 手機行業的跑分軟件是噱頭還是實力
手機行業的跑分軟件是噱頭還是實力
一、背景:性能之戰
“不服跑個分”已經淪為手機行業的調侃用語,但是實話實說,在操作系統領域“跑分”確實是最重要的評價方式之一。比如 Linux 內核社區常常以跑分軟件得分,來評價一個優化補丁的價值。甚至還有 phoronix 這樣專注于 Linux 跑分的媒體。而且今天我還想說一點,讓軟件跑分高,這是實力的體現,是建立在對內核的深刻理解基礎上的。本文的故事就源于一次日常的性能優化分析。我們在評估自動化性能調優軟件 tuned 的時候,發現它在服務器場景,對 Linux 內核調度器相關的參數做了一些微小的修改,但是這些修改卻很大程度改善了 hackbench 這款跑分軟件的性能。是不是很有意思?讓我們一起來一探究竟。
本文將從幾個方面展開,并重點介紹黑體字部分:
相關知識簡介
hackbench 工作模式簡介
hackbench 性能受損之源
雙參數優化
思考與拓展
二、相關知識簡介
2.1 CFS調度器
Linux 中大部分(可以粗略認為是實時任務之外的所有)線程/進程,都由一個叫 CFS(完全公平調度器)的調度器進行調度,它是 Linux 最核心的組件之一。(在Linux中,線程和進程只有細微差別,下文統一用進程表述)
CFS 的核心是紅黑樹,用于管理系統中進程的運行時間,作為選擇下一個將要運行的進程的依據。此外,它還支持優先級、組調度(基于我們熟知的 cgroup 實現)、限流等功能,滿足各種高級需求。CFS 的詳細介紹。
2.2 hackbench
hackbench 是一個針對 Linux 內核調度器的壓力測試工具,它的主要工作是創建指定數量的調度實體對(線程/進程),并讓它們通過 sockets/pipe 進行數據傳輸,最后統計整個運行過程的時間開銷。
2.3 CFS 調度器參數
本文重點關注以下兩個參數,這兩個參數也是影響 hackbench 跑分性能的重要因素。系統管理員可以使用 sysctl 命令來進行設置。
最小粒度時間:kernel.sched_min_granularity_ns
通過修改 kernel.sched_min_granularity_ns,可以影響 CFS 調度周期(sched period)的時間長短。例如:設置kernel.sched_min_granularity_ns = m,當系統中存在大量可運行進程時,m 越大,CFS 調度周期就越長。
如圖 1 所示,每個進程都能夠在 CPU 上運行且時間各有長短,sched_min_granularity_ns 保證了每個進程的最小運行時間(優先級相同的情況下),sched_min_granularity_ns 越大每個進程單次可運行的時間就越長。
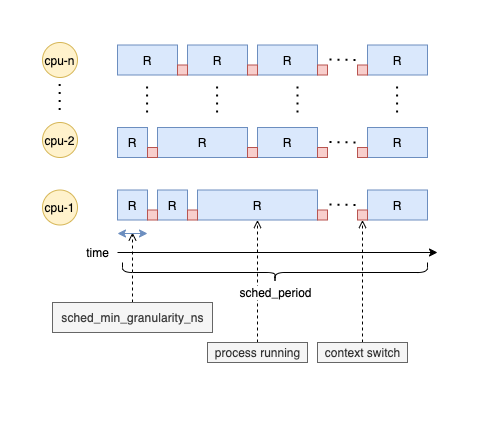
圖 1:sched_min_granularity_ns 示意圖
喚醒搶占粒度:kernel.sched_wakeup_granularity_ns
kernel.sched_wakeup_granularity_ns 保證了重新喚醒的進程不會頻繁搶占正在運行的進程,kernel.sched_wakeup_granularity_ns 越大,喚醒進程進行搶占的頻率就越小。
如圖 2 所示,有 process-{1,2,3} 三個進程被喚醒,因為 process-3 的運行時間大于 curr(正在 CPU 上運行的進程)無法搶占運行,而 process-2 運行時間小于 curr 但其差值小于 sched_wakeup_granularity_ns 也無法搶占運行,只有 process-1 能夠搶占 curr 運行,因此 sched_wakeup_granularity_ns 越小,進程被喚醒后的響應時間就越快(等待運行時間越短)。
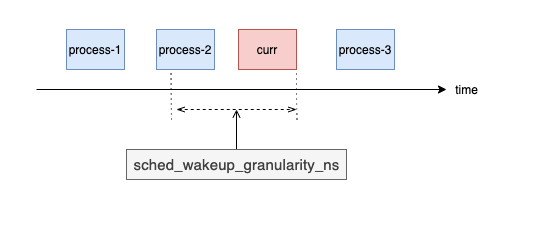
圖 2:sched_wakeup_granularity_ns 示意圖
