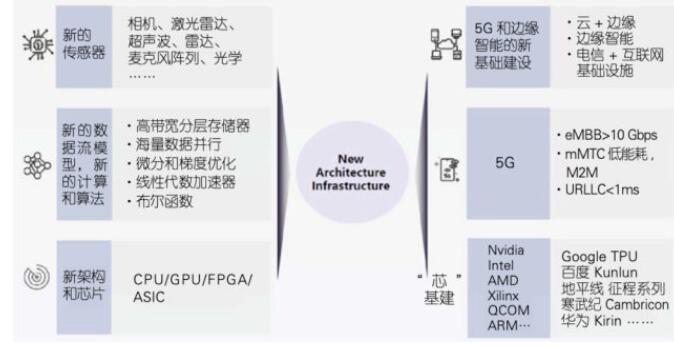
計算體系與通訊架構的研究方向
第二,我們需要新的計算范式。包括量子計算、類腦計算和生物計算等在內的新的計算范式能夠為計算瓶頸提供解決途徑。
第三,我們需要新的計算體系和通訊架構突破馮諾伊曼體系架構的限制。首先,我們需要新的傳感器、新的數據流架構和計算模式,以及高速的存儲,這些都與傳統的馮諾伊曼架構不同。我們還需要新的通訊架構,即5G技術和邊緣計算。5G技術首次在應用層上實現了“三網合一”,比提升傳輸的速度更加有效。此外,5G技術更好地解決了延時問題并帶來了新的應用,如百度的阿波羅項目中有一個服務叫做“云代駕”,通過5G技術讓遠程的安全操作員實時了解車輛所處的環境與狀態,在自動駕駛無法完成的場景 下接管車輛,完成遠程協助。但3G和4G網絡的延遲使得“云代駕”模式無法成為現實,必須通過5G網絡來解決延遲問題。很多人認為,當前的5G技術在能耗和覆蓋率等方面還沒有達到預期,但任何新技術的發展都需要時間,相信在未來的三五年后,5G技術能夠為用戶、工業和產業界帶來巨大的變革。
芯片的升級對產業界的作用是顯著的,近年來國內有許多公司在芯片領域有所成就。以百度的昆侖AI芯片為例,第一代昆侖芯片采用14nm先進工藝,2.5D封裝,使用HBM內存,可以達到 512GB/s 的帶寬。而預計于2021年量產的第二代昆侖芯片,采用7nm先進工藝,性能是第一代昆侖芯片的3倍,同時耗能減少,具備了大規模片間互聯的能力,進步顯著。
責任編輯:YYX
-
通訊
+關注
關注
9文章
927瀏覽量
35646 -
人工智能
+關注
關注
1806文章
48987瀏覽量
249093 -
深度學習
+關注
關注
73文章
5560瀏覽量
122764
發布評論請先 登錄





 工商網監
工商網監
評論