") SMP、NUMA、MPP體系結(jié)構(gòu)比較
SMP、NUMA、MPP體系結(jié)構(gòu)比較
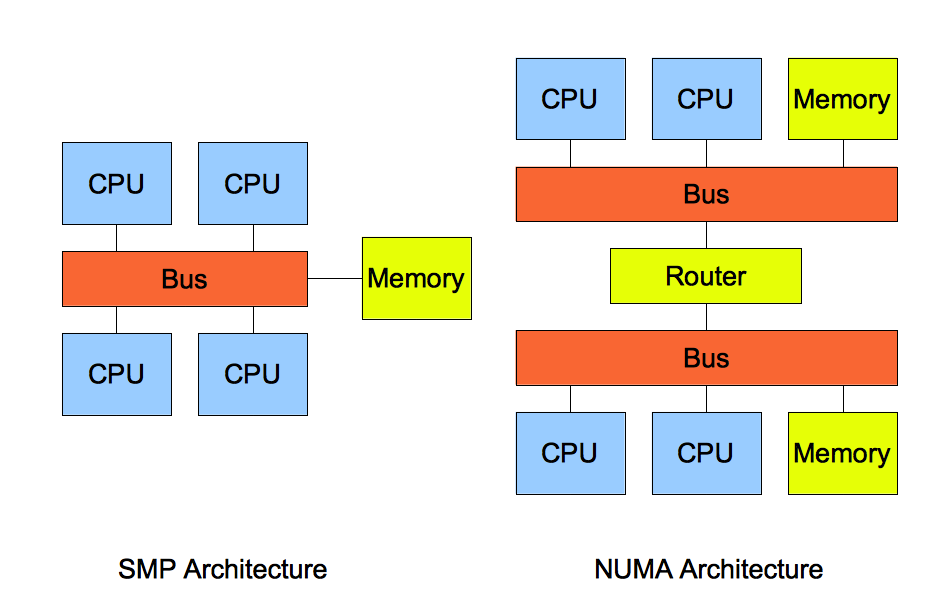
從系統(tǒng)架構(gòu)來看,目前的商用服務(wù)器大體可以分為三類,即對稱多處理器結(jié)構(gòu) (SMP :Symmetric Multi-Processor) ,非一致存儲訪問結(jié)構(gòu) (NUMA :Non-Uniform Memory Access) ,以及海量并行處理結(jié)構(gòu) (MPP :Massive Parallel Processing) 。它們的特征分別描述如下:
1. SMP(Symmetric Multi-Processor)
SMP (Symmetric Multi Processing),對稱多處理系統(tǒng)內(nèi)有許多緊耦合多處理器,在這樣的系統(tǒng)中,所有的CPU共享全部資源,如總線,內(nèi)存和I/O系統(tǒng)等,操作系統(tǒng)或管理數(shù)據(jù)庫的復本只有一個,這種系統(tǒng)有一個最大的特點就是共享所有資源。多個CPU之間沒有區(qū)別,平等地訪問內(nèi)存、外設(shè)、一個操作系統(tǒng)。操作系統(tǒng)管理著一個隊列,每個處理器依次處理隊列中的進程。如果兩個處理器同時請求訪問一個資源(例如同一段內(nèi)存地址),由硬件、軟件的鎖機制去解決資源爭用問題。Access to RAM is serialized; this and cache coherency issues causes performance to lag slightly behind the number of additional processors in the system.
