 詳解TAO的配置文件與執行流程
詳解TAO的配置文件與執行流程
圖像分類 (image classification) 是視覺人工智能的最基礎應用,目前 TAO 模型訓練工具支持 resnet、vgg、mobilenet_v1、mobilenet_v2、googlenet、cspdarknet、darknet、efficientnet_b0、efficientnet_b1、cspdarknet_tiny 等 10 種神經網絡,其中 resnet、vgg、darknet、cspdarknet 還有不同結構層數的區分。
在 TAO 啟動器中只用 “classification” 這個任務指令,去面對上面所列出的十多種網絡結構,其關鍵處就是結合“配置文件”的協助,因此這個配置文件的設置組是 TAO 工具的核心所在,也是本文一開始要花時間說明的部分。
在 cv_samples 下面的 classification 項目,是 TAO 工具的圖像分類模型訓練的標準范例,里面提供 classification.ipynb 執行腳本與 specs 目錄下兩個 .cfg 配置文件,基本上在執行腳本里只需要修改一些路徑的設定就行,其余細節都在配置文件里面進行調整,包括所選擇的神經網絡種類與結構。
這個項目以 PascalVOC 2012 數據集作為訓練源,與 TAO 所支持的格式并不相同,因此在訓練之前還需要進行格式的轉換。還好這里的轉換比較簡單,只要將圖像分別存放在以“類別”所命名的目錄下就可以,同時分割成訓練與校驗兩個不同用途的數據集,在腳本里透過一段簡單的 Python 代碼就能完成,并沒有什么難度。
最后在訓練之前,可以選擇是否啟動 “遷移學習” 的功能?在這個實驗中也會示范這中間所得到的精度差異,讓大家直接體驗到遷移學習所帶來的的好處。
以下就將幾個執行重點提出來說明,協助大家可以輕松地執行。
配置文件內容
TAO 的 CLI 指令集只使用一個 classification 去面對所有的圖形分類應用,其余的工作就全部交給配置文件去處理。在圖像分類的配置文件里,主要有以下三個配置組:
1、model_config:存放神經網絡種類、結構(層數)與特性的內容,以下列出比較重要的部分:
(1) arch:網絡名稱,可使用所有已支持的網絡,包括 resnet、vgg、mobilenet_v1、mobilenet_v2、googlenet、cspdarknet、darknet、efficientnet_b0、efficientnet_b1、cspdarknet_tiny 等;
(2) n_layer:有些網絡有多種結構層,例如 resnet有10/18/34/50/101、vgg 有16/19、darknet 有 19/53、cspdarknet 有 19/53 等;
其余參數都按照配置文件里面所設定的值,因為 NGC 提供的預訓練模型是按照這些參數所訓練的,能在遷移學習過程中得到比較好的效果。
2、train_config:執行訓練時所需要參考的
(1) train_dataset_path: 訓練用數據集的位置,需要輸入在容器內的完整路徑
(2) val_dataset_path: 校驗用數據集的位置,需要輸入在容器內的完整路徑
(3) pretrained_model_path: 預訓練模型位置,需要輸入在容器內的完整路徑
(4) batch_size_per_gpu:請根據GPU顯存大小進行調整
(5) n_epochs:訓練的回合數
(6) n_workers:CPU的并行線程數,請根據實際CPU核數量進行調整
其余參數清先安裝范例所提供的設置。
3、eval_config:評估模型時所需要用到的參數,需要輸入在容器內的完整路徑
