 Linux的內存管理是什么,Linux的內存管理詳解
Linux的內存管理是什么,Linux的內存管理詳解

Linux的內存管理
Linux的內存管理是一個非常復雜的過程,主要分成兩個大的部分:內核的內存管理和進程虛擬內存。內核的內存管理是Linux內存管理的核心,所以我們先對內核的內存管理進行簡介。
一、物理內存模型
?
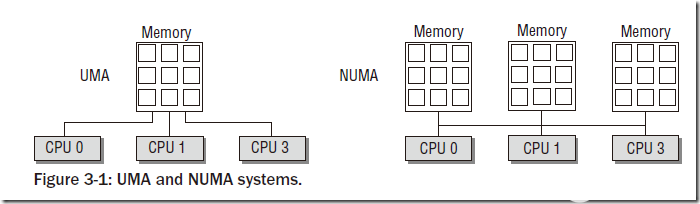
物理內存模型主要分為兩種:UMA(Uniform Memory Access)和NUMA(Non-Uniform Memory Access)。
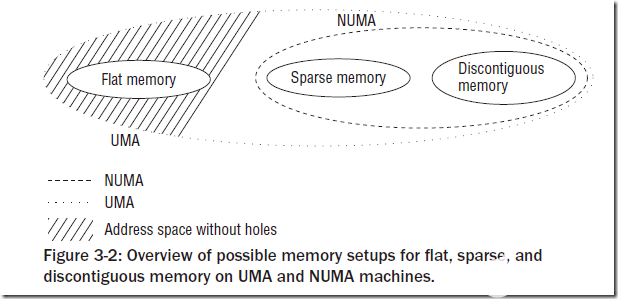
UMA模型是指物理內存是連續的,SMP系統中的每個處理器訪問各個內存區都是同樣快的;而NUMA模型則是指SMP中的每個CPU都有自己的物理內存區,雖然CPU可以訪問其他CPU的內存區,但是要比方位自己的內存區慢得多。我們一般使用的物理模型都是UMA模型。為了NUMA模型,Linux提供了三種可能的內存布局配置:Flat Memory, Sparse Memory, Discontiguous Memory。
?
Flat Memory就是簡單的線性組織物理內存,一般沒有內存空洞的UMA架構都采用這種配置。對于NUMA模型,一般只能采用后兩者,而后兩者的區別主要在于:Sparse Memory配置一般認為是試驗性的,不是那么穩定,但是有一些新的功能和性能優化,而Discontiguous Memory配置一般認為是穩定的,但不具有內存熱插拔之類的新特性。
二、物理內存組織
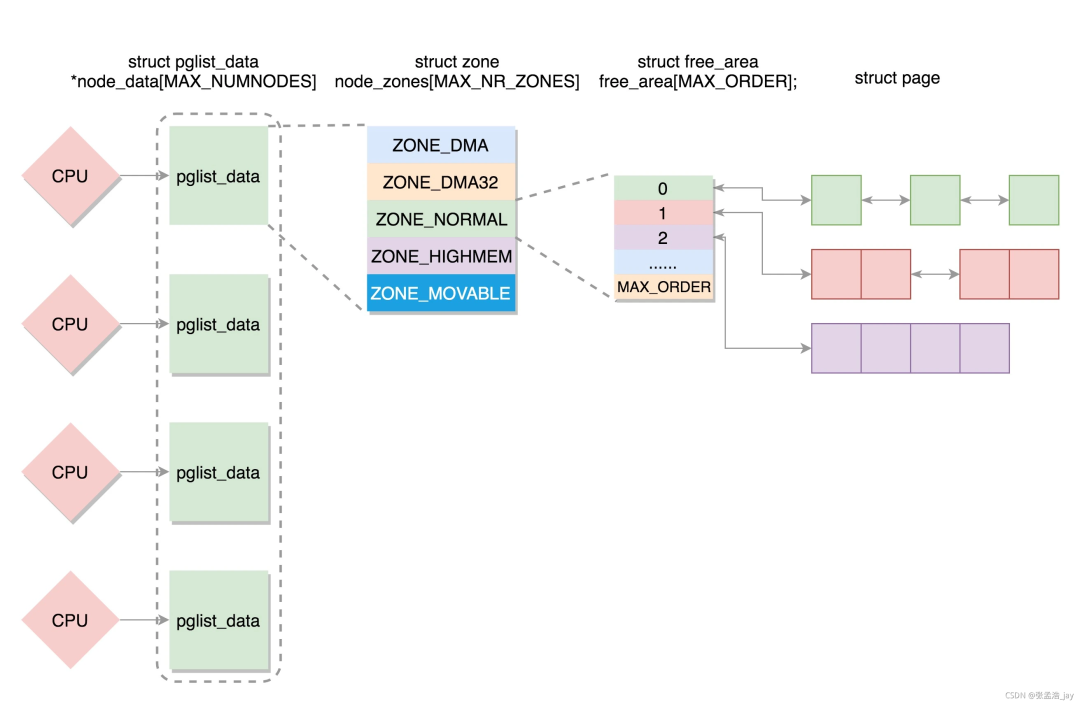
- 物理內存的組織主要分為兩個部分:節點(node)和內存與內存域(zone)。
