") StyleGAN在圖像質量和可控性方面為生成模型樹立了新的標桿
StyleGAN在圖像質量和可控性方面為生成模型樹立了新的標桿
StyleGAN-XL 首次在 ImageNet 上實現(xiàn)了 1024^2 分辨率圖像合成。
近年來,計算機圖形學領域的研究者一直致力于生成高分辨率的仿真圖像,并經歷了一波以數(shù)據(jù)為中心的真實可控內容創(chuàng)作浪潮。其中英偉達的 StyleGAN 在圖像質量和可控性方面為生成模型樹立了新的標桿。
但是,當用 ImageNet 這樣的大型非結構化數(shù)據(jù)集進行訓練時,StyleGAN 還不能取得令人滿意的結果。另一個存在的問題是,當需要更大的模型時,或擴展到更高的分辨率時,這些方法的成本會高得令人望而卻步。
比如,英偉達的 StyleGAN3 項目消耗了令人難以想象的資源和電力。研究者在論文中表示,整個項目在 NVIDIA V100 內部集群上消耗了 92 個 GPU year(即單個 GPU 一年的計算)和 225 兆瓦時(Mwh)的電力。有人說,這相當于整個核反應堆運行大約 15 分鐘。
最初,StyleGAN 的提出是為了明確區(qū)分變量因素,實現(xiàn)更好的控制和插值質量。但它的體系架構比標準的生成器網(wǎng)絡更具限制性,這些限制似乎會在諸如 ImageNet 這種復雜和多樣化的數(shù)據(jù)集上訓練時帶來相應代價。
此前有研究者嘗試將 StyleGAN 和 StyleGAN2 擴展到 ImageNet [Grigoryev et al. 2022; Gwern 2020],導致結果欠佳。這讓人們更加相信,對于高度多樣化的數(shù)據(jù)集來說,StyleGAN 可能會從根本上受到限制。
受益于更大的 batch 和模型尺寸,BigGAN [Brock et al. 2019] 是 ImageNet 上的圖像合成 SOTA 模型。最近,BigGAN 的性能表現(xiàn)正在被擴散模型 [Dhariwal and Nichol 2021] 超越。也有研究發(fā)現(xiàn),擴散模型能比 GAN 實現(xiàn)更多樣化的圖像合成,但是在推理過程中速度明顯減慢,以前的基于 GAN 的編輯工作不能直接應用。
此前在擴展 StyleGAN 上的失敗嘗試引出了這樣一個問題:架構約束是否從根本上限制了基于 Style 的生成器,或者 missing piece 是否是正確的訓練策略。最近的一項工作 [Sauer et al. 2021] 引入了 Projected GAN,將生成和實際的樣本投射到一個固定的、預訓練的特征空間。重組 GAN 設置這種方式顯著改進了訓練穩(wěn)定性、訓練時間和數(shù)據(jù)效率。然而,Projected GAN 的優(yōu)勢只是部分地延伸到了這項研究的單模態(tài)數(shù)據(jù)集上的 StyleGAN。
為了解決上述種種問題,英偉達的研究者近日提出了一種新的架構變化,并根據(jù)最新的 StyleGAN3 設計了漸進式生長的策略。研究者將改進后的模型稱為 StyleGAN-XL,該研究目前已經入選了 SIGGRAPH 2022。
論文地址:https://arxiv.org/pdf/2202.00273.pdf
代碼地址:https://github.com/autonomousvision/stylegan_xl
這些變化結合了 Projected GAN 方法,超越了此前在 ImageNet 上訓練 StyleGAN 的表現(xiàn)。為了進一步改進結果,研究者分析了 Projected GAN 的預訓練特征網(wǎng)絡,發(fā)現(xiàn)當計算機視覺的兩種標準神經結構 CNN 和 ViT [ Dosovitskiy et al. 2021] 聯(lián)合使用時,性能顯著提高。最后,研究者利用了分類器引導這種最初為擴散模型引入的技術,用以注入額外的類信息。
