 解析在目標檢測中怎么解決小目標的問題?
解析在目標檢測中怎么解決小目標的問題?
導讀
本文介紹了一些小目標物體檢測的方法和思路。
在深度學習目標檢測中,特別是人臉檢測中,由于分辨率低、圖像模糊、信息少、噪聲多,小目標和小人臉的檢測一直是一個實用和常見的難點問題。然而,在過去幾年的發展中,也出現了一些提高小目標檢測性能的解決方案。本文將對這些方法進行分析、整理和總結。
圖像金字塔和多尺度滑動窗口檢測
一開始,在深學習方法成為流行之前,對于不同尺度的目標,通常是從原始圖像開始,使用不同的分辨率構建圖像金字塔,然后使用分類器對金字塔的每一層進行滑動窗口的目標檢測。
在著名的人臉檢測器MTCNN中,使用圖像金字塔法檢測不同分辨率的人臉目標。然而,這種方法通常是緩慢的,雖然構建圖像金字塔可以使用卷積核分離加速或簡單粗暴地縮放,但仍需要做多個特征提取,后來有人借其想法想出一個特征金字塔網絡FPN,在不同層融合特征,只需要一次正向計算,不需要縮放圖片。它也被應用于小目標檢測,這將在后面的文章中討論。
簡單,粗暴和可靠的數據增強
通過增加訓練集中小目標樣本的種類和數量,也可以提高小目標檢測的性能。有兩種簡單而粗糙的方法:
針對COCO數據集中含有小目標的圖片數量較少的問題,使用過采樣策略:
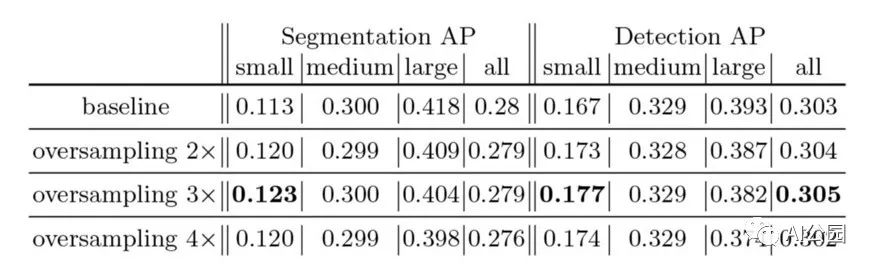
不同采樣比的實驗。我們觀察到,不管檢測小目標的比率是多少,過采樣都有幫助。這個比例使我們能夠在大小物體之間做出權衡。
針對同一張圖片中小目標數量少的問題,使用分割mask切出小目標圖像,然后使用復制和粘貼方法(當然,再加一些旋轉和縮放)。
通過復制粘貼小目標來實現人工增強的例子。正如我們在這些例子中所觀察到的,粘貼在同一幅圖像上可以獲得正確的小目標的周圍環境。
在Anchor策略方法中,如果同一幅圖中有更多的小目標,則會匹配更多的正樣本。
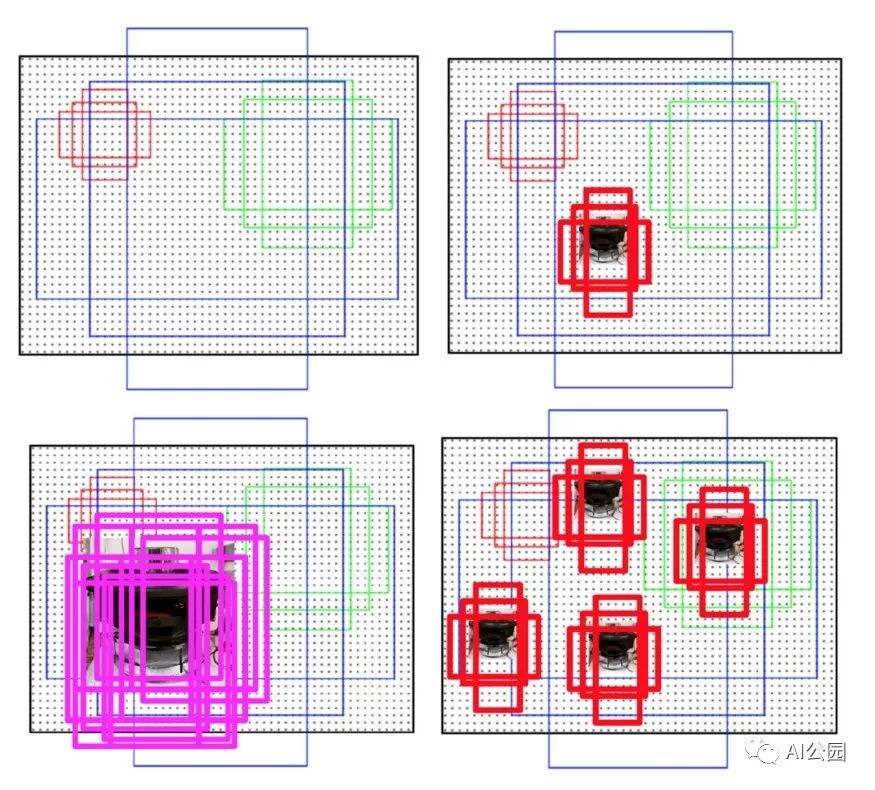
與ground truth物體相匹配的不同尺度anchor示意圖,小的目標匹配到更少的anchor。為了克服這一問題,我們提出通過復制粘貼小目標來人工增強圖像,使訓練過程中有更多的anchor與小目標匹配。