所謂對稱多處理器結(jié)構(gòu),是指服務(wù)器中多個 CPU 對稱工作,無主次或從屬關(guān)系。各 CPU 共享相同的物理內(nèi)存,每個 CPU 訪問內(nèi)存中的任何地址所需時間是相同的,因此 SMP 也被稱為一致存儲器訪問結(jié)構(gòu) (UMA :Uniform Memory Access) 。對 SMP 服務(wù)器進行擴展的方式包括增加內(nèi)存、使用更快的 CPU 、增加 CPU 、擴充 I/O( 槽口數(shù)與總線數(shù) ) 以及添加更多的外部設(shè)備 ( 通常是磁盤存儲 ) 。
SMP 服務(wù)器的主要特征是共享,系統(tǒng)中所有資源 (CPU 、內(nèi)存、 I/O 等 ) 都是共享的。也正是由于這種特征,導致了 SMP 服務(wù)器的主要問題,那就是它的擴展能力非常有限。對于 SMP 服務(wù)器而言,每一個共享的環(huán)節(jié)都可能造成 SMP 服務(wù)器擴展時的瓶頸,而最受限制的則是內(nèi)存。由于每個 CPU 必須通過相同的內(nèi)存總線訪問相同的內(nèi)存資源,因此隨著 CPU 數(shù)量的增加,內(nèi)存訪問沖突將迅速增加,最終會造成 CPU 資源的浪費,使 CPU 性能的有效性大大降低。實驗證明, SMP 服務(wù)器 CPU 利用率最好的情況是 2 至 4 個 CPU 。
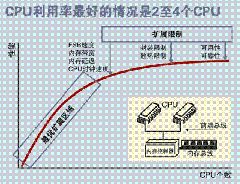
圖1. SMP 服務(wù)器 CPU 利用率狀態(tài)
8路服務(wù)器是服務(wù)器產(chǎn)業(yè)的分水嶺。因為4路及以下服務(wù)器都采用SMP架構(gòu)(Symmetric Multi-Processor,對稱多處理結(jié)構(gòu)),實驗證明,SMP服務(wù)器CPU利用率最好的情況是2至4個CPU。8是這種架構(gòu)支持的處理器數(shù)量的極限,要支持8顆以上的處理器須采用另外的NUMA架構(gòu)(Non-Uniform Memory Access,非一致性內(nèi)存訪問)。利用NUMA技術(shù),可以較好地解決原來SMP系統(tǒng)的擴展問題,在一個物理服務(wù)器內(nèi)可以支持上百個CPU。
2. NUMA(Non-Uniform Memory Access)
由于 SMP 在擴展能力上的限制,人們開始探究如何進行有效地擴展從而構(gòu)建大型系統(tǒng)的技術(shù), NUMA 就是這種努力下的結(jié)果之一。利用 NUMA 技術(shù),可以把幾十個 CPU( 甚至上百個 CPU) 組合在一個服務(wù)器內(nèi)。其 CPU 模塊結(jié)構(gòu)如圖 2 所示:
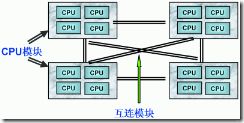
圖2. NUMA 服務(wù)器 CPU 模塊結(jié)構(gòu)
NUMA 服務(wù)器的基本特征是具有多個 CPU 模塊,每個 CPU 模塊由多個 CPU( 如 4 個 ) 組成,并且具有獨立的本地內(nèi)存、 I/O 槽口等。由于其節(jié)點之間可以通過互聯(lián)模塊 ( 如稱為 Crossbar Switch) 進行連接和信息交互,因此每個 CPU 可以訪問整個系統(tǒng)的內(nèi)存 ( 這是 NUMA 系統(tǒng)與 MPP 系統(tǒng)的重要差別 ) 。顯然,訪問本地內(nèi)存的速度將遠遠高于訪問遠地內(nèi)存 ( 系統(tǒng)內(nèi)其它節(jié)點的內(nèi)存 ) 的速度,這也是非一致存儲訪問 NUMA 的由來。由于這個特點,為了更好地發(fā)揮系統(tǒng)性能,開發(fā)應(yīng)用程序時需要盡量減少不同 CPU 模塊之間的信息交互。
利用 NUMA 技術(shù),可以較好地解決原來 SMP 系統(tǒng)的擴展問題,在一個物理服務(wù)器內(nèi)可以支持上百個 CPU 。比較典型的 NUMA 服務(wù)器的例子包括 HP 的 Superdome 、 SUN15K 、 IBMp690 等。
