 前后端數據接口協作提效實踐
前后端數據接口協作提效實踐
導讀
introduction
在大部分場景中,前后端可以在開發前約定好數據接口,雙方能夠圍繞約定并行地完成開發和自測。然而在大型系統中一些后端模塊有時并非直連前端,在它們之間可能包含一些其它模塊的處理過程,為了保證數據真實有效,前端需要搭建整套環境來調試渲染效果,導致效率和研發體驗不斷劣化。本文主要介紹百度商業前端團隊結合接口平臺和數據直達能力優化前后端協作效率的嘗試,有效的提升了團隊協作效能。
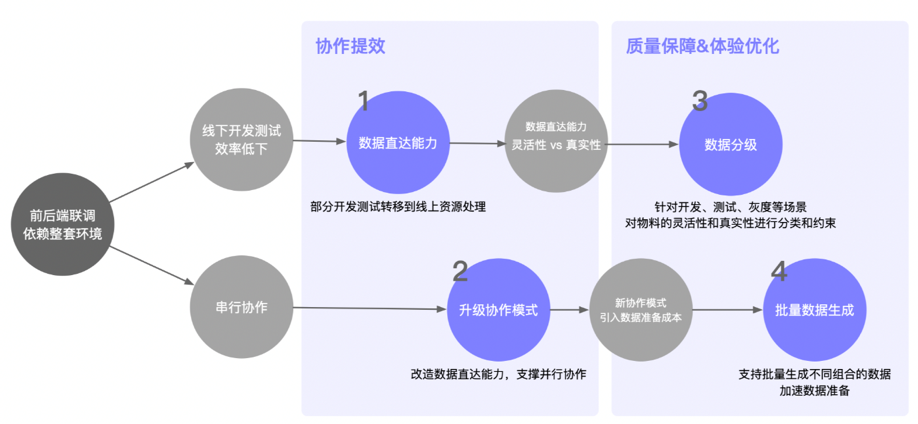
一、實踐方案
GEEK TALK 我們的實踐主要分為兩大階段:
1. 協作提效;
2. 質量保障&體驗優化。
其中協作提效包括基礎能力建設和協作模式升級落地;質量保障&研發體驗是在協作提效的基礎上,對業務質量保障和極端場景所遇到的問題提出的一些解決方案。
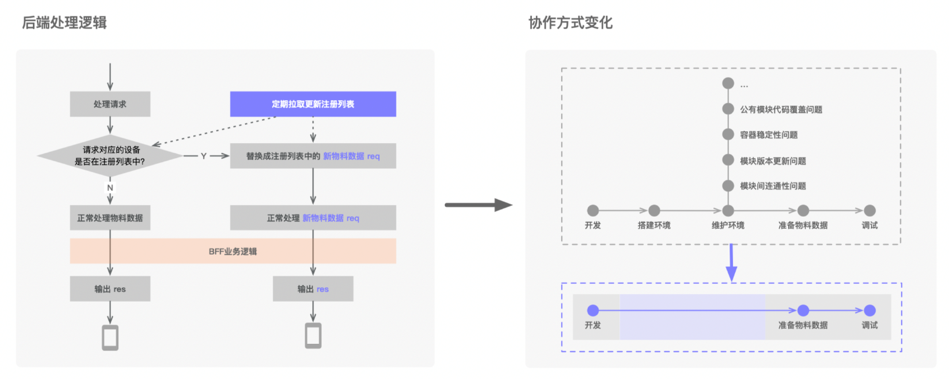
二、數據直達能力
GEEK TALK 我們團隊所維護的后端模塊是一個BFF層,負責適配上游和前端模塊的數據,和前端業務聯系非常緊密。然而由于該層和前端之間還包含了一些策略和聚合的處理邏輯,大家在開發自測過程中沒辦法直接使用樁數據來預覽效果,前端為了調試功能只能維護多套環境,除去環境搭建本身需要消耗大把時間之外,模塊連通性排查、資源協調,環境更新都會影響前端的工作效率。 為了減少維護環境帶來的精力消耗,我們在實踐初期嘗試過多次環境管理優化,效果都不是很理想,一方面有限的環境資源始終沒辦法很好地滿足頻繁迭代的需要,另一方面環境提供方也疲于應對各種各樣的問題,所以我們就想能不能不再維護線下環境,而是將開發測試的工作轉移到線上環境上去進行,也就是讓后端能夠同時處理線上和線下數據請求,使前端在連接線上環境時看到線下數據的渲染結果。 