 meta reweighting 策略來增強偽樣本的效果
meta reweighting 策略來增強偽樣本的效果

自增強(self-augmentation)最近在提升低資源場景下的 NER 問題中得到了越來越多的關注,token 替換和表征混合是對于 NER 這類 token 級別的任務很有效的兩種自增強方法。值得注意的是,自增強的方法得到的增強數據有潛在的噪聲,先前的研究是對于特定的自增強方法設計特定的基于規則的約束來降低噪聲。
本文提出了一個聯合的 meta-reweighting 的策略來自然的進行整合。我們提出的方法可以很容易的擴展到其他自增強的方法中,實驗表明,本文的方法可以有效的提升自增強方法的表現。

命名實體識別旨在從非結構化文本中抽取預先定義的命名實體,是 NLP 的一個基礎任務。近期,基于神經網絡的方法推動 NER 任務不斷取得更好的表現,但是其通常需要大規模的標注數據,這在真實場景中是不現實的,因此小樣本設置的 NER 更符合現實需求。
數據自增強是一個小樣本任務可行的解法,對于 token-level 的 NER 任務,token 替換和表征混合是常用的方法。但自增強也有局限性,我們需要為每種特定的自增強方法單獨進行一些設計來降低自增強所帶來的噪聲,緩解噪聲對效果的影響。本文提出了 meta-reweighting 框架將各類方法聯合起來。