但 NUMA 技術(shù)同樣有一定缺陷,由于訪問遠地內(nèi)存的延時遠遠超過本地內(nèi)存,因此當 CPU 數(shù)量增加時,系統(tǒng)性能無法線性增加。如 HP 公司發(fā)布 Superdome 服務(wù)器時,曾公布了它與 HP 其它 UNIX 服務(wù)器的相對性能值,結(jié)果發(fā)現(xiàn), 64 路 CPU 的 Superdome (NUMA 結(jié)構(gòu) ) 的相對性能值是 20 ,而 8 路 N4000( 共享的 SMP 結(jié)構(gòu) ) 的相對性能值是 6.3 。從這個結(jié)果可以看到, 8 倍數(shù)量的 CPU 換來的只是 3 倍性能的提升。
2008年intel發(fā)布了Nehalem構(gòu)架處理器,CPU內(nèi)集成了內(nèi)存控制器。當多CPU時任何一顆CPU都能訪問全部內(nèi)存。但CPU0訪問本地內(nèi)存(CPU0控制器直接控制的內(nèi)存)消耗小,CPU0訪問遠地內(nèi)存(CPU1內(nèi)存控制器控制的內(nèi)存)消耗大,NUMA功能的開啟變成了必須了。
默認的NUMA功能是將計算和內(nèi)存資源分配在一個NUMA內(nèi),有可能導致SWAP問題,即:NUMA0內(nèi)存已經(jīng)用完都開始用SWAP空間了,NUMA1還有很大的內(nèi)存free。在數(shù)據(jù)庫服務(wù)器上NUMA可能導致非常嚴重的性能問題,甚至有很多數(shù)據(jù)庫死機的問題。就下圖這個熊樣。

在虛擬化情況下,KVM虛機的CPU數(shù)量盡量不超過一個NUMA區(qū)域內(nèi)的CPU數(shù)量,如果超過,則會出現(xiàn)一個KVM虛機使用了兩個NUMA的情況,導致CPU等待內(nèi)存時間過長,系統(tǒng)性能下降,此時需要手動調(diào)整KVM的配置才可以提高性能。
Ubuntu 12.02自身帶有Automatic NUMA balancing,可以支持NUMA自平衡,具體情況未測試。SUSE12也支持Automatic NUMA balancing
JUNO版的Openstack中,KVM的CPU的拓撲可以通過image或者flavor進行元數(shù)據(jù)傳遞來定義,如果沒有特別的定義此類元數(shù)據(jù),則模擬的CPU將是多Socket單Core單NUMA節(jié)點的CPU,這樣的CPU與物理CPU完全不同。
上面是KVM。Vmware ESX 5.0及之后的版本支持一種叫做vNUMA的特性,它將Host的NUMA特征暴露給了GuestOS,從而使得Guest OS可以根據(jù)NUMA特征進行更高性能的調(diào)度。
CPU的熱添加功能不支持vNUMA功能。
vmotion等功能一旦將vmware虛機遷移,則可能導致vNUMA失效,帶來嚴重的性能降低。所以在ESXi中保持物理服務(wù)器的一致性是有必要的。
中國第一臺自主研發(fā)的,可支持32可處理器的高端服務(wù)器浪潮天梭K1,發(fā)布于2013年1月,系統(tǒng)可用性達到99.9994%,同時,我國也成為了時間上第三個掌握該技術(shù)的國家。
3. MPP(Massive Parallel Processing)
和 NUMA 不同, MPP 提供了另外一種進行系統(tǒng)擴展的方式,它由多個 SMP 服務(wù)器通過一定的節(jié)點互聯(lián)網(wǎng)絡(luò)進行連接,協(xié)同工作,完成相同的任務(wù),從用戶的角度來看是一個服務(wù)器系統(tǒng)。其基本特征是由多個 SMP 服務(wù)器 ( 每個 SMP 服務(wù)器稱節(jié)點 ) 通過節(jié)點互聯(lián)網(wǎng)絡(luò)連接而成,每個節(jié)點只訪問自己的本地資源 ( 內(nèi)存、存儲等 ) ,是一種完全無共享 (Share Nothing) 結(jié)構(gòu),因而擴展能力最好,理論上其擴展無限制,目前的技術(shù)可實現(xiàn) 512 個節(jié)點互聯(lián),數(shù)千個 CPU 。目前業(yè)界對節(jié)點互聯(lián)網(wǎng)絡(luò)暫無標準,如 NCR 的 Bynet , IBM 的 SPSwitch ,它們都采用了不同的內(nèi)部實現(xiàn)機制。但節(jié)點互聯(lián)網(wǎng)僅供 MPP 服務(wù)器內(nèi)部使用,對用戶而言是透明的。
