 Series4擁有經得起未來考驗的性能和計算密度
Series4擁有經得起未來考驗的性能和計算密度

深度學習的多功能性和強大功能意味著現代神經網絡在機器翻譯、動作識別、任務規劃、情感分析和圖像處理等領域有著廣泛的應用。隨著該領域的不斷成熟,不可避免的,專業化程度也越來越高,而且呈現加速的趨勢。這使保持現有技術水平成為一項挑戰,更不用說預測神經網絡的未來計算需求了。
神經網絡加速器 (NNA) IP 的設計者手頭有一項艱巨的任務:確保他們的產品具有足夠的通用性,能夠應用于當前和未來非常廣泛的應用,同時保證高性能。在Imagination公司最前沿的 IMG Series4 NNA 所針對的移動、汽車、數據中心和嵌入式領域中,對帶寬、面積和功耗有更嚴格的限制。Imagination公司的工程師們已經找到了創新的方法來應對這些嚴峻挑戰,并提供超高性能和面向未來的IP。
利用率與靈活性
每個IMG Series4 多核NNA的核心是行業領先的卷積引擎陣列,每秒可執行 10 萬億次操作。四核Series4 NNA每秒可完成驚人的40萬億次操作,簡稱40TOPS。其架構的一個顯著特點是效率:數據盡可能緊密地打包在卷積引擎的輸入上,以實現最大可能的利用率,這意味著芯片面積保持最小。Series4 NNA 包含幾個高度優化、可快速配置的硬件模塊,用于池化、標準化和激活功能等操作。
這種專業化程度顯然在網絡與硬件很匹配的情況下獲得了巨大的回報,也就是說,當網絡由卷積層、池化層、激活層等“傳統”層組成,但是這樣的體系結構如何擴展以支持更復雜的操作,比如注意機制和非最大化抑制?
有兩個明顯的選擇:
在硬件中添加新的專用塊。
使硬件具有高度可編程性和通用性。
其中第一個主要問題是,它會導致硬件膨脹和暗硅——如果在一些應用程序中需要多1%的計算時間,那么我們需要一個固定的功能模塊嗎?不——我們必須獲得盡可能重復使用硬件。這也意味著硬件總是保持最前沿的工藝技術。添加固定功能模塊說明硬件未來會過時,NNA的設計師們之前遇到過不少硬件適用性受限于操作類型的案例。第一種方法導致硬件膨脹或強制使用額外的“協處理器”,如GPU、DSP或CPU:硅面積、帶寬、能量和復雜性都會增加。大多數NNA 設計人員都選擇第二種方案。這種方法的例子是基于向量 ALU 和脈動陣列的設計。復雜性從硬件轉移到軟件,這一切都符合計算機體系結構中歷史悠久的 RISC(精簡指令集計算機)哲學。然而,要付出巨大的代價——計算密度的降低。為達到40 TOPS 的目標, Series4 NNA架構師必須容忍芯片面積和功耗的大幅增長。Imagination的研究人員認為,一定存在第三種方式。他們的策略是利用新穎的編譯技術和他們稱之為“簡化操作集計算”(ROSC)的新設計理念來換取靈活性。
Series4 NNA具有巨大的計算密度,用于運行標準層,如卷積層、池化層、激活層和完全連接的圖層,這些層占據了神經網絡中大部分計算需求。從本質上講,它具有冗余的計算能力。簡單地說,ROSC 就是從這個簡化的“操作集”中重新配置和重組操作,以構建各種各樣的其他操作:乍一看,這些基礎操作似乎很難實現。這種重新分配任務通常會導致較低的利用率,因為硬件模塊并未用于其主要目的;但是,由于Series4 NNA具有如此多的原始計算能力,即使利用率為1%,例如每秒 400 千兆次操作,在其上運行復雜操作的速度通常仍遠遠快于在“片外”執行復雜操作的速度,例如在CPU或者GPU上。以這種方式在設備上保持處理可節省寶貴的系統資源,包括 CPU/GPU 時間、功率和帶寬。復雜操作可以實施為多個硬件通道的較簡單操作計算圖。因此,Series4 NNA使用帶有張量分塊的新型片上存儲器系統來保持數據本地化(有關此主題的詳細白皮書,請參看鏈接) - 這可以被用來以最小的系統開銷在多個硬件通道上運行復雜的操作。
ROSC 概念背后的關鍵是,專用硬件模塊通常可以配置以執行其他任務。即使由于這種重新分配任務而導致使用率下降,硬件的巨大計算能力也彌補了這一不足。這使得Series4 架構師能夠吃上蛋糕——無需額外的硬件復雜性或面積,Series4可以在原始性能很重要的地方具備閃電般的速度,并且在必要時,具有足夠的靈活性來處理任意復雜的高級操作。
不要低估架構!