首先,放寬前人方法中的約束,得到更多偽樣本。然而這樣會產生更多低質量的增強樣本,為此,我們提出 meta reweighting 策略來控制增強樣本的質量。同時,使用 example reweighting 機制可以很自然的將兩種方法結合在一起。實驗表明,在小樣本場景下,本文提出的方法可以有效提升數據自增強方法的效果,在全監督場景下本文的方法仍然有效。
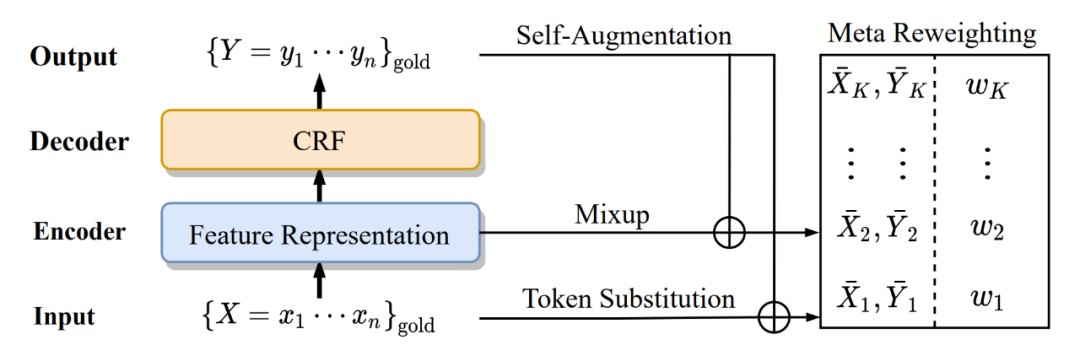
Method
2.1 Baseline
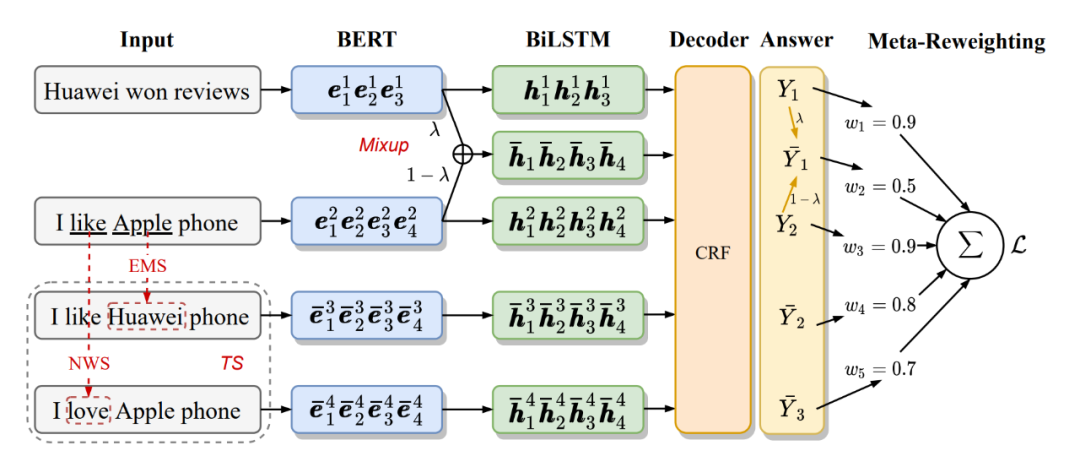
本文的 basic 模型使用 BERT+BiLSTM+CRF 進行 NER 任務。首先給定輸入序列 ,使用預訓練的 BERT 得到每個 token 的表征。
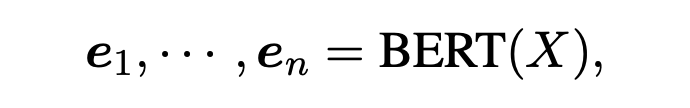
然后使用 BiLSTM 進一步抽取上下文的特征:
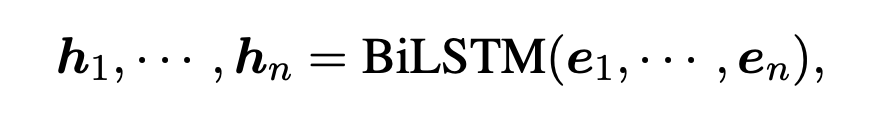
