") Netty如何做到單機(jī)百萬(wàn)并發(fā)?
Netty如何做到單機(jī)百萬(wàn)并發(fā)?
相信很多人知道石中劍這個(gè)典故,在此典故中,天命注定的亞瑟很容易的就拔出了這把石中劍,但是由于資歷不被其他人認(rèn)可,所以他頗費(fèi)了一番周折才成為了真正意義上的英格蘭全境之王,亞瑟王。
說(shuō)道這把劍,劍身上銘刻著這樣一句話(huà):ONLY THE KING CAN TAKE THE SWORD FROM THE STONE。
雖然典故中的 the king 是指英明之主亞瑟王,但是在本章中,這個(gè) king 就是讀者自己。
我們今天不僅要從百萬(wàn)并發(fā)基石上拔出這把 epoll 之劍,也就是 Netty,而且要利用這把劍大殺四方,一如當(dāng)年的亞瑟王憑借此劍統(tǒng)一了英格蘭全境一樣。
說(shuō)到石中劍 Netty,我們知道他極其強(qiáng)悍的性能以及純異步模型,釋放出了極強(qiáng)的生產(chǎn)力,內(nèi)置的各種編解碼編排,心跳包檢測(cè),粘包拆包處理等,高效且易于使用,以至于很多耳熟能詳?shù)慕M件都在使用,比如 Hadoop,Dubbo 等。
但是他是如何做到這些的呢?本章將會(huì)以庖丁解牛的方式,一步一步的來(lái)拔出此劍。
Netty 的異步模型
說(shuō)起 Netty 的異步模型,我相信大多數(shù)人,只要是寫(xiě)過(guò)服務(wù)端的話(huà),都是耳熟能詳?shù)模琤ossGroup 和 workerGroup 被 ServerBootstrap 所驅(qū)動(dòng),用起來(lái)簡(jiǎn)直是如虎添翼。
再加上各種配置化的 handler 加持,組裝起來(lái)也是行云流水,俯拾即是。但是,任何一個(gè)好的架構(gòu),都不是一蹴而就實(shí)現(xiàn)的,那她經(jīng)歷了怎樣的心路歷程呢?
①經(jīng)典的多線(xiàn)程模型
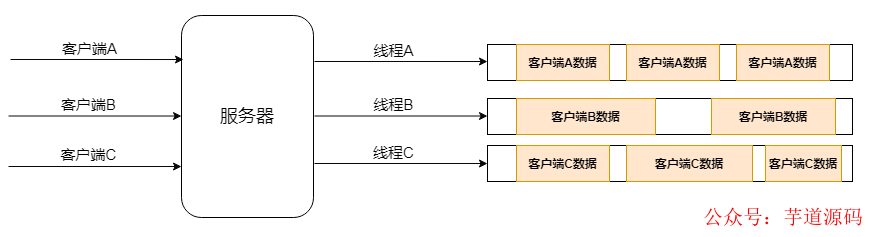
此模型中,服務(wù)端起來(lái)后,客戶(hù)端連接到服務(wù)端,服務(wù)端會(huì)為每個(gè)客戶(hù)端開(kāi)啟一個(gè)線(xiàn)程來(lái)進(jìn)行后續(xù)的讀寫(xiě)操作。
客戶(hù)端少的時(shí)候,整體性能和功能還是可以的,但是如果客戶(hù)端非常多的時(shí)候,線(xiàn)程的創(chuàng)建將會(huì)導(dǎo)致內(nèi)存的急劇飆升從而導(dǎo)致服務(wù)端的性能下降,嚴(yán)重者會(huì)導(dǎo)致新客戶(hù)端連接不上來(lái),更有甚者,服務(wù)器直接宕機(jī)。
