 基于多模態語義SLAM框架
基于多模態語義SLAM框架
摘要
 ? 大家好,今天為大家帶來的文章是?Multi-modal Semantic SLAM for Complex Dynamic Environments 同時定位和建圖(SLAM)是許多現實世界機器人應用中最重要的技術之一。靜態環境的假設在大多數 SLAM 算法中很常見,但是對于大多數應用程序來說并非如此。最近關于語義 SLAM 的工作旨在通過執行基于圖像的分割來理解環境中的對象并從場景上下文中區分動態信息。然而,分割結果往往不完善或不完整,這會降低映射的質量和定位的準確性。在本文中,我們提出了一個強大的多模態語義框架來解決復雜和高度動態環境中的 SLAM 問題。我們建議學習更強大的對象特征表示,并將三思而后行的機制部署到主干網絡,從而為我們的基線實例分割模型帶來更好的識別結果。此外,將純幾何聚類和視覺語義信息相結合,以減少由于小尺度物體、遮擋和運動模糊造成的分割誤差的影響。已經進行了徹底的實驗來評估所提出方法的性能。結果表明,我們的方法可以在識別缺陷和運動模糊下精確識別動態對象。此外,所提出的 SLAM 框架能夠以超過 10 Hz 的處理速率有效地構建靜態密集地圖,這可以在許多實際應用中實現。訓練數據和建議的方法都是開源的。?
? 大家好,今天為大家帶來的文章是?Multi-modal Semantic SLAM for Complex Dynamic Environments 同時定位和建圖(SLAM)是許多現實世界機器人應用中最重要的技術之一。靜態環境的假設在大多數 SLAM 算法中很常見,但是對于大多數應用程序來說并非如此。最近關于語義 SLAM 的工作旨在通過執行基于圖像的分割來理解環境中的對象并從場景上下文中區分動態信息。然而,分割結果往往不完善或不完整,這會降低映射的質量和定位的準確性。在本文中,我們提出了一個強大的多模態語義框架來解決復雜和高度動態環境中的 SLAM 問題。我們建議學習更強大的對象特征表示,并將三思而后行的機制部署到主干網絡,從而為我們的基線實例分割模型帶來更好的識別結果。此外,將純幾何聚類和視覺語義信息相結合,以減少由于小尺度物體、遮擋和運動模糊造成的分割誤差的影響。已經進行了徹底的實驗來評估所提出方法的性能。結果表明,我們的方法可以在識別缺陷和運動模糊下精確識別動態對象。此外,所提出的 SLAM 框架能夠以超過 10 Hz 的處理速率有效地構建靜態密集地圖,這可以在許多實際應用中實現。訓練數據和建議的方法都是開源的。?
主要工作與貢獻
? 1. 本文提出了一個魯棒且快速的多模態語義 SLAM 框架,旨在解決復雜和動態環境中的 SLAM 問題。具體來說,將僅幾何聚類和視覺語義信息相結合,以減少由于小尺度對象、遮擋和運動模糊導致的分割誤差的影響。 2. 本文提出學習更強大的對象特征表示,并將三思機制部署到主干網絡,從而為基線實例分割模型帶來更好的識別結果。 3. 對所提出的方法進行了全面的評估。結果表明,本文的方法能夠提供可靠的定位和語義密集的地圖
算法流程
? 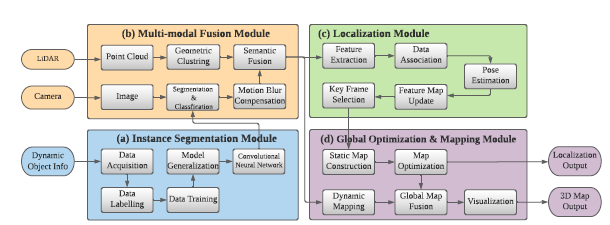 圖 2 是框架的概述。它主要由四個模塊組成,分別是實例分割模塊、多模態融合模塊、定位模塊和全局優化與映射模塊。 1.實例分割和語義學習 使用2D實例分割網絡,一張圖像的實例分割結果:
圖 2 是框架的概述。它主要由四個模塊組成,分別是實例分割模塊、多模態融合模塊、定位模塊和全局優化與映射模塊。 1.實例分割和語義學習 使用2D實例分割網絡,一張圖像的實例分割結果: 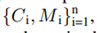 C代表類別,M是物體的掩碼信息,n代表當前圖像中存在物體數量。 圖像在空間上被分成 N × N 個網格單元。如果一個對象的中心落入一個網格單元,該網格單元負責分別預測類別分支Bc和掩碼分支P m 中對象的語義類別Cij和語義掩碼Mij:
C代表類別,M是物體的掩碼信息,n代表當前圖像中存在物體數量。 圖像在空間上被分成 N × N 個網格單元。如果一個對象的中心落入一個網格單元,該網格單元負責分別預測類別分支Bc和掩碼分支P m 中對象的語義類別Cij和語義掩碼Mij: 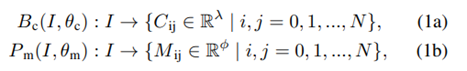 λ 是類的數量。φ 是網格單元的總數。 為了滿足實時性的要求:采用SOLOv2 的輕量級版本,但精度較低,可實現實時實例分割。 為了提高分割精度:實施了多種方法來在骨干網絡中構建更有效和更健壯的特征表示鑒別器。 輸出是每個動態對象的像素級實例掩碼,以及它們對應的邊界框和類類型。為了更好地將動態信息集成到 SLAM 算法中,輸出二進制掩碼被轉換為包含場景中所有像素級實例掩碼的單個圖像。蒙版落在其上的像素被認為是“動態狀態”,否則被認為是“靜態”。然后將二進制掩碼應用于語義融合模塊以生成 3D 動態掩碼。 2.多模態融合 1.移動模糊補償: 目前實例分割的性能已經是不錯的,但是移動的物體會出現物體識別不完整 導致物體的邊界不明確 最終影響定位精度。因此,本文首先實現形態膨脹,將 2D 像素級掩模圖像與結構元素進行卷積,以逐漸擴展動態對象的區域邊界。形態膨脹結果標志著動態對象周圍的模糊邊界。我們將動態對象及其邊界作為動態信息,將在多模態融合部分進一步細化。 2.幾何聚類和語義融合: 通過歐幾里得空間的連通性分析進行補償也在本文的工作中實現。實例分割網絡在大多數實際情況下都具有出色的識別能力,但是由于區域之間的模糊像素,運動模糊限制了分割性能,導致了不希望的分割錯誤。因此,將點云聚類結果和分割結果結合起來,以更好地細化動態對象。特別是,對幾何信息進行連通性分析,并與基于視覺的分割結果合并。 為了提高工作效率,首先將 3D 點云縮小以減少數據規模,并將其用作點云聚類的輸入。然后將實例分割結果投影到點云坐標上,對每個點進行標注。當大多數點(90%)是動態標記點時,點云簇將被視為動態簇。當靜態點靠近動態點簇時,它會被重新標記為動態標簽。并且當附近沒有動態點聚類時,動態點將被重新標記。 3.定位與位姿估計 1.特征提取: 多模態動態分割后,點云分為動態點云PD和靜態點云PS。基于原先之前的工作,靜態點云隨后用于定位和建圖模塊。與現有的 SLAM 方法(如 LOAM )相比,原先之前的工作中提出的框架能夠支持 30 Hz 的實時性能,速度要快幾倍。與 ORB-SLAM2和 VINS-MONO 等視覺 SLAM 相比,它還可以抵抗光照變化。對于每個靜態點 pk ∈ PS ,可以在歐幾里得空間中通過半徑搜索來搜索其附近的靜態點集 Sk。讓 |S|是集合 S 的基數,因此局部平滑度定義為:
λ 是類的數量。φ 是網格單元的總數。 為了滿足實時性的要求:采用SOLOv2 的輕量級版本,但精度較低,可實現實時實例分割。 為了提高分割精度:實施了多種方法來在骨干網絡中構建更有效和更健壯的特征表示鑒別器。 輸出是每個動態對象的像素級實例掩碼,以及它們對應的邊界框和類類型。為了更好地將動態信息集成到 SLAM 算法中,輸出二進制掩碼被轉換為包含場景中所有像素級實例掩碼的單個圖像。蒙版落在其上的像素被認為是“動態狀態”,否則被認為是“靜態”。然后將二進制掩碼應用于語義融合模塊以生成 3D 動態掩碼。 2.多模態融合 1.移動模糊補償: 目前實例分割的性能已經是不錯的,但是移動的物體會出現物體識別不完整 導致物體的邊界不明確 最終影響定位精度。因此,本文首先實現形態膨脹,將 2D 像素級掩模圖像與結構元素進行卷積,以逐漸擴展動態對象的區域邊界。