最后解碼過程使用 CRF 進行解碼,先將得到的表征過一層線性層作為初始的標簽分數,定義一個標簽轉移矩陣 T 來建模標簽之間的依賴關系。對于一個標簽序列 ,其分數 計算如下:
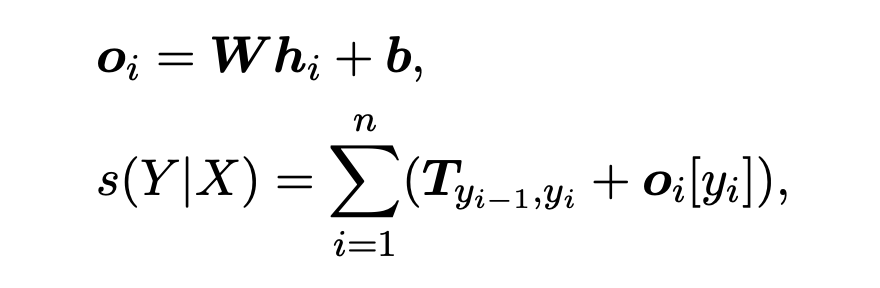
其中 W、b 和 T 是模型的參數,最后使用維特比算法得到最佳的標簽序列。訓練的損失函數采用句子級別的交叉熵損失,對于給定的監督樣本對 (X, Y),其條件概率 P(Y|X) 計算如下:
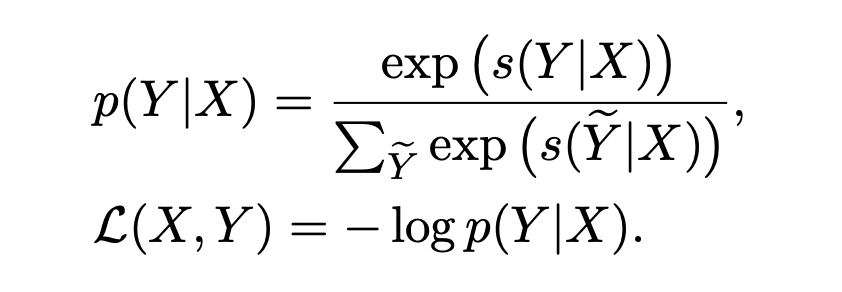
其中 為候選標簽序列。
2.2 自增強方法
2.2.1 Token Substitution(TS)
token 替換是在原始的訓練文本中對部分 token 進行替換得到偽樣本。本文通過構建同義詞詞典來進行 token 替換,詞典中既包含實體詞也包含大量的普通詞。遵循前人的設置,我們將所有屬于同一實體類型的詞當作同義詞,并且添加到實體詞典中,作者將其稱為 entity mention substitution (EMS)。