") 如何用eBPF優(yōu)化內(nèi)存存儲(chǔ)功能
如何用eBPF優(yōu)化內(nèi)存存儲(chǔ)功能
1.背景
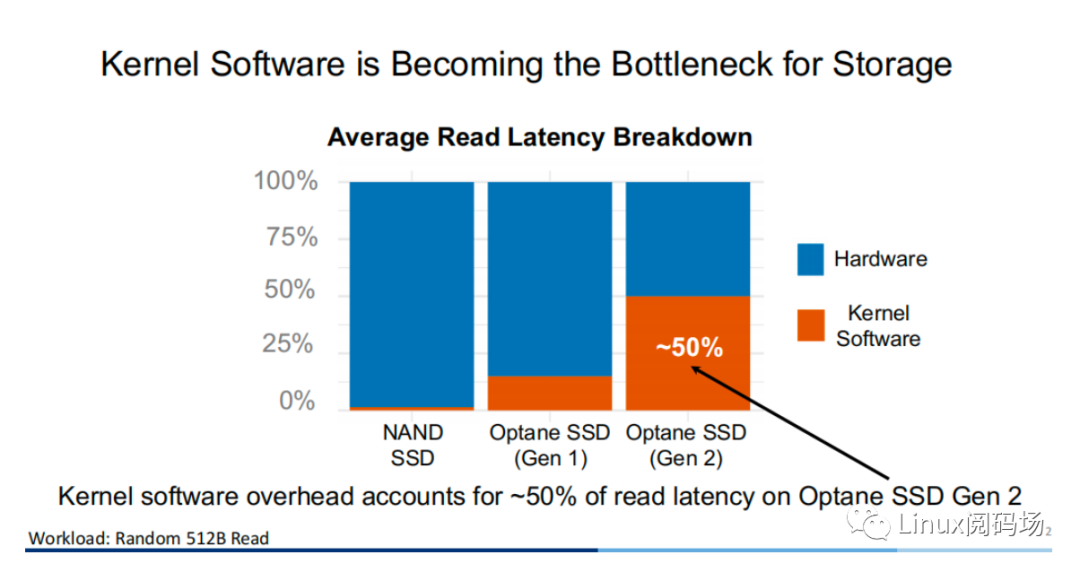
隨著存儲(chǔ)設(shè)備的升級(jí)與發(fā)展,當(dāng)代的存儲(chǔ)設(shè)備性能越來越高,延遲也越來越低。對(duì)于內(nèi)核而言,Linux I/O 存儲(chǔ)棧的軟件所帶來的性能開銷已經(jīng)越來越不可忽視。同樣在 512B 的隨機(jī)讀條件下,在采用二代 Optane SSD 作為存儲(chǔ)設(shè)備的測(cè)試?yán)?中,內(nèi)核軟件( Linux 存儲(chǔ)棧)所帶來的性能開銷已經(jīng)?達(dá) 50%。
2.傳統(tǒng)方式與XRP
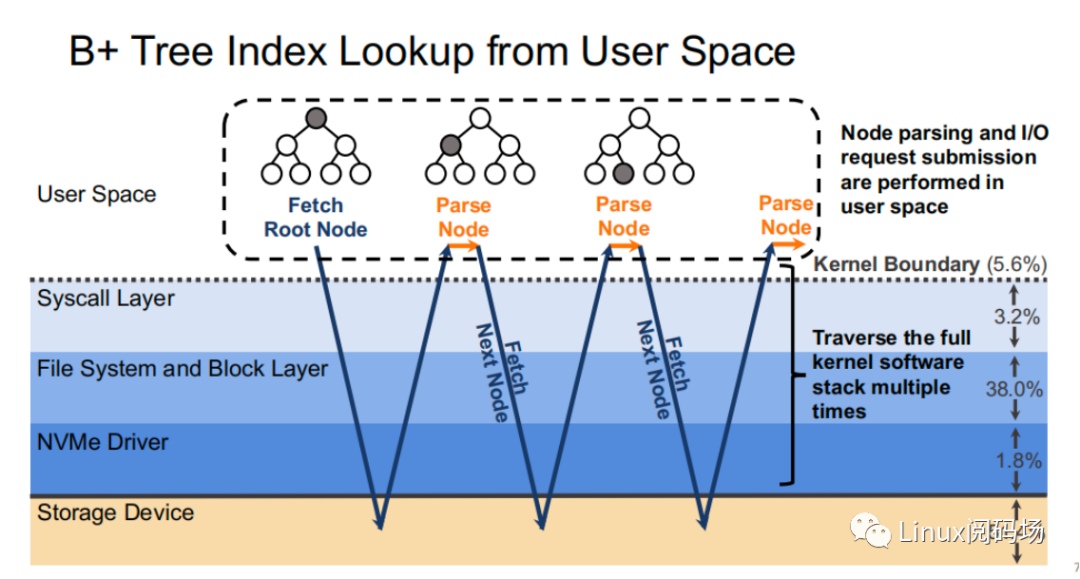
我們來看?個(gè)實(shí)際的例?,假設(shè)現(xiàn)在有?棵樹?為 4 的 B+ tree 存儲(chǔ)于存儲(chǔ)設(shè)備當(dāng)中。當(dāng)我們從根節(jié)點(diǎn)出發(fā),?共需要經(jīng)過三次訪盤才能獲得最終的葉?節(jié)點(diǎn),?中間的索引節(jié)點(diǎn)對(duì)于?