在 MPP 系統(tǒng)中,每個 SMP 節(jié)點也可以運行自己的操作系統(tǒng)、數(shù)據(jù)庫等。但和 NUMA 不同的是,它不存在異地內(nèi)存訪問的問題。換言之,每個節(jié)點內(nèi)的 CPU 不能訪問另一個節(jié)點的內(nèi)存。節(jié)點之間的信息交互是通過節(jié)點互聯(lián)網(wǎng)絡(luò)實現(xiàn)的,這個過程一般稱為數(shù)據(jù)重分配 (Data Redistribution) 。
但是 MPP 服務(wù)器需要一種復雜的機制來調(diào)度和平衡各個節(jié)點的負載和并行處理過程。目前一些基于 MPP 技術(shù)的服務(wù)器往往通過系統(tǒng)級軟件 ( 如數(shù)據(jù)庫 ) 來屏蔽這種復雜性。舉例來說, NCR 的 Teradata 就是基于 MPP 技術(shù)的一個關(guān)系數(shù)據(jù)庫軟件,基于此數(shù)據(jù)庫來開發(fā)應(yīng)用時,不管后臺服務(wù)器由多少個節(jié)點組成,開發(fā)人員所面對的都是同一個數(shù)據(jù)庫系統(tǒng),而不需要考慮如何調(diào)度其中某幾個節(jié)點的負載。
MPP (Massively Parallel Processing),大規(guī)模并行處理系統(tǒng),這樣的系統(tǒng)是由許多松耦合的處理單元組成的,要注意的是這里指的是處理單元而不是處理器。每個單元內(nèi)的CPU都有自己私有的資源,如總線,內(nèi)存,硬盤等。在每個單元內(nèi)都有操作系統(tǒng)和管理數(shù)據(jù)庫的實例復本。這種結(jié)構(gòu)最大的特點在于不共享資源。
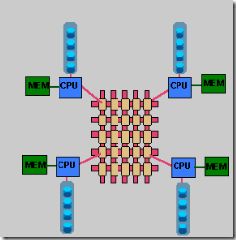
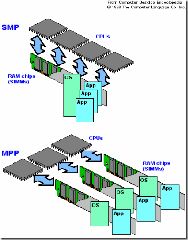
4. 三種體系架構(gòu)之間的差異
4.1 SMP系統(tǒng)與MPP系統(tǒng)比較
既然有兩種結(jié)構(gòu),那它們各有什么特點呢?采用什么結(jié)構(gòu)比較合適呢?通常情況下,MPP系統(tǒng)因為要在不同處理單元之間傳送信息(請注意上圖),所以它的效率要比SMP要差一點,但是這也不是絕對的,因為MPP系統(tǒng)不共享資源,因此對它而言,資源比SMP要多,當需要處理的事務(wù)達到一定規(guī)模時,MPP的效率要比SMP好。這就是看通信時間占用計算時間的比例而定,如果通信時間比較多,那MPP系統(tǒng)就不占優(yōu)勢了,相反,如果通信時間比較少,那MPP系統(tǒng)可以充分發(fā)揮資源的優(yōu)勢,達到高效率。當前使用的OTLP程序中,用戶訪問一個中心數(shù)據(jù)庫,如果采用SMP系統(tǒng)結(jié)構(gòu),它的效率要比采用MPP結(jié)構(gòu)要快得多。而MPP系統(tǒng)在決策支持和數(shù)據(jù)挖掘方面顯示了優(yōu)勢,可以這樣說,如果操作相互之間沒有什么關(guān)系,處理單元之間需要進行的通信比較少,那采用MPP系統(tǒng)就要好,相反就不合適了。
通過上面兩個圖我們可以看到,對于SMP來說,制約它速度的一個關(guān)鍵因素就是那個共享的總線,因此對于DSS程序來說,只能選擇MPP,而不能選擇SMP,當大型程序的處理要求大于共享總線時,總線就沒有能力進行處理了,這時SMP系統(tǒng)就不行了。當然了,兩個結(jié)構(gòu)互有優(yōu)缺點,如果能夠?qū)煞N結(jié)合起來取長補短,當然最好了。

4.2 NUMA 與 MPP 的區(qū)別
從架構(gòu)來看, NUMA 與 MPP 具有許多相似之處:它們都由多個節(jié)點組成,每個節(jié)點都具有自己的 CPU 、內(nèi)存、 I/O ,節(jié)點之間都可以通過節(jié)點互聯(lián)機制進行信息交互。那么它們的區(qū)別在哪里?通過分析下面 NUMA 和 MPP 服務(wù)器的內(nèi)部架構(gòu)和工作原理不難發(fā)現(xiàn)其差異所在。
