 詳解Tutorial代碼的學習過程與準備
詳解Tutorial代碼的學習過程與準備

導讀:本文主要解析Pytorch Tutorial中BiLSTM_CRF代碼,幾乎注釋了每行代碼,希望本文能夠幫助大家理解這個tutorial,除此之外借助代碼和圖解也對理解條件隨機場(CRF)會有一定幫助,因為這個tutorial代碼主要還是在實現CRF部分。
1 知識準備
在閱讀tutorial前,需具備一些理論或知識基礎,包括LSTM單元、BiLSTM-CRF模型、CRF原理以及一些代碼中的函數使用,參考資料中涵蓋了主要的涉及知識,可配合tutorial一同學習。
2 理解CRF中歸一化因子Z(x)的計算
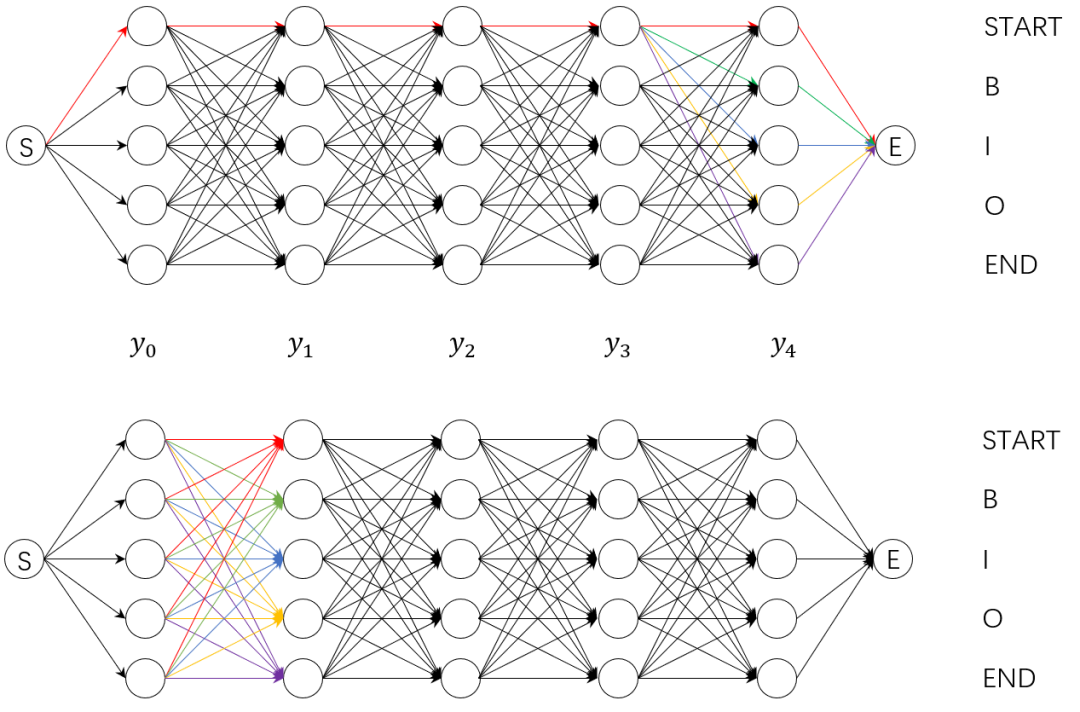
條件隨機場中的Z(x)表示歸一化因子,它是一個句子所有可能標記tag序列路徑的得分總和。一般的,我們會有一個直接的想法,就是列舉出所有可能的路徑,計算出每條路徑的得分之后再加和。如上圖中的例子所示,有5個字符和5個tag,如果按照上述的暴力窮舉法進行計算,就有種路徑組合,而在我們的實際工作中,可能會有更長的序列和更多的tag標簽,此時暴力窮舉法未免顯得有些效率低下。于是我們考慮采用分數累積的方式進行所有路徑得分總和的計算,即先計算出到達的所有路徑的總得分,然后計算-》的所有路徑的得分,然后依次計算-》。..-》間的所有路徑的得分,最后便得到了我們的得分總和,這個思路源于如下等價等式:

上式相等表明,直接計算整個句子序列的全局分數與計算每一步的路徑得分再加和等價,計算每一步的路徑得分再加和這種方式可以大大減少計算的時間,故Pytorch Tutorial中的_forward_alg()函數據此實現。這種計算每一步的路徑得分再加和的方法還可以以下圖方式進行計算。
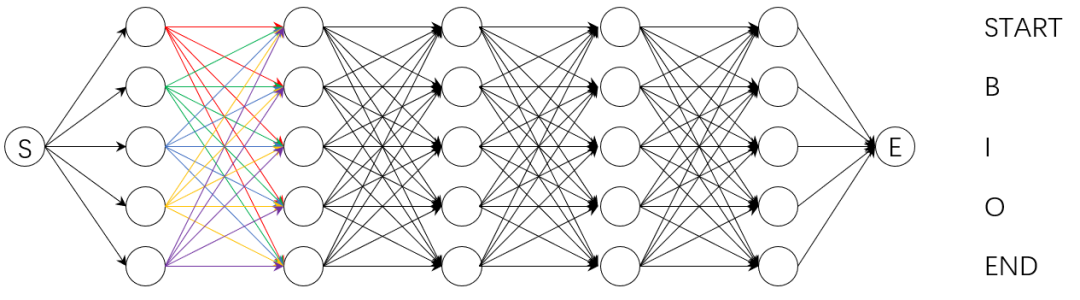
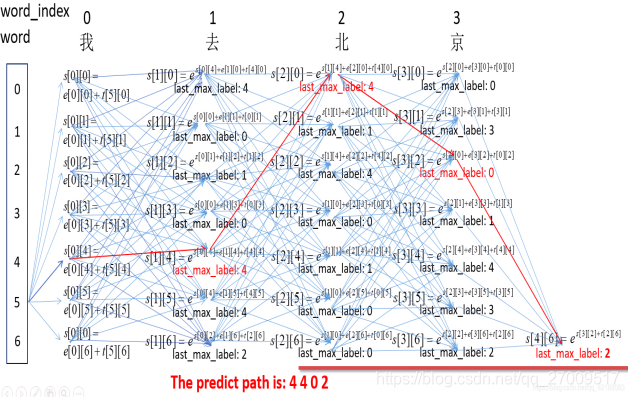
如上圖所示,在每個時間步上,比如’word==去‘這一列,每一個tag處(0~6豎框是tag的id),關注兩個值:前一個時間步上所有tag到當前tag中總得分最大值以及該最大值對應的前一個時間步上tag的id。這樣一來每個tag都記錄了它前一個時間步上到自己的最優路徑,最后通過tag的id進行回溯,這樣就可以得到最終的最優tag標記序列。此部分對應Pytorch Tutorial中的_viterbi_decode()函數實現。
4 理解log_sum_exp()函數
Pytorch Tutorial中的log_sum_exp()函數最后返回的計算方式數學推導如下:
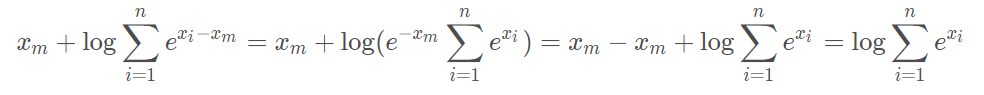
5 Pytorch Tutorial代碼部分注釋輔助理解
import torch
import torch.nn as nn
import torch.optim as optim
# 人工設定隨機種子以保證相同的初始化參數,使模型可復現
torch.manual_seed(1)
# 得到每行最大值索引idx
def argmax(vec):
# 得到每行最大值索引idx
_, idx = torch.max(vec, 1)
# 返回每行最大值位置索引
return idx.item()
# 將序列中的字轉化為數字(int)表示
def prepare_sequence(seq, to_ix):
# 將序列中的字轉化為數字(int)表示
idx = [to_ix[c] for c in seq]
return torch.tensor(idx, dtype=torch.long)
# 前向算法是不斷積累之前的結果,這樣就會有個缺點
# 指數和積累到一定程度之后,會超過計算機浮點值的最大值
# 變成inf,這樣取log后也是inf
# 為了避免這種情況,用一個合適的值clip=max去提指數和的公因子
# 這樣不會使某項變得過大而無法計算
def log_sum_exp(vec):# vec:形似[[tag個元素]]
# 取vec中最大值
max_score = vec[0, argmax(vec)]
# vec.size()[1]:tag數
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
