") 利用NVIDIA DALI為加速數(shù)據(jù)管道提供性能和靈活性
利用NVIDIA DALI為加速數(shù)據(jù)管道提供性能和靈活性
深度學(xué)習(xí)模型需要使用大量數(shù)據(jù)進(jìn)行培訓(xùn),以獲得準(zhǔn)確的結(jié)果。由于各種原因,例如不同的存儲(chǔ)格式、壓縮、數(shù)據(jù)格式和大小,以及高質(zhì)量數(shù)據(jù)的數(shù)量有限,原始數(shù)據(jù)通常無法直接輸入神經(jīng)網(wǎng)絡(luò)。
解決這些問題需要大量的數(shù)據(jù)準(zhǔn)備和預(yù)處理步驟,從加載、解碼、解壓縮到調(diào)整大小、格式轉(zhuǎn)換和各種數(shù)據(jù)擴(kuò)充。
深度學(xué)習(xí)框架,如 TensorFlow 、 PyTorch 、 MXNet 等,為一些預(yù)處理步驟提供了本地實(shí)現(xiàn)。由于使用特定于框架的數(shù)據(jù)格式、轉(zhuǎn)換的可用性以及不同框架之間的實(shí)現(xiàn)差異,這通常會(huì)帶來可移植性問題。
CPU 瓶頸
直到最近,深度學(xué)習(xí)工作負(fù)載的數(shù)據(jù)預(yù)處理才引起人們的關(guān)注,因?yàn)橛?xùn)練復(fù)雜模型所需的巨大計(jì)算資源使其黯然失色。因此,由于 OpenCV 、 Pillow 或 Librosa 等庫的簡(jiǎn)單性、靈活性和可用性,預(yù)處理任務(wù)通常用于在 CPU 上運(yùn)行。
NVIDIA 伏特和 NVIDIA 安培體系結(jié)構(gòu)中引入的 GPU 體系結(jié)構(gòu)的最新進(jìn)展顯著提高了深度學(xué)習(xí)任務(wù)中的 GPU 吞吐量。特別是,半精度算法與張量核加速某些類型的 FP16 矩陣計(jì)算,這對(duì)培訓(xùn)DNNs非常有用。密集的多 GPU 系統(tǒng),如 NVIDIA DGX-2和DGX A100訓(xùn)練模型的速度遠(yuǎn)遠(yuǎn)快于輸入管道提供的數(shù)據(jù),使 GPU 缺少數(shù)據(jù)。
今天的 DL 應(yīng)用程序包括由許多串行操作組成的復(fù)雜、多階段的數(shù)據(jù)處理管道。依賴 CPU 處理這些管道會(huì)限制性能和可擴(kuò)展性。在圖 1 中,可以觀察到數(shù)據(jù)預(yù)處理對(duì) ResNet-50 網(wǎng)絡(luò)訓(xùn)練吞吐量的影響。在左側(cè),我們可以看到在 CPU 上運(yùn)行的用于數(shù)據(jù)加載和預(yù)處理的框架工具時(shí)網(wǎng)絡(luò)的吞吐量。在右側(cè),我們可以看到相同網(wǎng)絡(luò)的性能,而不受數(shù)據(jù)加載和預(yù)處理的影響,用合成數(shù)據(jù)替換。當(dāng)比較不同的數(shù)據(jù)預(yù)處理工具時(shí),這種測(cè)量可以用作理論上限。
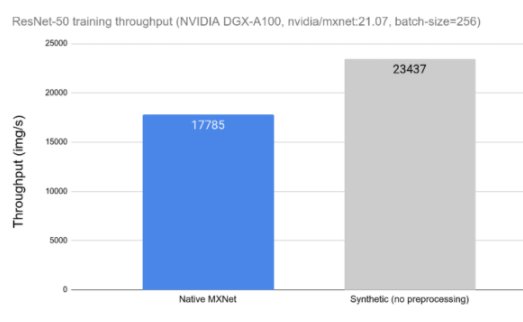
圖 1 : ResNet-50 網(wǎng)絡(luò)的數(shù)據(jù)預(yù)處理對(duì)總體訓(xùn)練吞吐量的影響。
大理來營(yíng)救
NVIDIA 數(shù)據(jù)加載庫( DALI )是我們致力于為上述數(shù)據(jù)管道問題找到可擴(kuò)展和可移植解決方案的結(jié)果。 DALI 是一組高度優(yōu)化的構(gòu)建塊和執(zhí)行引擎,用于加速深度學(xué)習(xí)( DL )應(yīng)用程序的輸入數(shù)據(jù)預(yù)處理(見圖 2 )。 DALI 為加速不同的數(shù)據(jù)管道提供了性能和靈活性。
