") 一種緩解負采樣偏差的對比學習句表示框架DCLR
一種緩解負采樣偏差的對比學習句表示框架DCLR
本文針對句表示對比學習中的負采樣偏差進行研究,提出了一種針對錯負例和各向異性問題的去偏句表示對比學習框架。該框架包括一種懲罰假負例的實例加權方法以及一種基于噪聲的負例生成方法,有效緩解了句表示任務中的負采樣偏差問題,提升了表示空間的均勻性。
論文題目:Debiased Contrastive Learning of Unsupervised Sentence Representations
論文下載地址:https://arxiv.org/abs/2205.00656
論文開源代碼:https://github.com/rucaibox/dclr
引言
作為自然語言處理(NLP)領域的一項基本任務,無監(jiān)督句表示學習(unsupervised sentence representation learning)旨在得到高質量的句表示,以用于各種下游任務,特別是低資源領域或計算成本較高的任務,如 zero-shot 文本語義匹配、大規(guī)模語義相似性計算等等。
考慮到預訓練語言模型原始句表示的各向異性問題,對比學習被引入到句表示任務中。然而,以往工作的大多采用批次內負采樣或訓練數(shù)據(jù)隨機負采樣,這可能會造成采樣偏差(sampling bias),導致不恰當?shù)呢摾儇摾蚋飨虍愋缘呢摾┍挥脕磉M行對比學習,最終損害表示空間的對齊度(alignment)和均勻性(uniformity)。
為了解決以上問題,我們提出了一種新的句表示學習框架 DCLR(Debiased Contrastive Learning of Unsupervised Sentence Representations)。在 DCLR 中,我們設計了一種懲罰假負例的實例加權方法以及一種基于噪聲的負例生成方法,有效緩解了句表示任務中的負采樣偏差問題,提升了表示空間的對齊度和均勻性。
背景與動機
近年來,預訓練語言模型在各種 NLP 任務上取得了令人矚目的表現(xiàn)。然而,一些研究發(fā)現(xiàn),由預訓練模型得出的原始句表示相似度都很高,在向量空間中并不是均勻分布的,而是構成了一個狹窄的錐體,這在很大程度上限制了句表示的表達能力。
為了得到分布均勻的句表示,對比學習被應用于句表示學習中。對比學習的目標是從數(shù)據(jù)中學習到一個優(yōu)質的語義表示空間。優(yōu)質的語義表示空間需要正例表示分布足夠接近,同時語義表示盡量均勻地分布在超球面上,具體可以用以下兩種指標來衡量:
