") DeepMind如何用神經(jīng)網(wǎng)絡(luò)自動構(gòu)建啟發(fā)式算法
DeepMind如何用神經(jīng)網(wǎng)絡(luò)自動構(gòu)建啟發(fā)式算法
混合整數(shù)規(guī)劃(MIP)是一類 NP 困難問題,來自 DeepMind、谷歌的一項研究表明,用神經(jīng)網(wǎng)絡(luò)與機(jī)器學(xué)習(xí)方法可以解決混合整數(shù)規(guī)劃問題。
混合整數(shù)規(guī)劃(Mixed Integer Program, MIP)是一類 NP 困難問題,旨在最小化受限于線性約束的線性目標(biāo),其中部分或所有變量被約束為整數(shù)值。混合整數(shù)規(guī)劃的形式如下:
MIP 已經(jīng)在產(chǎn)能規(guī)劃、資源分配和裝箱等一系列問題中得到廣泛應(yīng)用。人們在研究和工程上的大量努力也研發(fā)出了 SCIP、CPLEX、Gurobi 和 Xpress 等實用的求解器。這些求解器使用復(fù)雜的啟發(fā)式算法來指導(dǎo)求解 MIP 的搜索過程,并且給定應(yīng)用上求解器的性能主要依賴于啟發(fā)式算法適配應(yīng)用的程度。
在本文中,來自 DeepMind、谷歌的研究者展示了機(jī)器學(xué)習(xí)可以用于從 MIP 實例數(shù)據(jù)集自動構(gòu)建有效的啟發(fā)式算法。
在實踐中經(jīng)常會出現(xiàn)這樣的用例,即應(yīng)用程序需要用不同的問題參數(shù)解決同一高級語義問題的大量實例。
文中此類「同質(zhì)」數(shù)據(jù)集的示例包括:(1)優(yōu)化電網(wǎng)中發(fā)電廠的選擇以滿足需求,其中電網(wǎng)拓?fù)浔3植蛔儯枨蟆⒖稍偕茉窗l(fā)電等則因情況而異(2)解決了谷歌在生產(chǎn)系統(tǒng)中的一個包裝問題,在這個系統(tǒng)中,要包裝的「items」和「bins」的語義基本保持不變,但它們的尺寸在不同的實例之間有所波動。
然而,現(xiàn)有的 MIP 求解器無法自動構(gòu)造啟發(fā)式來利用這種結(jié)構(gòu)。在具有挑戰(zhàn)性的應(yīng)用程序中,用戶可能依賴專家設(shè)計的啟發(fā)式,或者以放棄潛在的大型性能改進(jìn)為代價。而機(jī)器學(xué)習(xí)提供了在不需要特定于應(yīng)用程序?qū)I(yè)知識的情況下進(jìn)行大規(guī)模改進(jìn)的可能性。
論文地址:https://arxiv.org/pdf/2012.13349.pdf
該研究證明,機(jī)器學(xué)習(xí)可以構(gòu)建針對給定數(shù)據(jù)集的啟發(fā)式算法,其性能顯著優(yōu)于 MIP 求解器中使用的經(jīng)典算法,特別是具有 SOTA 性能的非商業(yè)求解器 SCIP 7.0.1。
該研究將機(jī)器學(xué)習(xí)應(yīng)用于 MIP 求解器的兩個關(guān)鍵子任務(wù):(1)輸出對滿足約束的所有變量的賦值(如果存在此類賦值)(2)證明變量賦值與最優(yōu)賦值之間的目標(biāo)值差距邊界。這兩個任務(wù)決定了該方法的主要組件,即:Neural Diving、 Neural Branching。
該研究在不同的數(shù)據(jù)集上進(jìn)行了評估,這些數(shù)據(jù)集包含來自實際應(yīng)用的大規(guī)模 MIP,包括來自谷歌生產(chǎn)系統(tǒng)和 MIPLIB 的兩組數(shù)據(jù)。來自所有數(shù)據(jù)集的大多數(shù) MIP 組合集在解算后都有 10^3-10^6 個變量和約束,這明顯大于早期的工作。
一旦在給定的數(shù)據(jù)集上訓(xùn)練 Neural Diving 和 Neural Branching 模型,它們就被集成到 SCIP 中,以形成專門針對該數(shù)據(jù)集的「神經(jīng)求解器」。基線是 SCIP,其重點參數(shù)通過網(wǎng)格搜索在每個數(shù)據(jù)集上進(jìn)行調(diào)整,稱之為 Tuned SCIP。