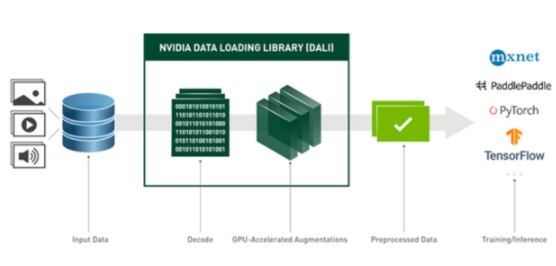
圖 2 : DALI 概述及其在 DL 應(yīng)用程序中作為加速數(shù)據(jù)加載和預(yù)處理工具的使用。
DALI 為各種深度學(xué)習(xí)應(yīng)用程序(如分類或檢測(cè))提供數(shù)據(jù)處理原語,并支持不同的數(shù)據(jù)域,包括圖像、視頻、音頻和體積數(shù)據(jù)。
支持的輸入格式包括最常用的圖像文件格式( JPEG 、 PNG 、 TIFF 、 BMP 、 JPEG2000 、 NETPBM )、 NumPy 陣列、使用多種編解碼器編碼的視頻文件( H 。 264 、 HEVC 、 VP8 、 VP9 、 MJPEG )以及音頻文件( WAV 、 OGG 、 FLAC )。
DALI 的一個(gè)重要特性是插件,它可以作為框架本機(jī)數(shù)據(jù)集的插入式替換。目前, DALI 帶有 MxNET PyTorch 、 TensorFlow 和 PaddlePaddle 的插件。只要使用不同的數(shù)據(jù)迭代器包裝器,就可以一次性定義 DALI 管道,并與任何受支持的框架一起使用。
除此之外, DALI 本機(jī)支持特定框架中使用的不同存儲(chǔ)格式(例如, Caffe 和 Caffe2 中的 LMDB 、 MXNet 中的 RecordIO 、 TensorFlow 中的 TFRecord )。這允許我們使用任何受支持的數(shù)據(jù)格式,而不管使用的是何種 DL 框架。例如,我們可以對(duì)模型使用 MXNet ,同時(shí)將數(shù)據(jù)保存在 TFRecord (原生 TensorFlow 數(shù)據(jù)格式)中。
通過在 Python 中配置外部數(shù)據(jù)源,或使用自定義運(yùn)算符進(jìn)行擴(kuò)展,可以輕松地為特定項(xiàng)目定制 DALI 。最后,DALI是一個(gè)開源項(xiàng)目,因此您可以輕松地對(duì)其進(jìn)行擴(kuò)展和調(diào)整,以滿足您的特定需求。
大理關(guān)鍵概念
DALI 中的主要實(shí)體是數(shù)據(jù)處理pipeline。管道由operators連接的數(shù)據(jù)節(jié)點(diǎn)的符號(hào)圖定義。每個(gè)操作符通常獲得一個(gè)或多個(gè)輸入,應(yīng)用某種數(shù)據(jù)處理,并產(chǎn)生一個(gè)或多個(gè)輸出。有一些特殊類型的運(yùn)算符不接受任何輸入并產(chǎn)生輸出。這些特殊操作符就像一個(gè)數(shù)據(jù)源——讀卡器、隨機(jī)數(shù)生成器和外部_源都屬于這一類。管道定義在 Python 中使用命令式語言表示,與當(dāng)前大多數(shù)深度學(xué)習(xí)框架一樣,但以異步方式運(yùn)行。
構(gòu)建完成后,管道實(shí)例可以通過調(diào)用管道的 run 方法顯式運(yùn)行,也可以使用特定于目標(biāo)深度學(xué)習(xí)框架的數(shù)據(jù)迭代器包裝。
DALI 為各種處理操作員提供 CPU 和 GPU 實(shí)現(xiàn)。 CPU 或 GPU 實(shí)現(xiàn)的可用性取決于運(yùn)營(yíng)商的性質(zhì)。確保檢查文檔中是否有支持的操作的最新列表,因?yàn)槊總€(gè)版本都會(huì)對(duì)其進(jìn)行擴(kuò)展。