此模型雖然簡(jiǎn)單,但是由于其簡(jiǎn)單粗暴,所以難堪大用,建議在寫(xiě)服務(wù)端的時(shí)候,要徹底的避免此種寫(xiě)法。
②經(jīng)典的 Reactor 模型
由于多線(xiàn)程模型難堪大用,所以更好的模型一直在研究之中,Reactor 模型,作為天選之子,也被引入了進(jìn)來(lái),由于其強(qiáng)大的基于事件處理的特性,使得其成為異步模型的不二之選。
Reactor 模型由于是基于事件處理的,所以一旦有事件被觸發(fā),將會(huì)派發(fā)到對(duì)應(yīng)的 event handler 中進(jìn)行處理。
所以在此模型中,有兩個(gè)最重要的參與者,列舉如下:
- Reactor: 主要用來(lái)將 IO 事件派發(fā)到相對(duì)應(yīng)的 handler 中,可以將其想象為打電話(huà)時(shí)候的分發(fā)總機(jī),你先打電話(huà)到總機(jī)號(hào)碼,然后通過(guò)總機(jī),你可以分撥到各個(gè)分機(jī)號(hào)碼。
- Handlers: 主要用來(lái)處理 IO 事件相關(guān)的具體業(yè)務(wù),可以將其想象為撥通分機(jī)號(hào)碼后,實(shí)際上為你處理事件的員工。
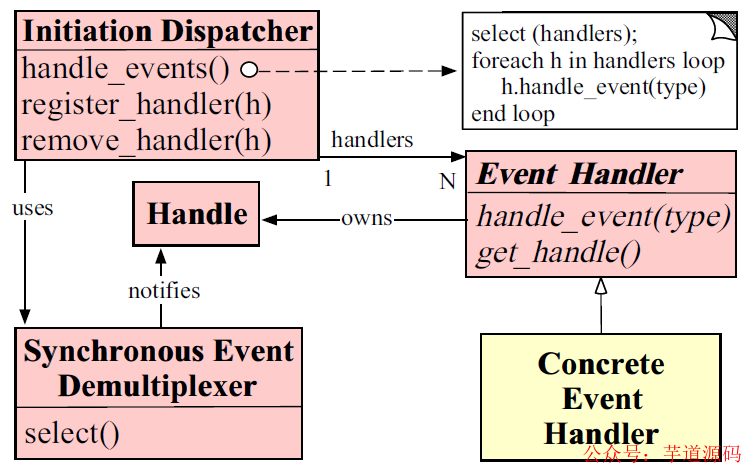
上圖為 Reactor 模型的描述圖,具體來(lái)說(shuō)一下:
Initiation Dispatcher 其實(shí)扮演的就是 Reactor 的角色,主要進(jìn)行 Event Demultiplexer,即事件派發(fā)。
而其內(nèi)部一般都有一個(gè) Acceptor,用于通過(guò)對(duì)系統(tǒng)資源的操縱來(lái)獲取資源句柄,然后交由 Reactor,通過(guò) handle_events 方法派發(fā)至具體的 EventHandler 的。
Synchronous Event Demultiplexer 其實(shí)就是 Acceptor 的角色,此角色內(nèi)部通過(guò)調(diào)用系統(tǒng)的方法來(lái)進(jìn)行資源操作。
比如說(shuō),假如客戶(hù)端連接上來(lái),那么將會(huì)獲得當(dāng)前連接,假如需要?jiǎng)h除文件,那么將會(huì)獲得當(dāng)前待操作的文件句柄等等。