將神經(jīng)求解器和 Tuned SCIP 與原始對偶間隙(primal-dual gap)在一組實例上的平均值進(jìn)行比較,圖 2 所示,神經(jīng)求解器在相同的運(yùn)行時間內(nèi)提供了更好的間隙,或者在更短的時間內(nèi)提供了相同的間隙,在五個數(shù)據(jù)集中進(jìn)行評估,有四個數(shù)據(jù)集的 MIP 最大,而第五個數(shù)據(jù)集的性能與 Tuned SCIP 性能相匹配。據(jù)了解,這是第一次使用機(jī)器學(xué)習(xí)在大規(guī)模真實應(yīng)用數(shù)據(jù)集和 MIPLIB 上得到如此大的改進(jìn)。
MIP 表示與神經(jīng)網(wǎng)絡(luò)架構(gòu)
該研究描述了 MIP 如何表示為神經(jīng)網(wǎng)絡(luò)的輸入,并用來學(xué)習(xí) Neural Diving、Neural Branching 模型的架構(gòu)。該研究使用的深度學(xué)習(xí)架構(gòu)為一種圖神經(jīng)網(wǎng)絡(luò),特別是圖卷積網(wǎng)絡(luò) (GCN)。
將 MIP 表示為神經(jīng)網(wǎng)絡(luò)的輸入
該研究使用 MIP 的二部圖表示,方程(1)可用于定義二部圖,其中圖中的一組 n 個節(jié)點對應(yīng)于被優(yōu)化的 n 個變量,另一組 m 個節(jié)點對應(yīng)于 m 個約束。
神經(jīng)網(wǎng)絡(luò)架構(gòu)
下面介紹一下 Neural Diving 、 Neural Branching 所使用的網(wǎng)絡(luò)架構(gòu)中共同的方面。
給定一個 MIP 的二部圖表示,該研究使用 GCN 來學(xué)習(xí) Neural Diving 、Neural Branching 模型。設(shè) GCN 的輸入為圖,其中 V 為節(jié)點集合、ε為邊集合、A 為圖鄰接矩陣。對于 MIP 二部圖,V 是 n 個變量節(jié)點和 m 個約束節(jié)點的并集,大小 N := |V| = n + m。一個單層 GCN 用來學(xué)習(xí)計算輸入圖中每個節(jié)點的 H 維連續(xù)向量表示,稱為節(jié)點嵌入。
在 MIP 和 GCN 體系架構(gòu)中二部圖表示的兩個關(guān)鍵性質(zhì)是:(1)網(wǎng)絡(luò)輸出對變量和約束的排列是不變的(2)可以使用同一組參數(shù)應(yīng)用于不同大小的 MIP。
這兩個性質(zhì)很重要,因為變量和約束可能沒有任何規(guī)范順序,而且同一應(yīng)用程序中的不同實例可能具有不同數(shù)量的變量和約束。
架構(gòu)改進(jìn)
該研究對上述體系架構(gòu)進(jìn)行了改進(jìn),這些改進(jìn)提高了網(wǎng)絡(luò)的性能,主要體現(xiàn)在以下方面:
該研究修改了 MIP 二部圖的鄰接矩陣 A ,以包含來自 MIP 約束矩陣 A 的系數(shù),而不在是表示邊緣存在的二進(jìn)制值;
該研究通過連接來自第 l 層的節(jié)點嵌入來擴(kuò)展第 l + 1 層的節(jié)點嵌入;該研究在每一層的輸出處應(yīng)用 layer norm,使得 Z^ (l+1) =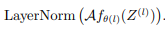
此外,該研究還探索了可以用來替代的架構(gòu),這些架構(gòu)對節(jié)點和邊使用嵌入,并使用單獨的 MLP 來計算。當(dāng)在每一層中使用具有高維邊嵌入的此類網(wǎng)絡(luò)時,它們的內(nèi)存使用量可能會比 GCN 高得多,因為 GCN 只需要鄰接矩陣,可能不適合 GPU 內(nèi)存,除非以精度為代價減少層數(shù)。GCN 更適合擴(kuò)展到大規(guī)模 MIP。
數(shù)據(jù)集