戶??沒有意義,但也需要經(jīng)過?個(gè)完整的存儲(chǔ)棧路徑。?每次訪盤的過程中,存儲(chǔ)棧所花費(fèi)的開銷就要整個(gè)存儲(chǔ)路徑的 48.6%。
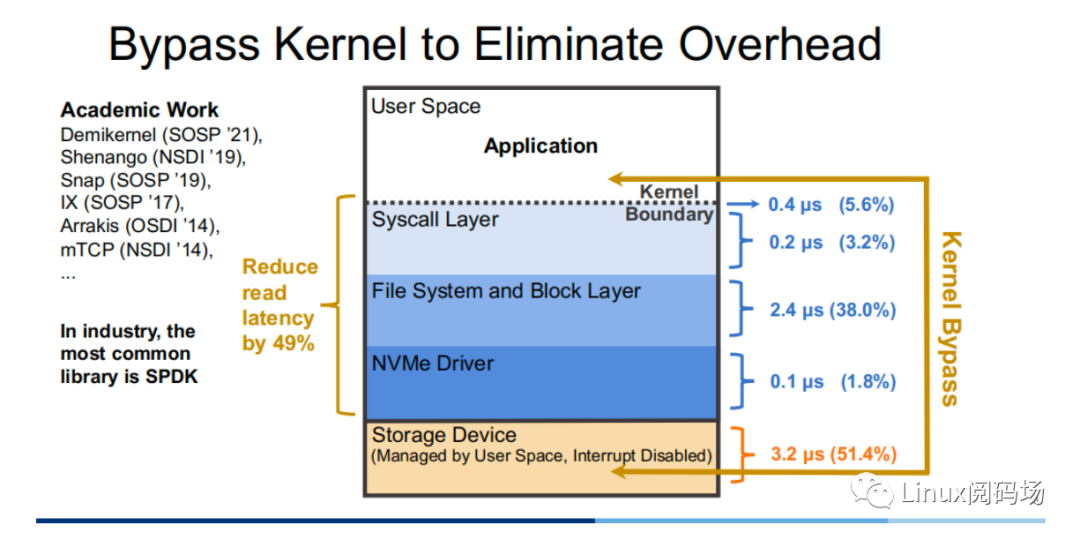
顯然,冗?的存儲(chǔ)棧路徑鉗制了?性能存儲(chǔ)設(shè)備的發(fā)揮,那么?個(gè)直觀的優(yōu)化思路便是通過 Kernel Bypass 的?式,繞開內(nèi)核中存儲(chǔ)棧,以提升存儲(chǔ)性能。?前在學(xué)術(shù)界中,對(duì)于這??的?作有 Demikernel、Shenango、Snap 等,??業(yè)界中最為?泛使?的則是 Intel 的 SPDK。
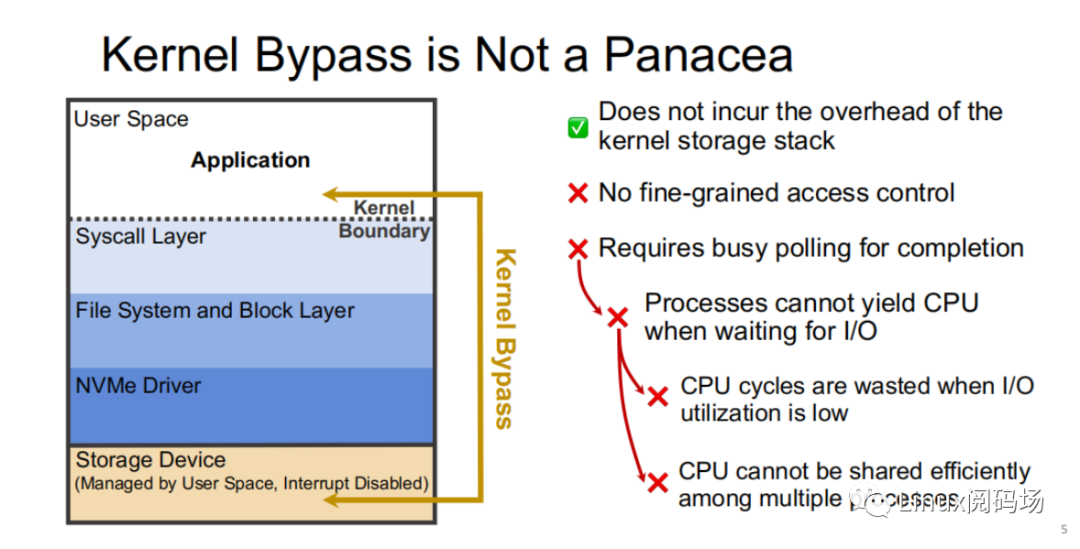
然?,Kernel Bypass 技術(shù)并?銀彈,它雖然能夠降低內(nèi)核存儲(chǔ)棧的開銷,但也存在著如下缺點(diǎn):
1. 沒有適當(dāng)粒度的訪問控制
2. 需要采? polling ?式來判斷 I/O 是否完成,這會(huì)導(dǎo)致在 I/O 利?率低時(shí),Polling 進(jìn)程所在的 CPU ?部分情況下只是在空轉(zhuǎn),浪費(fèi) CPU 周期,同時(shí) CPU 資源不能?效地在多進(jìn)程中共享。