DALI 運(yùn)營(yíng)商要求將輸入數(shù)據(jù)放置在與運(yùn)營(yíng)商后端相同的設(shè)備上。具有混合后端的運(yùn)算符是一種特殊類型的運(yùn)算符,用于接收 CPU 內(nèi)存中的輸入和 GPU 內(nèi)存中的輸出數(shù)據(jù)。出于性能原因,無法訪問 DALI 管道中從 GPU 到 CPU 內(nèi)存的數(shù)據(jù)傳輸。
雖然 DALI 的大部分好處是在將處理卸載到 GPU 時(shí)實(shí)現(xiàn)的,但有時(shí)在 CPU 上保持部分操作運(yùn)行是有益的。特別是在 CPU 與 GPU 比率較高的系統(tǒng)中,或在 GPU 完全被模型占用的情況下。用戶可以嘗試 CPU / GPU 位置,以逐個(gè)找到最佳位置。
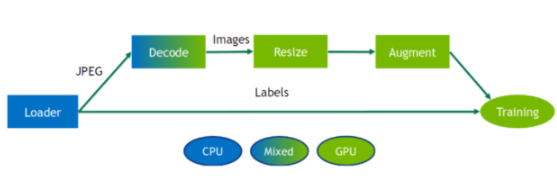
圖 3 : DALI 管道的示例。數(shù)據(jù)加載到 CPU 上,然后使用混合后端操作符進(jìn)行解碼,該操作符在 GPU 內(nèi)存上輸出解碼圖像,然后在 GPU 上對(duì)其進(jìn)行大小調(diào)整和擴(kuò)充。
如前所述, DALI 的執(zhí)行是異步的,這允許數(shù)據(jù)預(yù)取,也就是說,在請(qǐng)求批數(shù)據(jù)之前提前準(zhǔn)備批數(shù)據(jù),以便框架始終為下一次迭代準(zhǔn)備好數(shù)據(jù)。 DALI 使用可配置的預(yù)取隊(duì)列長(zhǎng)度為用戶透明地處理數(shù)據(jù)預(yù)取。數(shù)據(jù)預(yù)取有助于隱藏預(yù)處理的延遲,當(dāng)處理時(shí)間在迭代中發(fā)生顯著變化時(shí),這一點(diǎn)很重要(見圖 4 )。
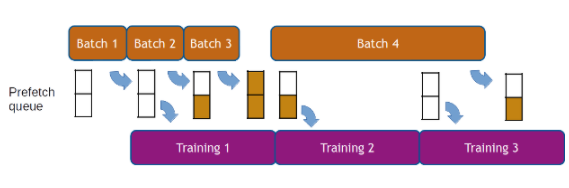
圖 4 :數(shù)據(jù)預(yù)取示例,預(yù)取隊(duì)列深度為 2 。較長(zhǎng)迭代(第 4 批)的延遲因提前計(jì)算而被隱藏。
如何使用大理
定義 DALI 管道的最簡(jiǎn)單方法是使用pipeline_def Python 裝飾器。為了創(chuàng)建管道,我們定義了一個(gè)函數(shù),在該函數(shù)中實(shí)例化并連接所需的運(yùn)算符,并返回相關(guān)的輸出。然后用pipeline_def來裝飾它。
from nvidia.dali import pipeline_def, fn
@pipeline_def
def simple_pipeline():
jpegs, labels = fn.readers.file(file_root=image_dir,
random_shuffle=True,
name="Reader")
images = fn.decoders.image(jpegs)
return images, labels
在這個(gè)示例管道中,沒有什么值得注意的事情。第一個(gè)操作符是文件讀取器,它發(fā)現(xiàn)并加載目錄中包含的文件。讀取器輸出文件的內(nèi)容(在本例中為編碼的 JPEG )和從目錄結(jié)構(gòu)推斷的標(biāo)簽。我們還啟用了隨機(jī)洗牌并為 reader 實(shí)例命名,這在稍后與框架迭代器集成時(shí)非常重要。第二個(gè)運(yùn)算符是圖像解碼器。
下一步是實(shí)例化simple_pipeline對(duì)象并構(gòu)建它以實(shí)際構(gòu)建圖形。在管道實(shí)例化過程中,我們還定義了批大小、用于數(shù)據(jù)處理的 CPU 線程數(shù)以及 GPU 設(shè)備序號(hào)。