# 里面先做減法,減去最大值可以避免e的指數次,計算機上溢
# 等同于torch.log(torch.sum(torch.exp(vec))),防止e的指數導致計算機上溢
return max_score + torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
class BiLSTM_CRF(nn.Module):
# 初始化參數
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
# 詞嵌入維度
self.embedding_dim = embedding_dim
# BiLSTM 隱藏層維度
self.hidden_dim = hidden_dim
# 詞典的大小
self.vocab_size = vocab_size
# tag到數字的映射
self.tag_to_ix = tag_to_ix
# tag個數
self.tagset_size = len(tag_to_ix)
# num_embeddings (int):vocab_size 詞典的大小
# embedding_dim (int):embedding_dim 嵌入向量的維度,即用多少維來表示一個符號
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
# input_size: embedding_dim 輸入數據的特征維數,通常就是embedding_dim(詞向量的維度)
# hidden_size: hidden_dim LSTM中隱藏層的維度
# 默認使用偏置,默認不用dropout
# bidirectional = True 用雙向LSTM
# 設定為單層雙向
# 隱藏層設定為指定維度的一半,便于后期拼接
# // 表示整數除法,返回不大于結果的一個最大的整數
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# 將BiLSTM提取的特征向量映射到特征空間,即經過全連接得到發射分數
# in_features: hidden_dim 每個輸入樣本的大小
# out_features:tagset_size 每個輸出樣本的大小
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# 轉移矩陣的參數初始化,transition[i,j]代表的是從第j個tag轉移到第i個tag的轉移分數
self.transitions = nn.Parameter(torch.randn(self.tagset_size, self.tagset_size))
# 初始化所有其他tag轉移到START_TAG的分數非常小,即不可能由其他tag轉移到START_TAG
# 初始化STOP_TAG轉移到所有其他的分數非常小,即不可能有STOP_TAG轉移到其他tag
# CRF的轉移矩陣,T[i,j]表示從j標簽轉移到i標簽,
self.transitions.data[tag_to_ix[START_TAG], :] = -10000
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000
# 初始化LSTM的參數
self.hidden = self.init_hidden()
# 使用隨機正態分布初始化LSTM的h0和c0
# 否則模型自動初始化為零值,維度為[num_layers*num_directions, batch_size, hidden_dim]
def init_hidden(self):
return (torch.randn(2, 1, self.hidden_dim // 2),
torch.randn(2, 1, self.hidden_dim // 2))
# 計算歸一化因子Z(x)
def _forward_alg(self, feats):
‘’‘
輸入:發射矩陣(emission score),實際上就是LSTM的輸出
sentence的每個word經BiLSTM后對應于每個label的得分
輸出:所有可能路徑得分之和/歸一化因子/配分函數/Z(x)
’‘’
# 通過前向算法遞推計算
# 初始化1行 tagset_size列的嵌套列表
init_alphas = torch.full((1, self.tagset_size), -10000.)
# 初始化step 0 即START位置的發射分數,START_TAG取0其他位置取-10000
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# 包裝到一個變量里面以便自動反向傳播