同時,我們也將 token 替換擴展到了“O”類型中,作者將其稱為 normal word substitution (NWS)。作者使用 word2vec 的方法,在 wikidata 上通過余弦相似度找到 k 個最近鄰的詞作為“O”類型詞的同義詞。這里作者設置了參數 (此參數代表 EMS 的占比)來平衡 EMS 和 NWS 的比率,在 entity diversity 和 context diversity 之間達到更好的 trade-off。
2.2.2 Mixup for CRF
不同于 token 替換在原始文本上做增強,mixup 是在表征上進行處理,本文將 mixup 的方法擴展到了 CRF 層。形式上,給定一個樣本對 和 ,首先用 BERT 得到其向量表示 和 。然后通過參數 將兩個樣本混合:
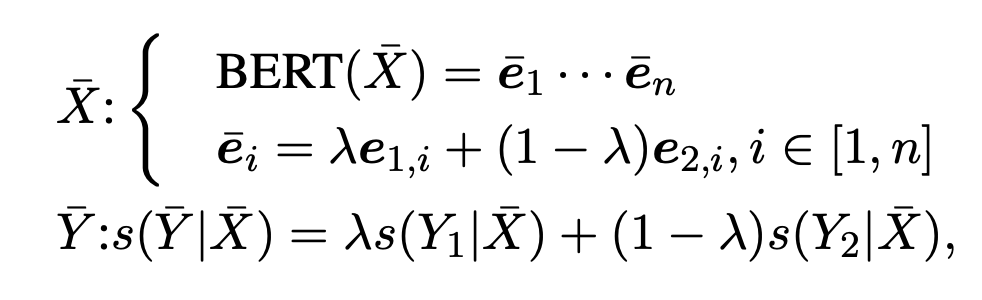
其中,n 為 , 從 分布中采樣。損失函數變為:
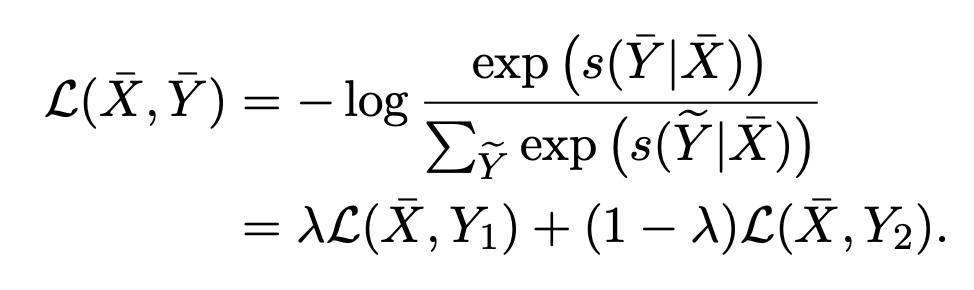
2.3 Meta Reweighting