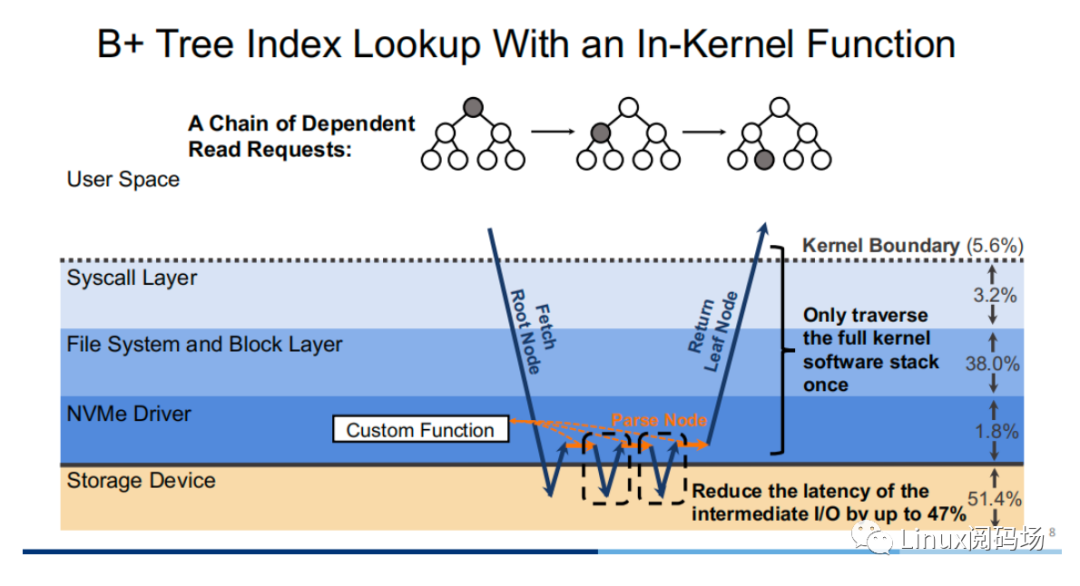
所謂 XRP 的全稱是 eXpress Resubmission Path(快速重提交路徑)。與 SPDK 完全繞開內(nèi)核存儲(chǔ)棧,采? polling的?式來訪問存儲(chǔ)的?式不同,XRP 則是通過將中間請(qǐng)求直接在 NVMe 驅(qū)動(dòng)層進(jìn)? resubmission,從?避免讓中間請(qǐng)求通過冗?的存儲(chǔ)棧后再提交,從?達(dá)到加速的?的。反映到上?的例?當(dāng)中,可以明顯地看到使? XRP 存儲(chǔ)訪問?式中,只有第?次請(qǐng)求和最后?次響應(yīng)會(huì)經(jīng)過?個(gè)完整的存儲(chǔ)棧路徑。顯然,在允許范圍內(nèi),B+ tree的樹?越?,XRP 的加速效果也就越明顯。
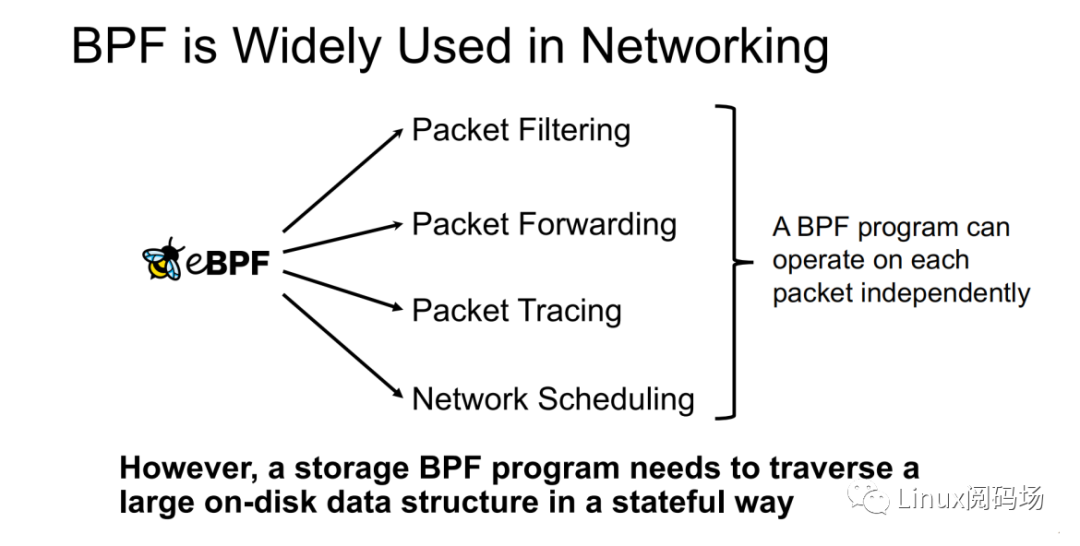
既然優(yōu)化思路有了,那么應(yīng)當(dāng)如何才能將請(qǐng)求重提交于 NVMe 驅(qū)動(dòng)層呢?這?可以借鑒 XDP 的實(shí)現(xiàn)思路。