(1) eval_dataset_path: 測試用數據集路徑,與前面相同
(2) model_path: 在前面訓練模型過程中所生成的 .tlt 模型文件中,挑選效果最好的一個模型來進行評估,通常最后一個的效果會最好。這里的 “resnet_080.tlt” 是因為訓練回合數為 80。
其余參數請先按照范例所提供的設置。
以上關于路徑部分的設置,只要遵循腳本一開始 “0. Set up env variables and map drives” 的配置規則,文件里基本上不需要做修改。其他參數的定義與設定值,請訪問 https://docs.nvidia.com/tao/tao-toolkit/text/image_classification.html#model-config 有完整的說明。
數據集格式轉換與分配
TAO 支持的圖像分類數據格式,是以“分類名”作為路徑名,將所有該類的圖像都放置到分類名目錄之下,例如有 20 個分類的數據集,就會有 20 個分類目錄。
本實驗使用 PascalVOC 的 VOCtrainval_11-May-2012.tar (1.9GB) 數據集,可以用腳本提供的鏈接,也可以在https://pan.baidu.com/s/1JhnBCRi32xblhSSWFmF5aA (密碼: gg95) 下載壓縮文件。
請按照腳本的數據集處理過程,包括放置路徑與解壓縮的指令。由于這個數據集的格式并不符合 TAO 的要求,因此腳本中使用一段 Python 代碼來進行轉換,詳細內容請自行閱讀代碼,其主要功能就是將下圖左邊 VOC 路徑結構轉換成右邊符合 TAO 要求的結構,存放在 “formated” 目錄下。

接著再將 “formated” 的數據,隨機分割成 train、val與test 三大類存放到 “split” 目錄下,作為后面執行訓練、校驗與測試時所需要的數據路徑。
動遷移學習功能
TAO 的模型訓練繼承 TLT 的遷移學習功能,只要在配置文件中的“train_config” 配置組里,指定好 “pretrained_model_path:” 的路徑就可以,如果不想啟用這個功能,只要在這個參數前面用 “#” 去關閉就行。
在 NGC 提供 300 多個預訓練模型,我們需要挑選合適的模型來協助執行遷移學習,這部分的下載需要使用 NGC 的指令來操作,在腳本中已經提供完整的安裝步驟,只要執行命令塊就行,然后用以下指令去下載所選的模型:
ngc registry model download-version 模型全名 --dest 本地存放路徑
這里配合所使用的網絡種類,挑選 nvidia/tao/pretrained_classification:resnet18 作為本次的預訓練模型,文件大小在 80MB 左右。
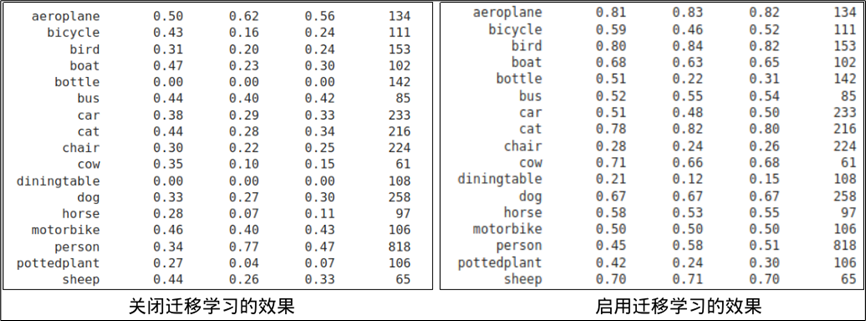
下圖左方是這個實驗中,關閉遷移學習功能所訓練出來的模型,經過下面評估步驟所測算出來的結果,下圖右方則是在基于 NGC 下載的預訓練模型基礎上,利用遷移學習功能所訓練出來的模型效果,總體來說得到的精準度提升還是很明顯的。
但如果是缺乏合適預訓練模型的狀況下,也不能硬是挑選不合適的模型來做遷移學習,可能得到的效果會更差。
執行模型訓練
當前面的準備工作都做到位之后,這個步驟就是水到渠成。執行訓練所耗費的時間就只跟 GPU 卡的總體計算資源有關系,如果您的設備有一張以上 GPU 計算卡的話,可以透過 TAO 指令以下參數,去調整可用的計算資源:
--gpus [N]:指定要調用的 GPU 卡數量;
--gpu_index 編號1 [編號2...]