Series4有五種主要可配置的計算硬件模塊類型,可稱為:
卷積引擎
池化單元
標準化單元
元素操作單元
激活單元
圖1:單個硬件模塊通常可以配置為執行范圍非常廣泛的任務。這些可配置的硬件模塊每一個都比乍一看可能做的更多。例如,Series 4卷積引擎可以配置為執行圖 1所示的操作(以及其他許多操作),而無需依賴于其他計算硬件模塊。使用幾個這樣的模塊的組合,可以實現更廣泛的操作范圍。事實上,Series4可以使用高級的圖形降低編譯器技術來配置,以覆蓋現代神經網絡中遇到的幾乎所有操作。
標簽可能具有誤導性。僅僅因為一個硬件模塊被標記為“卷積引擎”或“池化模塊”并不意味著這是它所能做的全部——在正確的人手中,這些模塊可以做的遠遠超過他們在tin上所說的!下面給出了使用多個硬件模塊組合實施復雜操作的兩個示例。
Softmax
Softmax是神經網絡中的一種常見操作,通常用于需要離散概率的場合。在某些情況下,它也用于使張量進行歸一化,以便沿某個軸或多個軸的所有元素都在 [0,1]范圍內,且總和為1。在網絡中,Softmax通常只占計算的一小部分。例如,在大多數 ImageNet 分類網絡中,Softmax占計算的最大比重不到 0.01%。為了與ROSC 避免將芯片面積浪費為“暗硅”的策略保持一致,4系列 沒有專用的Softmax硬件;相反,它是在其他可用操作方面實現的。這使它成為我們如何應用上述原則的一個最佳例子。從本質上講,該策略是用一系列數學上相同但由硬件直接支持的操作構成的操作(“計算子圖”)來替換Softmax。Softmax是一個復雜的操作,需要五個階段,如圖2所示。其中四個交叉通道最大化削減、指數、跨通道求和削減和除法——在Series4上也沒有專門的硬件!但是,我們可以在Series4上以創造性的方法運行它們,如下所述。圖2:將Softmax分解為其組成部分。
一個1×1的卷積與權重張量和一個完全由1組成的過濾器可以用來實現跨通道的求和。
除法可以用一個張量與另一個張量的倒數相乘來實現。Series4的 LRN(本地響應歸一化)模塊可以配置為計算倒數。
交叉通道最大值可以通過將信道轉換置到空間軸上并執行一系列空間最大池化操作來實現。之后,它被轉置回通道軸上。
由于指數僅限于負值和零輸入值,激活 LUT 可以配置為指數衰減函數。
總之,這將產生一個替換子圖,其中包含大約10到15個操作(取決于輸入張量的大小),這些操作在幾個硬件過程中執行。ROSC的見解是,這個圖比在CPU或協處理器上執行更快、更簡單。避免了完全可編程和專用固定功能硬件的兩種極端情況,并且編譯過程中包含了最容易管理的復雜性。
此外,用于Softmax的操作替換可以重用為其他高級操作。一旦實現了一些這樣的高級操作,就很容易看到如何構建一個可重用操作替換庫,從而使將來的操作更容易降到Series4。這就是ROSC如何引領未來。
三維卷積
卷積引擎和Series4中的相關數據輸入和輸出針對一維和二維卷積進行了高度優化——這非常有意義,因為在大多數CNN(卷積神經網絡)中,這些引擎占據了絕大多數計算量。