pipe = simple_pipeline(batch_size=32, num_threads=3, device_id=0)
pipe.build()
此時(shí),管道已準(zhǔn)備好使用。我們可以通過調(diào)用 run 方法獲得一批數(shù)據(jù)。
images, labels = pipe.run()
現(xiàn)在,讓我們添加一些數(shù)據(jù)增強(qiáng),例如,以隨機(jī)角度旋轉(zhuǎn)每個(gè)圖像。要生成隨機(jī)角度,我們可以使用random.uniform,并旋轉(zhuǎn)rotation:
@pipeline_def()
def rotate_pipeline():
jpegs, labels = fn.readers.file(file_root=image_dir,
random_shuffle=True,
name="Reader")
images = fn.decoders.image(jpegs)
angle = fn.random.uniform(range=(-10.0, 10.0))
rotated_images = fn.rotate(images, angle=angle, fill_value=0)
return rotated_images, labels
將計(jì)算卸載到 GPU
我們現(xiàn)在可以修改我們的簡(jiǎn)單_管道,以便它使用.gpu()執(zhí)行擴(kuò)充。 DALI 使這種轉(zhuǎn)變非常容易。唯一改變的是rotate運(yùn)算符的定義。我們只需要將device參數(shù)設(shè)置為“gpu”,并確保通過調(diào)用 GPU 將其輸入傳輸?shù)?GPU 。
self.rotate = fn.rotate(images.gpu(), angle=angle, device="gpu")
為了使事情更簡(jiǎn)單,我們甚至可以省略device參數(shù),讓 DALI 直接從輸入位置推斷出運(yùn)算符。
self.rotate = fn.rotate(images.gpu(), angle=angle)
也就是說,simple_pipeline現(xiàn)在在 GPU 上執(zhí)行旋轉(zhuǎn)。請(qǐng)記住,生成的圖像也會(huì)分配到 GPU 內(nèi)存中,這通常是我們想要的,因?yàn)槟P托枰?GPU 內(nèi)存中的數(shù)據(jù)。在任何情況下,運(yùn)行管道后將數(shù)據(jù)復(fù)制回 CPU 內(nèi)存都可以通過調(diào)用Pipeline.run返回的對(duì)象as_cpu輕松實(shí)現(xiàn)。
images, labels = pipe.run()
images_host = images.as_cpu()
框架集成
與不同深度學(xué)習(xí)框架的無縫互操作性代表了 DALI 的最佳功能之一。例如,要將您的管道與 PyTorch 模型一起使用,我們可以通過使用DALIClassificationIterator包裝它來輕松實(shí)現(xiàn)。對(duì)于更一般的情況,例如任意數(shù)量的管道輸出,請(qǐng)使用DALIGenericIterator。
from nvidia.dali.plugin.pytorch import DALIGenericIterator
train_loader = DALIClassificationIterator([pipe], reader_name='Reader')
注意參數(shù)reader_name,該值與reader實(shí)例的 name 參數(shù)匹配。迭代器將使用該讀取器作為一個(gè)歷元中樣本數(shù)的信息源。