基于這個思路,我們在后端隔離出一套旁支邏輯定時地從Redis拉取線下物料數據和對應的設備信息,其中設備信息是某臺手機或者某個瀏覽器唯一id,當這些設備所對應的請求到達時,后端就把它當作一個特殊請求替換原有請求成線下數據,接著繼續之后的處理過程,前端只需要將數據和設備信息寫入到Redis就能接收到線下數據的處理結果,這樣前端就像在使用一套始終保持最新版本的常駐環境,不會再被各種各樣的環境維護問題消耗精力,雙方都能在協作過程中更關注業務邏輯本身。
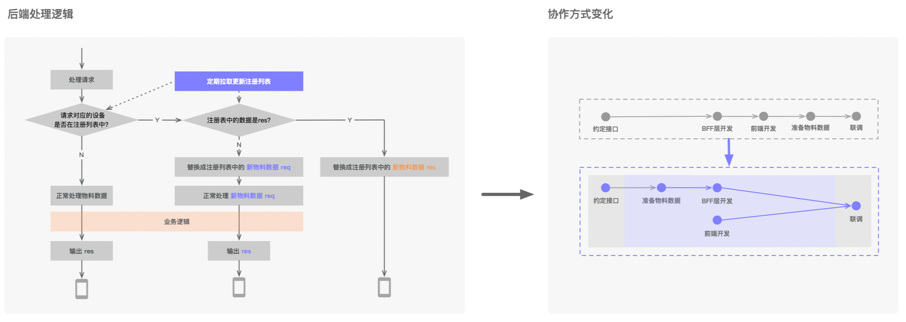
三、升級協作模式
GEEK TALK 借助數據直達能力,我們成功解決了環境維護困難的問題,大幅地提升了聯調階段的效率,但其實我們在開發階段的協作仍然存在著一些問題。在能力建設初期我們只支持了請求數據的替換,前端沒辦法在后端代碼上線之前開始開發,這樣串行的協作模式顯然是有問題的,所以我們就想能不能基于數據直達能力擴展出一套常規的樁服務。 為了實現樁服務,我們在需要作為樁輸出給前端的數據上添加了特殊標識,當后端識別到攜帶特殊標識的數據請求時就會跳過后續的處理邏輯,直接返回結果給下游模塊。這種替換返回的模式能夠讓后端在開發前就將線下樁數據交付給前端使用,使前后端能夠并行協作。
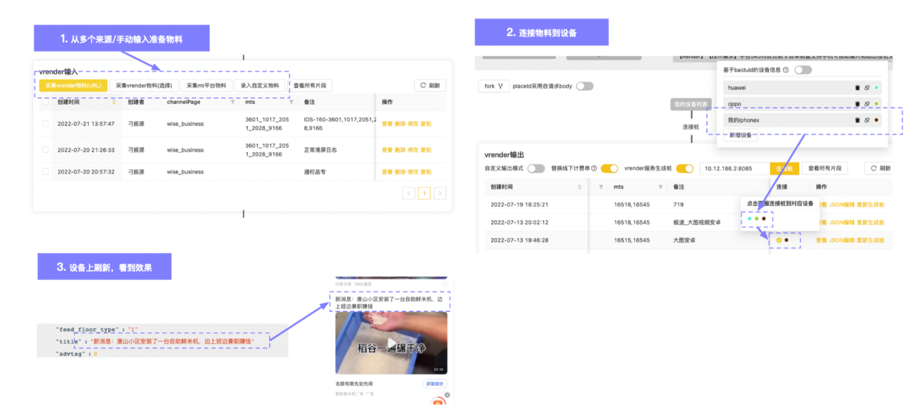
為了減少學習和操作成本,我們將以上所介紹的能力封裝成平臺提供給團隊使用,后端可以按照項目為維度編輯和交付數據,前端可以拿這些數據去和設備做連接,然后直接在app上刷新就可以看到效果。
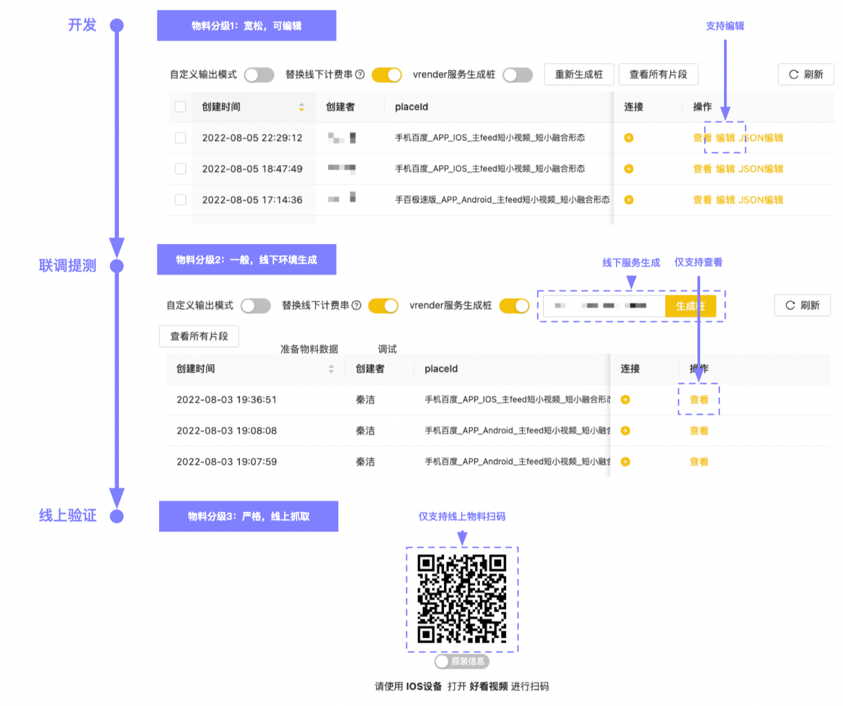
四、數據分級
GEEK TALK 為了改造前后端協作模式,我們在開發過程中使用的其實都是樁數據,這樣可能會導致數據和最后真實邏輯所輸出的結果存在差異,這些差異可能會暴露到線上影響業務功能,所以如果缺少有效的措施去約束數據使用的話,那么質量風險會變得難以控制。 為此,我們將數據的使用根據規則和應用場景劃分成三種類型:手動生成、線下后端生成、線上后端生成。