- node主要針對NUMA設計,在NUMA的SMP系統中,每個處理器都有一個自己的node,而在UMA模型中則只有一個node。對于每個node中的內存,Linux分成了若干內存域,定義在mmzone.h的zone_type中,常用的有ZONE_DMA、ZONE_DMA32、ZONE_NORMAL、ZONE_HIGHMEM和ZONE_MOVABLE。其中ZONE_NORMAL是最為常用的,表示內核能夠直接映射的一般內存區域;ZONE_DMA表示DMA內存區;ZONE_DMA32表示64位系統中對于32位DMA設備使用的內存;ZONE_HIGHMEM表示在32位系統中,高地址內存的區域;ZONE_MOVABLE與伙伴系統的內存碎片消除有關。后文會詳細介紹相關部分。
- 在物理內存管理過程中有一些名詞:
- Page Frame(頁幀,或稱頁框):是系統內存管理的最小單位,系統中每個頁框都是struct page的一個實例。IA-32系統的頁框大小是4KB。
- Hot-n-Code Pages(冷熱頁):是指內存管理中對頁框的分類,訪問較多的或者近期訪問的為熱頁,否則為冷頁。該標記主要與內存換出(memory swap)相關。
- Page Table(頁表):是內存尋址過程中的輔助數據結構。層次化的頁表對于大地之空間的快速、高效管理很有意義。Linux一般支持四級頁表:PGD(Page Global Directory)、PUD(Page Upper Directory)、PMD(Page Middle Directory)和PTE(Page Table Entry)。IA-32體系中默認只是用了兩級分頁系統,即只有PGD和PTE。
三、X86架構下的內存布局
內核在內存中的布局
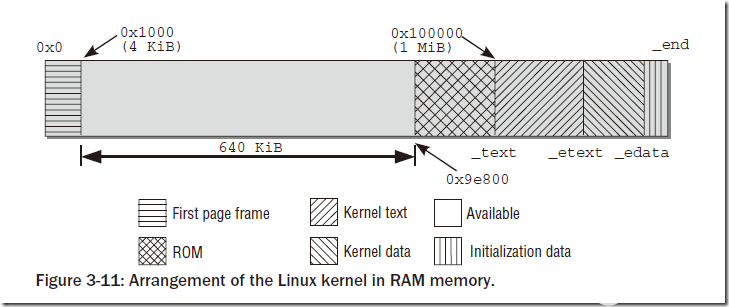
Linux的內核在初始化的時候會被加載到內存區的固定位置(在此我們不討論可重定位內核的情況),而內核所占用的內存區域的布局是固定的,如圖:
?