我們現(xiàn)在可以枚舉train_loader實(shí)例并將數(shù)據(jù)批提供給模型。
for i, data in enumerate(train_loader):
images = data[0]["data"]
target = data[0]["label"].squeeze(-1).long()
# model training
關(guān)于框架集成的更多信息可以在文檔的框架插件部分中找到。
推理中的達(dá)利
為訓(xùn)練和推理提供數(shù)據(jù)處理步驟的等效定義對(duì)于獲得良好的精度結(jié)果至關(guān)重要。多虧了 NVIDIA Triton 推理服務(wù)器及其專用的大理后端,我們現(xiàn)在可以輕松地將 DALI 管道部署到推理應(yīng)用程序,使數(shù)據(jù)管道完全可移植。在圖 6 所示的體系結(jié)構(gòu)中, DALI 管道作為 Triton 集成模型的一部分進(jìn)行部署。這種配置有兩個(gè)主要優(yōu)點(diǎn)。首先,數(shù)據(jù)處理是在服務(wù)器中執(zhí)行的,通常是一臺(tái)比客戶機(jī)功能更強(qiáng)大的機(jī)器。第二個(gè)好處是數(shù)據(jù)可以被壓縮后發(fā)送到服務(wù)器,這節(jié)省了網(wǎng)絡(luò)帶寬。
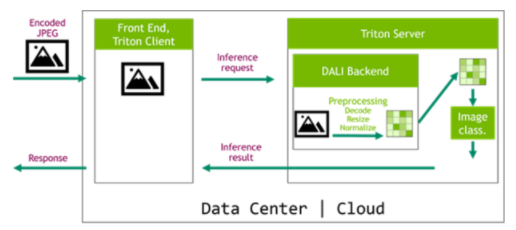
圖 6 : DALI 在推理配置中,帶有 NVIDIA Triton 推理服務(wù)器和用于服務(wù)器端預(yù)處理的 DALI 后端。
請(qǐng)務(wù)必查看我們的專用文章使用 NVIDIA Triton 推理服務(wù)器和 NVIDIA DALI 加速推理,詳細(xì)介紹此主題。
達(dá)利對(duì)績(jī)效的影響
NVIDIA 展示了 DALI 對(duì) SSD 、 ResNet-50 和 RNN-T 的實(shí)現(xiàn),這是我們的MLPerf基準(zhǔn)成功中的一個(gè)促成因素。
讓我們比較一下使用 DALI 和使用框架的本機(jī)解決方案時(shí) ResNet-50 網(wǎng)絡(luò)的訓(xùn)練吞吐量。在圖 7 中,我們可以看到與圖 1 中所示類似的比較,這一次顯示了將 DALI 作為選項(xiàng)之一用于數(shù)據(jù)加載和預(yù)處理的結(jié)果。我們可以看到 DALI 的訓(xùn)練吞吐量如何更接近理論上限(合成示例)。
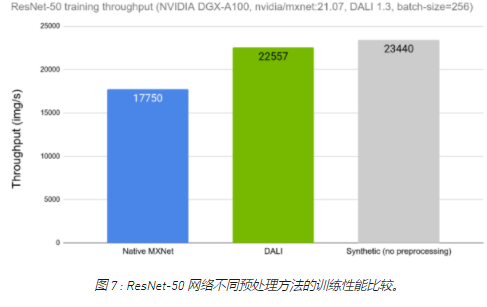
圖 7 : ResNet-50 網(wǎng)絡(luò)不同預(yù)處理方法的訓(xùn)練性能比較。
現(xiàn)在讓我們看看 DALI 如何影響 Triton 服務(wù)器中 Resnet50 推理的性能。圖 8 顯示了脫機(jī)預(yù)處理的平均推斷請(qǐng)求延遲,這意味著在啟動(dòng)請(qǐng)求之前數(shù)據(jù)已經(jīng)過預(yù)處理,以及聯(lián)機(jī)服務(wù)器端預(yù)處理。所花費(fèi)的時(shí)間細(xì)分為通信開銷、數(shù)據(jù)預(yù)處理和模型推理。由于解碼數(shù)據(jù)的大小較大,預(yù)處理請(qǐng)求的延遲會(huì)受到通信開銷的嚴(yán)重影響。因此,服務(wù)器端預(yù)處理比離線預(yù)處理快,即使前者在度量中包含數(shù)據(jù)預(yù)處理時(shí)間。
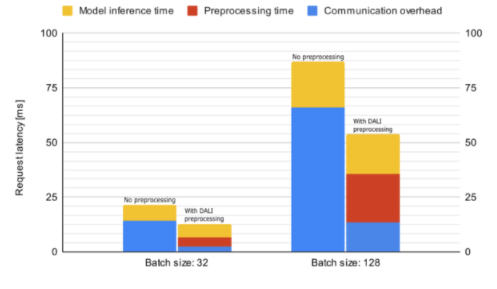