表 1 中總結(jié)了數(shù)據(jù)集的詳細(xì)信息,除 MIPLIB 之外的所有數(shù)據(jù)集都是特定于應(yīng)用程序的,即它們只包含來自單個應(yīng)用程序的實例。
除了 MIPLIB 之外的所有數(shù)據(jù)集,該研究將實例隨機(jī)拆分為 70%、15% 和 15% 的不相交子集來定義訓(xùn)練集、驗證集和測試集。對于 MIPLIB,該研究使用來自 MIPLIB 2017 基準(zhǔn)集的實例作為測試集。
在刪除與 MIPLIB 2017 基準(zhǔn)集的重疊實例后,分別使用 MIPLIB 2017 Collection Set 和 MIPLIB 2010 set 作為訓(xùn)練集和驗證集。對每個數(shù)據(jù)集來說,訓(xùn)練集用于學(xué)習(xí)該數(shù)據(jù)集的模型,驗證集用于調(diào)整學(xué)習(xí)超參數(shù)和 SCIP 的元參數(shù),測試集用于報告評估結(jié)果。
評估
首先該研究單獨評估了 Neural Diving、 Neural Branching,后續(xù)又進(jìn)行了聯(lián)合評估。不管在哪種情況下,該研究都評估了與訓(xùn)練集分離的 MIP 測試集,以衡量模型對未見實例的泛化能力。并使用 gap plot 和 survival plot 呈現(xiàn)結(jié)果。
校準(zhǔn)時間(Calibrated time):所有數(shù)據(jù)集和比較任務(wù)所需的評估工作量需要 160000 多個 MIP 解算,以及近一百萬個 CPU 和 GPU 小時。為了滿足計算需求,該研究使用了一個共享的、異構(gòu)的計算集群。
為了提高準(zhǔn)確性,對于每個求解任務(wù),該研究定期在同一臺機(jī)器上的不同線程上解決一個小的校準(zhǔn) MIP。該研究還使用在同一臺機(jī)器上解決任務(wù)時的校準(zhǔn) MIP 求解數(shù)的估計來測量時間,然后使用參考機(jī)器上的校準(zhǔn) MIP 求解時間將這個量轉(zhuǎn)換為時間值。
Neural Diving
在本節(jié)中,研究者用本文方法來學(xué)習(xí) diving-style 原始啟發(fā)式的方法,該算法從給定的實例分布為 MIP 生成高質(zhì)量的賦值。思想是訓(xùn)練一個生成模型,對 MIP 的整數(shù)變量進(jìn)行賦值,從這些整數(shù)變量中可以抽樣部分賦值。該研究使用 SCIP 獲得高質(zhì)量的賦值(不一定是最優(yōu)的)作為 MIP 訓(xùn)練集的目標(biāo)標(biāo)簽。
一旦在這些數(shù)據(jù)上進(jìn)行了訓(xùn)練,該模型就可以預(yù)測來自同一問題分布的未見實例上的整數(shù)變量值。模型預(yù)測中所表示的不確定性被用于定義對原始 MIP 的部分賦值,該初始 MIP 固定了很大一部分整型變量。這些非常小的 sub-MIP 可以使用 SCIP 快速解決,產(chǎn)生高質(zhì)量的可行賦值。
解決方案預(yù)測作為條件生成模型
考慮一個整數(shù)程序(即,所有變量都是整數(shù)),其參數(shù)為 M = (A, b, c)(見方程 1),并在一組整數(shù)變量 x 上有一個非空可行集。假設(shè)最小化,該研究使用目標(biāo)函數(shù)定義 x 上的一個能量函數(shù):
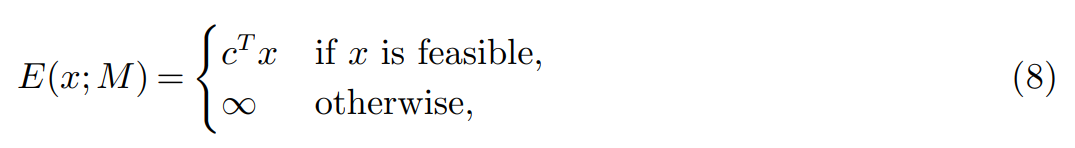
注意,所有變量都使用了相同的 MLP
模型預(yù)測與經(jīng)典求解器相結(jié)合
該研究使用 SelectiveNet 方法訓(xùn)練了一個額外的二元分類器,可以用來判斷哪些變量需要預(yù)測,哪些不需要預(yù)測,并優(yōu)化變量之間的「coverage」,將其定義為預(yù)測變量數(shù)與未預(yù)測變量數(shù)之比。
通過分配或收緊大部分變量的邊界,該研究顯著地減少了問題的規(guī)模,并熱啟動 SCIP,以在更短的時間內(nèi)找到高質(zhì)量的解決方案。