可以看到,數據的約束規則隨著項目的推進是逐步收緊的。在開發前期后端能使用編輯生成出的樁數據快速交付給前端,讓前端完成單模塊開發自測;在聯調階段,我們的數據是由后端所開發完成的代碼邏輯生成而來的,由于這部分數據需要保證一定真實性,所以不再支持編輯,這樣數據就能夠匹配上后端即將上線的邏輯;而在后端上線完成之后,前端能夠從線上檢索系統采集到真實物料數據,通過掃碼等方式進行效果預覽,這樣同時從數據和代碼邏輯兩方面保證了真實性。 通過上述對數據分級的規劃,我們保證了協作過程在高效并行運轉的同時,始終遵循一套流程標準,能夠有效地保障了業務的交付質量。
五、優化平臺體驗
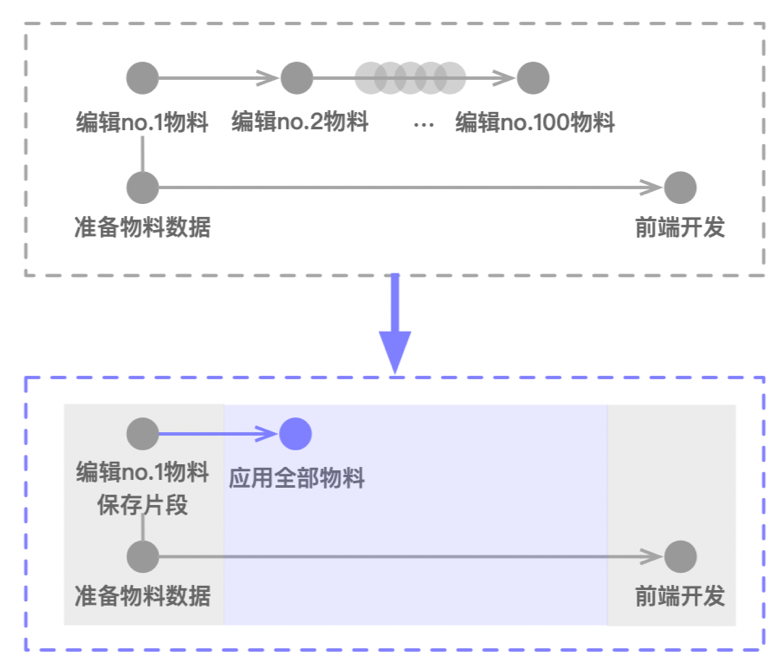
GEEK TALK 經過前面三個步驟的優化,我們在大部分的項目中已經能讓前后端解耦協作,然而在一些復雜項目中這套流程反而會降低工作效率,這是因為復雜項目往往需要覆蓋的功能點更多,數據組合也相應的更多,我們發現部分項目所需要的數據條數甚至超過兩百條,這樣后端就要花費大量的時間和精力去錄入和編輯數據,在這種極端需求下數據準備時間就成為了效率瓶頸,使得研發體驗急劇下降。 為了解決這個問題,我們圍繞“片段”概念支持了對數據批量編輯的功能,可以讓后端在編輯數據的過程中,將編輯的操作以“片段”的形式保存下來,每一個“片段”包含編輯的位置和值,這些“片段”可以繼續應用到多個數據上,這樣編輯工作就從多次變成一次,大大減少了重復工作量。
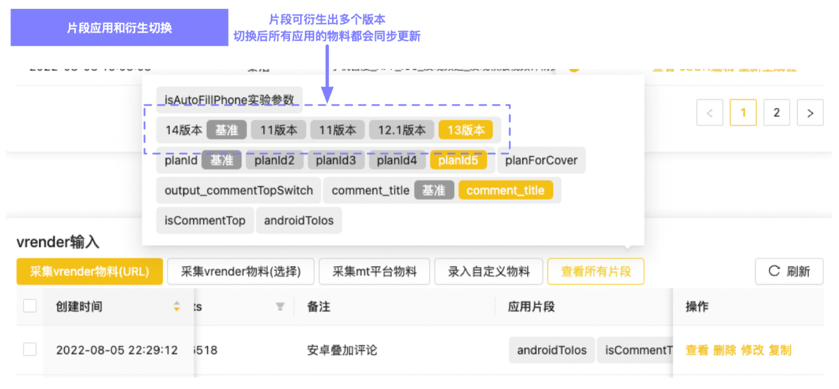
