 英偉達地位不保?BERT訓練吞吐量提升4.7倍
英偉達地位不保?BERT訓練吞吐量提升4.7倍

電子發燒友網報道(文/周凱揚)推理和訓練作為AI/ML關鍵的一環,無論是通用的GPU,還是專用的推理/訓練加速器,都想在各大流行模型和機器學習庫上跑出優秀的成績,以展示自己的硬件實力。業界需要一個統一的跑分標準,為此,各大廠商在2018年根據業內指標聯合打造的MLPerf就承擔了這一重任。
不過隨著時間的推移,MLPerf幾乎已經成了英偉達一家獨大的跑分基準,這家GPU廠商憑借自己的產品幾乎統治著整個AI硬件市場。這不,近日公布的MLPerf Training 2.0,就將這些AI硬件公司和服務器廠商提交的具體AI訓練成績公布了出來,其中既有一些新晉成員,也有一些出人意料的結果。
谷歌的反超這次跑分結果中,最驚艷的還是谷歌的TPU v4系統,谷歌憑借這一架構的系統,在五個基準測試中都打破了性能記錄,平均訓練速度比第二名的英偉達A100系統快了1.42倍左右,哪怕是與自己在1.0測試下的成績相比,也提升了1.5倍。
能實現這樣的成績自然離不開谷歌自己的TPU芯片設計,谷歌的每個TPU v4 Pod都由4096個芯片組成,且帶寬做到了6Tbps。除此之外,谷歌有著豐富的用例經驗,相較其他公司而言,谷歌是唯一一個在搜索和視頻領域都已經大規模普及AI/ML應用的。
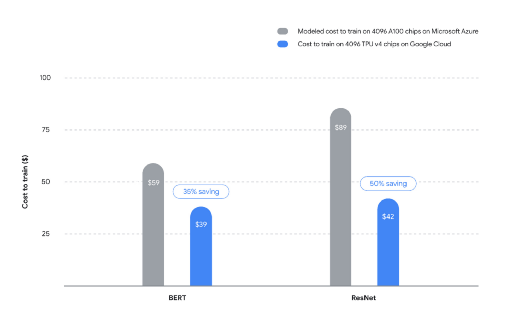
TPU v4與A100的對比 / 谷歌
不過谷歌與英偉達并不是直接競爭關系,他們對標的還是使用英偉達GPU系統的云服務公司,比如微軟的Azure,谷歌也為此特地做了成本對比。如上圖所示,在BERT模型的訓練中,4096個TPU v4芯片與Azure 4096個A100芯片對比,谷歌的方案可以節省35%,ResNet模型的訓練下更是可以節省近50%。
不過以上的成績在所有8項測試中也只是和英偉達平分秋色,而且隨著系統規模的不同,其結果或許會有更多的變化。再者,谷歌的TPU僅限于其自己的云服務,所以總的來說并不算一個通用方案,至少微軟和亞馬遜這樣的競爭對手肯定是用不上。
英偉達地位不保?除了谷歌之外,還取得了不錯的成績的就是英特爾旗下Habana Labs的Gaudi2訓練加速器。這款今年5月推出的處理器,從上一代的16nm換成了臺積電7nm,Tensor處理器內核的數量因此增加了兩倍,使其在ResNet-50的訓練吞吐量上實現了3倍提升,BERT的訓練吞吐量提升了4.7倍。
在與英偉達提交的A100-80GB GPU系統成績相比,Gaudi2在ResNet-50上的訓練時間縮短了36%;與戴爾提交的A100-40GB GPU系統成績相比,Gaudi2在BERT上的訓練時間縮短了45%。
從結果來看,已經有不少廠商的AI硬件已經可以在訓練上對標甚至超過英偉達的GPU生態了,但這并不代表全部機器學習訓練領域。比如在測試中,廠商是不需要將每個項目的測試結果都提交上去的。從這個角度來看,RetinaNet輕量型目標檢測、COCO重型目標檢測、語音識別數據集Librispeech和強化學習Minigo這幾個項目中,只有基于英偉達GPU的系統提交了成績。
不僅如此,如果你看所有提交成績的服務器和云服務公司來看,他們用到的CPU或是AMD的EPYC處理器,或是英特爾的Xeon處理器,但加速器卻是幾乎清一色的英偉達A100。這也證明了在百度、戴爾、H3C、浪潮和聯想這些廠商的眼中,英偉達的GPU依然是最具競爭力的那個。