內存第一個頁框不實用,主要被BIOS用來初始化;之后的連續640KB內存也不被內核使用,主要用來映射各種ROM(通常是BIOS和顯卡ROM);再之后的空間是閑置的,原因是內核要被放在連續的內存空間。在0x100000開始為內核部分,分別是代碼段、數據段和附加段。
IA-32架構的布局
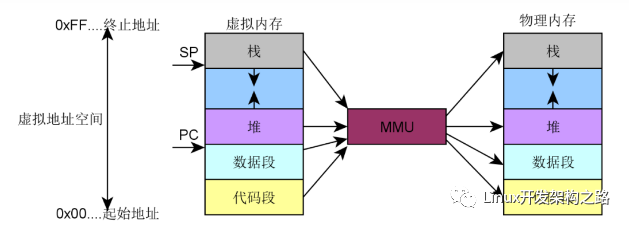
IA-32架構可以訪問4GB的地址空間(不考慮PAE),常規情況下會將4GB線性空間劃分成3:1的兩部分:低地址的3/4部分為用戶空間,而高地址的1GB是內核空間,即內核地址空間從偏移量0xC0000000開始,每個虛擬地址x都對應于物理地址x-0xC0000000。這樣的設計加快了內核空間尋址的速度(簡單的減法操作)。在進程切換的過程中,只有用戶空間的低3GB內存對應的頁表會被切換,高地址空間會公用內核頁表。
IA-32架構的這種設計存在著一個問題:既然內核只能處理1GB的空間(事實上,內核處理的空間還不足1GB,后面會詳細說明),那么如果物理內存大于1GB,剩下的內存將如何處理?這種情況下,內核將無法直接映射全部物理內存,這樣就用到了上面所說的高地址內存域(ZONE_HIGHMEM)。具體的內存分配如下圖:

?
能夠看到內核區域的映射從__PAGE_OFFSET(0xC00000)開始,即3GiB位置開始映射到4GiB,開始的一段用來直接映射,而后面有128MB的VMALLOC空間(這部分空間的使用后文將講到),再之后有永久映射和固定映射的空間(從PKMAP_BASE開始)。所以事實上物理內存能夠直接映射的空間為1GB-VMALLOC-固定映射-永久映射,所以真正大約只有850MB多一點,也就是說,物理內存中只有前850多MB是可以直接映射到內核空間的,對于超過的部分來說,將作為高地址空間(HIGHMEM)。高地址空間可以在VMALLOC、永久映射和固定映射部分使用到。
到這里可能會有這樣一個疑問:如果內核只能處理896MB的空間,那么如果內存很大(比如3GB),剩下的空間的利用率和利用效率豈不是很低?對于這個問題我們需要注意:這里我們所講述的:1、這里的內存都是內核在內核區的1GB空間里對物理內存的訪問,用戶對物理內存的訪問不是通過直接映射來訪問的,還有另外一套機制;2、這里的內存僅僅是通過直接映射得到的內存,內核還可以通過其他的方式訪問到較高地址的內存。
還有一個普遍的疑問就是:內核直接映射占用了800多MB的空間,那么如果我們又3GB的物理內存,是不是只有2GB多一點的實際可用內存呢?這個說法是錯誤的,上圖所描述的只是內核在線性地址空間的分布情況,其中的任何區域如果沒有真正的物理內存與之映射的話是不會真正占用物理內存的,而物理內存在分配的過程中(用戶申請內存、VMALLOC部分等),更傾向于先分配高地址內存,在高地址內存耗盡的情況下才會使用低850MB內存。
AMD64架構的布局
AMD64架構采用了與IA-32完全不同的布局模式。由于64位的尋址空間的64位長,而在真正的實現過程中64位長尋址會造成較大的開銷,所以Linux目前僅適用了48位長的地址空間,但是為了向后兼容仍然適用64位地址空間表示。在布局方面考慮,如果單純采用48位類似IA-32的布局方式的話,則很難保證向后兼容性。所以AMD64架構下的內存布局Linux采用了一種特殊的方式,如圖:

?