1、對齊度(alignment)計算原始表示與正例表示的平均距離。
2、均勻性(uniformity)計算表示整體在超球面上分布的均勻程度。
因此,對比學習的思想為拉近語義相似的正例表示以提高對齊度,同時推開不相關的負例以提高整個表示空間的均勻性。
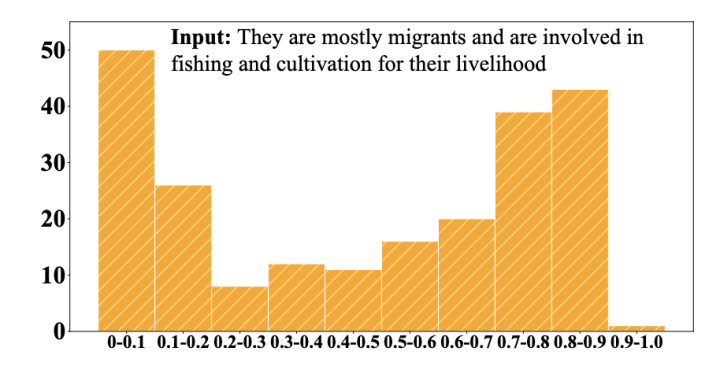
以往的基于對比學習的句表示學習工作大多使用 batch 內數(shù)據(jù)作為負例或從訓練數(shù)據(jù)中隨機采樣負例。然而,這類方式可能會造成抽樣偏差(sampling bias),導致不恰當?shù)呢摾ɡ缂儇摾蚋飨虍愋缘呢摾┍挥脕韺W習句表示,這將損害表征空間的對齊性和統(tǒng)一性。上圖是 SimCSE 編碼的輸入句表示與批次內其它樣本表示的余弦相似度分布。可以看到,有接近一半的相似度高于 0.7,直接在向量空間中推遠這些負例很有可能損害模型的語義表示能力。
因此,本文聚焦于如何降低負采樣偏差,從而使得對比學習得到向量分布對齊、均勻的句表示。
方法簡介
DCLR 聚焦于減少句表示對比學習中負采樣偏差的影響。在這個框架中,我們設計了一種基于噪聲的負例生成策略和一種懲罰假負例的實例加權方法。
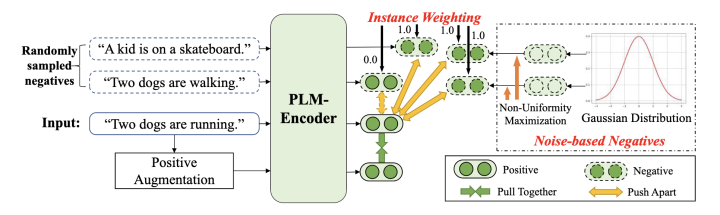
基于噪聲的負例生成
對于每個輸入句 ,我們首先基于高斯分布初始化個噪聲向量作為負例表示:
其中為標準差。因為這些噪聲向量是從上述高斯分布中隨機初始化的,所以它們均勻地分布在語義空間中。因此,模型可以通過學習這些負例來提高語義空間的均勻性。
為了提高生成負例的質量,我們考慮迭代更新負例,以捕捉語義空間中的非均勻性點。受虛擬對抗訓練(virtual adversarial training, VAT)的啟發(fā),我們設計了一個非均勻性(non-uniformity)損失最大化的目標函數(shù)以產生梯度來改善這些負例。具體來說,目標函數(shù)表示為基于噪聲的負例與正例表示的對比學習損失:
其中是溫度超參數(shù),是余弦相似度。對于每個負例 ,我們通過 t 步梯度上升法對其進行優(yōu)化:
其中為學習率,是 L2 范數(shù)。表示通過最大化非均勻性目標函數(shù)產生的的梯度。這樣一來,基于噪音的負例將朝著句表示空間的非均勻點優(yōu)化。學習與這些負例的對比可以進一步提高表示空間的均勻性。