圖 8 : Resnet50 模型推斷的平均請(qǐng)求延遲(越低越好)比較。這些數(shù)字是使用 NVIDIA / Triton 服務(wù)器在 DGX A100 機(jī)器上使用單個(gè) GPU 收集的: 21 。 07-py3 容器。
今天就從 DALI 開始吧
您可以下載預(yù)構(gòu)建和測(cè)試的 DALI pip 包的最新版本。]:、MXNetMXNet的 NVIDIA GPU 云( NGC )容器已集成 DALI 。您可以查看許多examples并閱讀最新的發(fā)行說明,以獲取新功能和增強(qiáng)功能的詳細(xì)列表。
關(guān)于作者
Joaquin Anton Guirao 是 NVIDIA 深度學(xué)習(xí)框架團(tuán)隊(duì)的高級(jí)軟件工程師,專注于 NVIDIA DALI
Rafal Banas 是 NVIDIA 的軟件開發(fā)工程師。他致力于 DALI 項(xiàng)目,專注于推理用例。拉法在華沙大學(xué)獲得計(jì)算機(jī)科學(xué)學(xué)士學(xué)位。
Krzysztof ??cki 是 NVIDIA 的高級(jí)軟件開發(fā)工程師,在 DALI 工作。他以前的工作包括為 GPU 和 SIMD 體系結(jié)構(gòu)編寫高度優(yōu)化的數(shù)據(jù)處理代碼,重點(diǎn)關(guān)注計(jì)算機(jī)視覺和圖像處理應(yīng)用。
Janusz Lisiecki 是 NVIDIA 的深度學(xué)習(xí)經(jīng)理,致力于快速數(shù)據(jù)管道。他過去的經(jīng)驗(yàn)涵蓋從面向大眾消費(fèi)市場(chǎng)的嵌入式系統(tǒng)到高性能硬件軟件數(shù)據(jù)處理解決方案。
Albert Wolant 是軟件開發(fā)工程師,在 NVIDIA 的 DALI 團(tuán)隊(duì)工作。他在深度學(xué)習(xí)和 GP GPU 軟件開發(fā)方面都有經(jīng)驗(yàn)。他在并行算法和數(shù)據(jù)結(jié)構(gòu)方面做了一些研究工作。
Micha? Zientkiewicz 是 NVIDIA 的高級(jí)軟件工程師,目前正在開發(fā) DALI 。他的專業(yè)背景包括 GPU 編程、圖像處理和編譯器開發(fā)。米莎先生在華沙工業(yè)大學(xué)獲得計(jì)算機(jī)科學(xué)碩士學(xué)位。
Kamil Tokarski 是 NVIDIA 的軟件工程師,在 DALI 團(tuán)隊(duì)工作,熱衷于深度學(xué)習(xí)和密碼學(xué)。
Micha? Szo?ucha 是 NVIDIA 的軟件工程師,從事圖像處理和深度學(xué)習(xí)項(xiàng)目。曾與移動(dòng) 3D 技術(shù)合作。熱衷于使波蘭民間傳說適應(yīng)現(xiàn)代接受者的認(rèn)知。
審核編輯:郭婷
-
gpu
+關(guān)注
關(guān)注
28文章
4921瀏覽量
130796 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86353 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122572
發(fā)布評(píng)論請(qǐng)先 登錄
將M.2 SSD轉(zhuǎn)為可插拔設(shè)計(jì):提升工作站靈活性與維護(hù)效率的解決方案

磁性近程傳感器保證非接觸式定位和近程檢測(cè)的靈活性和可靠性

探索 RK3576 方案:卓越性能與靈活框架,誠(chéng)邀開發(fā)定制合作!