Linux將內存分成了高地址部分和低地址部分兩部分,即下半部空間0~0x0000 7FFF FFFF FFFF和上半部空間0xFFFF 8000 0000 0000~0xFFFF FFFF FFFF FFFF。可以看到虛擬地址的低47位,即[0,46]為有效位,[47,63]的值總是相同的:或者全為0或者全為1。除此之外的值都是無效的。這樣在虛擬內存空間中就將內存分成了兩個部分:內存空間的下半部和上半部。下半部為用戶空間,上半部為內核空間。我們考慮內核空間部分,下半部的前MAXMEM大小(64TB)為直接映射地址,之后有一個空洞,主要目的是處理內存訪問越界;再之后是大小為32TB的VMALLOC空間,在之后是VMMEMMAP空間、KERNEL TEXT段空間以及Modules空間。
在這里我們不仔細講述AMD64架構的布局,以后的部分則主要關注于IA-32架構。
四、啟動過程期間的內存管理
在啟動過程中,盡管內存管理尚未初始化,但內核仍然需要分配內存以創建各種數據結構。bootmem分配器用于在啟動階段早期分配內存。由于對這部分內存分配集中于簡單性方面而不是性能和通用性,因此使用的是最先適配(first-fit)分配器。該分配器使用一個位圖來管理頁,位圖中的1表示頁已使用,0表示未使用。在需要分配內存時,分配器掃描位圖,直到找到一個能夠提供足夠連續頁的為之,即最先最佳(first-best)或最先適配位置。
在這個分配過程中,需要處理一些不可分配的頁面,如IA-32系統中的0頁。另外對于IA-32系統,bootmem僅僅使用了低地址部分,對于高地址部分的操作過于麻煩,所以在這里被放棄了。
在這個部分有一個很有意思的事情。我們在編寫內核模塊的時候,對于模塊的初始化函數會使用__init標記或者__init_data標記。對于被這兩個關鍵字標記的函數和數據,是只有在初始化階段才用到的,在bootmem退出的時候會全部被回收。而這部分代碼和數據再內核鏈接的過程中將會被放在.init.text段和.init.data段,并統一放在內核的尾部,在啟動結束后便于回收。
五、物理內存的管理
1、伙伴系統
物理內存管理中伙伴系統是最為重要的一個系統,伙伴系統也基于一種相對簡單然而令人吃驚的強大算法,到目前已經使用了幾乎40年。伙伴系統在這里不再贅述,簡單谷歌一下就可以查到該算法的描述(實在是很簡單)。在這里主要講一下Linux Kernel的伙伴系統以及在2.6.24之后版本的系統中對伙伴系統的改良。
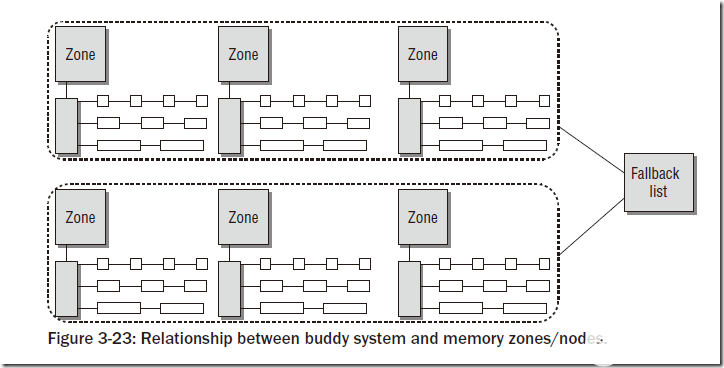
在上文中已經說到,物理內存的慣例分為若干個node,每個node中又有若干個zone。對于每個zone,都會有對應的伙伴系統,如下圖所示:
?
