") 如何優(yōu)化數(shù)據(jù)實現(xiàn)機器學(xué)習(xí)高數(shù)據(jù)吞吐量
如何優(yōu)化數(shù)據(jù)實現(xiàn)機器學(xué)習(xí)高數(shù)據(jù)吞吐量
譯者 | 李睿
作者:Bin Fan, InfoWorld
機器學(xué)習(xí)工作負載需要高效的基礎(chǔ)設(shè)施來快速產(chǎn)生結(jié)果,而模型訓(xùn)練非常依賴大型數(shù)據(jù)集。在所有機器學(xué)習(xí)工作流程中,第一步是將這些數(shù)據(jù)從存儲集中到訓(xùn)練集群,而這也會對模型訓(xùn)練效率產(chǎn)生顯著影響。
長期以來,數(shù)據(jù)和人工智能平臺工程師一直在考慮以下問題來管理數(shù)據(jù):
數(shù)據(jù)可訪問性:當(dāng)數(shù)據(jù)跨越多個來源并且數(shù)據(jù)被遠程存儲時,如何使訓(xùn)練數(shù)據(jù)可訪問?
數(shù)據(jù)管道:如何將數(shù)據(jù)作為一條管道進行管理,無需等待即可將數(shù)據(jù)持續(xù)輸入到訓(xùn)練工作流程中?
性能和GPU利用率:如何同時實現(xiàn)低元數(shù)據(jù)延遲和高數(shù)據(jù)吞吐量以保持GPU不會空閑?
本文將討論一種新的解決方案,它將用來協(xié)調(diào)端到端機器學(xué)習(xí)管道中的數(shù)據(jù)以解決上述問題。本文將概述常見的挑戰(zhàn)和陷阱,并推出編排數(shù)據(jù)這種新技術(shù),以優(yōu)化機器學(xué)習(xí)的數(shù)據(jù)管道。
模型訓(xùn)練中常見數(shù)據(jù)挑戰(zhàn)
端到端機器學(xué)習(xí)管道是從數(shù)據(jù)預(yù)處理、清理、模型訓(xùn)練再到推理的一系列步驟,其中模型訓(xùn)練是整個工作流程中最關(guān)鍵和最耗費資源的部分。
下圖是一個典型的機器學(xué)習(xí)管道。它從數(shù)據(jù)收集開始,然后是數(shù)據(jù)準備,最后是模型訓(xùn)練。在數(shù)據(jù)收集階段,數(shù)據(jù)平臺工程師通常需要花費大量時間讓數(shù)據(jù)工程師可以訪問數(shù)據(jù),數(shù)據(jù)工程師則需要為數(shù)據(jù)科學(xué)家準備數(shù)據(jù)以構(gòu)建和迭代模型。

訓(xùn)練階段需要處理大量數(shù)據(jù),以確保將數(shù)據(jù)持續(xù)提供給生成模型的GPU。你必須對數(shù)據(jù)予以管理,以支持機器學(xué)習(xí)及其可執(zhí)行架構(gòu)的復(fù)雜性。在數(shù)據(jù)管道中,每個步驟都會面臨相應(yīng)的技術(shù)挑戰(zhàn)。
(1)數(shù)據(jù)收集挑戰(zhàn)——數(shù)據(jù)無處不在
機器學(xué)習(xí)訓(xùn)練需要采用大型數(shù)據(jù)集,因此從所有相關(guān)來源收集數(shù)據(jù)至關(guān)重要。當(dāng)數(shù)據(jù)駐留在數(shù)據(jù)湖、數(shù)據(jù)倉庫和對象存儲中時,(無論是在內(nèi)部部署、在云中還是分布在多個地理位置)將所有數(shù)據(jù)組合到一個單一的源中不再可行。對于數(shù)據(jù)孤島,通過網(wǎng)絡(luò)進行遠程訪問不可避免地會導(dǎo)致延遲。因此如何在保持所需性能的同時使數(shù)據(jù)可訪問是一項重大挑戰(zhàn)。
(2)數(shù)據(jù)準備挑戰(zhàn)——序列化數(shù)據(jù)準備
數(shù)據(jù)準備從采集階段的數(shù)據(jù)開始,包括清理、ETL和轉(zhuǎn)換,然后交付數(shù)據(jù)以訓(xùn)練模型。如果沒有對這個階段全面考慮,那么數(shù)據(jù)管道是序列化的,且在等待為訓(xùn)練集群準備的數(shù)據(jù)時會浪費額外的時間。因此,平臺工程師必須弄清楚如何創(chuàng)建并行化的數(shù)據(jù)管道,并實現(xiàn)高效的數(shù)據(jù)共享和中間結(jié)果的高效存儲。
(3)模型訓(xùn)練挑戰(zhàn)——I/O與GPU未充分利用
模型訓(xùn)練需要處理數(shù)百TB的數(shù)據(jù),這些數(shù)據(jù)通常是大量的小文件,例如圖像和音頻文件等等。訓(xùn)練涉及需要多次epoch的迭代,從而頻繁訪問數(shù)據(jù)。通過不斷地向GPU提供數(shù)據(jù)來保持其忙碌是有必要的,同時優(yōu)化I/O并保持GPU所需的吞吐量也非易事。
傳統(tǒng)方法和常見陷阱
在討論不同的解決方案之前,先設(shè)定一個簡化的場景,如下圖所示。這里使用一個GPU集群在云中訓(xùn)練,該集群具有多個運行TensorFlow作為機器學(xué)習(xí)框架的節(jié)點。預(yù)處理數(shù)據(jù)存儲在Amazon S3中。通常,有兩種方法可以將此數(shù)據(jù)傳輸?shù)接?xùn)練集群,下文將予以討論。