這些句柄實(shí)際上是要返回給 Reactor 的,然后經(jīng)由 Reactor 派發(fā)下放給具體的 EventHandler。
Event Handler 這里,其實(shí)就是具體的事件操作了。其內(nèi)部針對(duì)不同的業(yè)務(wù)邏輯,擁有不同的操作方法。
比如說(shuō),鑒權(quán) EventHandler 會(huì)檢測(cè)傳入的連接,驗(yàn)證其是否在白名單,心跳包 EventHanler 會(huì)檢測(cè)管道是否空閑。
業(yè)務(wù) EventHandler 會(huì)進(jìn)行具體的業(yè)務(wù)處理,編解碼 EventHandler 會(huì)對(duì)當(dāng)前連接傳輸?shù)膬?nèi)容進(jìn)行編碼解碼操作等等。
由于 Netty 是 Reactor 模型的具體實(shí)現(xiàn),所以在編碼的時(shí)候,我們可以非常清楚明白的理解 Reactor 的具體使用方式,這里暫時(shí)不講,后面會(huì)提到。
由于 Doug Lea 寫(xiě)過(guò)一篇關(guān)于 NIO 的文章,整體總結(jié)的極好,所以這里我們就結(jié)合他的文章來(lái)詳細(xì)分析一下 Reactor 模型的演化過(guò)程。
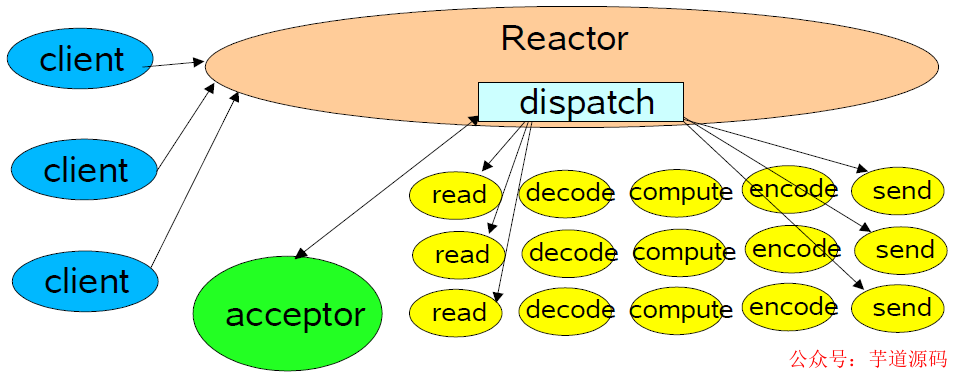
上圖模型為單線(xiàn)程 Reator 模型,Reactor 模型會(huì)利用給定的 selectionKeys 進(jìn)行派發(fā)操作,派發(fā)到給定的 handler。
之后當(dāng)有客戶(hù)端連接上來(lái)的時(shí)候,acceptor 會(huì)進(jìn)行 accept 接收操作,之后將接收到的連接和之前派發(fā)的 handler 進(jìn)行組合并啟動(dòng)。
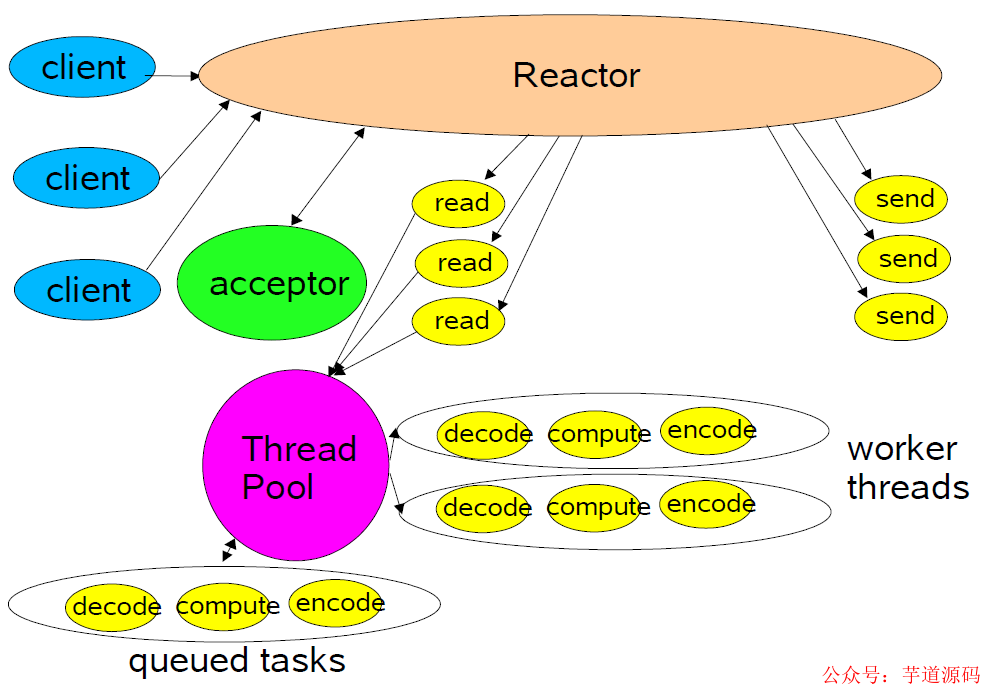
上圖模型為池化 Reactor 模型,此模型將讀操作和寫(xiě)操作解耦了出來(lái),當(dāng)有數(shù)據(jù)過(guò)來(lái)的時(shí)候,將 handler 的系列操作扔到線(xiàn)程池中來(lái)進(jìn)行,極大的提到了整體的吞吐量和處理速度。
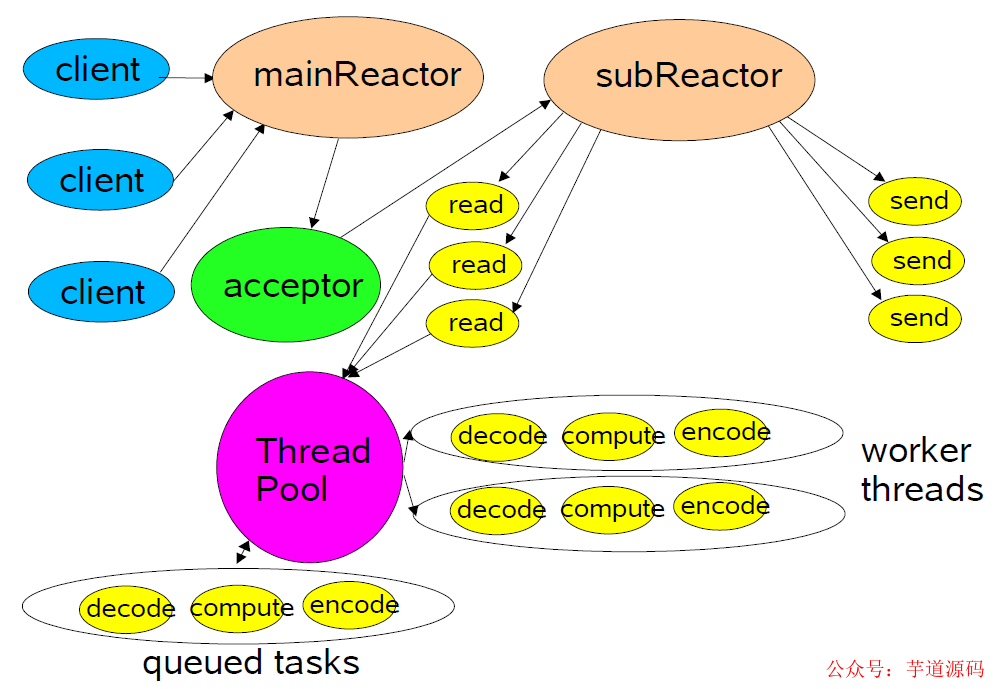