首先是節(jié)點互聯(lián)機制不同, NUMA 的節(jié)點互聯(lián)機制是在同一個物理服務(wù)器內(nèi)部實現(xiàn)的,當某個 CPU 需要進行遠地內(nèi)存訪問時,它必須等待,這也是 NUMA 服務(wù)器無法實現(xiàn) CPU 增加時性能線性擴展的主要原因。而 MPP 的節(jié)點互聯(lián)機制是在不同的 SMP 服務(wù)器外部通過 I/O 實現(xiàn)的,每個節(jié)點只訪問本地內(nèi)存和存儲,節(jié)點之間的信息交互與節(jié)點本身的處理是并行進行的。因此 MPP 在增加節(jié)點時性能基本上可以實現(xiàn)線性擴展。
其次是內(nèi)存訪問機制不同。在 NUMA 服務(wù)器內(nèi)部,任何一個 CPU 可以訪問整個系統(tǒng)的內(nèi)存,但遠地訪問的性能遠遠低于本地內(nèi)存訪問,因此在開發(fā)應(yīng)用程序時應(yīng)該盡量避免遠地內(nèi)存訪問。在 MPP 服務(wù)器中,每個節(jié)點只訪問本地內(nèi)存,不存在遠地內(nèi)存訪問的問題。
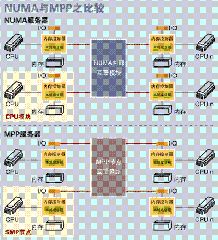
圖3.MPP 服務(wù)器架構(gòu)圖
數(shù)據(jù)倉庫的選擇
哪種服務(wù)器更加適應(yīng)數(shù)據(jù)倉庫環(huán)境?這需要從數(shù)據(jù)倉庫環(huán)境本身的負載特征入手。眾所周知,典型的數(shù)據(jù)倉庫環(huán)境具有大量復雜的數(shù)據(jù)處理和綜合分析,要求系統(tǒng)具有很高的 I/O 處理能力,并且存儲系統(tǒng)需要提供足夠的 I/O 帶寬與之匹配。而一個典型的 OLTP 系統(tǒng)則以聯(lián)機事務(wù)處理為主,每個交易所涉及的數(shù)據(jù)不多,要求系統(tǒng)具有很高的事務(wù)處理能力,能夠在單位時間里處理盡量多的交易。顯然這兩種應(yīng)用環(huán)境的負載特征完全不同。
從 NUMA 架構(gòu)來看,它可以在一個物理服務(wù)器內(nèi)集成許多 CPU ,使系統(tǒng)具有較高的事務(wù)處理能力,由于遠地內(nèi)存訪問時延遠長于本地內(nèi)存訪問,因此需要盡量減少不同 CPU 模塊之間的數(shù)據(jù)交互。顯然, NUMA 架構(gòu)更適用于 OLTP 事務(wù)處理環(huán)境,當用于數(shù)據(jù)倉庫環(huán)境時,由于大量復雜的數(shù)據(jù)處理必然導致大量的數(shù)據(jù)交互,將使 CPU 的利用率大大降低。
相對而言, MPP 服務(wù)器架構(gòu)的并行處理能力更優(yōu)越,更適合于復雜的數(shù)據(jù)綜合分析與處理環(huán)境。當然,它需要借助于支持 MPP 技術(shù)的關(guān)系數(shù)據(jù)庫系統(tǒng)來屏蔽節(jié)點之間負載平衡與調(diào)度的復雜性。另外,這種并行處理能力也與節(jié)點互聯(lián)網(wǎng)絡(luò)有很大的關(guān)系。顯然,適應(yīng)于數(shù)據(jù)倉庫環(huán)境的 MPP 服務(wù)器,其節(jié)點互聯(lián)網(wǎng)絡(luò)的 I/O 性能應(yīng)該非常突出,才能充分發(fā)揮整個系統(tǒng)的性能。
4.3 NUMA、MPP、SMP 之間性能的區(qū)別
NUMA的節(jié)點互聯(lián)機制是在同一個物理服務(wù)器內(nèi)部實現(xiàn)的,當某個CPU需要進行遠地內(nèi)存訪問時,它必須等待,這也是NUMA服務(wù)器無法實現(xiàn)CPU增加時性能線性擴展。
MPP的節(jié)點互聯(lián)機制是在不同的SMP服務(wù)器外部通過I/O實現(xiàn)的,每個節(jié)點只訪問本地內(nèi)存和存儲,節(jié)點之間的信息交互與節(jié)點本身的處理是并行進行的。因此MPP在增加節(jié)點時性能基本上可以實現(xiàn)線性擴展。
SMP所有的CPU資源是共享的,因此完全實現(xiàn)線性擴展。
4.4 NUMA、MPP、SMP之間擴展的區(qū)別