同時,由于前端需要頻繁對同一個功能進行例如版本兼容、標題長度兼容等細分情況的驗證,為了更好的支持這種需求,我們支持了“片段”的版本的功能,也就是在保持“片段”操作位置不變的前提下,為“片段”賦予不同的值,前端可以通過切換“片段”的不同版本,快速拿到同個功能下攜帶不同細節的數據去快速地驗證一些兼容效果。
六、總結
GEEK TALK 前后端數據接口協作升級使我們的團隊能夠更穩定高效地完成產品迭代,團隊的項目的平均交付時間減少了50%以上,目前已經有上千次的業務項目基于這套方案完成了開發測試和線上回歸工作。我們也在持續不斷地探索在如產品視覺驗收、銷售問題驗證等其它方面落地的可能性,希望能在更多的場景下提升團隊的協作效能。
END
審核編輯 :李倩
-
模塊
+關注
關注
7文章
2785瀏覽量
49825 -
數據接口
+關注
關注
1文章
82瀏覽量
18968
原文標題:前后端數據接口協作提效實踐
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
3Dfindit 的協作功能
SOLIDWORKS教育版?團隊協作與溝通技巧的提升
SOLIDWORKS 2025教育版有效的數據管理與團隊協作
高速公路綜合能效管理:從理論到實踐的跨越

安科瑞:以綜合能效管理解決方案,賦能人工智能時代的數據中心可持續發展

芯片前端和后端制造工藝的區別
SOLIDWORKS 2025更有效的協作和數據管理
遞歸算法實踐--到倉合單助力京東物流提效增收
ADS1299后端數據是通過寫好的exe程序來處理的?
SOLIDWORKS 2025協作與數據管理功能簡介
480V變380V:UL變壓器的能效優勢與應用實踐
eBPF技術實踐之virtio-net網卡隊列可觀測
SOLIDWORKS 2025:更有效的協作和數據管理
前后端數據傳輸約定探討
Jira實踐案例分享:小米集團如何通過API請求優化、數據治理與AI智能客服等,實現Jira系統的高效運維





 工商網監
工商網監
評論