上圖模型為多 Reactor 模型,此模型中,將原本單個(gè) Reactor 一分為二,分別為 mainReactor 和 subReactor。
其中 mainReactor 主要進(jìn)行客戶(hù)端連接方面的處理,客戶(hù)端 accept 后發(fā)送給 subReactor 進(jìn)行后續(xù)處理處理。
這種模型的好處就是整體職責(zé)更加明確,同時(shí)對(duì)于多 CPU 的機(jī)器,系統(tǒng)資源的利用更加高一些。
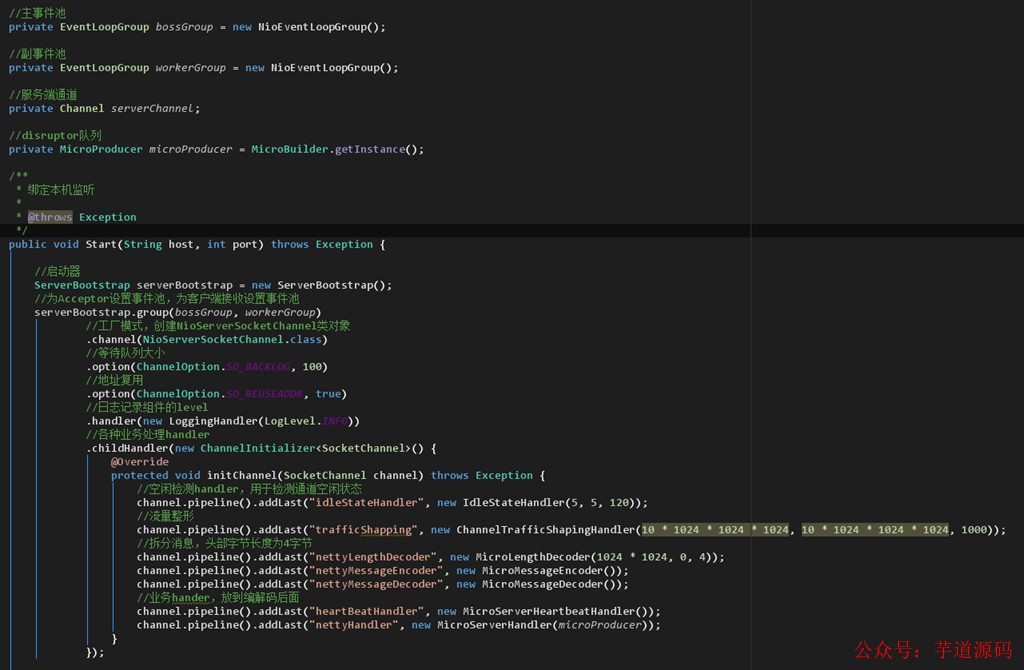
從 Netty 寫(xiě)的 server 端,就可以看出,boss worker group 對(duì)應(yīng)的正是主副 Reactor。
之后 ServerBootstrap 進(jìn)行 Reactor 的創(chuàng)建操作,里面的 group,channel,option 等進(jìn)行初始化操作。
而設(shè)置的 childHandler 則是具體的業(yè)務(wù)操作,其底層的事件分發(fā)器則通過(guò)調(diào)用 Linux 系統(tǒng)級(jí)接口 epoll 來(lái)實(shí)現(xiàn)連接并將其傳給 Reactor。
基于 Spring Boot + MyBatis Plus + Vue & Element 實(shí)現(xiàn)的后臺(tái)管理系統(tǒng) + 用戶(hù)小程序,支持 RBAC 動(dòng)態(tài)權(quán)限、多租戶(hù)、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
石中劍 Netty 強(qiáng)悍的原理(JNI)
Netty 之劍之所以鋒利,不僅僅因?yàn)槠浼儺惒降木幣拍P停苊饬烁鞣N阻塞式的操作,同時(shí)其內(nèi)部各種設(shè)計(jì)精良的組件,終成一統(tǒng)。
且不說(shuō)讓人眼前一亮的緩沖池設(shè)計(jì),讀寫(xiě)標(biāo)隨心而動(dòng),摒棄了繁冗復(fù)雜的邊界檢測(cè),用起來(lái)著實(shí)舒服之極。
原生的流控和高低水位設(shè)計(jì),讓流速控制真的是隨心所欲,鑄就了一道相當(dāng)堅(jiān)固的護(hù)城河。
齊全的粘包拆包處理方式,讓每一筆數(shù)據(jù)都能夠清晰明了;而高效的空閑檢測(cè)機(jī)制,則讓心跳包和斷線(xiàn)重連等設(shè)計(jì)方案變得如此俯拾即是。