帶有實例加權的對比學習
除了上述基于噪音的負例,我們也遵循現(xiàn)有工作,使用其它批次內樣本表示作為負例。然而,如前文所述,批次內負例可能包含與正例有類似語義的例子,即假負例。為了緩解這個問題,我們提出了一種實例加權的方法來懲罰假負例。由于我們無法獲得真實的負例標簽,我們利用補充模型 SimCSE 來計算每個負例的權重。給定 或 {hat{h}}中的一個負例表示 和原始句表示 ,我們使用補全模型來計算權重:
其中 是實例加權閾值,是余弦相似度函數(shù)。通過上式,與原句表示有較高語義相似性的負例將被視為假負例,并將被賦予 0 權重作為懲罰。基于以上權重,我們用去偏的交叉熵對比學習損失函數(shù)來優(yōu)化句表示:
我們的方法使用了 SimCSE 的 dropout 正例增廣策略,但也適用于其它多種正例增廣策略。
實驗
數(shù)據(jù)集
遵循以往的工作,我們在 7 個標準語義文本相似度任務上進行實驗。這些數(shù)據(jù)集由成對句子樣本構成,其相似性分數(shù)被標記為 0 到 5。標簽分數(shù)和句表示預測分數(shù)之間的相關性由 Spearman 相關度來衡量。
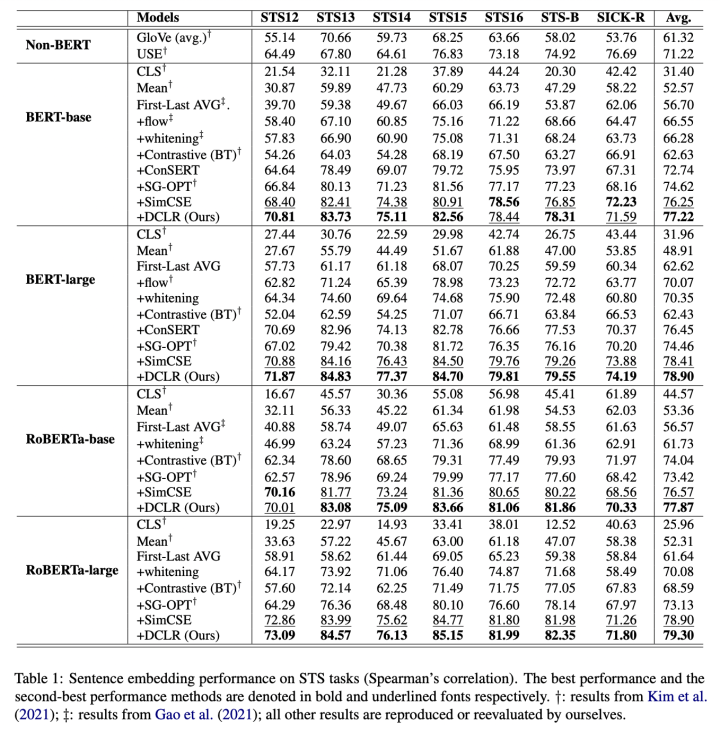
主實驗
我們在 7 個數(shù)據(jù)集上進行了語義相似度測試,并與現(xiàn)有 baseline 進行比較。可以看到,DCLR 的性能在絕大部分實驗中優(yōu)于基線模型。
分析與擴展
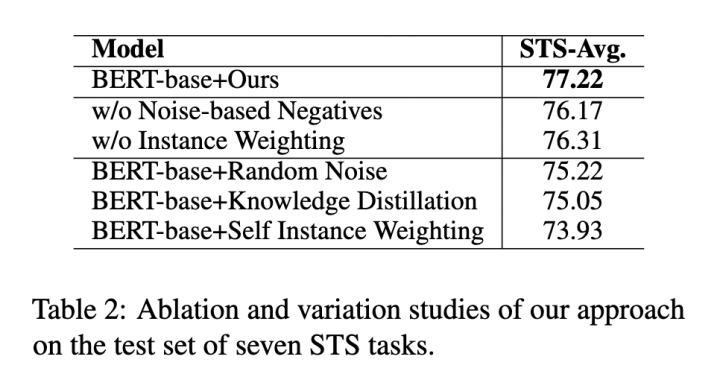
DCLR 框架包含兩個去偏負采樣策略,為了驗證其有效性,我們對兩部分分別進行了消融實驗。除此之外,我們還考慮其它三種策略:
1、Random Noise 直接從高斯分布中生成負例,不進行梯度優(yōu)化。
2、Knowledge Distillation 使用 SimCSE 作為教師模型在訓練過程中向學生模型蒸餾知識。
3、Self Instance Weighting 將模型自己作為補全模型為實例計算權重。
結果顯示 DCLR 的性能優(yōu)于各類變種,表明所提策略的合理性。
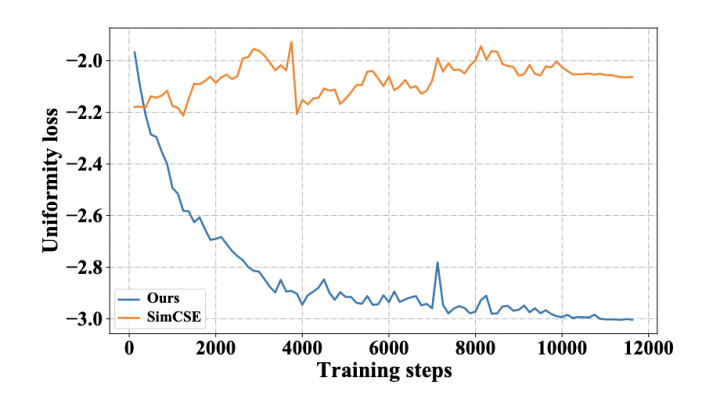