這種方法還提供了實際的計算優(yōu)勢:預(yù)測抽樣和解搜索是完全并行的。研究者可以重復(fù)和獨立地從模型中提取不同的樣本,并且樣本的每個部分賦值都可以獨立地求解。
結(jié)果
該研究在訓(xùn)練集上為每個數(shù)據(jù)集訓(xùn)練一個 GNN,并在驗證集上調(diào)整超參數(shù)。 原始間隙(primal gap)與基線 SCIP 的平均結(jié)果。
與 SCIP 相比,該研究在并行和順序運(yùn)行方面,在所有數(shù)據(jù)集上以更短的時間產(chǎn)生更好的原始邊界。研究者認(rèn)為該方法的優(yōu)勢是能迅速找到好的解決方案,但有時它不能找到最優(yōu)或接近最優(yōu)的解決方案。這可以從圖 7 的 survival plot 中看出,Neural Diving 方法在較短的時間限制下勝出,但在 Electric Grid Optimization 和 MIPLIB 數(shù)據(jù)集上不如 SCIP。
該研究在兩個數(shù)據(jù)集上(Google Production Packing 、 NN Verification,如圖 8、9 所示)引入了兩個額外的結(jié)果,并且將 Neural Diving、Gurobi 求解器進(jìn)行結(jié)合:該研究以同樣的方式分配變量,但使用 Gurobi 而不是 SCIP 來解決剩下的問題。
除了在上表 1 中的數(shù)據(jù)集上評估 Neural Diving 之外,研究者還通過修改自身方法來求解 MIPLIB 2017 Collection Set 中的開放實例。這些實例是 MIPLIB 2017 Collection Set 能夠提供的 hardest 的問題。
Neural Branching
分支定界(branch-and-bound)過程在每次迭代時需要做出兩個決策,即擴(kuò)展哪個葉節(jié)點以及在哪個變量上分支。研究者專注于后一個決策。變量選擇決策的質(zhì)量對求解 MIP 時分支定界所采取的步驟數(shù)量具有重大影響。通過模擬節(jié)點高效但計算昂貴的 expert 的行動,他們使用深度神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)變量選擇策略。
通過將昂貴 expert 的策略提煉到神經(jīng)網(wǎng)絡(luò)中,研究者尋求保持大致相同的決策質(zhì)量,但大大減少了做出決策所需時間。給定樹節(jié)點的決策完全是該節(jié)點的本地決策,因此學(xué)習(xí)策略只需要將節(jié)點的表示而不是整個樹作為輸入,由此實現(xiàn)更強(qiáng)的可擴(kuò)展性。
為了證明 expert 數(shù)據(jù)生成的可擴(kuò)展性得到了提升,研究者將 ADMM expert 與 Gasse 等人于 2019 年使用的 expert,即 Google Production Packing 和 MIPLIB 上的 Vanilla Full Strong Branching (VFSB)進(jìn)行了比較。
模仿學(xué)習(xí)是給定 expert 行為示例的情況時尋求學(xué)習(xí) expert 策略的算法的統(tǒng)稱。研究者在本文中將模仿學(xué)習(xí)表述為一個監(jiān)督學(xué)習(xí)問題,并考慮了三種變體:克隆 expert 策略、隨機(jī)移動的蒸餾和 DAgger。
在實驗中,研究者將他們選擇的三種模仿學(xué)習(xí)變體作為超參數(shù)對每個數(shù)據(jù)集進(jìn)行調(diào)整。他們使用這三種變體為每個數(shù)據(jù)集生成了數(shù)據(jù)和訓(xùn)練策略,并選定了三小時內(nèi)在驗證集實例上取得最低平均對偶間隙(dual gap)的策略,接著在測試集上對選定的策略進(jìn)行評估以得出相關(guān)結(jié)果。
結(jié)果
研究者在優(yōu)化雙重約束的任務(wù)上對學(xué)得的分支策略進(jìn)行評估。下圖 展示了 Neural Branching 與 Tuned SCIP 的平均對偶間隙曲線圖:

將一個數(shù)據(jù)集的目標(biāo)最優(yōu)間隙應(yīng)用于每個測試集 MIP 實例的對偶間隙時計算得出的生存曲線。研究者確認(rèn)了上圖 得出的結(jié)論,即在除 Google Production Planning 和 MIPLIB 之外的所有數(shù)據(jù)集上,Neural Branching 能夠在所有時間期限內(nèi)持續(xù)地求解出更高分?jǐn)?shù)的測試實例。
聯(lián)合評估
研究者將 Neural Branching 和 Neural Diving 結(jié)合成了單個求解器,這種做法使得在 Tuned SCIP 上實現(xiàn)了顯著加速。他們通過 PySCIPOpt 包提供的接口使用并將學(xué)得的啟發(fā)式方法集成到 SCIP 中。
此外,研究者考慮了四種結(jié)合 Neural Branching 和 Neural Diving 的可能方法,具體如下:
單獨的 Tuned SCIP;
Neural Branching+Neural Diving(序列)使用神經(jīng)啟發(fā)式方法;
Neural Branching 僅使用學(xué)得的 branching 策略;
Tuned SCIP+Neural Diving(序列)僅使用連續(xù)版本的 Neural Diving。
作為運(yùn)行時間函數(shù)的平均原始對偶間隙曲線,神經(jīng)求解器在四個數(shù)據(jù)集上顯著優(yōu)于 Tuned SCIP。
具體來講,在 NN Verification 數(shù)據(jù)集上,神經(jīng)求解器在大的時間期限內(nèi)平均原始對偶間隙比 Tuned SCIP 好 5 個數(shù)量級以上;在 Google Production Packing 數(shù)據(jù)集上,Neural Branching 和 Neural Diving(序列)更快地實現(xiàn)更低的間隙,在比 Tuned SCIP 時間少 5 倍多的情況下達(dá)到了 0.1 的間隙,但 Tuned SCIP 最后趕上了;在 Electric Grid Optimization 數(shù)據(jù)集上,神經(jīng)求解器以更高的運(yùn)行時間實現(xiàn)了低一半的間隙;在 MIPLIB 數(shù)據(jù)集上,Tuned SCIP+Neural Diving(序列)組合以更高的運(yùn)行時間實現(xiàn)了 1.5 倍的間
研究者進(jìn)一步確認(rèn)了觀察結(jié)果,同樣在四個數(shù)據(jù)集上,神經(jīng)求解器在給定時間期限內(nèi)求解測試集問題時能夠取得比 Tuned SCIP 更高的分?jǐn)?shù)。因此,這些結(jié)果表明學(xué)習(xí)可以顯著提升 SCIP 等強(qiáng)大求解器的性能。
編輯:jq
-
MIP
+關(guān)注
關(guān)注
0文章
38瀏覽量
14238 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25306 -
求解器
+關(guān)注
關(guān)注
0文章
79瀏覽量
4713 -
GCN
+關(guān)注
關(guān)注
0文章
5瀏覽量
2356
原文標(biāo)題:DeepMind用神經(jīng)網(wǎng)絡(luò)自動構(gòu)建啟發(fā)式算法,求解MIP問題
文章出處:【微信號:AcousticSignal,微信公眾號:聲學(xué)信號處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是BP神經(jīng)網(wǎng)絡(luò)的反向傳播算法
人工神經(jīng)網(wǎng)絡(luò)的原理和多種神經(jīng)網(wǎng)絡(luò)架構(gòu)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論