 面向中文搜索的開放域文檔視覺問答任務解決方案
面向中文搜索的開放域文檔視覺問答任務解決方案

摘要
開放域問答在現實生活中有著廣泛的應用,例如搜索引擎、企業問答、醫療問答等等。然而,現有開放域問答系統通常需要消耗大量成本針對不同格式的異構文檔(如PDF、網頁、掃描文檔等)設計特定的內容抽取算法,預先從文檔中抽取文本內容作為系統的信息來源。這不僅限制了現有系統的可擴展能力,還損失了文檔中的布局和視覺信息。為此,本文提出了一個全新的開放域文檔視覺問答任務,直接以異構文檔圖像集合為信息來源回答用戶提問,并提出了中文開放域文檔視覺問答數據集DuReadervis。DuReadervis共包含158K文檔圖像和15K對問答對,主要挑戰包括:1)長文檔理解;2)噪聲干擾;和3)多片段答案抽取。
1. 背景
現有開放域問答系統主要以文本集合作為信息來源回答用戶提問,如圖1所示,現有系統通常需要花費大量成本根據不同的文檔格式設計特定的內容抽取算法,預先從異構文檔中抽取文本內容。這無疑限制了開放域問答系統的可擴展(scalable)能力。一個可擴展的問答系統應能同時處理各種格式文檔,還可以輕松地遷移到尚未見過的文檔格式中。此外,現有系統由于只抽取了文本內容,因此會損失原始文檔中極有價值的布局特征(如字體大小、列表格式或表格格式等)和視覺特征(如文本顏色、圖像等)。
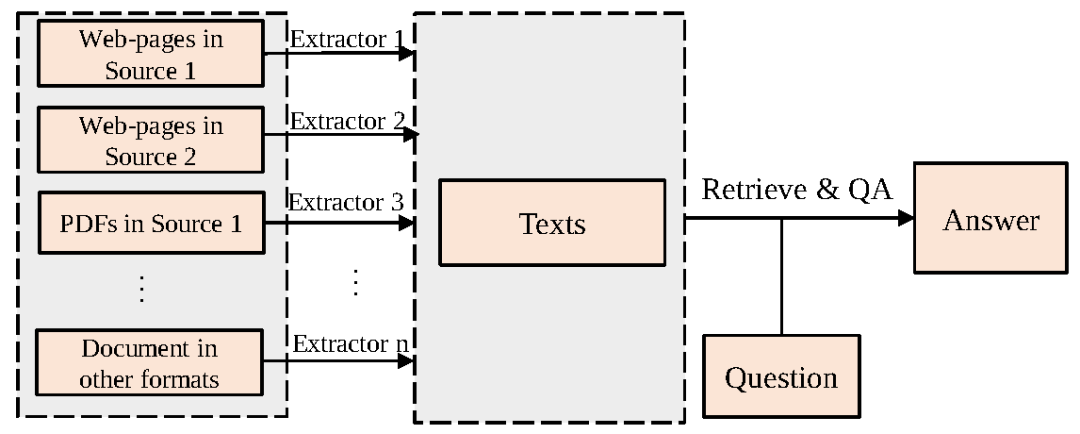
圖1 開放域問答系統通用流程,需要根據文檔格式和來源設計不同的內容抽取器抽取文本內容
2. 開放域文檔視覺問答
為了提升開放域問答系統的可擴展能力,同時充分利用異構文檔中的布局和視覺信息,本文提出了一個全新的問答任務,即開放域文檔視覺問答(Open-domain Document Visual Question Answering,Open-domain DocVQA)。該任務從視覺角度描述異構文檔,直接以從異構文檔轉換得到的文檔圖像集合為信息來源來回答用戶提問。如圖2所示,該任務通過通用抽取器(如OCR)抽取文檔圖像中的文本內容和布局結構,然后將這些信息連同文檔圖像的視覺特征應用于后續流程中。
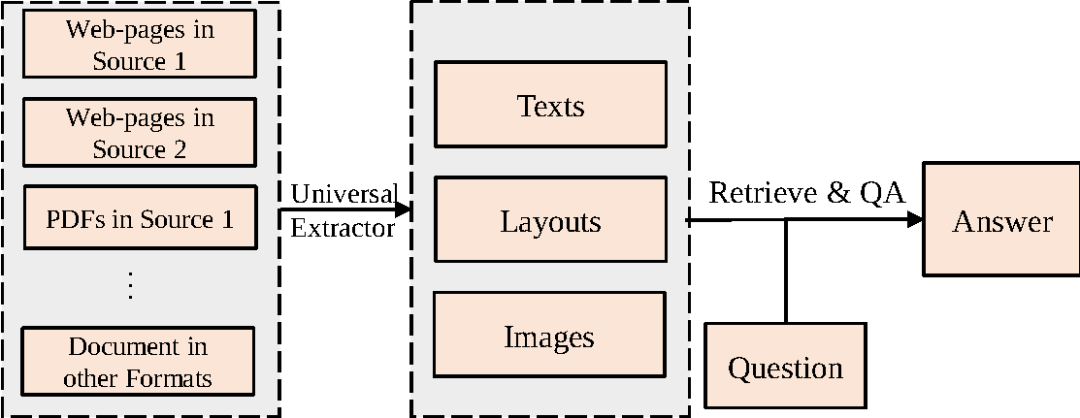
圖2 開放域文檔視覺問答通用流程,將不同格式文檔視為文檔圖像,只需類似于OCR的通用抽取器抽取其中的文本內容和布局特征
與開放域問答類似,該任務也包含兩個階段:
文檔視覺檢索(Document Visual Retrieval,DocVRE):從原始的文檔圖像集合中檢索和問題相關的小規模候選文檔圖像集合
文檔視覺問答(Document Visual Question Answering,DocVQA):根據檢索結果抽取單個或多個文本片段作為問題答案
3. DuReadervis
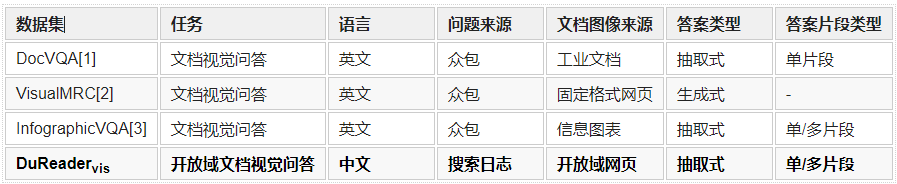
