 如何在Python中實現一個簡單的貝葉斯模型?
如何在Python中實現一個簡單的貝葉斯模型?
即使對于一個非數據科學家來說,貝葉斯統計這個術語也已經很流行了。你可能在大學期間把它作為必修課之一來學習,而沒有意識到貝葉斯統計有多么重要。事實上,貝葉斯統計不僅僅是一種特定的方法,甚至是一類方法;它是一種完全不同的統計分析范式。
為什么貝葉斯統計如此重要
貝葉斯統計為你提供了在新數據的證據中更新你的評估工具,這是一個在許多現實世界場景中常見的概念,如跟蹤大流行病,預測經濟趨勢,或預測氣候變化。貝葉斯統計是許多較著名的統計模型的支柱,如高斯過程。
重要的是,學習貝葉斯統計原理可以成為你作為一個數據科學家的寶貴財富,因為它給你一個全新的視角來解決具有真實世界動態數據來源的新問題。
這篇文章將介紹貝葉斯統計的基本理論,以及如何在Python中實現一個簡單的貝葉斯模型。
目錄表:
01 什么是貝葉斯統計?
02 貝葉斯編程簡介
03 貝葉斯的工作流程
04 建立一個簡單的貝葉斯模型
閑話少說,進入主題!讓我們開始介紹貝葉斯統計編程。
1 什么是貝葉斯統計?
你可能會在互聯網上的某個地方或在你的課堂上看到這個方程式。
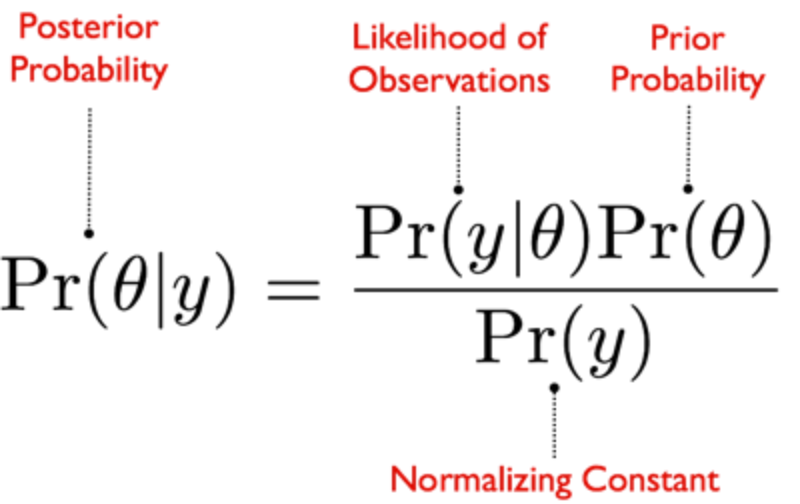
如果你沒有,也不要擔心,因為我將向你簡要介紹貝葉斯的基本原則以及該公式的工作原理。
關鍵術語
上述貝葉斯公式的組成部分一般被稱為概率聲明。例如,在下面的后驗概率聲明中,該術語的意思是 "給定觀測值y,theta(θ)的概率是多少 "。
Theta(θ)是這里的未知數,被稱為我們所關心的參數。參數的不確定性遵循一個特定的概率分布,可以使用與數據相關的模型組合來估計有關參數。
上述貝葉斯統計表述也被稱為反概率,因為它是從觀察到參數開始的。換言之,貝葉斯統計試圖從數據(效果)中推斷出假設(原因),而不是用數據來接受/拒絕工作假設。
貝葉斯公式
那么,貝葉斯公式告訴我們什么呢?
后驗概率是我們想知道的主要部分,因為Theta(θ)是我們感興趣的參數。
觀察的可能性僅僅意味著,在Theta(θ)的特定值下,數據y在現實世界中出現的可能性有多大。
先驗概率是我們對Theta (θ)應該是什么樣子的最佳猜測(例如,也許它遵循正態或高斯分布)。
歸一化常數只是一個系數常數,使整個方程積分為1(因為概率不能低于0和高于1)。
現在我們已經涵蓋了貝葉斯統計的基本理論,讓我們開始為即將到來的貝葉斯編程教程進行設置。
2 貝葉斯編程介紹
安裝
首先,安裝PyMC3作為我們執行貝葉斯統計編程的首選庫。
推薦使用conda
conda install -c conda-forge pymc3
也可使用pip
pip install pymc3
獲取數據
我們將使用描述美國家庭中氡氣(Radon)濃度的氡氣數據集。氡氣已被證明是非吸煙者患肺癌的最高預測因素之一,其濃度通常與房屋的整體條件(例如,是否有地下室,等等)有關。
首先,在你的筆記本或終端運行以下命令:
!wget "https://raw.githubusercontent.com/fonnesbeck/mcmc_pydata_london_2019/master/data/radon.csv"
確保你的數據位于你的筆記本的同一目錄內。
數據探索
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import numpy as npradon = pd.read_csv('./radon.csv', index_col=0)radon.head()