利用NVIDIA DPF引領(lǐng)DPU加速云計(jì)算的未來
Dali通信如何提高能源效率
NVIDIA DOCA-OFED的主要特性
面對(duì)快速迭代的技術(shù),怎能忽視設(shè)備升級(jí)的高效與靈活性?

NVIDIA JetPack 6.0版本的關(guān)鍵功能

利用NVIDIA RAPIDS加速DolphinDB Shark平臺(tái)提升計(jì)算性能
NVIDIA助力提供多樣、靈活的模型選擇
使用低成本MSPM0 MCU提高電池管理設(shè)計(jì)的靈活性

使用低成本MSPM0 MCU提高電子溫度計(jì)設(shè)計(jì)的靈活性
納米軟件帶您了解電源自動(dòng)測(cè)試設(shè)備的儀器靈活接入與擴(kuò)展
使用BQ27Z746實(shí)現(xiàn)反向充電保護(hù)的設(shè)計(jì)靈活性
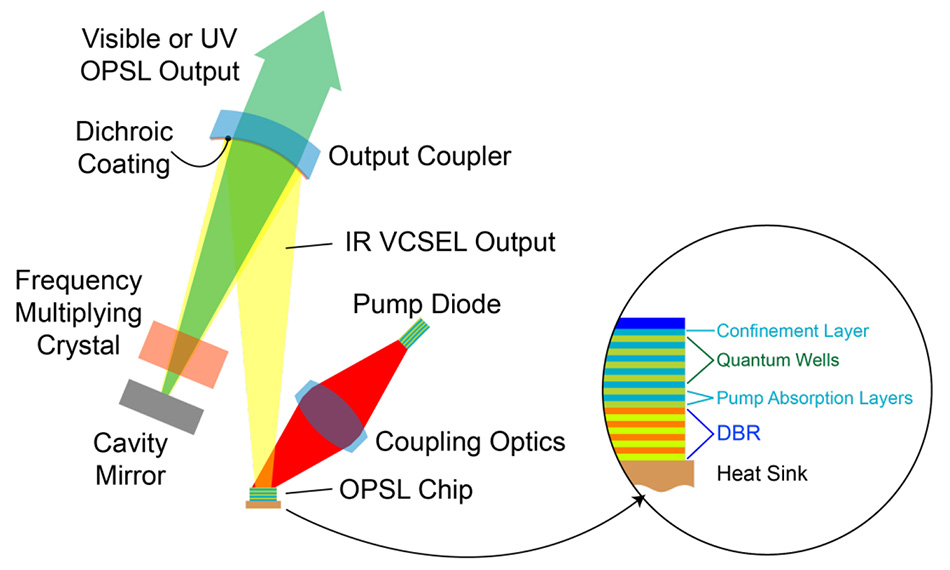
OPSL 優(yōu)勢(shì)1:波長(zhǎng)靈活性





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論