形態膨脹結果標志著動態對象周圍的模糊邊界。我們將動態對象及其邊界作為動態信息,將在多模態融合部分進一步細化。 2.幾何聚類和語義融合: 通過歐幾里得空間的連通性分析進行補償也在本文的工作中實現。實例分割網絡在大多數實際情況下都具有出色的識別能力,但是由于區域之間的模糊像素,運動模糊限制了分割性能,導致了不希望的分割錯誤。因此,將點云聚類結果和分割結果結合起來,以更好地細化動態對象。特別是,對幾何信息進行連通性分析,并與基于視覺的分割結果合并。 為了提高工作效率,首先將 3D 點云縮小以減少數據規模,并將其用作點云聚類的輸入。然后將實例分割結果投影到點云坐標上,對每個點進行標注。當大多數點(90%)是動態標記點時,點云簇將被視為動態簇。當靜態點靠近動態點簇時,它會被重新標記為動態標簽。并且當附近沒有動態點聚類時,動態點將被重新標記。 3.定位與位姿估計 1.特征提取: 多模態動態分割后,點云分為動態點云PD和靜態點云PS。基于原先之前的工作,靜態點云隨后用于定位和建圖模塊。與現有的 SLAM 方法(如 LOAM )相比,原先之前的工作中提出的框架能夠支持 30 Hz 的實時性能,速度要快幾倍。與 ORB-SLAM2和 VINS-MONO 等視覺 SLAM 相比,它還可以抵抗光照變化。對于每個靜態點 pk ∈ PS ,可以在歐幾里得空間中通過半徑搜索來搜索其附近的靜態點集 Sk。讓 |S|是集合 S 的基數,因此局部平滑度定義為: 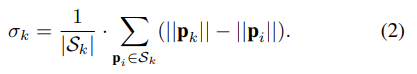 邊緣特征由 σk 大的點定義,平面特征由 σk 小的點定義。 2.數據關聯: 通過最小化點到邊緣和點到平面的距離來計算最終的機器人位姿。對于邊緣特征點 pE ∈ PE ,可以通過 p^E = T·pE 將其轉換為局部地圖坐標,其中 T ∈ SE(3) 是當前位姿。從局部邊緣特征圖中搜索 2 個最近的邊緣特征 p 1 E 和 p 2 E,點到邊緣殘差定義:
邊緣特征由 σk 大的點定義,平面特征由 σk 小的點定義。 2.數據關聯: 通過最小化點到邊緣和點到平面的距離來計算最終的機器人位姿。對于邊緣特征點 pE ∈ PE ,可以通過 p^E = T·pE 將其轉換為局部地圖坐標,其中 T ∈ SE(3) 是當前位姿。從局部邊緣特征圖中搜索 2 個最近的邊緣特征 p 1 E 和 p 2 E,點到邊緣殘差定義: 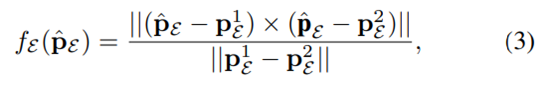 類似地,給定一個平面特征點 pL ∈ PL 及其變換點 p^L = T·pL,我們可以從局部平面圖中搜索 3 個最近點 。點到平面殘差定義為:
類似地,給定一個平面特征點 pL ∈ PL 及其變換點 p^L = T·pL,我們可以從局部平面圖中搜索 3 個最近點 。點到平面殘差定義為: 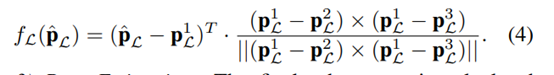 3.位姿估計: 通過最小化點到平面和點到邊緣殘差的總和來計算最終的機器人位姿:
3.位姿估計: 通過最小化點到平面和點到邊緣殘差的總和來計算最終的機器人位姿: 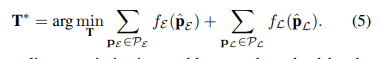 4.特征地圖更新和關鍵幀選擇: 一旦位姿優化解決,特征點將被更新到局部地圖和平面地圖當中。這些點將被用于一下幀的數據關聯。當平移或者旋轉的值大于閾值時候,該幀將被選作關鍵幀。 4.全局地圖構建 全局語義地圖由靜態地圖和動態地圖構成。視覺信息用于構建測色密集靜態地圖。視覺信息能夠反投影3D點到圖像平面。為防止內存溢出的問題采用3d is here: Point cloud library (pcl)。