三、hackbench 工作模式簡介
hackbench 工作模式分為 process mode 和 thread mode,主要區別就是以創建 process 還是 thread 為基礎來進行測試,下面以 thread 來進行介紹。
hackbench 會創建若干線程(偶數),均分為兩類線程:sender 和 receiver
并將其劃分為 n 個 group,每個 group 包含 m 對 sender 和 receiver。
每個 sender 的任務就是給其所在 group 的所有 receiver 輪流發送 loop 次大小為 datasize 的數據包
receiver 則只負責接收數據包即可。
同一個 group 中的sender 和 receiver 有兩種方式進行通信:pipe 和 local socket(一次測試中只能都是 pipe 或者 socket),不同 group 之間的線程沒有交互關系。
通過上面 hackbench 模型分析,可以得知同一個 group 中的 thread/process 主要是 I/O 密集型,不同 group 之間的 thread/process 主要是 CPU 密集型。
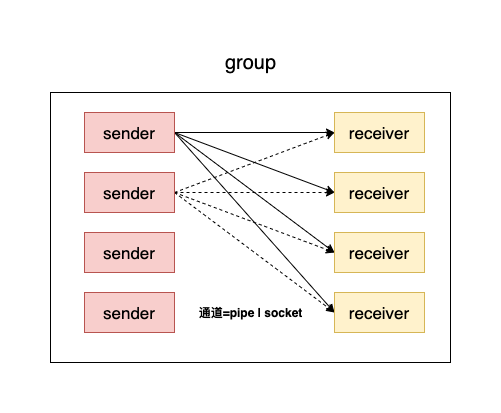
圖 3: hackbench 工作模式主動上下文切換:
對于 receiver,當 buffer 中沒有數據時,receiver 會被阻塞并主動讓出 CPU 進入睡眠。
對于 sender,如果 buffer 中沒有足夠空間寫入數據時, sender 也會被阻塞且主動讓出 CPU。
因此,系統中"主動上下文切換"是很多的,但同時也存在“被動上下文切換”。后者會受到接下來我們將要介紹的參數影響。
四、hackbench性能影響之源
在hackbench-socket 測試中,tuned修改了 CFS 的 sched_min_granularity_ns 和 sched_wakeup_granularity_ns 兩個參數,導致了性能的顯著區別。具體如下:
| 開關/參數和性能 | sched_min_granularity_ns | sched_wakeup_granularity_ns | 性能 |
| 關 tuned | 2.25ms | 3ms | 差 |
| 開 tuned | 10ms | 15ms | 好 |
接下來我們調整這兩個調度參數來進行進一步的深入分析。
五、雙參數優化
注:為了簡介表達下面會以 m 表示 kernel.sched_min_granularity_ns,w 表示 kernel.sched_wakeup_granularity_ns
為了探索雙參數對于調度器的影響,我們選擇每次固定一個參數,研究另一個參數變化對于性能的影響,并使用系統知識來解釋這種現象背后的原理。
5.1 固定sched_wakeup_granularity_ns
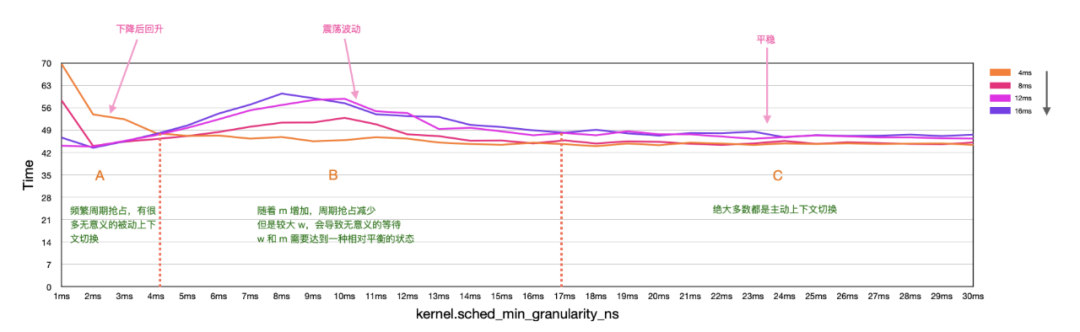
圖 4: 固定 w,調整m
在上圖中我們固定了參數 w 并根據參數 m 變化趨勢其劃分為三個部分:區域A(1ms~4ms),區域B(4ms~17ms),區域C(17ms~30ms)。在區域A中四條曲線均呈現一個極速下降的趨勢,而在區域B中四條曲線都處于一種震蕩狀態,波動較大,最后在區域C中四條曲線都趨于穩定。
在第二節相關知識中可以知道 m 影響著進程的運行時間,同時也意味著它影響著進程的“被動上下文切換”。
對于區域A而言,搶占過于頻繁,而大部分搶占都是無意義的,因為對端無數據可寫/無緩沖區可用,導致大量冗余的“主動上下文切換“。此時較大的 w 能讓 sender/receiver 有更多的時間來寫入數據/消耗數據來減少對端進程無意義的“主動上下文切換“。