XDP 通過 eBPF 來實(shí)現(xiàn)對(duì)每個(gè)數(shù)據(jù)包進(jìn)?獨(dú)?的操作(數(shù)據(jù)包過濾、數(shù)據(jù)包轉(zhuǎn)發(fā)、數(shù)據(jù)包追蹤、?絡(luò)調(diào)度)。XRP 也可以通過 BPF 程序來實(shí)現(xiàn)。
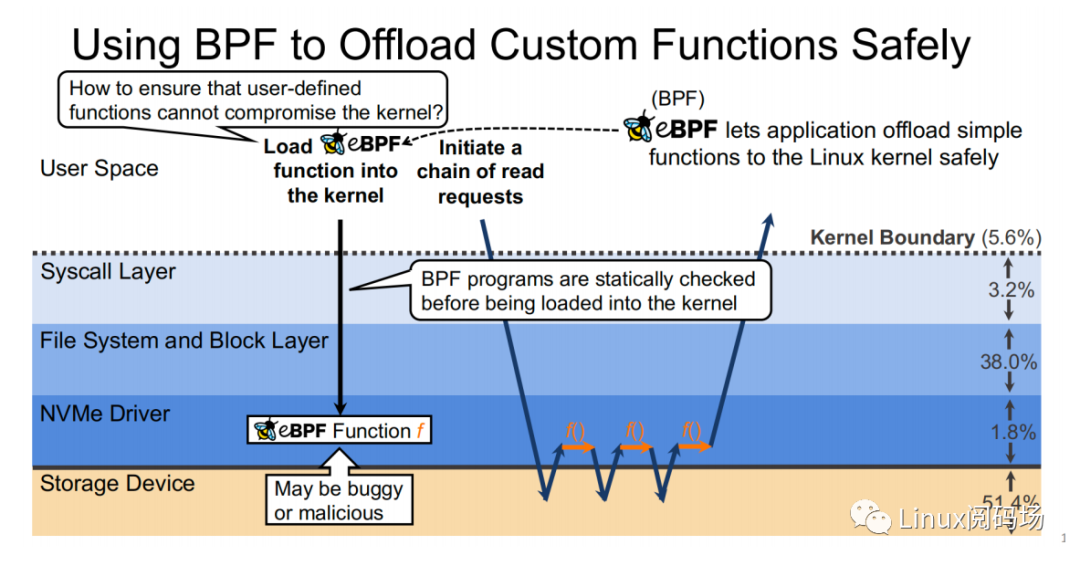

XRP 是?個(gè)使? eBPF 來降低內(nèi)核存儲(chǔ)軟件開銷的系統(tǒng)。它所?臨的挑戰(zhàn)主要有:
1. 如何在 NVMe 驅(qū)動(dòng)層實(shí)現(xiàn)對(duì)?件偏移的翻譯
2. 如何強(qiáng)化 eBPF verifier 以?持存儲(chǔ)應(yīng)?場(chǎng)景
3. 如何重新提交 NVMe 請(qǐng)求
4. 如何與應(yīng)?層 Cache 進(jìn)?交互

XRP 引?了?種新的 BPF 類型(BPF_PROG_TYPE_XRP),包含了 5 個(gè)字段,分別是
1. char* data:?個(gè)緩沖區(qū),?于緩沖從磁盤中讀取出來的數(shù)據(jù)