上層的設(shè)計(jì)如此優(yōu)秀,其性能又怎能甘居下風(fēng)。由于底層通訊方式完全是 C 語(yǔ)言編寫(xiě),然后利用 JNI 機(jī)制進(jìn)行處理,所以整體的性能可以說(shuō)是達(dá)到了原生 C 語(yǔ)言性能的強(qiáng)悍程度。
說(shuō)道 JNI,這里我覺(jué)得有必要詳細(xì)說(shuō)一下,他是我們利用 Java 直接調(diào)用 C 語(yǔ)言原生代碼的關(guān)鍵。
JNI,全稱(chēng)為Java Native Interface,翻譯過(guò)來(lái)就是 Java 本地接口,他是 Java 調(diào)用 C 語(yǔ)言的一套規(guī)范。具體來(lái)看看怎么做的吧。
步驟一,先來(lái)寫(xiě)一個(gè)簡(jiǎn)單的 Java 調(diào)用函數(shù):
/**
*@authorshichaoyang
*@Description:數(shù)據(jù)同步器
*@date2020-10-1419:41
*/
publicclassDataSynchronizer{
/**
*加載本地底層C實(shí)現(xiàn)庫(kù)
*/
static{
System.loadLibrary("synchronizer");
}
/**
*底層數(shù)據(jù)同步方法
*/
privatenativeStringsyncData(Stringstatus);
/**
*程序啟動(dòng),調(diào)用底層數(shù)據(jù)同步方法
*
*@paramargs
*/
publicstaticvoidmain(String...args){
Stringrst=newDataSynchronizer().syncData("ProcessStep2");
System.out.println("TheexecuteresultfromCis:"+rst);
}
}
可以看出,是一個(gè)非常簡(jiǎn)單的 Java 類(lèi),此類(lèi)中,syncData 方法前面帶了 native 修飾,代表此方法最終將會(huì)調(diào)用底層 C 語(yǔ)言實(shí)現(xiàn)。main 方法是啟動(dòng)類(lèi),將 C 語(yǔ)言執(zhí)行的結(jié)果接收并打印出來(lái)。
然后,打開(kāi)我們的 Linux 環(huán)境,這里由于我用的是 linux mint,依次執(zhí)行如下命令來(lái)設(shè)置環(huán)境:
執(zhí)行aptinstalldefault-jdk 安裝java環(huán)境,安裝完畢。