例如設備上有 2 片 GPU 卡時,想要全部用上的話就直接用 “--gpus 2” 參數進行調用;如果設備上有 4 片 GPU 計算卡,想要指定調用 0 號與 3 號這兩張卡的時,就用 “--gpus 2--gpu_index 0 3” 參數,就能精準調用指定的GPU來進行訓練。
在這個圖像分類實驗中,我們以 NVIDIA RTX2070 與 RTX3070 進行測試,這兩張計算卡都具有 8GB 顯存。在固定回合數為 80、batch_size_per_gpu 為 64 的條件下,所耗費的訓練時間如下:
單GPU/3070-8G : 52分19秒
單GPU/2070-8G : 62分44秒
雙GPU/3070+2070 : 38分03秒
修剪模型
這個步驟的目的,是要在維持足夠精準度的前提下縮小模型的尺寸,越小的模型會消耗更少的計算資源,特別是內存與顯存。
這對于計算資源充沛的計算設備來說,所體現的差異并不明顯,但是對于計算資源相對吃緊的邊緣設備來說,就有非常大的影響,甚至影響推理識別的性能,因此請自行決定是否需要執行這個步驟。
這里的要剪裁的對象是已訓練好的模型,而不是從網絡結構層進行融合處理,最簡單的方法就是調整 “-pth(閾值)” ,在精確度與模型大小之間取得平衡,調整的值越高就會得到越小的模型,但精準度會受到比較大的損失,這就需要經過不斷嘗試去調節出滿足要求的模型。
以這個 classification 項目為例,在 80 回合中訓練的模型大小為 87.7MB,通常最后一回合訓練的模型精確度會最好,因此用 resnet_080.tlt 模型進行修剪測試:
-pth=0.6:修剪后生成大小為38.5MB的resnet18_nopool_bn_pruned.tlt
-pth=0.3:修剪后生成大小為44.2MB的resnet18_nopool_bn_pruned.tlt
至于修剪后模型對精確度產生怎樣的影響?就需繼續往下執行“再訓練”之后,看看評估的效果如何!
模型再訓練
經過修剪的模型并不能立即使用,而是作為“再訓練”的預訓練模型,再次利用遷移學習的技巧,以前面的數據集進行模型再訓練的工作,唯一不一樣的地方是這次使用的配置文件為 classification_retrain_spec.cfg,這個配置內容與前面的 classification_spec.cfg 只有三個差異的地方:
1. 在 model_config 設置組少了兩個 “freeze_blocks” 設置;
2. 在 train_config 設置組的 “pretrained_model_path” 換成前面修剪過的模型;
3. 在 eval_config 設置組的 “model_path” 換成修剪后重新訓練的模型
繼續往下執行 “7. Retrain pruned models” 與 “8. Testing the model” 兩個步驟,就能得到修剪過模型的精確度評估結果。
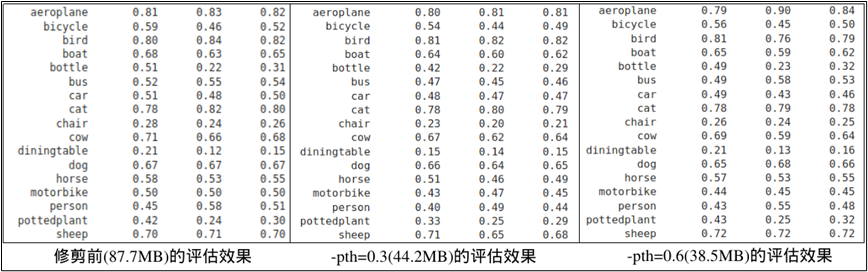
從上面的比較表中可以看出,這個剪裁的方式對模型文件大小的影響是很明顯的,但精確度的損失并不是太大,所以這個剪裁應視為有效果。
本實驗結語
這個范例主要讓大家體會并熟悉 TAO 的配置文件與執行流程,事實上 TAO 所提供的范例幾乎都是一樣的流程,后面還有導出模型、INT8 優化、生成 TensorRT 引擎的步驟,我們結合在后面的物件檢測范例中進行說明。
原文標題:NVIDIA Jetson Nano 2GB 系列文章(60):圖像分類的模型訓練與修剪
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
5267瀏覽量
105883 -
TAO
+關注
關注
0文章
10瀏覽量
7042 -
模型訓練
+關注
關注
0文章
20瀏覽量
1440
原文標題:NVIDIA Jetson Nano 2GB 系列文章(60):圖像分類的模型訓練與修剪
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
配置文件的差異介紹
Web Bluetooth SPP(串行端口配置文件)示例
DLPC3478怎么去做ini配置文件和firmware呢 ?
如何導出交換機的配置文件
linux網卡配置文件
docker-compose配置文件內容詳解以及常用命令介紹
springboot的項目如何既要用jar包啟動,同時還可以為不同的機房設置不同的配置文件

HID over GATT配置文件(HOGP)低功耗藍牙

InModbus2配置文件的注意事項
如何完成編輯配置文件來采集數據
如何遠程修改配置box文件?
Systemd是什么?Systemd Service配置文件詳解
鴻蒙開發Ability Kit程序框架服務:FA模型應用配置文件





 工商網監
工商網監
評論