上圖中的Fallback list指的是:在多個node的系統中,如果某個node的內存空間不夠,則會在Fallback List中指定的node中分配內存。
我們可以執行cat /proc/buddyinfo,能夠看到大約如下所示的信息:
/proc/buddyinfo:
wolfgang@meitner> cat /proc/buddyinfo
Node 0, zone DMA 3 5 7 4 6 3 3 3 1 1 1
Node 0, zone DMA32 130 546 695 271 107 38 2 2 1 4 479
Node 0, zone Normal 23 6 6 8 1 4 3 0 0 0 0
顯示的三個域則是我們使用到的內存域。
伙伴系統會出現一個很常見的問題:在系統使用較長時間之后,內存中經常出現較多碎片。對于這種情況,內核將內存頁面分成五種類型:
MIGRATE_UNMOVABLE
MIGRATE_RECLAIMABLE
MIGRATE_RESERVE
MIGRATE_MOVABLE
MIGRATE_ISOLATE
其中MIGRATE_RESERVE所表示的內存是被系統保留以備急用的;MIGRATE_UNMOVABLE是不可移動的,如BIOS信息頁;MIGRATE_RECLAIMABLE在swap系統中使用;MIGRATE_ISOLATE表示不能從這里分配的內存;MIGRATE_MOVABLE表示可以移動的內存。對于內核來說,MIGRATE_MOVABLE部分的內存可以采用某種算法來進行移動,使得內存中的碎片減少。另外內核還維護了一個fallback list,來表示如果在某個類型中分配頁面未成功,會在哪些類型的頁面中來分配。
具體的信息可以在/proc/pagetypeinfo中看到
2、伙伴系統的內存分配API
基本上從如下兩張圖就能夠看出來:
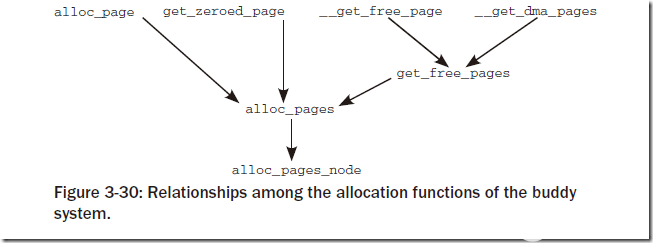
?
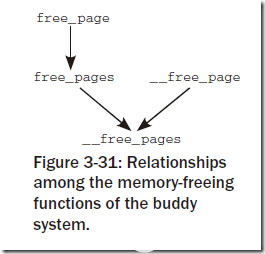
?
對于其中的函數命名基本都是自明的,主要的差別在于:對于雙下劃線開頭的函數(__get_free_page, __free_page等)返回值或者參數為struct page *,而其他的函數返回值為unsigned long,即線性地址地址。
3、內核中不連續頁的分配
根據上文的講述,我們知道物理上連續的映射對內核是最好的,但并不是總能成功的使用。所以內核提供了類似用戶空間訪問內存一樣的機制(vmalloc)來進行對內核中不連續頁的分配。這一部分就是上文中所說的vmalloc區域。這部分主要是一個vmalloc函數:
void *vmalloc(unsigned long size);
在該函數的實現過程中,需要先申請一部分虛擬內存空間vm_area,然后將這部分空間映射到vmalloc區域中。對于映射的物理內存,內核更傾向于使用高地址空間(ZONE_HIGHMEM),來節省寶貴的地地址空間。對于不同vmalloc調用申請的vm_area之間,會有一個hole來隔離,以避免越界訪問。
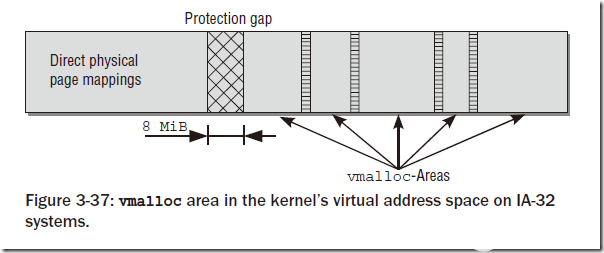
?