通過(guò)update-alternatives --list java 獲取java安裝路徑,這里為:/usr/lib/jvm/java-11-openjdk-amd64
設(shè)置java環(huán)境變量exportJAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
環(huán)境設(shè)置完畢之后,就可以開(kāi)始進(jìn)行下一步了。
步驟二,編譯,首先,進(jìn)入到代碼 DataSynchronizer.c 所在的目錄,然后運(yùn)行如下命令來(lái)編譯 Java 源碼:
javac-h.DataSynchronizer.java
編譯完畢之后,可以看到當(dāng)前目錄出現(xiàn)了如下幾個(gè)文件:

其中 DataSynchronizer.h 是生成的頭文件,這個(gè)文件盡量不要修改,整體內(nèi)容如下:
/*DONOTEDITTHISFILE-itismachinegenerated*/
#include
其中 JNIEXPORT jstring JNICALL Java_DataSynchronizer_syncData 方法,就是給我們生成的本地 C 語(yǔ)言方法,我們這里只需要?jiǎng)?chuàng)建一個(gè) C 語(yǔ)言文件,名稱(chēng)為 DataSynchronizer.c。
將此頭文件加載進(jìn)來(lái),實(shí)現(xiàn)此方法即可:
#include
其中需要注意的是,JNIEnv* 變量,實(shí)際上指的是當(dāng)前的 JNI 環(huán)境。而 jobject 變量則類(lèi)似 Java 中的 this 關(guān)鍵字。
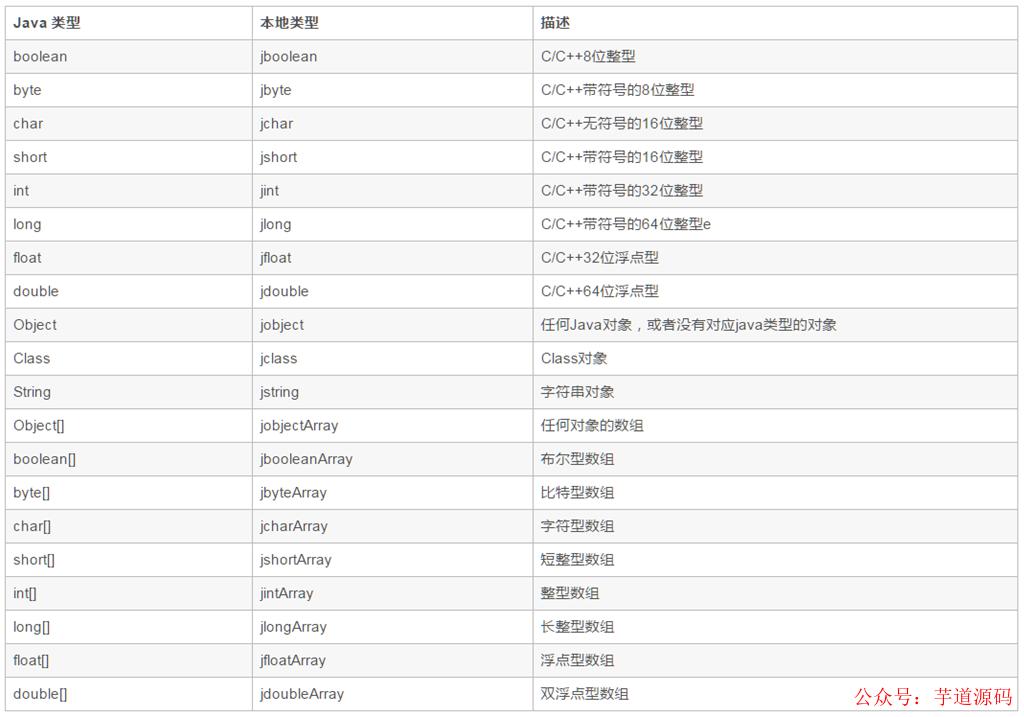
jstring 則是 C 語(yǔ)言層面上的字符串,相當(dāng)于 Java 中的 String。整體對(duì)應(yīng)如下:
最后,我們來(lái)編譯一下:
gcc-fPIC-I"$JAVA_HOME/include"-I"$JAVA_HOME/include/linux"-shared-olibsynchronizer.soDataSynchronizer.c
編譯完畢后,可以看到當(dāng)前目錄下又多了一個(gè) libsynchronizer.so 文件(這個(gè)文件類(lèi)似 Windows 上編譯后生成的 .dll 類(lèi)庫(kù)文件):