方法一:在本地存儲中復(fù)制數(shù)據(jù)
在第一種方法中,整個數(shù)據(jù)集從遠程存儲復(fù)制到每個服務(wù)器的本地存儲進行訓(xùn)練,如下圖所示。因此,數(shù)據(jù)局部性得到保證,訓(xùn)練作業(yè)從本地讀取輸入,而不是從遠程存儲中檢索。
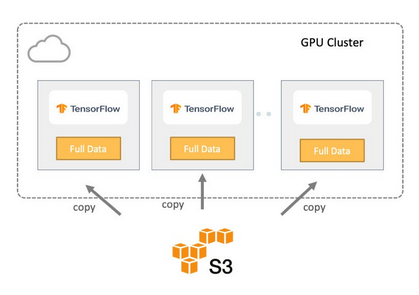
從數(shù)據(jù)管道和I/O的角度來看,這種方法提供了最高的I/O吞吐量,因為所有數(shù)據(jù)都是本地的。除了開始階段,GPU將保持忙碌,因為訓(xùn)練必須等待數(shù)據(jù)從對象存儲完全復(fù)制到訓(xùn)練集群。

但這種方法并不適用于所有情況。
首先,數(shù)據(jù)集必須適合聚合本地存儲。隨著輸入數(shù)據(jù)集大小的增長,數(shù)據(jù)復(fù)制過程變得更長且更容易出錯,從而浪費更多時間和GPU資源。
其次,將大量數(shù)據(jù)復(fù)制到每臺訓(xùn)練機上會對存儲系統(tǒng)和網(wǎng)絡(luò)造成巨大壓力。在輸入數(shù)據(jù)經(jīng)常變化的情況下,數(shù)據(jù)同步可能非常復(fù)雜。
最后,因為要使云存儲上的數(shù)據(jù)與訓(xùn)練數(shù)據(jù)保持同步,人工復(fù)制數(shù)據(jù)既費時又容易出錯。
方法二:直接訪問云存儲
另一種常見的方法是將訓(xùn)練與遠程存儲上的目標數(shù)據(jù)集直接連接起來,如下圖所示。這種方法與之前的解決方案一樣,數(shù)據(jù)集的大小不是問題,但也面臨著一些新的挑戰(zhàn)。