為了推動開放域文檔視覺問答的發展,本文從百度搜索日志中收集用戶向搜索引擎提出的真實問題和相關網頁并進行了問答對的標注,提出中文開放域文檔視覺問答數據集DuReadervis。相比于現有的文檔視覺問答數據集,DuReadervis的問題面向真實用戶提問,可以滿足開放域的信息搜索需求。此外,DuReadervis中的文檔圖像均來自于互聯網網頁,包含豐富的文本內容和視覺特征以及復雜多樣的布局結構,而且DuReadervis需要抽取格式復雜的長答案,如多片段文本型答案、列表型答案和表格型答案。表1對比了DuReadervis和現有文檔視覺問答數據集。
表1 DuReadervis與其他文檔視覺問答數據集的對比
3.1 數據集統計分析
DuReadervis共包含158K文檔圖像和15K問答對,其中訓練集包括11K問答對;開發集包括1.5K問答對;測試集包括2.5K問答對。
文檔圖像
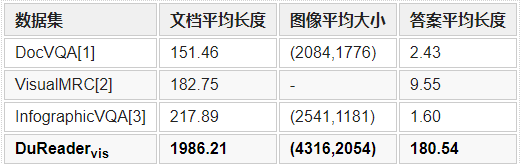
DuReadervis中的文本內容的平均長度和文檔圖像的平均大小要遠超于其他數據集,表明DuReadervis中的文檔圖像包含更豐富的文本內容和視覺特征。此外,DuReadervis中的文檔圖像來自于17000多個隨機網站,文檔主題和布局結構多樣性高。另一方面,通常情況下網頁中會包含大量的噪聲信息,會對模型理解文檔產生干擾。
問題和答案
現有文檔視覺問答數據集中的問題主要為事實類問題。而在DuReadervis中,問題類型同時包含事實類和非事實類問題。本文隨機篩選了200條問題人工進行分類,發現43%的問題是非事實類問題。DuReadervis中的答案平均長度也要遠長于其他數據集中的答案平均長度。此外,DuReadervis的答案格式復雜,包含約40%的文本型答案、25%的列表型答案和35%的表格型答案。在列表型和表格型答案中,很多答案都是不連續的,需要抽取多片段答案。
表2 數據集統計特征
3.2 數據集挑戰
總體而言,DuReadervis的主要挑戰包括以下三點:
長文檔理解:DuReadervis中的文檔圖像均轉換自互聯網頁面,包含更長的文本內容、更豐富的視覺特征和復雜的布局結構;
噪聲干擾:來自于網頁的文檔圖像中會包含大量噪聲信息,例如廣告、相關推薦等,增大了文檔圖像的理解難度;
多片段答案抽取:DuReadervis中的答案格式更加復雜,包含文本、列表和表格型答案,需要模型抽取多片段長答案。
3.3 數據集樣例
傳統的開放域問答系統可以通過設計特殊的內容抽取算法可以很好地去除表格外的噪聲干擾,但提取的文本內容很難保留表格的布局結構,系統很難得知不同單元格文本內容間的語義關聯。相比之下,開放域文檔視覺問答系統則可以通過表格的布局特征更輕松地建模單元格文本內容間的語義關聯,通過“站點”這一列標題找到問題的答案。
4. 基線方法
本文為DuReadervis提出了一個基線方法。該方法包括三部分:
基于PaddleOCR的通用內容抽取:利用PaddleOCR技術從文檔圖像中抽取文本內容和布局結構作為系統輸入;
基于BM25的文檔視覺檢索:根據抽取出的文本內容構建檢索庫,再利用BM25算法檢索相關文檔圖像;