對于區域B而言,隨著 m 的增加漸漸滿足 sender/receiver 執行任務的時間需求能夠在緩沖區寫入/讀出足夠的數據,因此需要較小的 w 來增加喚醒進程的搶占幾率,讓對端進程能夠更快的響應處理數據,減少下一輪調度時的“主動上下文切換”。
對于區域C而言,m已經足夠大,已經幾乎不會有“被動上下文切換”發生,進程會在執行完任務之后進行“主動上下文切換”等待對端進程進行處理,此時 m 對性能的影響就很小了。
5.2 固定sched_min_granularity_ns
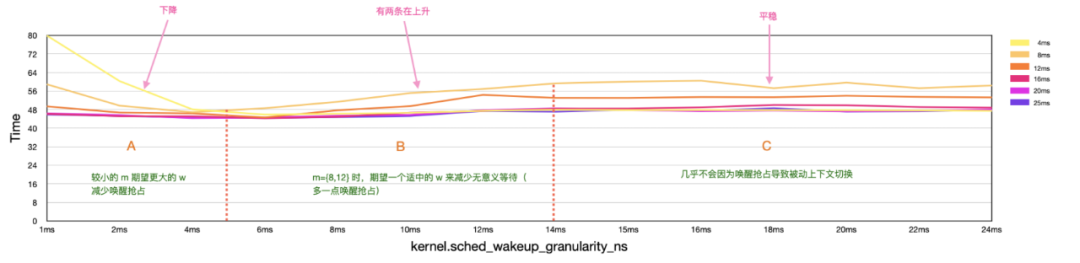
圖 5: 固定 m,調整w
在上圖中我們固定了參數 m,同樣劃分了三個區域:
在區域A中,同樣存在圖 4 中的現象,較大 m 受 w 的影響較小,而較小的 m 隨著 w 的增大性能會越來越好。
在區域B中,中等大小的 m(8ms/12ms)進程還是存在較多“被動上下文切換”,并且其中的進程已經處理了相當一部分數據期望對端進程能夠盡快的響應處理,因此較大 w 會嚴重影響中等大小 m 的性能。
在區域C中圖5和圖4表現一致都是趨于穩定,因為 w 過大時幾乎不會發生喚醒搶占,因此這時單純 w 值的變化對性能的影響并不大,但是過大的 w 對于中等大小的 m 則會造成性能問題(原因同上條)。
5.4 最優雙參數(對于 hackbench )
從上面兩節的分析可知對于 hackbench 這樣帶有“主動上下文切換”的場景可以選擇較大的 m(例如:15~20ms)。
在pipe/socket 雙向通信的場景中,對端的響應時間會對影響進程的下一次處理,為了讓對端進程能夠及時響應可以選擇一個中等大小的 w(例如:6~8ms)來獲取較高的性能。
六、思考與擴展
在桌面場景中,應用更偏向于交互型,應用的服務質量也更多的體現在應用對于用戶操作的響應時間,因此可以選擇較小的 sched_wakeup_granularity_ns 來提高應用的交互性。
在服務器場景中,應用更偏向于計算處理,應用需要更多的運行時間來進行密集計算,因此可以選擇較大的 sched_min_granularity_ns,但是為了防止單個進程獨占 CPU 過久同時也為了能夠及時處理客戶端請求響應,應該選擇一個中等大小的 sched_wakeup_granularity_ns。
在 Linux 原生內核中 m 和 w 的默認參數被設置為適配桌面場景,Anolis OS的用戶,需要根據自己部署的應用的場景,屬于桌面型還是服務器型,來選擇內核參數,或者使用tuned的推薦配置。而 hackbench 作為一個介于桌面和服務器間的應用,也可以作為配置的參考。
責任編輯:haq
-
Linux
+關注
關注
87文章
11357瀏覽量
210859 -
調度器
+關注
關注
0文章
98瀏覽量
5308
原文標題:“不服跑個分?” 是噱頭還是實力?
文章出處:【微信號:gh_6fde77c41971,微信公眾號:FPGA干貨】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
vivo V50 5G手機現身Geekbench跑分庫
AI跑分超8000,天璣9400憑實力碾壓一眾旗艦芯片
康尼新能源亮相2024零跑智能汽車技術論壇暨前瞻技術展
AMC1311是真差分輸出,還是偽差分輸出?可否直接給MSP430的ADC采集?
飛貓榮膺世界物聯網500強:引領行業創新,展現中國實力

跑在ram里快還是跑在flash里快?
索尼Xperia 10 VI Geekbench跑分曝光,搭載高通驍龍6 Gen 1處理器
vivo X100S手機曝光:搭載天璣9300+處理器,16GB內存,綜合跑分表現出色
三星Galaxy Z Flip 6搭載驍龍8G跑分曝光

三星手機AI功能將收費?AI手機是噱頭還是未來?
米爾-全志T527開發板評測試用【米爾-全志T527開發板評測試用】+B-跑分
一加創始人內部講話曝光 劉作虎稱AI手機不是噱頭
智能硬件 | AI手機是營銷噱頭嗎?對哪些行業利好?





 工商網監
工商網監
評論