有別于句子級的分類任務,NER 這類 token 級別的任務對于上下文高度敏感,一些低質量的增強數據會嚴重影響模型的效果。在本文中,作者使用 meta reweighting 策略為 mini batch 中的訓練數據分配樣本級的權重。
在少樣本設置中,我們希望少量的標注樣本能夠引導增強樣本進行模型參數更新。直覺上看,如果增強樣本的數據分布和其梯度下降的方向與標注樣本相似,說明模型能夠從增強樣本中學到更多有用的信息。
算法流程如下:

實驗
3.1 實驗設置
數據集采用 OntoNotes 4、OntoNotes 5、微博和 CoNLL03,所有數據集均采用 BIOES 標注方式。
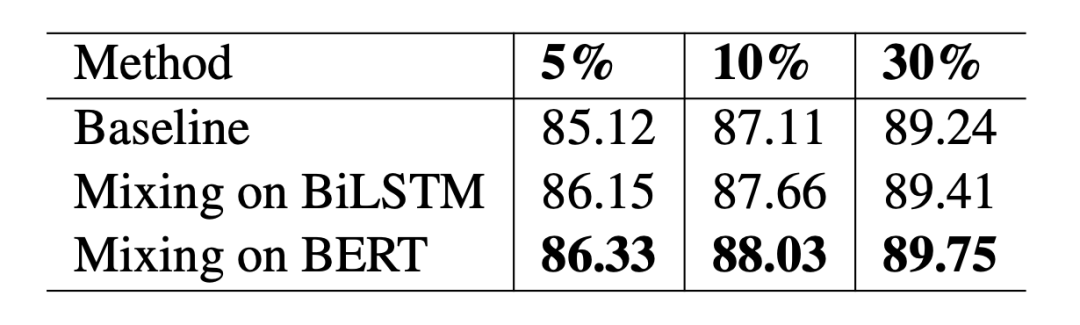
對于 NWS,使用在 wikipedia 上訓練的 GloVe 獲取詞向量,取 top5 最近鄰的詞作為同義詞, 取 0.2, 在 Beta (7, 7) 中進行采樣,評價指標使用 F1 值。3.2 主實驗本文在小樣本設置和全監督設置下都做了實驗,結果如下:
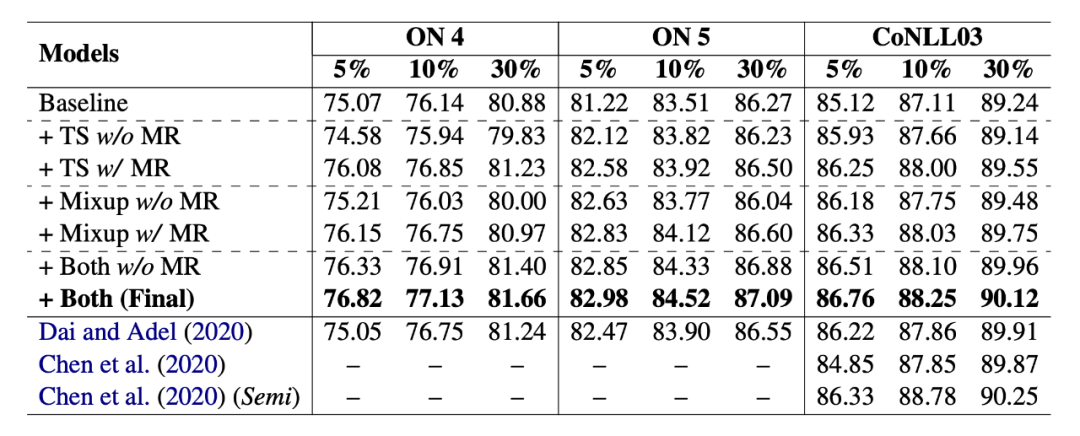
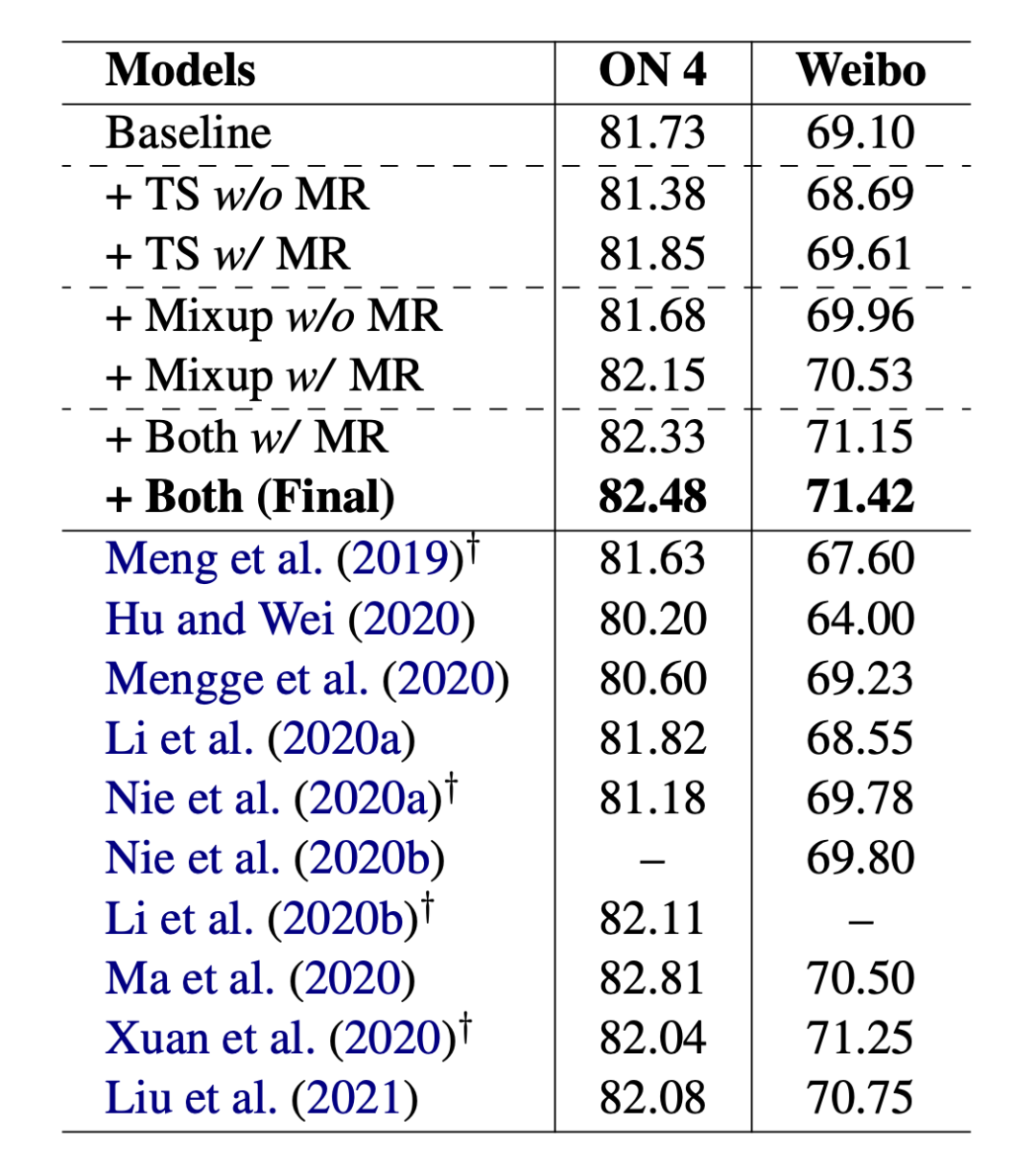
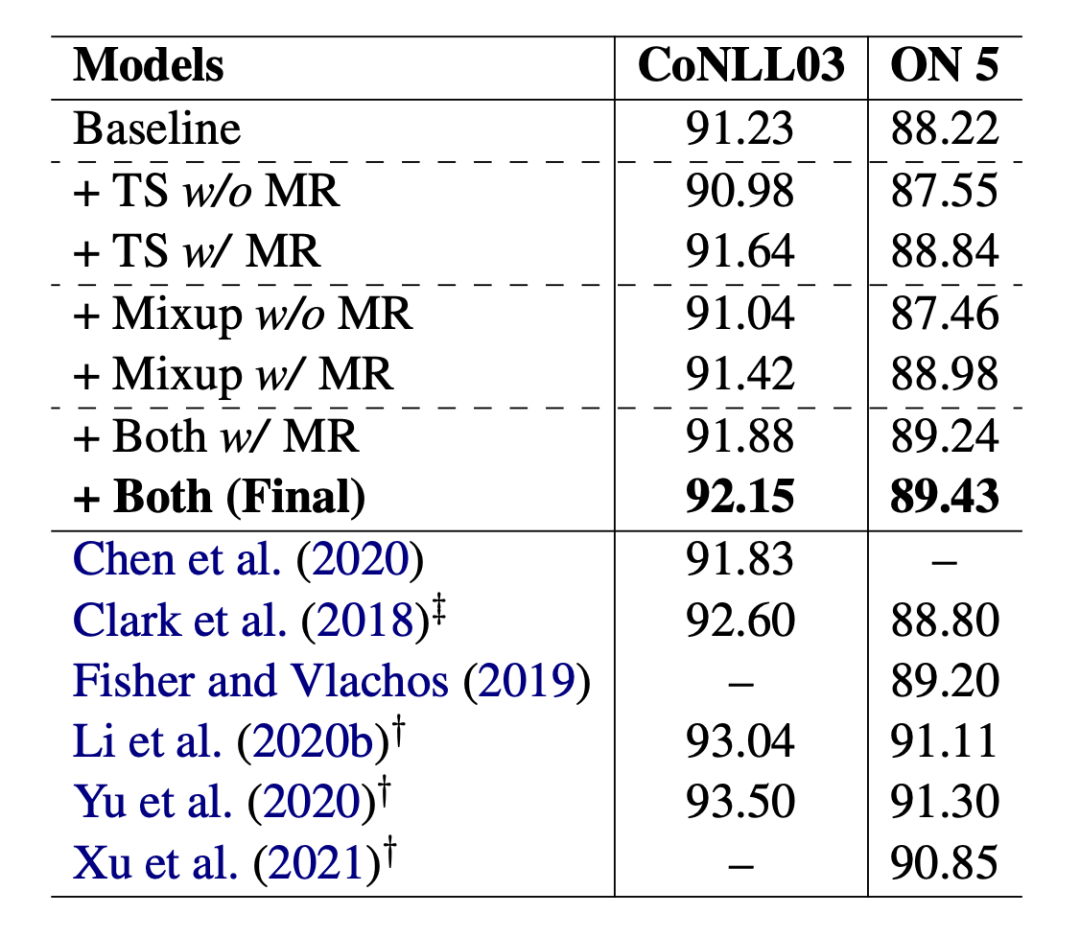