2. int done:布爾語意,表示 resubmission 邏輯是否應(yīng)當(dāng)返回給 user,還是應(yīng)當(dāng)繼續(xù) resubmitting I/O 請(qǐng)求
3. uint64_t next_addr[16]:邏輯地址數(shù)組,存放的是下次 resubmission 的邏輯地址
4. uint64_t size[16]:存放的是下次 resubmission 的請(qǐng)求的??5. char* scratch:user 和 BPF 函數(shù)的私有空間,?來傳遞從 user 到 BPF 函數(shù)的參數(shù)。BPF 函數(shù)也可以?這段
空間來保存中間數(shù)據(jù)。處于簡單考慮,默認(rèn) scratch 的??是 4KB。
同時(shí),為了避免因存在?限循環(huán)?導(dǎo)致 BPF Verifier 驗(yàn)證失敗,代碼中指定了 B+ tree 的最?扇出數(shù)為
MAX_FANOUT,其值為 16。
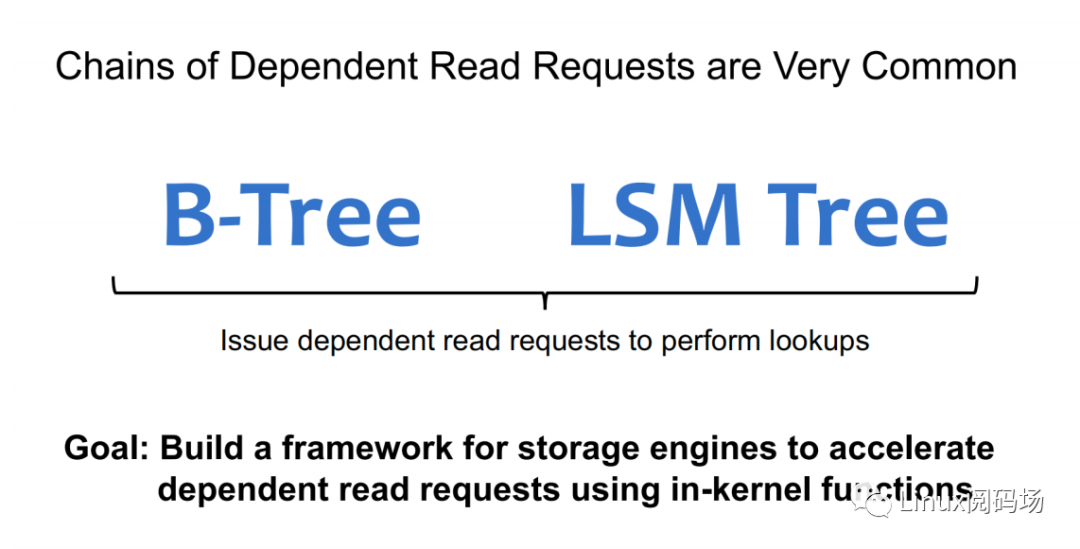
?前,最常?鏈?zhǔn)阶x請(qǐng)求主要有 B-Tree 和 LSM Tree 兩種,? XRP 分別繼承了 BPF-KV(?個(gè)簡易的基于 B+ Tree的鍵值存儲(chǔ)引擎) 和 WIREDTIGER(mongoDB 的后端鍵值存儲(chǔ)引擎)。