NUMA理論上可以無限擴展,目前技術(shù)比較成熟的能夠支持上百個CPU進行擴展。如HP的SUPERDOME。
MPP理論上也可以實現(xiàn)無限擴展,目前技術(shù)比較成熟的能夠支持512個節(jié)點,數(shù)千個CPU進行擴展。
SMP擴展能力很差,目前2個到4個CPU的利用率最好,但是IBM的BOOK技術(shù),能夠?qū)PU擴展到8個。
MPP是由多個SMP構(gòu)成,多個SMP服務(wù)器通過一定的節(jié)點互聯(lián)網(wǎng)絡(luò)進行連接,協(xié)同工作,完成相同的任務(wù)。
4.5 MPP 和 SMP、NUMA 應(yīng)用之間的區(qū)別
MPP 的優(yōu)勢:
MPP系統(tǒng)不共享資源,因此對它而言,資源比SMP要多,當需要處理的事務(wù)達到一定規(guī)模時,MPP的效率要比SMP好。由于MPP系統(tǒng)因為要在不同處理單元之間傳送信息,在通訊時間少的時候,那MPP系統(tǒng)可以充分發(fā)揮資源的優(yōu)勢,達到高效率。也就是說:操作相互之間沒有什么關(guān)系,處理單元之間需要進行的通信比較少,那采用MPP系統(tǒng)就要好。因此,MPP 系統(tǒng)在決策支持和數(shù)據(jù)挖掘方面顯示了優(yōu)勢。
SMP 的優(yōu)勢:
MPP系統(tǒng)因為要在不同處理單元之間傳送信息,所以它的效率要比SMP要差一點。在通訊時間多的時候,那MPP系統(tǒng)可以充分發(fā)揮資源的優(yōu)勢。因此當前使用的OTLP程序中,用戶訪問一個中心數(shù)據(jù)庫,如果采用SMP系統(tǒng)結(jié)構(gòu),它的效率要比采用MPP結(jié)構(gòu)要快得多。
NUMA 架構(gòu)的優(yōu)勢:
NUMA 架構(gòu)來看,它可以在一個物理服務(wù)器內(nèi)集成許多CPU,使系統(tǒng)具有較高的事務(wù)處理能力,由于遠地內(nèi)存訪問時延遠長于本地內(nèi)存訪問,因此需要盡量減少不同CPU模塊之間的數(shù)據(jù)交互。顯然,NUMA架構(gòu)更適用于OLTP事務(wù)處理環(huán)境,當用于數(shù)據(jù)倉庫環(huán)境時,由于大量復雜的數(shù)據(jù)處理必然導致大量的數(shù)據(jù)交互,將使CPU的利用率大大降低。
原文標題:五分鐘理解服務(wù)器 SMP、NUMA、MPP 三大體系結(jié)構(gòu)
文章出處:【微信公眾號:馬哥Linux運維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
審核編輯:湯梓紅
-
服務(wù)器
+關(guān)注
關(guān)注
12文章
9596瀏覽量
86983 -
SMP
+關(guān)注
關(guān)注
0文章
76瀏覽量
20097 -
MPP
+關(guān)注
關(guān)注
0文章
24瀏覽量
10733 -
numa
+關(guān)注
關(guān)注
0文章
7瀏覽量
3917
原文標題:五分鐘理解服務(wù)器 SMP、NUMA、MPP 三大體系結(jié)構(gòu)
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
SMO與SMP的區(qū)別與聯(lián)系
DS320PR810-SMP-EVM用戶指南

【「RISC-V體系結(jié)構(gòu)編程與實踐」閱讀體驗】-- SBI及NEMU環(huán)境
【「RISC-V體系結(jié)構(gòu)編程與實踐」閱讀體驗】-- 前言與開篇
GPGPU體系結(jié)構(gòu)優(yōu)化方向(2)
GPGPU體系結(jié)構(gòu)優(yōu)化方向(1)
無刷DC門驅(qū)動系統(tǒng)的體系結(jié)構(gòu)
名單公布!【書籍評測活動NO.45】RISC-V體系結(jié)構(gòu)編程與實踐(第二版)
嵌入式系統(tǒng)的體系結(jié)構(gòu)包括哪些
DCS分散控制系統(tǒng)的硬件體系結(jié)構(gòu)介紹

DCS的硬件體系結(jié)構(gòu)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論