特征融合FPN
不同階段的特征圖對應不同的感受野,其所表達的信息抽象程度也不同。
淺層特征圖感受野小,更適合檢測小目標,深層特征圖較大,更適合檢測大目標。因此,有人提出將不同階段的特征映射整合在一起來提高目標檢測性能,稱之為特征金字塔網絡FPN。
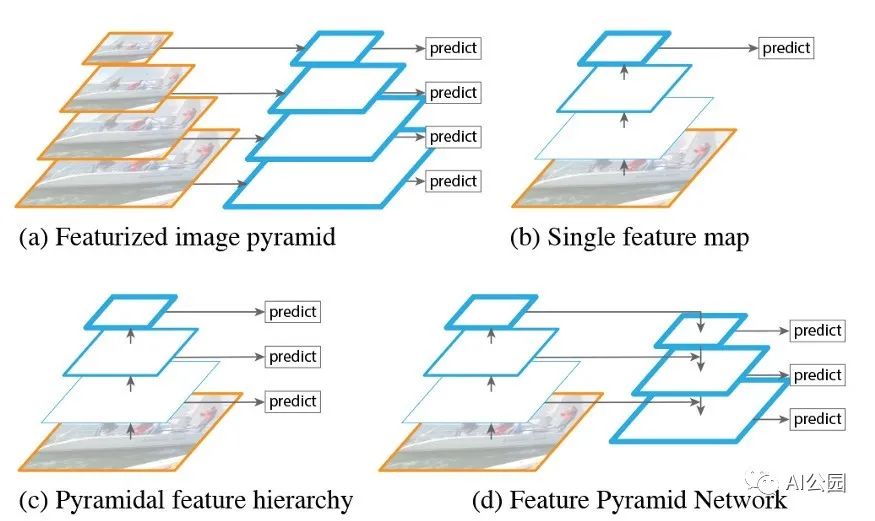
(a)利用圖像金字塔建立特征金字塔。特征的計算是在每個圖像的尺度上獨立進行的,這是很緩慢的。(b)最近的檢測系統選擇只使用單一尺度的特征以更快地檢測。另一種選擇是重用由ConvNet計算出的金字塔特征層次結構,就好像它是一個特征圖金字塔。(d)我們提出的特征金字塔網絡(FPN)與(b)和一樣快,但更準確。在這個圖中,特征圖用藍色輪廓線表示,較粗的輪廓線表示語義上較強的特征。
由于可以通過融合不同分辨率的特征圖來提高特征的豐富度和信息含量來檢測不同大小的目標,自然會有人進一步猜測,如果只檢測高分辨率的特征圖(淺層特征)來檢測小人臉,使用中分辨率特征圖(中間特征)來檢測大的臉。
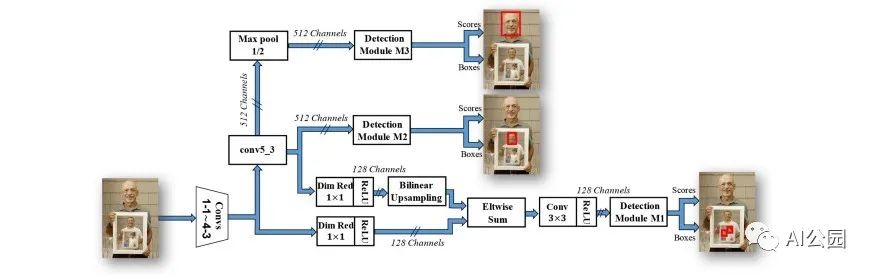
SSH的網絡結構
合適的訓練方法SNIP, SNIPER, SAN
在機器學習中有一點很重要,模型預訓練的分布應該盡可能接近測試輸入的分布。因此,在大分辨率(如常見的224 x 224)下訓練的模型不適合檢測小分辨率的圖像,然后放大并輸入到模型中。
如果輸入的是小分辨率的圖像,則在小分辨率的圖像上訓練模型,如果沒有,則應該先用大分辨率的圖片訓練模型,然后再用小分辨率的圖片進行微調,最壞的情況是直接使用大分辨率的圖像來預測小分辨率的圖像(通過上采樣放大)。
因此,在實際應用中,對輸入圖像進行放大并進行高速率的圖像預訓練,然后對小圖像進行微調比針對小目標訓練分類器效果更好。
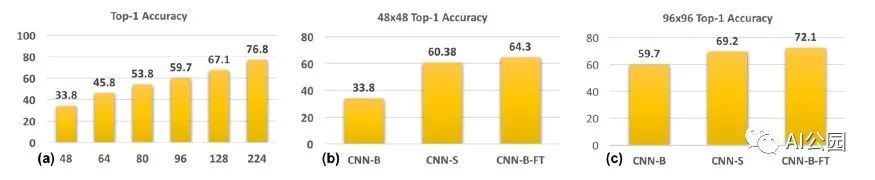
所有的圖都報告了ImageNet分類數據集驗證集的準確性。我們對48、64、80等分辨率的圖像進行上采樣,在圖(a)中繪制出預訓練的ResNet-101分類器的Top-1精度。圖(b、c)分別為原始圖像分辨率為48,96像素時不同cnn的結果。