3.實(shí)驗(yàn)測(cè)試
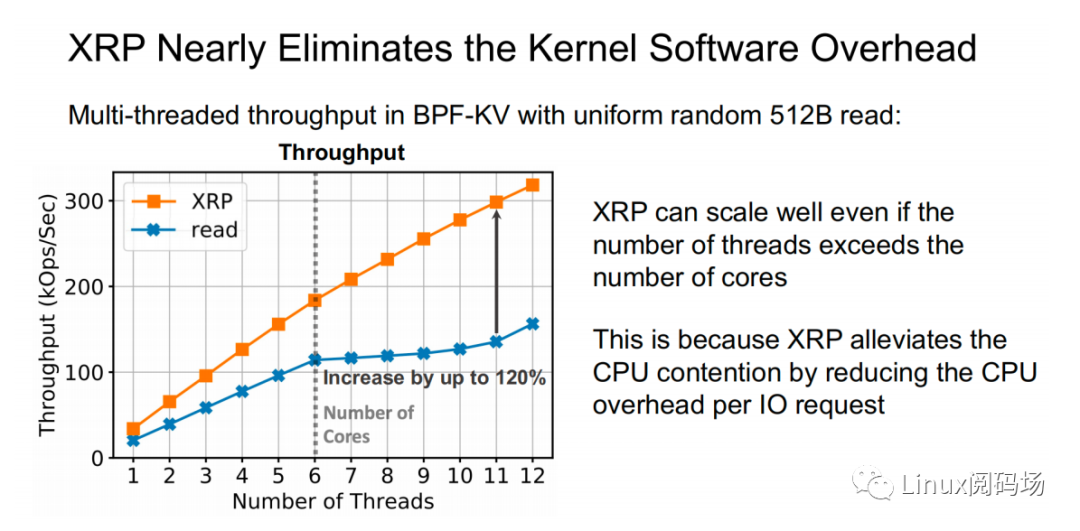
上圖為在 512B 隨機(jī)讀測(cè)試中,標(biāo)準(zhǔn) read 和 XRP 之間的性能對(duì)?測(cè)試。可以看到隨著線程數(shù)的增加,XRP 的吞吐保持線性增?的態(tài)勢(shì),同時(shí) XRP 通過降低每次 I/O 請(qǐng)求時(shí)的 CPU 開銷,從?緩解了 CPU 爭(zhēng)?問題。
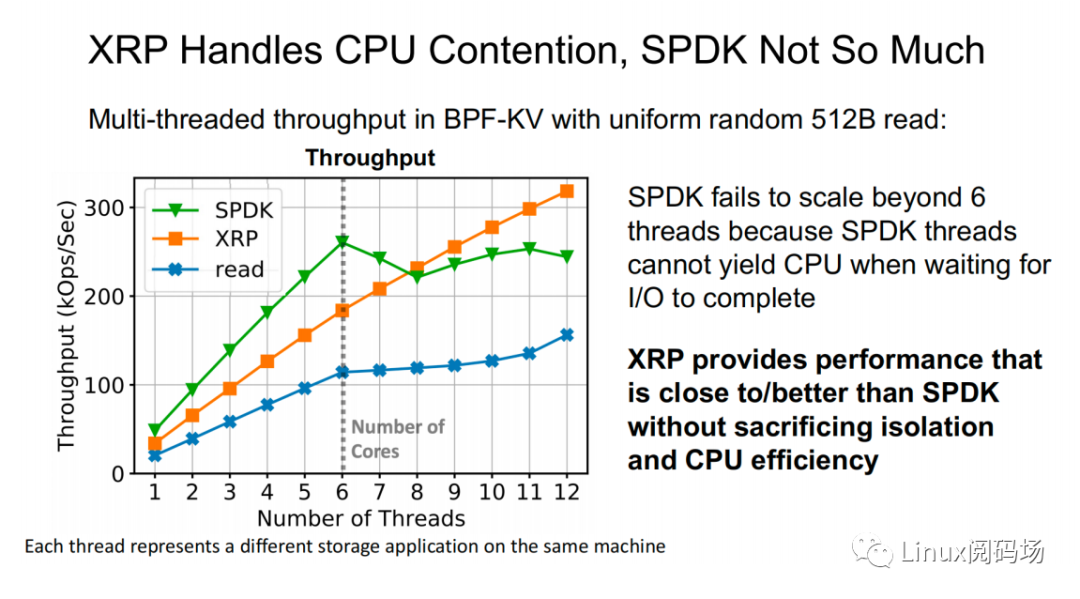
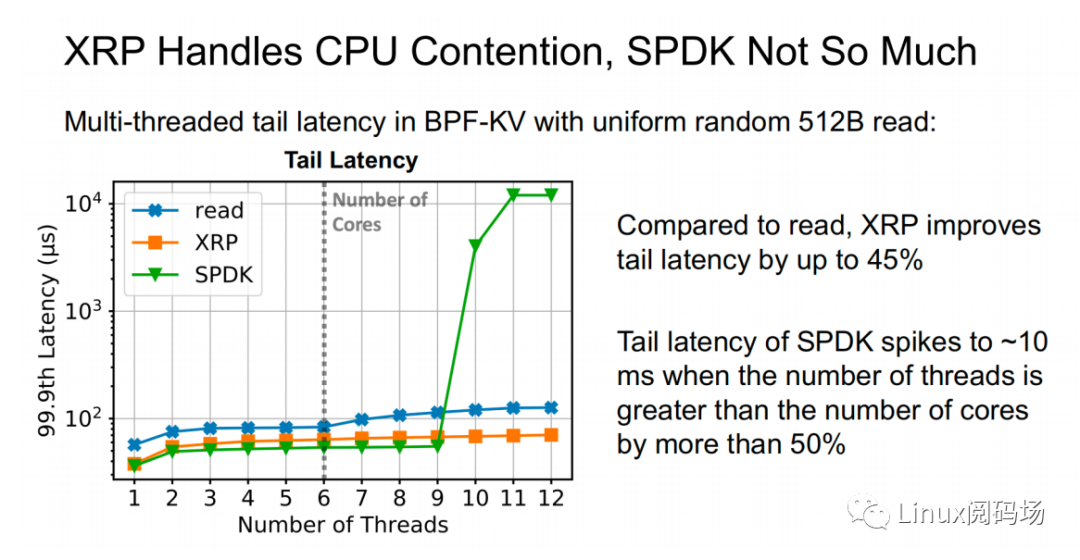
上?兩幅圖中,同樣表示了在 512B 隨機(jī)讀測(cè)試中(CPU 核?數(shù)為 6),標(biāo)準(zhǔn) read、XRP 和 SPDK 之間的吞吐量以及尾延遲的對(duì)?。在線程數(shù)?于等于 CPU 核?數(shù)時(shí),三者性能變化穩(wěn)定,從?到低依次為 SPDK > XRP >read。?當(dāng)線程數(shù)超過了核?數(shù)時(shí),SPDK 性能開始出現(xiàn)嚴(yán)重的下跌,標(biāo)準(zhǔn) read 性能輕微下滑,? XRP 依然保持著穩(wěn)定的線性增?。