forward_var = init_alphas
# 迭代整個句子
# feats:形似[[。..。], 每個字映射到tag的發射概率,
# [。..。],
# [。..。]]
for feat in feats:
# 存儲當前時間步下各tag得分
alphas_t = []
for next_tag in range(self.tagset_size):
# 取出當前tag的發射分數(與之前時間步的tag無關),擴展成tag維
emit_score = feat[next_tag].view(1, -1).expand(1, self.tagset_size)
# 取出當前tag由之前tag轉移過來的轉移分數
trans_score = self.transitions[next_tag].view(1, -1)
# 當前路徑的分數:之前時間步分數+轉移分數+發射分數
next_tag_var = forward_var + trans_score + emit_score
# 對當前分數取log-sum-exp
alphas_t.append(log_sum_exp(next_tag_var).view(1))
# 更新forward_var 遞推計算下一個時間步
# torch.cat 默認按行添加
forward_var = torch.cat(alphas_t).view(1, -1)
# 考慮最終轉移到STOP_TAG
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
# 對當前分數取log-sum-exp
scores = log_sum_exp(terminal_var)
return scores
# 通過BiLSTM提取特征
def _get_lstm_features(self, sentence):
# 初始化LSTM的h0和c0
self.hidden = self.init_hidden()
# 使用之前構造的詞嵌入為語句中每個詞(word_id)生成向量表示
# 并將shape改為[seq_len, 1(batch_size), embedding_dim]
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
# LSTM網絡根據輸入的詞向量和初始狀態h0和c0
# 計算得到輸出結果lstm_out和最后狀態hn和cn
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
# 轉換為詞 - 標簽([seq_len, tagset_size])表
# 可以看作為每個詞被標注為對應標簽的得分情況,即維特比算法中的發射矩陣
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
# 計算一個tag序列路徑的得分
def _score_sentence(self, feats, tags):
# feats發射分數矩陣
# 計算給定tag序列的分數,即一條路徑的分數
score = torch.zeros(1)
# tags前面補上一個句首標簽便于計算轉移得分
tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long), tags])
# 循環用于計算給定tag序列的分數
for i, feat in enumerate(feats):
# 遞推計算路徑分數:轉移分數+發射分數
# T[i,j]表示j轉移到i
score = score + self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
# 加上轉移到句尾的得分,便得到了gold_score
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score
# veterbi解碼,得到最優tag序列
def _viterbi_decode(self, feats):
‘’‘
:param feats: 發射分數矩陣
’‘’
# 便于之后回溯最優路徑
backpointers = []
# 初始化viterbi的forward_var變量
init_vvars = torch.full((1, self.tagset_size), -10000.)