4.特征地圖更新和關鍵幀選擇: 一旦位姿優化解決,特征點將被更新到局部地圖和平面地圖當中。這些點將被用于一下幀的數據關聯。當平移或者旋轉的值大于閾值時候,該幀將被選作關鍵幀。 4.全局地圖構建 全局語義地圖由靜態地圖和動態地圖構成。視覺信息用于構建測色密集靜態地圖。視覺信息能夠反投影3D點到圖像平面。為防止內存溢出的問題采用3d is here: Point cloud library (pcl)。
實驗結果
? 1.數據獲取  在自動駕駛、智能倉儲物流等諸多場景中,人往往被視為動態對象。因此,本文從 COCO 數據集中選擇了 5,000 張人體圖像。在實驗中,所提出的方法在倉庫環境中進行評估,如圖 4 所示。除了將人視為動態對象之外,先進的工廠還需要人與機器人和機器人與機器人之間的協作,因此自動導引車 ( AGV)也是潛在的動態對象。因此,總共收集了 3,000 張 AGV 圖像來訓練實例分割網絡,其中一些 AGV 如圖 4 所示。 2.評估實例分割性能 評估 COCO 數據集上關于分割損失和平均精度(mAP)的分割性能。該評估的目的是將我們采用的實例分割網絡 SOLOv2 與所提出的方法進行比較。結果如表I所示。
在自動駕駛、智能倉儲物流等諸多場景中,人往往被視為動態對象。因此,本文從 COCO 數據集中選擇了 5,000 張人體圖像。在實驗中,所提出的方法在倉庫環境中進行評估,如圖 4 所示。除了將人視為動態對象之外,先進的工廠還需要人與機器人和機器人與機器人之間的協作,因此自動導引車 ( AGV)也是潛在的動態對象。因此,總共收集了 3,000 張 AGV 圖像來訓練實例分割網絡,其中一些 AGV 如圖 4 所示。 2.評估實例分割性能 評估 COCO 數據集上關于分割損失和平均精度(mAP)的分割性能。該評估的目的是將我們采用的實例分割網絡 SOLOv2 與所提出的方法進行比較。結果如表I所示。 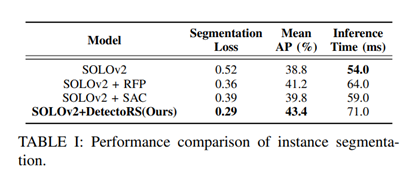 分割結果在圖 3 中進一步可視化:
分割結果在圖 3 中進一步可視化:  3. 稠密建圖和動態跟蹤 建圖如 圖5所示,能夠識別潛在移動的物體并且從靜態地圖中將其分離開來。
3. 稠密建圖和動態跟蹤 建圖如 圖5所示,能夠識別潛在移動的物體并且從靜態地圖中將其分離開來。  定位結果 如圖6所示:
定位結果 如圖6所示: 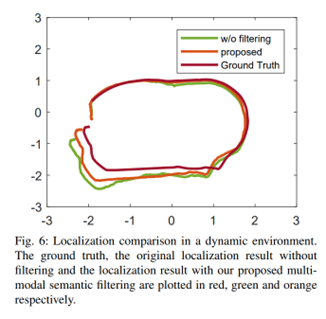 4.定位漂移的消融實驗
4.定位漂移的消融實驗 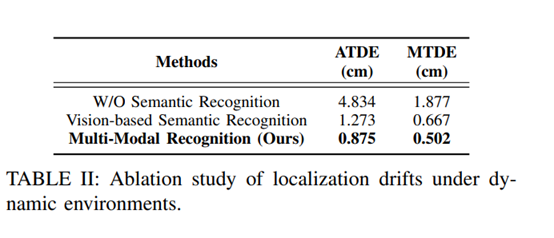
-
3D
+關注
關注
9文章
2955瀏覽量
110156 -
應用程序
+關注
關注
38文章
3324瀏覽量
58814 -
SLAM算法
+關注
關注
0文章
11瀏覽量
2599
原文標題:復雜動態環境的多模態語義 SLAM(arxiv 2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

HOOFR-SLAM的系統框架及其特征提取
多模態生物特征識別系統框架
高仙SLAM具體的技術是什么?SLAM2.0有哪些優勢?
基于語義耦合相關的判別式跨模態哈希特征表示學習算法

自動駕駛深度多模態目標檢測和語義分割:數據集、方法和挑戰

TRO新文:用于數據關聯、建圖和高級任務的對象級SLAM框架
中科大&字節提出UniDoc:統一的面向文字場景的多模態大模型
DreamLLM:多功能多模態大型語言模型,你的DreamLLM~

用語言對齊多模態信息,北大騰訊等提出LanguageBind,刷新多個榜單

OneLLM:對齊所有模態的框架!
利用VLM和MLLMs實現SLAM語義增強






 工商網監
工商網監
評論