這主要是因?yàn)?SPDK 采? polling 的?式訪問存儲(chǔ)設(shè)備的完成隊(duì)列,當(dāng)線程數(shù)超過核?數(shù),線程之間對(duì) CPU 的爭(zhēng)奪加上缺乏同步性,會(huì)導(dǎo)致所有線程都經(jīng)歷尾部延遲顯著提升和整體吞吐量的顯著下降。
4.總結(jié)

XRP 是?個(gè)將 BPF 應(yīng)?來通?存儲(chǔ)函數(shù)的加速上的系統(tǒng),它既能享受到 kernel bypass 的性能優(yōu)勢(shì),同時(shí)??須犧牲 CPU 的使?率和訪問控制。?前,XRP 團(tuán)隊(duì)依然在積極地將 XRP 與其他?些流?的鍵值存儲(chǔ)引擎,如 RocksDB進(jìn)?集成。
-
cpu
+關(guān)注
關(guān)注
68文章
11045瀏覽量
216101 -
存儲(chǔ)
+關(guān)注
關(guān)注
13文章
4507瀏覽量
87109 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3111瀏覽量
75017
原文標(biāo)題:XRP:用eBPF優(yōu)化內(nèi)存存儲(chǔ)功能
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于ebpf的性能工具-bpftrace腳本語法
內(nèi)存優(yōu)化王
內(nèi)存分配及Cache優(yōu)化
嵌入式系統(tǒng)內(nèi)存優(yōu)化使用
關(guān)于 eBPF 安全可觀測(cè)性,你需要知道的那些事兒
openEuler 倡議建立 eBPF 軟件發(fā)布標(biāo)準(zhǔn)
如何用全波段測(cè)試法優(yōu)化光器件性能
基于小文件的內(nèi)存云存儲(chǔ)優(yōu)化策略
如何用eBPF寫TCP擁塞控制算法?
eBPF是什么以及eBPF能干什么

美光推出一系列優(yōu)化解決方案應(yīng)對(duì)智能邊緣復(fù)雜內(nèi)存與存儲(chǔ)需求

openEuler倡議建立eBPF軟件發(fā)布標(biāo)準(zhǔn)
基于ebpf的性能工具-bpftrace

ebpf的快速開發(fā)工具--libbpf-bootstrap
eBPF動(dòng)手實(shí)踐系列三:基于原生libbpf庫的eBPF編程改進(jìn)方案簡析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論