更密集的Anchor采樣和匹配策略S3FD, FaceBoxes
如前面的數據增強部分所述,將一個小目標復制到圖片中的多個位置,可以增加小目標匹配的anchor數量,增加小目標的訓練權重,減少網絡對大目標的偏置。同樣,在逆向思維中,如果數據集已經確定,我們也可以增加負責小目標的anchor的設置策略,使訓練過程中對小目標的學習更加充分。
例如,在FaceBoxes中,其中一個貢獻是anchor策略。
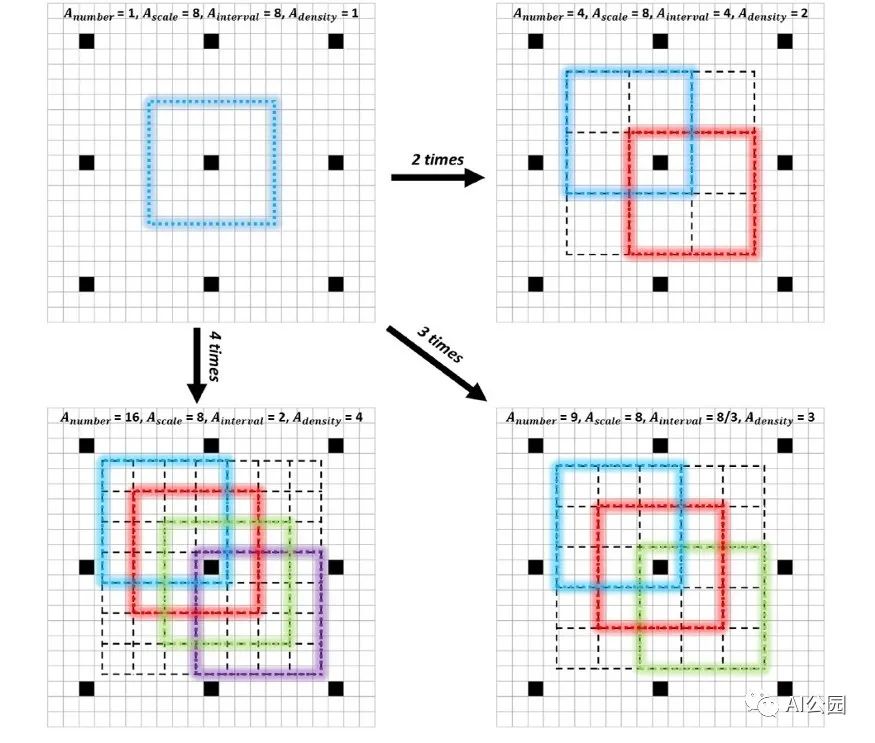
Anchor變的密集例子。為了清晰起見,我們只對一個感受野中心(即中央黑色網格)密集化錨點,并只給對角錨點上色。
Anchor密集化策略,使不同類型的anchor在圖像上具有相同的密度,顯著提高小人臉的召回率。
總結
本文較詳細地總結了一般目標檢測和特殊人臉檢測中常見的小目標檢測解決方案。
英文原文:https://medium.datadriveninvestor.com/how-to-deal-with-small-objects-in-object-detection-44d28d136cbc
來源:AI公園
-
噪聲
+關注
關注
13文章
1137瀏覽量
47891 -
分辨率
+關注
關注
2文章
1077瀏覽量
42430 -
人臉檢測
+關注
關注
0文章
86瀏覽量
16769
原文標題:在目標檢測中如何解決小目標的問題?
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于LockAI視覺識別模塊:C++目標檢測
基于LockAI視覺識別模塊:C++目標檢測

labview調用yolo目標檢測、分割、分類、obb
在樹莓派上部署YOLOv5進行動物目標檢測的完整流程
在目標檢測中大物體的重要性

智能化升級:機載無人機攝像頭如何自動識別目標?

圖像分割與目標檢測的區別是什么
慧視小目標識別算法 解決目標檢測中的老大難問題






 工商網監
工商網監
評論