3.3 分析
作者首先在 CoNLL03 5% 設置下做了增強數據量對實驗結果的影響:
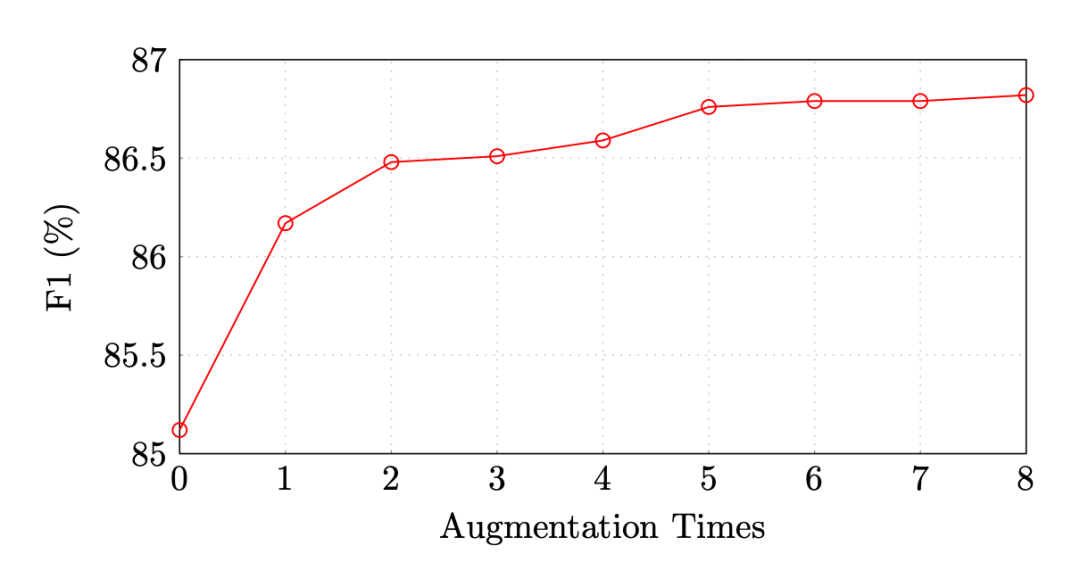
可以看出,在增強數據是原始訓練數據的 5 倍之后,模型的效果就趨于平緩了,單純的增加增強樣本數并不能帶來效果上持續的增長。
作者在三種小樣本設置下對參數 的影響:
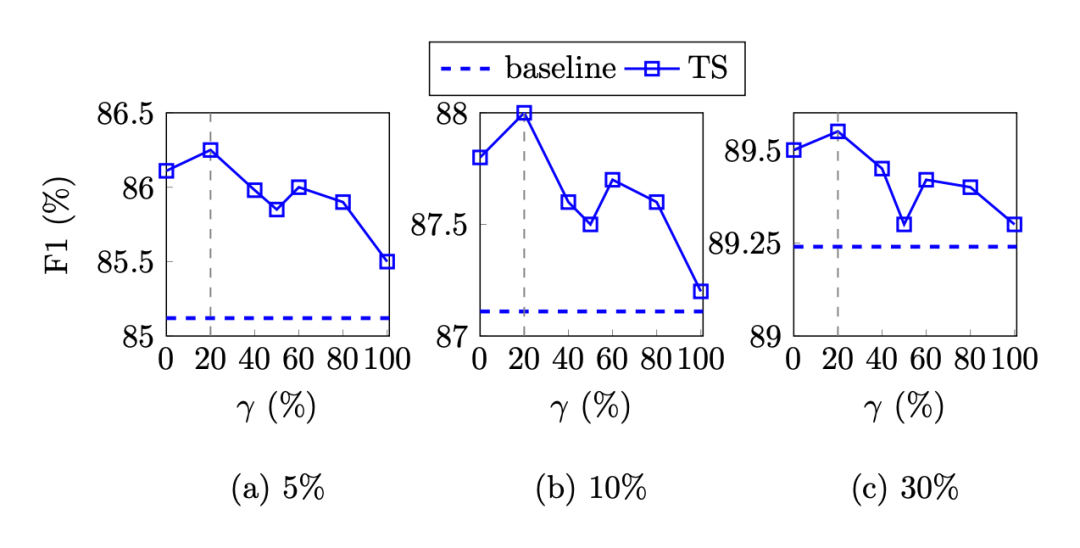
可以看出在 20% 時效果最好,而且相比之下,只使用 NWS 比只使用 EMS 效果更好。可能的一個原因是實體詞在文本中是稀疏的,NWS 能夠產生更多不同的偽樣本。
接著作者分析了 mixup 參數 (Beta 分布參數 )的取值:
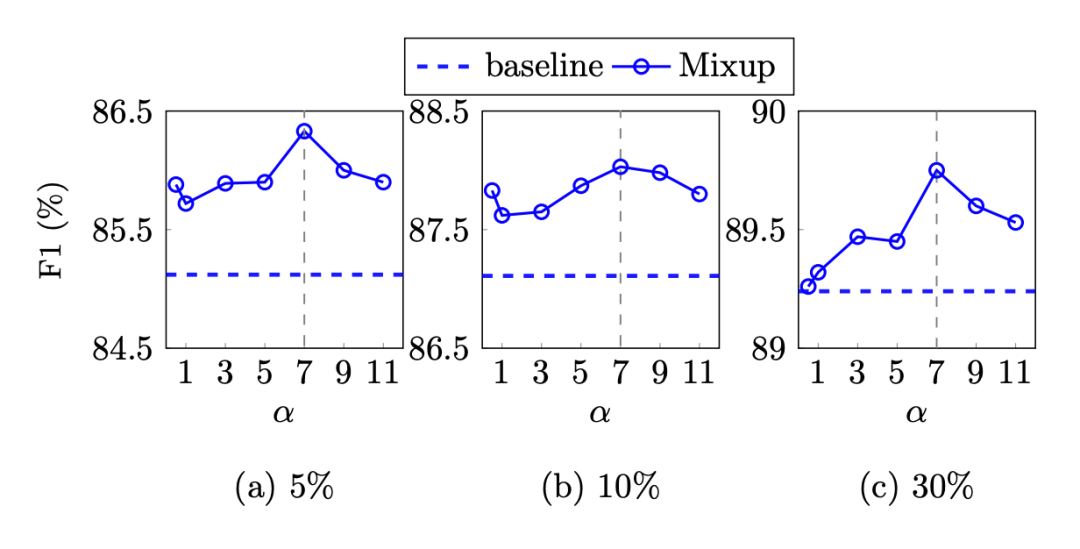
因為本文 Beta 分布的兩個參數都取 ,其期望總是 0.5,當 增大時,分布的方差減小,采樣更容易取到 0.5,實驗結果表明當 取 7 時整體效果最好。最后作者還分析了 mixup 添加在不同位置的不同結果:
總結
本文提出了 meta reweighting 策略來增強偽樣本的效果。是一篇很有啟發性的文章,從梯度的角度出發,結合類似于 MAML 中 gradient by gradient 的思想,用標注樣本來指導偽樣本訓練,為偽樣本的損失加權,對偽樣本的梯度下降的方向進行修正使其與標注樣本更加相似。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103724 -
數據
+關注
關注
8文章
7257瀏覽量
91941 -
解碼
+關注
關注
0文章
186瀏覽量
27894
發布評論請先 登錄
基于GPS偽衛星的多徑效應分析與研究
基于支持樣本的快速增強學習算法
采用偽衛星技術增強GPS定位系統來提高定位性能
Meta與DassaultSystèmes攜手為Solidworks3DCAD軟件提供增強現實支持
Bose推出了一款利用聲音來實現增強現實效果的太陽眼鏡
研究人員們提出了PBA的方法來獲取更為有效的數據增強策略
一種基于偽標簽半監督學習的小樣本調制識別算法
基于k近鄰與高斯噪聲的虛擬困難樣本增強方法
一個聯合的meta-reweighting的策略來自然的進行整合
yolov5和YOLOX正負樣本分配策略






 工商網監
工商網監
評論