 Python替換字符串的新方法
Python替換字符串的新方法
FlashText 算法是由 Vikash Singh 于2017年發表的大規模關鍵詞替換算法,這個算法的時間復雜度僅由文本長度(N)決定,算法時間復雜度為O(N)。
而對于正則表達式的替換,算法時間復雜度還需要考慮被替換的關鍵詞數量(M),因此時間復雜度為O(MxN)。
簡而言之,基于FlashText算法的字符串替換比正則表達式替換快M倍以上,這個M是需要替換的關鍵詞數量,關鍵詞越多,FlashText算法的優勢就越明顯。
下面就給大家介紹如何在 Python 中基于flashtext模塊使用FlashText算法進行字符串查找和替換,如果覺得對你的項目團隊很有幫助,請記得轉發一下哦。
1.準備
pip install flashtext
2.基本使用
提取關鍵詞
一個最基本的提取關鍵詞的例子如下:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器
keyword_processor = KeywordProcessor()
# 2. 添加關鍵詞
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
# 3. 處理目標句子并提取相應關鍵詞
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
# 4. 結果
print(keywords_found)
# ['New York', 'Bay Area']
其中add_keyword的第一個參數代表需要被查找的關鍵詞,第二個參數是給這個關鍵詞一個別名,如果找到了則以別名顯示。
替換關鍵詞
如果你想要替換關鍵詞,只需要調用處理器的replace_keywords函數:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器
keyword_processor = KeywordProcessor()
# 2. 添加關鍵詞
keyword_processor.add_keyword('New Delhi', 'NCR region')
# 3. 替換關鍵詞
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
# 4. 結果
print(new_sentence)
# 'I love New York and NCR region.'
關鍵詞大小寫敏感
如果你需要精確提取,識別大小寫字母,那么你可以在處理器初始化的時候設定sensitive參數:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器, 注意設置大小寫敏感(case_sensitive)為TRUE
keyword_processor = KeywordProcessor(case_sensitive=True)
# 2. 添加關鍵詞
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
# 3. 處理目標句子并提取相應關鍵詞
keywords_found = keyword_processor.extract_keywords('I love big Apple and Bay Area.')
# 4. 結果
print(keywords_found)
# ['Bay Area']
標記關鍵詞位置
如果你需要獲取關鍵詞在句子中的位置,在extract_keywords的時候添加span_info=True參數即可:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器
keyword_processor = KeywordProcessor()
# 2. 添加關鍵詞
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
# 3. 處理目標句子并提取相應關鍵詞, 并標記關鍵詞的起始、終止位置
keywords_found = keyword_processor.extract_keywords('I love big Apple and Bay Area.', span_info=True)
# 4. 結果
print(keywords_found)
# [('New York', 7, 16), ('Bay Area', 21, 29)]
獲取目前所有的關鍵詞
如果你需要獲取當前已經添加的所有關鍵詞,只需要調用處理器的get_all_keywords函數:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器
keyword_processor = KeywordProcessor()
# 2. 添加關鍵詞
keyword_processor.add_keyword('j2ee', 'Java')
keyword_processor.add_keyword('colour', 'color')
# 3. 獲取所有關鍵詞
keyword_processor.get_all_keywords()
# output: {'colour': 'color', 'j2ee': 'Java'}
批量添加關鍵詞
批量添加關鍵詞有兩種方法,一種是通過詞典,一種是通過數組:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器
keyword_processor = KeywordProcessor()
# 2. (第一種)通過字典批量添加關鍵詞
keyword_dict = {
"java": ["java_2e", "java programing"],
"product management": ["PM", "product manager"]
}
keyword_processor.add_keywords_from_dict(keyword_dict)
# 2. (第二種)通過數組批量添加關鍵詞
keyword_processor.add_keywords_from_list(["java", "python"])
# 3. 第一種的提取效果如下
keyword_processor.extract_keywords('I am a product manager for a java_2e platform')
# output ['product management', 'java']
單一或批量刪除關鍵詞
刪除關鍵詞也非常簡單,和添加類似:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器
keyword_processor = KeywordProcessor()
# 2. 通過字典批量添加關鍵詞
keyword_dict = {
"java": ["java_2e", "java programing"],
"product management": ["PM", "product manager"]
}
keyword_processor.add_keywords_from_dict(keyword_dict)
# 3. 提取效果如下
print(keyword_processor.extract_keywords('I am a product manager for a java_2e platform'))
# ['product management', 'java']
# 4. 單個刪除關鍵詞
keyword_processor.remove_keyword('java_2e')
# 5. 批量刪除關鍵詞,也是可以通過詞典或者數組的形式
keyword_processor.remove_keywords_from_dict({"product management": ["PM"]})
keyword_processor.remove_keywords_from_list(["java programing"])
# 6. 刪除了java programing關鍵詞后的效果如下
keyword_processor.extract_keywords('I am a product manager for a java_2e platform')
# ['product management']
3.高級使用
支持額外信息
前面提到在添加關鍵詞的時候第二個參數為其別名,其實你不僅可以指示別名,還可以將額外信息放到第二個參數中:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器
kp = KeywordProcessor()
# 2. 添加關鍵詞并附帶額外信息
kp.add_keyword('Taj Mahal', ('Monument', 'Taj Mahal'))
kp.add_keyword('Delhi', ('Location', 'Delhi'))
# 3. 效果如下
kp.extract_keywords('Taj Mahal is in Delhi.')