不可小覷的軟件還有一點需要指出,那就是以上都是封閉組的成績,他們所用到的都是標準的機器學習庫,比如TensorFlow 2.8.0和Pytorch 22.04等。而開放組則不受此限制,可以用到他們自己定制的庫或優化器,這一組中三星和Graphcore都根據不同的軟件配置提交了成績,但最亮眼的還是MosaicML。
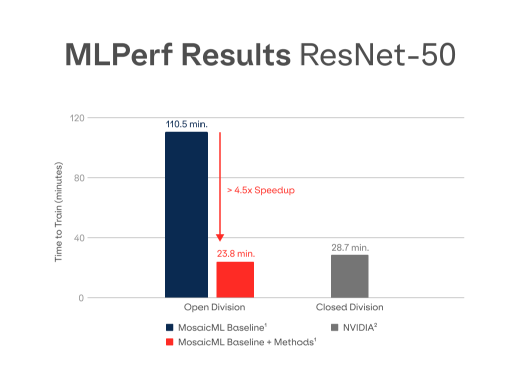
Composer在ResNet-50下的訓練時間對比 / MosaicML
這家公司所用的加速器硬件同樣是和諸多提交者一樣的英偉達A100-SXM-80GB GPU,但他們用到的是自己用Pytorch編寫的庫Composer。這家公司于今年4月推出了Composer,并聲稱可讓模型訓練速度提升2到4倍。在MLPerf Training 2.0的跑分中,使用MosaicML Composer的對比組在ResNet訓練速度上實現了近4.6倍的提升。不過Composer雖說支持任何模型,但這個提速的表現目前還是體現在ResNet上比較明顯,所以本次也并沒有提交其他模型下的成績。
考慮到英特爾等公司為了提升其軟件開發實力,已經在收購Codeplay這樣的軟件開發公司,MosaicML作為剛公開不久的初創公司,創始人又是英特爾的前AI實驗室骨干,如果能在未來展現出更優秀的成績,說不定也會被英偉達這樣的公司看中。
結語英偉達常年在MLPerf上霸榜,也有不少人認為MLPerf跑分成了英偉達的宣傳工具,然而事實是英特爾、谷歌等同樣重視AI的公司也將其視為一個公平的基準測試,而且MLPerf還有同行評審環節,進一步驗證測試結果。從以上結果來看,AI訓練硬件上的創新仍未停止,無論是GPU、TPU還是IPU都在推陳出新,但跑分結果并不代表任何用例都能達到高性能,還需要廠商自己去調校模型和軟件才能達成最好的成績。
原文標題:AI硬件反超英偉達?跑分來看尚不現實
文章出處:【微信公眾號:電子發燒友網】歡迎添加關注!文章轉載請注明出處。
-
谷歌
+關注
關注
27文章
6230瀏覽量
107852 -
機器學習
+關注
關注
66文章
8499瀏覽量
134331 -
TPU
+關注
關注
0文章
152瀏覽量
21139 -
英偉達
+關注
關注
22文章
3933瀏覽量
93367
原文標題:AI硬件反超英偉達?跑分來看尚不現實
文章出處:【微信號:elecfans,微信公眾號:電子發燒友網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
數據吞吐量提升!面向下一代音頻設備,藍牙HDT、星閃、Wi-Fi、UWB同臺競技
CY7C65211 作為 SPI 從機模式工作時每秒的最大吞吐量是多少?
如何在Visual Studio 2022中運行FX3吞吐量基準測試工具?
FX3進行讀或寫操作時CS信號拉低,在讀或寫完成后CS置高,對吞吐量有沒有影響?
新思科技攜手英偉達加速芯片設計,提升芯片電子設計自動化效率
英偉達發布Nemotron-CC大型AI訓練數據庫
ADC芯片的采樣率為100MSPS,位寬16位,那么吞吐量是多少?
英偉達推出歸一化Transformer,革命性提升LLM訓練速度
TMS320C6472/TMS320TCI6486的吞吐量應用程序報告






 工商網監
工商網監
評論