首先,從I/O和管道的角度來看,數(shù)據(jù)是串行處理的。所有的數(shù)據(jù)訪問操作都必須經(jīng)過對象存儲和訓(xùn)練集群之間的網(wǎng)絡(luò),使得I/O成為瓶頸。因此,由于I/O吞吐量受到網(wǎng)絡(luò)限制,GPU會等待并會浪費時間。
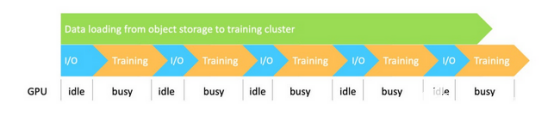
其次,當(dāng)訓(xùn)練規(guī)模較大時,所有訓(xùn)練節(jié)點同時從同一個遠程存儲訪問同一個數(shù)據(jù)集,給存儲系統(tǒng)增加了巨大的壓力。由于高并發(fā)訪問,存儲可能會變得擁擠,從而導(dǎo)致GPU利用率低。
第三,如果數(shù)據(jù)集包含大量的小文件,元數(shù)據(jù)訪問請求將占數(shù)據(jù)請求的很大一部分。因此,直接從對象存儲中獲取大量文件或目錄的元數(shù)據(jù)成為性能瓶頸,并增加了元數(shù)據(jù)的操作成本。
推薦的方法——編排數(shù)據(jù)
為了應(yīng)對這些挑戰(zhàn)和陷阱,在處理機器學(xué)習(xí)管道中的I/O時,需要重新考慮數(shù)據(jù)平臺架構(gòu)。在這里推薦一種加速端到端機器學(xué)習(xí)管道的新方法:數(shù)據(jù)編排。數(shù)據(jù)編排技術(shù)將跨存儲系統(tǒng)的數(shù)據(jù)訪問抽象化,同時將所有數(shù)據(jù)虛擬化,并通過標準化API和全局命名空間將數(shù)據(jù)呈現(xiàn)給數(shù)據(jù)驅(qū)動的應(yīng)用程序。
(1)使用抽象統(tǒng)一數(shù)據(jù)孤島
與其復(fù)制和移動數(shù)據(jù),留在原處也不失為上策,無論是在本地還是在云中。數(shù)據(jù)編排可以幫助抽象數(shù)據(jù)以創(chuàng)建統(tǒng)一的視圖。這將顯著降低數(shù)據(jù)收集階段的復(fù)雜性。
由于數(shù)據(jù)編排已經(jīng)可以與存儲系統(tǒng)集成,機器學(xué)習(xí)框架只需要與單個數(shù)據(jù)編排平臺交互即可訪問來自任何連接存儲的數(shù)據(jù)。因此,來自任何來源的數(shù)據(jù)都可以用來訓(xùn)練,從而提高模型質(zhì)量。同時,無需人工數(shù)據(jù)移動到中央源。包括Spark、Presto、PyTorch和TensorFlow在內(nèi)的所有計算框架都可以訪問數(shù)據(jù),而無需擔(dān)心數(shù)據(jù)的位置。
(2)在數(shù)據(jù)本地性方面使用分布式緩存
建議不要將整個數(shù)據(jù)集復(fù)制到每臺機器上,而是實施分布式緩存,其中數(shù)據(jù)可以均勻分布在集群中。當(dāng)訓(xùn)練數(shù)據(jù)集遠大于單個節(jié)點的存儲容量時,分布式緩存尤其有利。當(dāng)數(shù)據(jù)是來自遠程時,因為數(shù)據(jù)是在本地緩存的,它也可以提供助益。因為在訪問數(shù)據(jù)時沒有網(wǎng)絡(luò)I/O,機器學(xué)習(xí)訓(xùn)練會變得更快且更具成本效益。
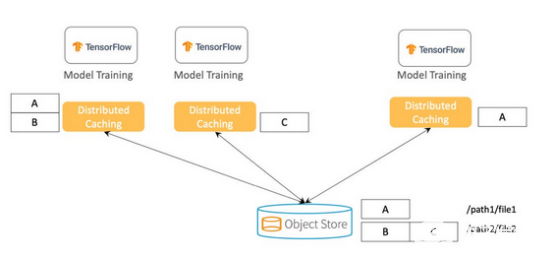
上圖顯示了存儲所有訓(xùn)練數(shù)據(jù)的對象存儲,以及表示數(shù)據(jù)集的兩個文件(/path1/file1和/path2/file2)。與其將所有文件塊存儲在每臺訓(xùn)練機器上,不如將塊分布在多臺機器上。為了防止數(shù)據(jù)丟失和提高讀取并發(fā)性,每個塊可以同時存儲在多個服務(wù)器上。
(3)優(yōu)化跨管道的數(shù)據(jù)共享
在機器學(xué)習(xí)(ML)訓(xùn)練作業(yè)中,作業(yè)內(nèi)部和作業(yè)之間執(zhí)行的數(shù)據(jù)讀取和寫入之間存在高度重疊。數(shù)據(jù)共享可以確保所有計算框架都可以訪問先前緩存的數(shù)據(jù),用于下一步的讀寫工作負載。例如,如果在數(shù)據(jù)準備步驟中使用Spark 進行ETL,數(shù)據(jù)共享可以確保輸出數(shù)據(jù)被緩存并可供下一階段使用。通過數(shù)據(jù)共享,整個數(shù)據(jù)管道獲得了更好的端到端性能。
(4)通過并行化數(shù)據(jù)預(yù)加載、緩存和訓(xùn)練來編排數(shù)據(jù)管道
可以通過執(zhí)行預(yù)加載和按需緩存來編排數(shù)據(jù)管道。如下圖顯示,使用數(shù)據(jù)緩存從源加載數(shù)據(jù)可以與實際訓(xùn)練任務(wù)并行完成。因此,在訪問數(shù)據(jù)時,訓(xùn)練受益于高數(shù)據(jù)吞吐量,而無需在訓(xùn)練前等待緩存完整數(shù)據(jù)。
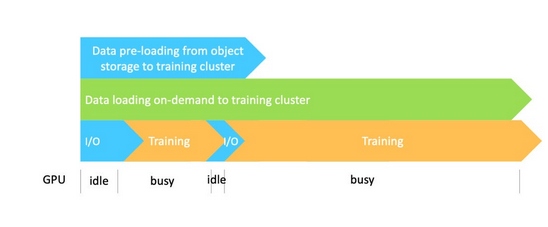
雖然一開始會有一些I/O延遲,但因為數(shù)據(jù)已經(jīng)加載到緩存中,等待時間會有所減少。這種方法可以減少重復(fù)步驟,從對象存儲到訓(xùn)練集群的數(shù)據(jù)加載、緩存、訓(xùn)練要求的數(shù)據(jù)加載以及訓(xùn)練都可以并行完成,從而大大加快整個過程。
通過跨機器學(xué)習(xí)管道的步驟編排數(shù)據(jù),可消除數(shù)據(jù)從一個階段流向下一個階段時串行執(zhí)行和相關(guān)的低效問題,同時也將具有較高的GPU利用率。下表將對這種新方法與兩種傳統(tǒng)方法進行比較:

如何為機器學(xué)習(xí)工作負載編排數(shù)據(jù)
這里以Alluxio為例,展示如何使用數(shù)據(jù)編排。同樣,我們還將使用上面提到的簡化場景。為了安排TensorFlow作業(yè),可使用Kubernetes或公共云服務(wù)。

使用Alluxio編排機器學(xué)習(xí)和深度學(xué)習(xí)訓(xùn)練通常包括三個步驟:
(1)在訓(xùn)練集群上部署Alluxio。
(2)掛載Alluxio作為本地文件夾來訓(xùn)練作業(yè)。
(3)使用訓(xùn)練腳本從本地文件夾(由Alluxio支持)加載數(shù)據(jù)。
不同存儲系統(tǒng)中的數(shù)據(jù)可以在掛載后通過Alluxio立即訪問,并且可以通過基準腳本透明訪問,無需修改TensorFlow。這顯著簡化了應(yīng)用程序開發(fā)過程,不然就需要集成每個特定的存儲系統(tǒng)以及憑證的配置。
可參照這里的方法使用Alluxio和TensorFlow運行圖像識別。
數(shù)據(jù)編排優(yōu)秀實踐
因為沒有一勞永逸的方法,所以數(shù)據(jù)編排最好在以下場景中使用:
需要分布式訓(xùn)練。
有大量的訓(xùn)練數(shù)據(jù)(10TB或更多),尤其是在訓(xùn)練數(shù)據(jù)中有很多小文件和圖像的情況下。
GPU資源沒有被網(wǎng)絡(luò)I/O充分占用。
管道使用許多數(shù)據(jù)源和多個訓(xùn)練/計算框架。
當(dāng)處理額外的訓(xùn)練請求時,底層存儲需要穩(wěn)定。
多個訓(xùn)練節(jié)點或任務(wù)使用相同的數(shù)據(jù)集。
隨著機器學(xué)習(xí)技術(shù)的不斷發(fā)展,框架執(zhí)行更復(fù)雜的任務(wù),管理數(shù)據(jù)管道的方法也將不斷改進。通過將數(shù)據(jù)編排擴展到數(shù)據(jù)管道,端到端訓(xùn)練管道的效率和資源利用率都可以得到提高。
-
人工智能
+關(guān)注
關(guān)注
1805文章
48843瀏覽量
247404 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8497瀏覽量
134222
發(fā)布評論請先 登錄
網(wǎng)卡吞吐量測試解決方案
優(yōu)化FPGA利用率和自動測試設(shè)備數(shù)據(jù)吞吐量參考設(shè)計
淺析敏捷高吞吐量衛(wèi)星通訊載荷
如何通過UBFS獲得流式ADC數(shù)據(jù)的最高吞吐量?
FF H1基于RDA的吞吐量優(yōu)化算法
防火墻術(shù)語-吞吐量
DM6467的吞吐量性能信息和系統(tǒng)芯片(SoC)架構(gòu)的詳細概述
AD7739:8通道、高吞吐量、24位Sigma-Delta ADC數(shù)據(jù)表

AD7731:低噪聲、高吞吐量24位Sigma-Delta ADC數(shù)據(jù)表
SAR ADC是如何實現(xiàn)更高數(shù)據(jù)吞吐量的
設(shè)計人員如何實現(xiàn) Wi-Fi 三頻段千兆網(wǎng)速和高吞吐量
GTC 2023主題直播:吞吐量可提高25%的Grace服務(wù)器

TMS320VC5510 HPI吞吐量和優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論