總體來說,這篇論文的貢獻在于推動模型性能超越現(xiàn)有的 GAN 和擴散模型,實現(xiàn)了大規(guī)模圖像合成 SOTA。論文展示了 ImageNet 類的反演和編輯,發(fā)現(xiàn)了一個強大的新反演范式 Pivotal Tuning Inversion (PTI)[ Roich et al. 2021] ,這一范式能夠與模型很好地結合,甚至平滑地嵌入域外圖像到學習到的潛在空間。高效的訓練策略使得標準 StyleGAN3 的參數(shù)能夠增加三倍,同時僅用一小部分訓練時間就達到擴散模型的 SOTA 性能。
這使得 StyleGAN-XL 能夠成為第一個在 ImageNet-scale 上演示 1024^2 分辨率圖像合成的模型。
將 StyleGAN 擴展到 ImageNet
實驗表明,即使是最新的 StyleGAN3 也不能很好地擴展到 ImageNet 上,如圖 1 所示。特別是在高分辨率時,訓練會變得不穩(wěn)定。因此,研究者的第一個目標是在 ImageNet 上成功地訓練一個 StyleGAN3 生成器。成功的定義取決于主要通過初始評分 (IS)[Salimans et al. 2016] 衡量的樣本質量和 Fréchet 初始距離 (FID)[Heusel et al. 2017] 衡量的多樣性。
在論文中,研究者也介紹了 StyleGAN3 baseline 進行的改動,所帶來的提升如下表 1 所示:
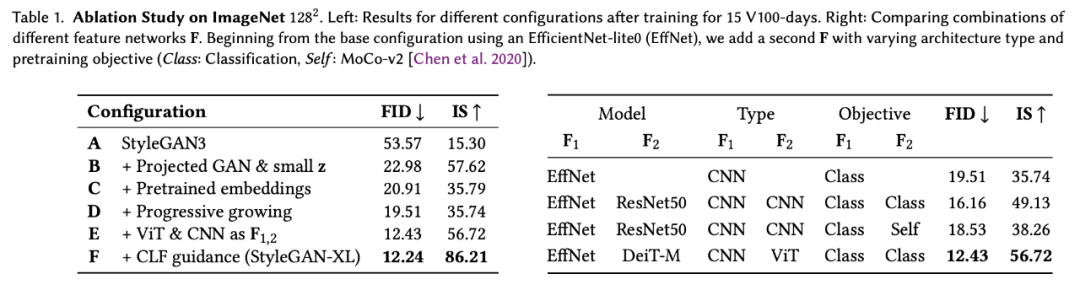
研究者首先修改了生成器及其正則化損失,調整了潛在空間以適應 Projected GAN (Config-B) 和類條件設置 (Config-C);然后重新討論了漸進式增長,以提高訓練速度和性能 (Config-D);接下來研究了用于 Projected GAN 訓練的特征網(wǎng)絡,以找到一個非常適合的配置 (Config-E);最后,研究者提出了分類器引導,以便 GAN 通過一個預訓練的分類器 (Config-F) 提供類信息。
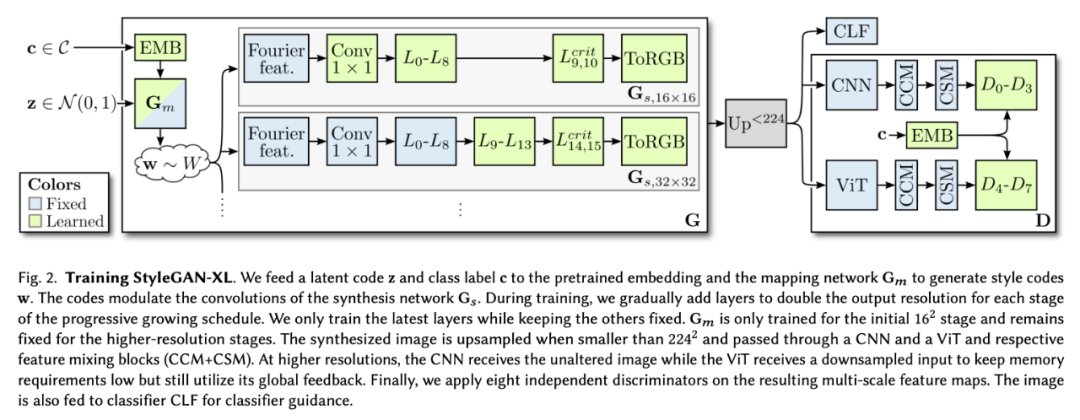
這樣一來,就能夠訓練一個比以前大得多的模型,同時需要比現(xiàn)有技術更少的計算量。StyleGAN-XL 在深度和參數(shù)計數(shù)方面比標準的 StyleGAN3 大三倍。然而,為了在 512^2 像素的分辨率下匹配 ADM [Dhariwal and Nichol 2021] 先進的性能,在一臺 NVIDIA Tesla V100 上訓練模型需要 400 天,而以前需要 1914 天。(圖 2)。
實驗結果
在實驗中,研究者首先將 StyleGAN-XL 與 ImageNet 上的 SOTA 圖像合成方法進行比較。然后對 StyleGAN-XL 的反演和編輯性能進行了評價。研究者將模型擴展到了 1024^2 像素的分辨率,這是之前在 ImageNet 上沒有嘗試過的。在 ImageNet 中,大多數(shù)圖像的分辨率較低,因此研究者用超分辨率網(wǎng)絡 [Liang et al. 2021] 對數(shù)據(jù)進行了預處理。
圖像合成
如表 2 所示,研究者在 ImageNet 上對比了 StyleGAN-XL 和現(xiàn)有最強大的 GAN 模型及擴散模型的圖像合成性能。
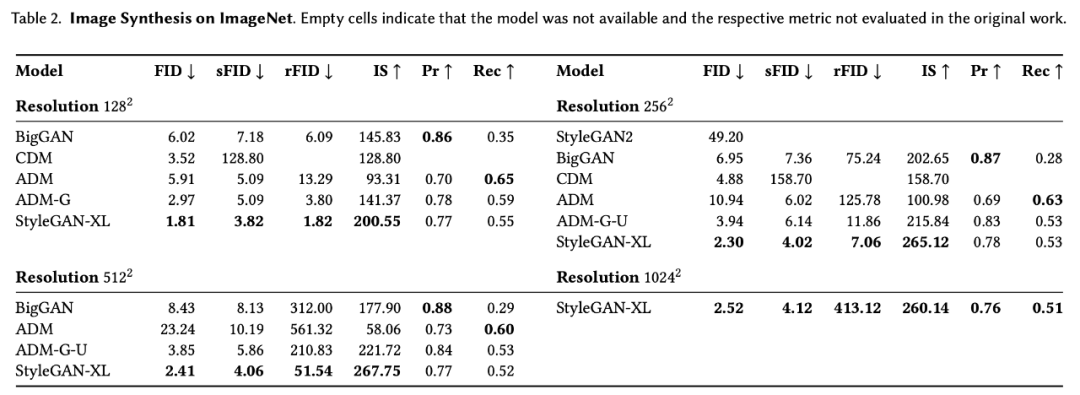
有趣的是,StyleGAN-XL 在所有分辨率下都實現(xiàn)了高度的多樣性,這可以歸功于漸進式生長策略。此外,這種策略使擴大到百萬像素分辨率的合成變成可能。
在 1024^2 這一分辨率下,StyleGAN-XL 沒有與 baseline 進行比較,因為受到資源限制,且它們的訓練成本高得令人望而卻步。
圖 3 展示了分辨率提高后的生成樣本可視化結果。