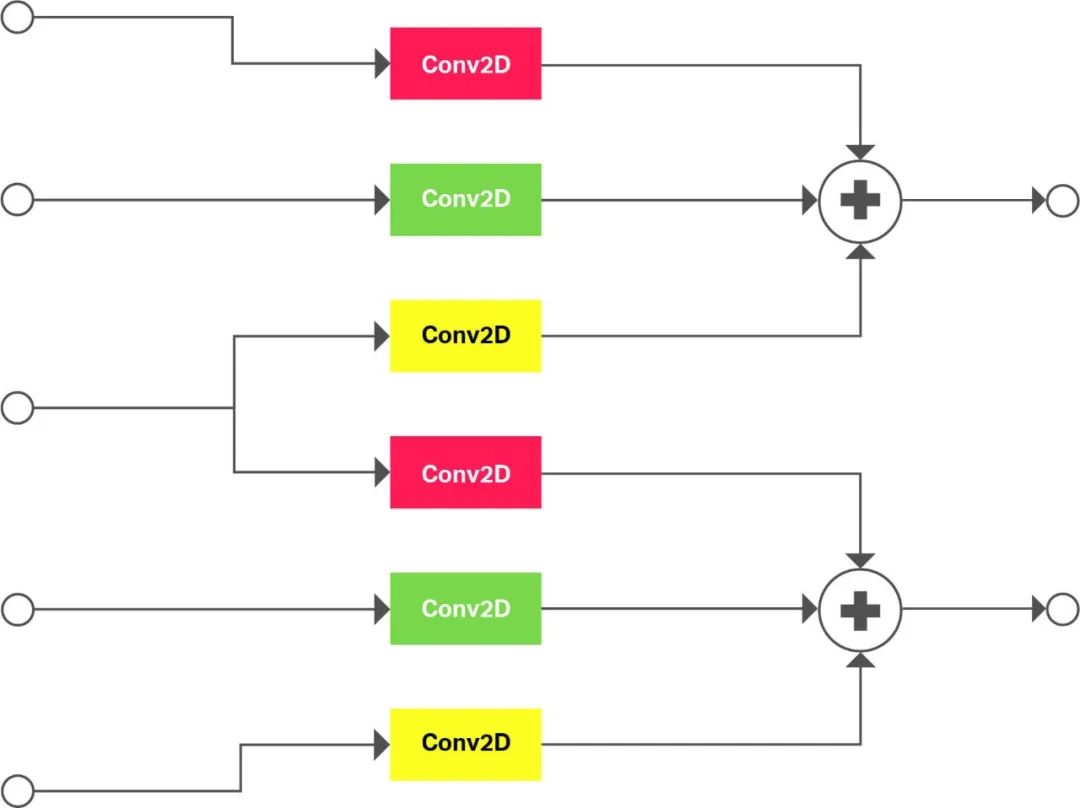
圖3:用二維卷積和元素求和實現的三維卷積。
但是,Series4硬件不支持三維和更高維度的卷積。三維卷積是復雜運算的一個具體例子,可使用圖形降低技術將其降低到Series4。在這種情況下,該子圖是根據二維卷積和元素加法構建的。無論編譯器在哪里“看到”原始置身事外中的三維卷積,在Series4上運行的機器代碼生成前,編譯器都會用該子圖形的等效版本替換它。
圖3顯示了一個三維卷積的例子,在深度軸上,內核大小為3,步長為2。卷積在深度軸上展開。相同顏色的卷積具有相同的權重。這種策略很容易擴展到高維和其他三維操作,如三維池和三維反褶積。這種三維卷積的方法是一個很好的例子,說明了如何將軟件設計成與硬件的優點相結合,從而擴展其適用性。
結論
高性能的神經網絡加速器很難設計,因為它們需要平衡兩個看似矛盾的目標:它們需要大量的并行性和計算密度,以便在幾分之一秒內完成一個典型神經網絡中的數百萬個操作;它們需要足夠的靈活性來處理這些問題現代神經網絡中有數百種不同類型的操作,還有那些尚未被發明的操作!通常必須在高效、更固定的函數方法和效率較低但更通用的方法之間進行折衷。Imagination公司的工程師們已經開發出一種令人興奮的創新方法,它提供了兩全其美的效果。Series4不包含任何近似ALU的可編程性所需的東西,而是有幾個非常有效的硬件模塊,設計用于執行特定的、通常發生的操作的計算。使用新的編譯技術可以實現完全的靈活性,通過這種技術,可以從一組簡化的基本操作中構建非常廣泛的操作。這種方法被稱為簡化運算集計算(簡稱ROSC)。通過以這種方式協調硬件和軟件設計,Series4擁有經得起未來考驗的、世界一流的性能和計算密度,同時又不犧牲靈活性。
原文標題:靈活、面向未來、高性能推理的簡化操作集計算
文章出處:【微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103440 -
深度學習
+關注
關注
73文章
5560瀏覽量
122748
原文標題:靈活、面向未來、高性能推理的簡化操作集計算
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
ESP32-P4—具備豐富IO連接、HMI和出色安全特性的高性能SoC
Vicor 高密度模塊電源為邊緣計算帶來成本效益
高密度、低功耗,關聯AI與云計算

FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預測......
15TS Series 1500W Transient Voltage Suppressor
AI高性能計算平臺是什么
邊緣計算的未來發展趨勢
嵌入式系統的未來趨勢有哪些?
樹莓派4b和什么性能計算機相當
高密度存儲系統集成必選,8盤位SATA/SAS熱插拔硬盤抽取盒







 工商網監
工商網監
評論