注意vmalloc系統底層也是使用伙伴系統來分配內存,所以申請內存的大小只能是整頁的(頁大小對齊)。
在這部分有一個有意思的事情:vmalloc區域在IA-32中預設的大小是128MB,這部分內存一般會被內核模塊使用。vmalloc區域的大小是可以定制的,在新版內核中可以在內核啟動選項中加入vmalloc=xxxMB的方式來修改,或者修改內核代碼對應的宏:
unsigned int __VMALLOC_RESERVE = 128 << 20;
如果修改了vmalloc區域的大小,那么內核能夠直接映射的區域將會縮小,即kmalloc能夠使用的內存將會變少(kmalloc使用slab allocator分配,后文將會介紹),但是內核真正使用的物理內存和vmalloc區域的大小沒有直接關系。所以在內核模塊的編寫過程中,要根據需求來使用vmalloc和kmalloc,而了解他們的內存分配機制是很有好處的。
4、內核映射
盡管vmalloc函數族可用于從高端內存向內核映射頁框,但這并不是這些函數的實際用途。內核提供了其他函數用于將ZONE_HIGHMEM頁框顯式的映射到內核空間。
如果需要長期的將高端頁框映射到內核地址空間中,即持久映射,需要使用kmap函數,映射的空間指向上文圖中所指Persistent Mapings。內核使用kunmap接觸映射。持久映射kmap函數不能用于處理中斷處理程序,因為kmap過程可能進入睡眠狀態。
為了能夠原子的執行映射過程(邏輯上稱為kmap_atomic),內核提供了臨時映射機制,也被稱作固定映射,頁面也會被映射到Fixmaps區域。映射的API分別是kmap_atomic和kunmap_atomic。固定映射可以用在中斷處理程序中。
對于不支持高端內存的體系結構(如64位體系結構),則將以上若干映射函數通過預編譯選項指向了對應的兼容函數。事實上對于這些體系結構的映射,都是簡單的返回對應的內存地址即可,因為內核可以在直接映射區域簡單的找到對應的地址。
六、slab分配器
上面所描述的物理內存管理機制中,最小粒度的內存管理單元是頁框,大小一般是4KB,而在內存中無論何時申請內存都分配一個頁面是不合適的方式,所以引入了新的管理機制,即slab分配器。Slab是Sun公司的一個雇員Jeff Bonwick在Solaris 2.4中設計并實現的。slab分配器將大小相同的內核對象放在一起,當對象被free了之后并不是直接還給伙伴系統,而是將這部分對象的頁面保存下來,在下一次該類對象的內存申請時分配給新的對象。這種機制的優勢在于:1、能夠按照CPU緩存的大小來組織分配對象的位置,一般來說,都會將若干個相同的對象放在一個cacheline中,并且對象占用的內存不會跨越兩個cacheline。這樣的設計能夠保證slab分配器分配的對象能夠較多時間的存在于CPU緩存中。2、采用LIFO方式管理對象。這種做法基于:最近釋放的對象空間是最有可能存在于cache中的。這也能夠有效的利用cache。
各個緩存管理的對象,會合并為較大的組,覆蓋一個或者多個連續的頁框。這種組稱作slab,每個緩存由幾個這種slab組成。這也是slab分配器命名的由來。
1、slab、slob、slub分配器
Linux內核中目前支持三種分配器,其中slab前文已經簡單介紹過了,另外兩種分配器是備選分配器,可以在內核編譯選項中指定。由于對上層提供的API是固定的,僅僅是底層實現不同,所以Kernel開發者不必去考慮底層的分配情況。
slab分配器雖然有很大的優勢,但是其存在兩個問題:1、在較小的內存系統下,slab分配器過于復雜。如嵌入式環境下slab顯得有些過于龐大。2、在內存很大的巨型機上,slab分配器本身的數據結構所占用的內存空間過大,最大的可高達2GB以上。
對于前一種情況,設計了slob分配器,它圍繞一個simple linked list of block展開(也是slob的由來),在分配內存的時候,采用了最先適配算法(first-fit)。
對于后一種情況,設計了slub分配器,slub分配器將頁框打包為組,并通過struct page中未使用的字段來管理這些組,試圖最小化內存開銷。slub分配器事實上是基于slab分配器的一種優化結構。在大型機上slub分配器上有著更好的性能。
2、slab分配器的原理
內核中一般的內存分配和釋放的函數有kmalloc、kzalloc、kcalloc。這三個函數的區別是:kmalloc僅僅申請一片空間,kzalloc在申請一篇空間之后將其置0。kcalloc很少用,即對數組進行空間分配并置0。
所有活動的slab緩存可以通過cat /proc/slabinfo來看到。
slab分配器由一個緊密交織的數據和內存結構的網絡組成,主要可以分為如圖的兩部分:保存管理型數據的緩存對象和保存被管理對象的各個slab。
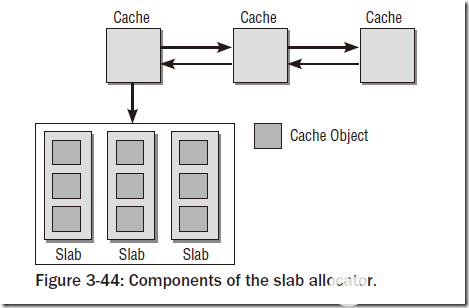
?