我們注意到,有29列描述了一個家庭中氡(Radon)的濃度。
數據集匯總
讓我們畫一張圖,顯示 "ANOKA "的氡的對數濃度分布,用一條垂直線來說明對數濃度為1.1。
anoka_radon = radon.query('county=="ANOKA"').log_radon sns.distplot(anoka_radon, bins=16)plt.axvline(1.1)
密度分布
ANOKA地區氡氣對數濃度超過1.1的家庭比例似乎相當大,這是一個令人擔憂的趨勢......
3 貝葉斯工作流
現在我們有了數據,讓我們進行貝葉斯推斷。一般來說,這個過程可以分解為以下三個步驟。
第1步:指定一個概率模型
這是作為建模者要多做選擇的地方。你將需要為一切指定最可能的概率分布函數(例如,正態或高斯、考奇、二項式、t分布、F分布,等等)。
我所說的一切,是指包括未知參數、數據、協變量、缺失數據、預測在內的一切。所以,用不同的分布函數做實驗,看看在現實世界的場景中如何起效。
第2步:計算后驗分布
現在你將計算這個概率項,給定貝葉斯方程右邊的所有項。
第3步:檢查你的模型
與其他ML模型一樣,評估你的模型是關鍵。回到第一步,檢查你的假設是否有意義。如果沒有,改變概率分布函數,并反復重申。
4 建立一個簡單的貝葉斯模型
現在,我將向你介紹一個簡單的編程練習來建立你的第一個貝葉斯模型。
第1步:定義一個貝葉斯模型
首先,讓我們定義我們的氡氣——貝葉斯模型,有兩個參數,平均值(μ-"miu")和其偏差(σ-"sigma")。這些參數(μ和σ)還需要通過選擇對應的分布函數來建立模型(記住:我們必須為所有參數定義概率分布)。
對于這些,我們選擇的函數是正態/高斯分布(μ=0,σ=10)和均勻分布。你可以在模型的驗證檢查中重新校準這些值,如上面步驟3所述。
from pymc3 import Model, Normal, Uniformwith Model() as radon_model: μ = Normal(’μ’, mu=0, sd=10) σ = Uniform(’σ’, 0, 10)
下一步是用另一個概率分布來編譯radon_model本身。
**with** radon_model: dist = Normal('dist', mu=μ, sd=σ, observed=anoka_radon)
第2步:用數據進行模型擬合
現在,我們需要用數據來擬合這個模型(即訓練)。
from pymc3 import sample **with** radon_model: samples = sample(1000, tune=1000, cores=2, random_seed=12)
讓我們畫出我們的參數μ在訓練后的分布情況,同時畫出95%的置信線。
from arviz import plot_posterior plot_posterior(samples, var_names=['μ'], ref_val=1.1)
好吧,看來1.1的對數濃度可能不是那么糟糕,因為它是在分布的尾端(只有2.2%的樣品的對數濃度大于1.1)。
責任編輯:lq6
-
貝葉斯
+關注
關注
0文章
77瀏覽量
12735 -
python
+關注
關注
56文章
4825瀏覽量
86370
原文標題:為什么貝葉斯統計如此重要?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

零基礎入門:如何在樹莓派上編寫和運行Python程序?

標貝數據標注服務:奠定大模型訓練的數據基石







 工商網監
工商網監
評論