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# forward_var表示每個標簽的前向狀態得分,即上一個詞被打作每個標簽的對應得分值
forward_var = init_vvars
# 遍歷每個時間步時的發射分數
for feat in feats:
# 記錄當前詞對應每個標簽的最優轉移結點
# 保存當前時間步的回溯指針
bptrs_t = []
# 與bptrs_t對應,記錄對應的最優值
# 保存當前時間步的viterbi變量
viterbivars_t = []
# 遍歷每個標簽,求得當前詞被打作每個標簽的得分
# 并將其與當前詞的發射矩陣feat相加,得到當前狀態,即下一個詞的前向狀態
for next_tag in range(self.tagset_size):
# transitions[next_tag]表示每個標簽轉移到next_tag的轉移得分
# forward_var表示每個標簽的前向狀態得分,即上一個詞被打作每個標簽的對應得分值
# 二者相加即得到當前詞被打作next_tag的所有可能得分
# 維特比算法記錄最優路徑時只考慮上一步的分數以及上一步的tag轉移到當前tag的轉移分數
# 并不取決于當前的tag發射分數
next_tag_var = forward_var + self.transitions[next_tag]
# 得到上一個可能的tag到當前tag中得分最大值的tag位置索引id
best_tag_id = argmax(next_tag_var)
# 將最優tag的位置索引存入bptrs_t
bptrs_t.append(best_tag_id)
# 添加最優tag位置索引對應的值
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
# 更新forward_var = 當前詞的發射分數feat + 前一個最優tag當前tag的狀態下的得分
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
# 回溯指針記錄當前時間步各個tag來源前一步的最優tag
backpointers.append(bptrs_t)
# forward_var表示每個標簽的前向狀態得分
# 加上轉移到句尾標簽STOP_TAG的轉移得分
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
# 得到標簽STOP_TAG前一個時間步的最優tag位置索引
best_tag_id = argmax(terminal_var)
# 得到標簽STOP_TAG當前最優tag對應的分數值
path_score = terminal_var[0][best_tag_id]
# 根據過程中存儲的轉移路徑結點,反推最優轉移路徑
# 通過回溯指針解碼出最優路徑
best_path = [best_tag_id]
# best_tag_id作為線頭,反向遍歷backpointers找到最優路徑
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# 去除START_TAG
start = best_path.pop()
# 最初的轉移結點一定是人為構建的START_TAG,刪除,并根據這一點確認路徑正確性
assert start == self.tag_to_ix[START_TAG]
# 最后將路徑倒序即得到從頭開始的最優轉移路徑best_path
best_path.reverse()
return path_score, best_path
# 損失函數loss
def neg_log_likelihood(self, sentence, tags):
# 得到句子對應的發射分數矩陣
feats = self._get_lstm_features(sentence)
# 通過前向算法得到歸一化因子Z(x)
forward_score = self._forward_alg(feats)
# 得到tag序列的路徑得分
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
# 輸入語句序列得到最佳tag路徑及其得分
def forward(self, sentence): # dont confuse this with _forward_alg above.