每個slab緩存只負責一種對象類型,或者提供一般性的緩沖區。下圖中給出了緩存的精細結構:
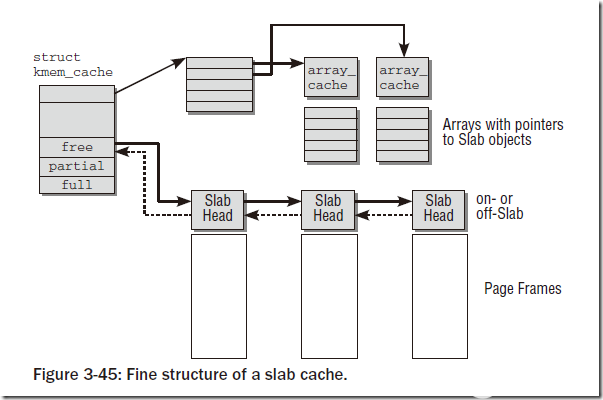
?
可以看到對于每個slab緩存,都會保存成一個struct kmem_cache,每個結構里面包含一個穿在一起的鏈表,以及三個鏈表頭:free、partial、full,分別表示空閑鏈、部分空閑鏈和滿鏈。含義和字面意思相同。對象在slab中并不是連續排列的,用戶可以要求對象按硬件緩存對齊,也可以要求按照BYTES_PER_WORD對齊,該值表示void指針所需的字節的數目。
創建新的slab緩存需要調用kmem_cache_create函數,返回struct kmem_cache結構。創建緩存的時候需要制定緩存的可讀name(會出現在/proc/slabinfo中),還需要制定被管理對象以字節計的長度(size),在對齊數據時使用的偏移量(align),以及flags標志。另外還需要制定構造/析構函數ctor/dtor。
分配對象時調用kmem_cache_alloc,函數需要指定創建過的slab緩存,以及flags。內核支持的所有GFP_xxx宏都可以用于指定標志。
下圖顯示了分配對象的過程:
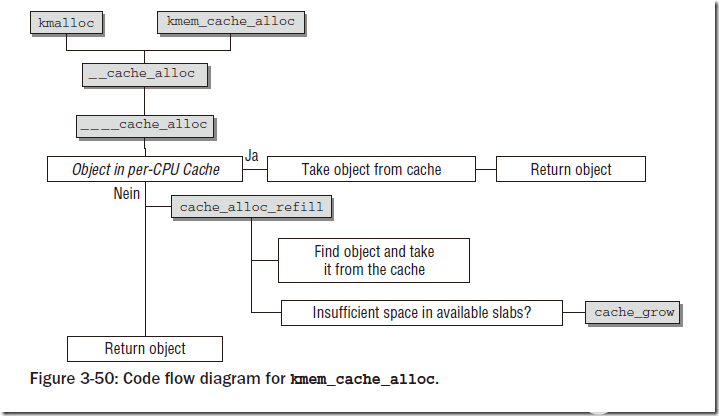
?