基于層次化LayoutXLM的文檔視覺問答:為了從候選文檔圖像中抽取問題答案,本文提出了層次化LayoutXLM模型。如圖4所示,該模型利用層次化建模的方式建模DuReadervis中的長文本內容,并通過基于CRF的序列標注算法抽取多片段答案。其中,LayoutXLM[4]是以文本、布局和視覺特征為輸入的面向多語言跨模態文檔的預訓練模型。
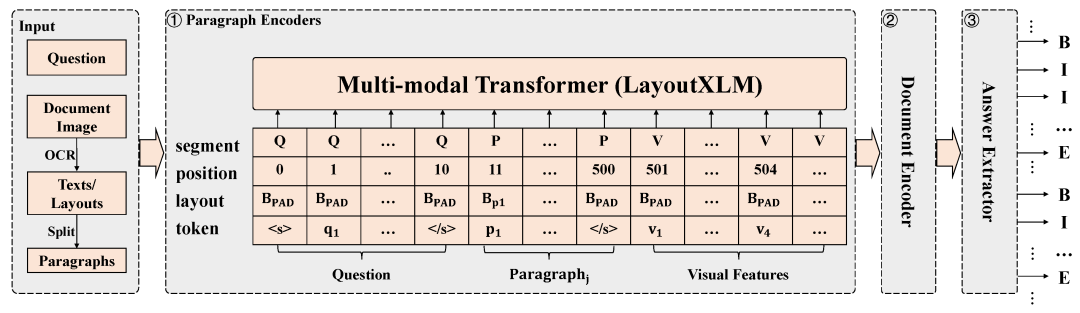
圖4 層次化LayoutXLM模型架構
5. 實驗
5.1 實驗設置
為了驗證所提方法的有效性,本文在文檔視覺問答和開放域文檔視覺問答任務上進行了實驗,將層次化LayoutXLM與基于純文本預訓練模型的層次化RobertaXLM[5]以及層次化BERT[6]進行對比。其中,在開放域文檔視覺問答實驗中,本文使用BM25算法檢索回與問題最相關的文檔圖像進行答案抽取。兩個任務的評價指標均為F1和Rouge-L。
5.2 實驗結果
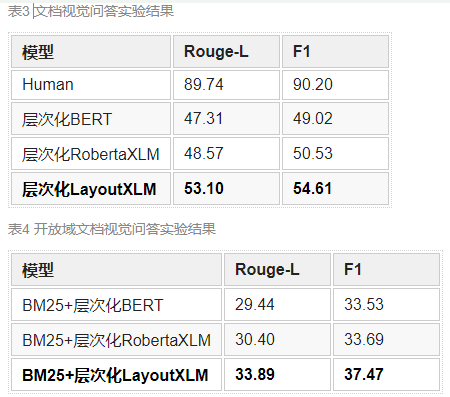
如表3和表4所示,相比于基于純文本預訓練模型的方法,層次化LayoutXLM的性能有明顯提高,然而其整體性能仍與人類表現有一定差距。這表明,一方面布局結構和視覺特征有助于模型理解文檔圖像,另一方面無論是文檔視覺問答亦或是開放域文檔視覺問答均有著較大的提升空間。
6. 結論
本文為了提高開放域問答系統的可擴展能力,使其可以用較低的成本以不同格式的異構文檔作為其信息來源,提出了一個全新的開放域文檔視覺問答任務,直接以從異構文檔轉換得到的文檔圖像集合來回答用戶提問。為了推動該任務的發展,本文提出了中文開放域文檔視覺問答數據集DuReadervis,包含158K文檔圖像和15K問答對。DuReadervis包含三個挑戰:1)長文檔理解;2)噪聲干擾;3)多片段答案抽取。同時,本文提出了一個基線系統并進行了實驗,實驗結果表明現有基線系統和人類表現仍有一定差距,開放域文檔視覺問答任務仍有較大的提升空間。除研究目的外,開放域文檔視覺問答的相關技術已初步應用于諸如汽車、電子、銀行等行業的問答系統中,并在飛槳AI Studio上開放。
審核編輯:郭婷
-
汽車電子
+關注
關注
3037文章
8352瀏覽量
170202 -
數據集
+關注
關注
4文章
1224瀏覽量
25463
原文標題:ACL2022 | 面向中文真實搜索場景的開放域文檔視覺問答數據集
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA助力圖靈新訊美推出企業級多模態視覺大模型融合解決方案
Vector為華域視覺頒發ISO/SAE 21434汽車CSMS流程證書
CADENAS 解決方案的標準化名稱:3Dfindit
中科曙光助力中航結算公司構建私域文檔智能問答系統
OpenAI免費開放ChatGPT搜索功能


Litera Drafting:幫助改進發布文檔的方式(十)
構建高效搜索解決方案,Elasticsearch & Kibana 的完美結合

安森美機器視覺系統解決方案
TE一站式解決方案,助您“域”見未來
面向功能安全應用的汽車開源操作系統解決方案





 工商網監
工商網監
評論