# 從BiLSTM獲得發射分數矩陣
lstm_feats = self._get_lstm_features(sentence)
# 使用維特比算法進行解碼,計算最佳tag路徑及其得分
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
START_TAG = “《START》”
STOP_TAG = “《STOP》”
# 詞嵌入維度
EMBEDDING_DIM = 5
# LSTM隱藏層維度
HIDDEN_DIM = 4
# 訓練數據
training_data = [(
“the wall street journal reported today that apple corporation made money”.split(),
“B I I I O O O B I O O”.split()
), (
“georgia tech is a university in georgia”.split(),
“B I O O O O B”.split()
)]
word_to_ix = {}
# 構建詞索引表,數字化以便計算機處理
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
# 構建標簽索引表,數字化以便計算機處理
tag_to_ix = {“B”: 0, “I”: 1, “O”: 2, START_TAG: 3, STOP_TAG: 4}
# 初始化模型參數
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM)
# 使用隨機梯度下降法(SGD)進行參數優化
# model.parameters()為該實例中可優化的參數,
# lr:學習率,weight_decay:正則化系數,防止模型過擬合
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# 在no_grad模式下進行前向推斷的檢測,函數作用是暫時不進行導數的計算,目的在于減少計算量和內存消耗
# 訓練前檢查模型預測結果
with torch.no_grad():
# 取訓練數據中第一條語句序列轉化為數字
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
# 取訓練數據中第一條語句序列對應的標簽序列進行數字化
precheck_tags = torch.tensor([tag_to_ix[t] for t in training_data[0][1]], dtype=torch.long)
print(model(precheck_sent))
# 300輪迭代訓練
for epoch in range(300):
for sentence, tags in training_data:
# Step 1. 每次開始前將上一輪的參數梯度清零,防止累加影響
model.zero_grad()
# Step 2. seq、tags分別數字化為sentence_in、targets
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# Step 3. 損失函數loss
loss = model.neg_log_likelihood(sentence_in, targets)
# Step 4. 通過調用optimizer.step()計算損失、梯度、更新參數
loss.backward()
optimizer.step()
# torch.no_grad() 是一個上下文管理器,被該語句 wrap 起來的部分將不會track 梯度
# 訓練結束查看模型預測結果,對比觀察模型是否學到
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
print(model(precheck_sent))
# We got it!
歡迎交流指正
參考資料:
[1]torch.max()使用講解
https://www.jianshu.com/p/3ed11362b54f
[2]torch.manual_seed()用法
https://www.cnblogs.com/dychen/p/13920000.html
[3]BiLSTM-CRF原理介紹+Pytorch_Tutorial代碼解析
https://blog.csdn.net/misite_j/article/details/109036725
[4]關于nn.embedding函數的理解
https://blog.csdn.net/a845717607/article/details/104752736
[5]torch.nn.LSTM()詳解
https://blog.csdn.net/m0_45478865/article/details/104455978
[6]pytorch函數之nn.Linear
https://www.cnblogs.com/Archer-Fang/p/10645473.html
[7]pytorch之torch.randn()
https://blog.csdn.net/zouxiaolv/article/details/99568414
[8]torch.full()
https://blog.csdn.net/Fluid_ray/article/details/109855155
[9]PyTorch中view的用法
https://blog.csdn.net/york1996/article/details/81949843
https://blog.csdn.net/zkq_1986/article/details/100319146
[10]torch.cat()函數
https://blog.csdn.net/xinjieyuan/article/details/105208352
[11]ADVANCED: MAKING DYNAMIC DECISIONS AND THE BI-LSTM CRF
https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html
[12]條件隨機場理論理解
https://blog.csdn.net/qq_27009517/article/details/107154441
[13]PyTorch tutorial - BiLSTM CRF 代碼解析
https://blog.csdn.net/ono_online/article/details/105089750
編輯:lyn
-
函數
+關注
關注
3文章
4381瀏覽量
64947 -
代碼
+關注
關注
30文章
4900瀏覽量
70799 -
LSTM
+關注
關注
0文章
60瀏覽量
4057
原文標題:【NER】命名實體識別:詳解BiLSTM_CRF_Pytorch_Tutorial代碼
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現

銅排制作工藝詳解 銅排的導電性能分析
如何在日常開發過程中提高代碼質量

探討篇(三):代碼復用的智慧 - 提升架構的效率與可維護性

BTB擴展接口:LCD、Camera、UART、I2C等|詳解篇
在學習go語言的過程踩過的坑
電子設計競賽準備經歷分享

數據準備指南:10種基礎特征工程方法的實戰教程





 工商網監
工商網監
評論