反演和操縱
同時,還可以進一步細化所得到的重構結果。將 PTI [Roich et al. 2021] 和 StyleGAN-XL 相結合,幾乎可以精確地反演域內 (ImageNet 驗證集) 和域外圖像。同時生成器的輸出保持平滑,如下圖 4 所示。

圖 5、圖 6 展示了 StyleGAN-XL 在圖像操縱方面的性能:


審核編輯 :李倩
-
模型
+關注
關注
1文章
3500瀏覽量
50124 -
圖像質量
+關注
關注
0文章
35瀏覽量
10199 -
英偉達
+關注
關注
22文章
3927瀏覽量
93270
原文標題:英偉達公布StyleGAN-XL:參數(shù)量3倍于StyleGAN3,計算時間僅為五分之一
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
Gemini API集成Google圖像生成模型Imagen 3
行業(yè)首創(chuàng)20kV耐壓繼電器為高壓開關樹立新標桿

愛立信與Telstra、聯(lián)發(fā)科技樹立5G連接新標桿
【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+第一章初體驗
打造貼心的Galaxy AI伙伴 三星Galaxy S25系列樹立Galaxy手機新標桿

SOLiDVUE激光雷達IC榮獲CES創(chuàng)新獎,樹立行業(yè)新標桿
借助谷歌Gemini和Imagen模型生成高質量圖像

【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型
凱茉銳電子 工業(yè)4.0時代下的索尼高清機芯FCB-CV7520:打造智能檢測新標桿
AI大模型在圖像識別中的優(yōu)勢
Arm Cortex-X925 樹立全新性能標桿,實現(xiàn)人工智能、游戲和多任務處理的先進功能

Meta發(fā)布Imagine Yourself AI模型,重塑個性化圖像生成未來
Google Gemma 2模型的部署和Fine-Tune演示





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論