均勻性是句表示的一個理想特征。我們比較了 DCLR 和 SimCSE 基于 BERT-base 在訓練期間的均勻性損失曲線。遵循 SimCSE,均勻性損失函數(shù)為:
其中 是所有句表示的分布。如圖所示,隨著訓練進行,DCLR 的均勻性損失下降,而 SimCSE 沒有明顯的下降趨勢。這可能表明 DCLR 中基于噪聲的負例采樣方法能夠有效改善語義空間的均勻性。
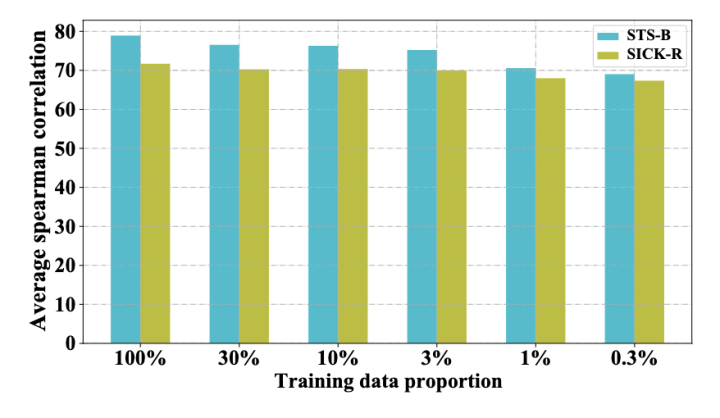
為了驗證 DCLR 在少樣本場景下的健壯性,我們在 0.3% 到 100% 的數(shù)據(jù)量設定下訓練模型。結果表明,即使在相對極端的數(shù)據(jù)設定(0.3%)下,我們的模型性能也僅僅在兩個任務中分別下降了了 9% 和 4%,這顯示了模型在少樣本場景中的有效性。
六. 總結
本文提出了一種緩解負采樣偏差的對比學習句表示框架 DCLR。DCLR 采用一種可梯度更新的噪聲負例生成方法來提高語義空間的均勻性,同時使用實例加權的方法緩解假負例問題,提升語義空間對齊度。實驗表明,該方法在大部分任務設定下優(yōu)于其它基線模型。
在未來,我們將探索其他減少句表示任務中對比學習偏差的方法(例如去偏預訓練)。此外,我們還將考慮將我們的方法應用于多語言或多模態(tài)的表示學習。
審核編輯 :李倩
-
框架
+關注
關注
0文章
404瀏覽量
17820 -
語言模型
+關注
關注
0文章
561瀏覽量
10704 -
nlp
+關注
關注
1文章
490瀏覽量
22525
原文標題:ACL2022 | 無監(jiān)督句表示的去偏對比學習
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
一種實時多線程VSLAM框架vS-Graphs介紹
FOC中的三種電流采樣方式,你真的會選擇嗎?(可下載)
晶振的頻率偏差與解決方法
xgboost與LightGBM的優(yōu)勢對比
AN-851: 一種WiMax雙下變頻IF采樣接收機設計方案

介紹一種 WiMax 雙下變頻 IF 采樣接收機設計方案
將ADS1294用于數(shù)據(jù)采集,偶爾出現(xiàn)實際采樣率與設定采樣率之間存在3%的固定偏差,為什么?
一種面向飛行試驗的數(shù)據(jù)融合框架

Dubbo源碼淺析(一)—RPC框架與Dubbo





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論