3、通用緩存
如果不涉及對象緩存,而是傳統意義上的分配/釋放內存,則需要調用kmalloc和kfree函數,而這兩個函數的后端依然是使用slab分配器進行分配的。kmalloc的基礎是一個數組,其中是一些分別用于不同內存長度的slab緩存,數組項是cache_sizes的實例。該數據結構定義如下:
struct cache_sizes {
size_t cs_size;
kmem_cache_t *cs_cachep;
kmem_cache_t *cs_dmacachep;
#ifdef CONFIG_ZONE_DMA
struct kmem_cache *cs_dmacachep;
#endif
}
cs_size指定了該項負責的內存區的長度。每個長度對應兩個slab緩存,其中之一提供適合DMA訪問的內存。通過cat /proc/slabinfo中能夠看到,kmalloc-xxx和dma-kmalloc-xxx就是這一部分提供的。
kmalloc定義在,該函數首先檢查所需的緩存是否用常數來指定,如果是這種情況,所需的緩存可以在編譯時靜態確定,這可以提高速度(內核的優化真是無所不用其極!!)。否則,該函數調用__kmalloc查找長度匹配的緩存,后者是__do_kmalloc的前端,提供參數轉換功能。
mm/slab.c
void *__do_kmalloc(size_t size, gfp_t flags)
{
kmem_cache_t *cachep;
cachep = __find_general_cachep(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return NULL;
return __cache_alloc(cachep, flags);
}
__find_general_cachep在上文提到的緩存中找到適當的一個,之后使用__cache_alloc函數完成最終的分配。
七、處理器高速緩存和TLB控制
在這里簡單的總結一些Kernel中和TLB/高速緩存相關的函數,具體TLB的實現機制與體系架構相關性很大,就不詳細總結了。
flush_tlb_all和flush_cache_all刷出整個TLB/高速緩存。此操作只在操縱內核頁表時需要,因為此類修改不僅影響所有進程,而且影響系統中的所有處理器。
flush_tlb_mm(struct mm_struct *mm)和flush_cache_mm刷出所有屬于地址空間mm的TLB/高速緩存項。
flush_tlb_range(struct vm_area_struct *vma, unsigned long start, unsigned long end)和flush_cache_range(vma, start, end)刷出地址范圍vma->vm_mm中虛擬地址start和end之間的所有TLB/高速緩存項。
flush_tlb_page(struct vm_area_struct *vma, unsigned long page) 和flush_cache_page(vma, page)刷出虛擬地址在[page, page + PAGE_SIZE]范圍內所有的TLB/高速緩存項。
update_mmu_cache(struct vm_area_struct *vma, unsigned long address, pte_t pte)在處理頁失效之后調用。它在處理器的內存管理單元MMU中加入信息,是的虛擬地址address由頁表項pte描述。僅當存在外部MMU時才需要該函數,通常MMU集成在處理器內部。
此外,flush_cache_和flush_tlb_函數常常成對出現,例如,在使用fork進程復制進程的地址空間時,則:1、刷出高速緩存,2、操作內存,3、刷出TLB。這個順序很重要,因為
如果順序相反,那么在TLB刷出之后,正確信息提供之前,多處理器系統中的另一個CPU可能從進程的頁表項取得錯誤的信息。
在刷出高速緩存時,某些體系結構需要依賴TLB中的“虛擬->物理”轉換規則。flush_tlb_mm必須在flush_cache_mm之后執行以確保這一點。
小結
這部分東西實在是太多,簡單的總結一下就已經這么多了。在這里對以上的內容進行一個簡單的概括。
在內核進入正常運行之后,內存管理分為兩個層次:伙伴系統負責物理頁框的管理。在伙伴系統之上,所有的內存管理都基于此,主要分為:slab分配器處理小塊內存;vmalloc模塊為不連續物理頁框提供映射;永久映射區域和固定映射區域提供對高地址物理頁框的訪問。
內存管理的初始化很具有挑戰性,內核通過引入一個非常簡單的自舉內存分配器(bootmem)解決了該問題,該分配器在正式的分配機制(伙伴系統)啟用后停用。
審核編輯:符乾江
-
Linux
+關注
關注
87文章
11511瀏覽量
213852 -
文件系統
+關注
關注
0文章
296瀏覽量
20400 -
內存管理
+關注
關注
0文章
168瀏覽量
14569 -
虛擬內存
+關注
關注
0文章
78瀏覽量
8260
發布評論請先 登錄
Linux kernel內存管理模塊結構分析
走進Linux內存系統探尋內存管理的機制和奧秘
Linux內核內存管理架構解析







 工商網監
工商網監
評論