 NVIDIA深度學習加速數據科學教材套滿足教學需求
NVIDIA深度學習加速數據科學教材套滿足教學需求
NVIDIA 深度學習培訓中心( DLI )發布了加速數據科學教材套,該研究所與佐治亞理工學院的 Polo Chau 教授和 Prairie View A & M 大學的董錫雙教授共同開發。
綜合教材涵蓋數據收集和預處理、加速數據科學 RAPIDS、可擴展和分布式計算 GPU – 加速機器學習、數據可視化和圖形分析等基礎和高級主題,并滿足了高等教育和研究機構對學生教授數據科學技能的日益增長的需求。
加速數據科學教學包包括以下重點模塊:
數據科學與技術導論 RAPIDS
數據收集和預處理( ETL )
數據集中的數據倫理和偏見
數據集成和分析
數據可視化
使用 Hadoop 、 Hive 、 Spark 、 HBase 和 RAPIDS 的可擴展計算
基于 Dask 和 UCX 的可擴展計算
機器學習:分類
機器學習:聚類和降維
圖形分析
流數據
基因組學
文本分析
CPU vs GPU – 加速數據科學
數據科學團隊、代碼備份和版本控制
團隊項目(假新聞檢測)
該工具包還涵蓋了公平性和數據偏見等文化敏感話題,以及來自代表性不足群體的挑戰和重要人物。
講座幻燈片和講稿、動手實驗室、 Jupyter 筆記本、解決方案(以私人回購形式持有)、樣本數據集、測驗/考試問題/答案、 GPU 通過免費 AWS 云學分提供的計算資源,以及免費 DLI 在線課程/證書都包括在內。講座視頻計劃在下一版本中發布。
RAPIDS 數據科學框架是 GPU 加速的庫集合,用于在 GPU 上完全執行端到端數據科學管道。使用 RAPIDS 的主要目標是加速典型數據科學工作流的各個部分,從而加速數據準備和機器學習中完整的端到端工作流。
第一個基于 Jupyter 筆記本電腦的實驗室之一讓學生使用 pandas 和 cuDF 直接進入 RAPIDS 。 pandas 是一個建立在 Python 編程語言之上的數據分析和操作工具,用于執行各種任務(例如:加載、加入、聚合、, cuDF 是一個基于 RAPIDS 的 GPU 數據幀庫,有助于通過 GPU 加速執行類似功能。
學生們首先要理解如何在 cuDF 中創建數據幀對象,為這些對象分配值,然后調用方法并對值應用用戶定義的函數。一旦學生掌握了如何使用 cuDF 數據幀,他們的任務就是從 Kaggle 的Netflix 電影數據集中創建一個數據幀。
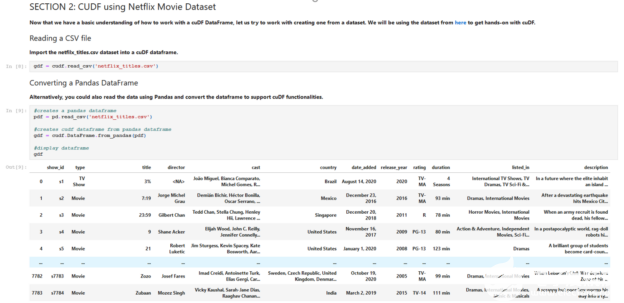
圖 1 。教學包模塊 1 的快照: RAPIDS 實驗室簡介。
從那里,學生們學習如何操作和查詢數據,從刪除缺失的列和值、查詢和查找唯一值,到對數據進行排序、計數和分組。學生將感受到使用 RAPIDS 和 GPU 與教學包中也包含的傳統方法相比是多么快速和簡單。作為實驗室的一項額外任務,最后要求學生使用 cuDF 一個熱編碼將數據集的電影和電視節目標題轉換為 0 和 1 的向量,以提高分析數據的準確性。
周教授說:“數據科學揭示了數據在解決社會挑戰和大規模復雜問題方面的巨大潛力,幾乎涵蓋了商業、技術、科學、工程、醫療保健、政府等各個領域。”隨著數據在數量、速度和復雜性方面的不斷增長,對數據科學人才和技能的需求不斷增加,以幫助設計最佳解決方案。”
關于作者
Joe Bungo 是 NVIDIA 的深度學習培訓中心( DLI )項目經理,在那里他能夠在大學中使用深度學習和 GPU 加速計算技術,包括課程和教材開發、 DLI 大學大使/講師認證、促進學術生態系統和實踐研討會。此前,他在 ARM 公司管理大學項目,并擔任應用工程師。喬獲得了得克薩斯大學奧斯汀分校計算機科學學位。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5083瀏覽量
103875 -
gpu
+關注
關注
28文章
4791瀏覽量
129473 -
深度學習
+關注
關注
73文章
5520瀏覽量
121626
發布評論請先 登錄
相關推薦
利用NVIDIA DPF引領DPU加速云計算的未來
NVIDIA RAPIDS cuDF如何賦能AI加速數據科學
NPU在深度學習中的應用

《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
FPGA做深度學習能走多遠?
NVIDIA推出全新深度學習框架fVDB
NVIDIA提供一套服務、模型以及計算平臺 加速人形機器人發展
深度學習與nlp的區別在哪
助力科學發展,NVIDIA AI加速HPC研究






 工商網監
工商網監
評論