# [('Monument', 'Taj Mahal'), ('Location', 'Delhi')]
這樣,在提取關鍵詞的時候,你還能拿到其他一些你想要在得到此關鍵詞時輸出的信息。
支持特殊單詞邊界
Flashtext 檢測的單詞邊界一般局限于 w [A-Za-z0-9_] 外的任意字符,但是如果你想添加某些特殊字符作為單詞的一部分也是可以實現的:
fromflashtext importKeywordProcessor
# 1. 初始化關鍵字處理器
keyword_processor = KeywordProcessor()
# 2. 添加關鍵詞
keyword_processor.add_keyword('Big Apple')
# 3. 正常效果
print(keyword_processor.extract_keywords('I love Big Apple/Bay Area.'))
# ['Big Apple']
# 4. 將 '/' 作為單詞一部分
keyword_processor.add_non_word_boundary('/')
# 5. 優化后的效果
print(keyword_processor.extract_keywords('I love Big Apple/Bay Area.'))
# []
4.結尾
個人認為這個模塊已經滿足我們的基本使用了,如果你有一些該模塊提供的功能之外的使用需求,可以給 flashtext 貢獻代碼:
https://github.com/vi3k6i5/flashtext
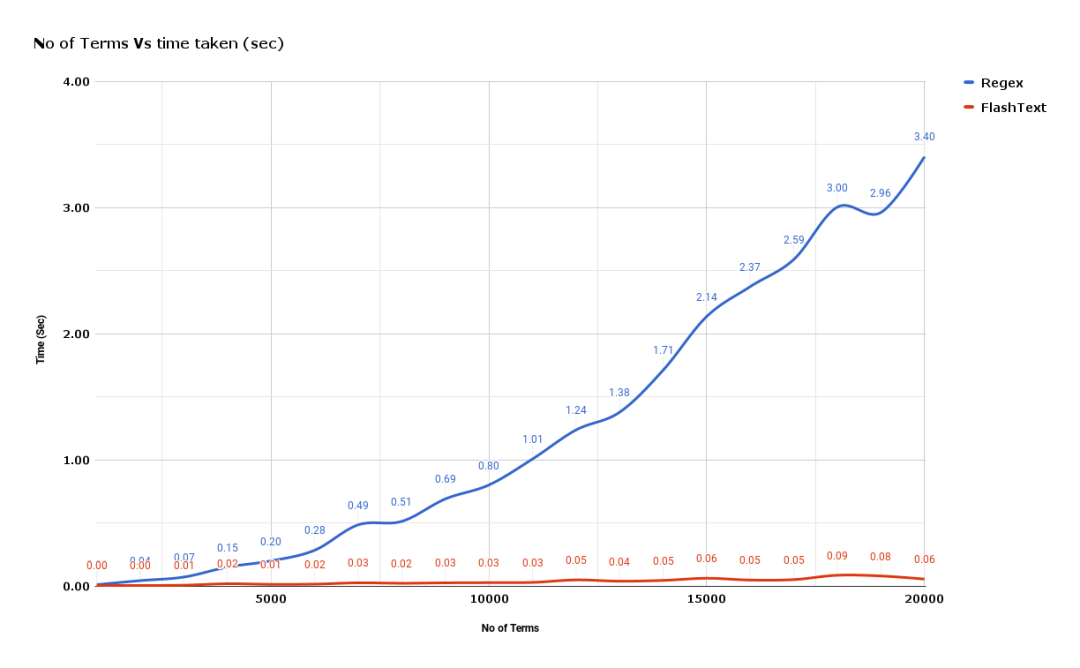
附 FlashText 與正則相比查詢關鍵詞所花費的時間之比:
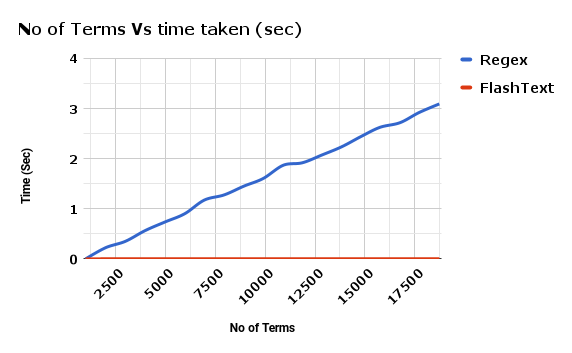
附 FlashText 與正則相比替換關鍵詞所花費的時間之比:
這篇文章如果對你有幫助的話,記得轉發一下哦。
原文標題:比正則快 M 倍以上!Python 替換字符串的新姿勢
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
-
算法
+關注
關注
23文章
4702瀏覽量
94971 -
字符串
+關注
關注
1文章
589瀏覽量
21178 -
python
+關注
關注
56文章
4825瀏覽量
86375
原文標題:比正則快 M 倍以上!Python 替換字符串的新姿勢
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄







 工商網監
工商網監
評論