此時(shí)我們可以運(yùn)行了,運(yùn)行如下命令進(jìn)行運(yùn)行:
java-Djava.library.path=.DataSynchronizer
得到結(jié)果如下:
java-Djava.library.path=.DataSynchronizer
InC,thereceivedstringis:ProcessStep2
EnteraString:sdfsdf
TheexecuteresultfromCis:sdfsdf
從這里看到,我們正確的通過(guò) java jni 技術(shù),調(diào)用了 C 語(yǔ)言底層的邏輯,然后獲取到結(jié)果,打印了出來(lái)。
在 Netty 中,也是利用了 jni 的技術(shù),然后通過(guò)調(diào)用底層的 C 語(yǔ)言邏輯實(shí)現(xiàn),來(lái)實(shí)現(xiàn)高效的網(wǎng)絡(luò)通訊的。
感興趣的同學(xué)可以扒拉下 Netty 源碼,在 transport-native-epoll 模塊中,就可以見(jiàn)到具體的實(shí)現(xiàn)方法了。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實(shí)現(xiàn)的后臺(tái)管理系統(tǒng) + 用戶(hù)小程序,支持 RBAC 動(dòng)態(tài)權(quán)限、多租戶(hù)、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
IO 多路復(fù)用模型
石中劍,之所以能蕩平英格蘭全境,自然有其最強(qiáng)悍的地方。
相應(yīng)的,Netty,則也是不遑多讓?zhuān)阅軌虮桓鞔笾慕M件所采用,自然也有其最強(qiáng)悍的地方,而本章節(jié)的 IO 多路復(fù)用模型,則是其強(qiáng)悍的理由之一。
在說(shuō) IO 多路復(fù)用模型之前,我們先來(lái)大致了解下 Linux 文件系統(tǒng)。
在 Linux 系統(tǒng)中,不論是你的鼠標(biāo),鍵盤(pán),還是打印機(jī),甚至于連接到本機(jī)的 socket client 端,都是以文件描述符的形式存在于系統(tǒng)中,諸如此類(lèi),等等等等。
所以可以這么說(shuō),一切皆文件。來(lái)看一下系統(tǒng)定義的文件描述符說(shuō)明:
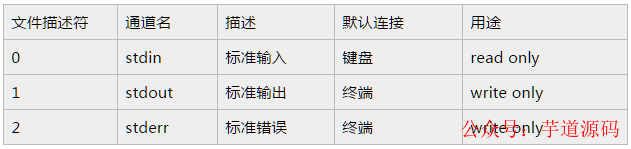
從上面的列表可以看到,文件描述符 0,1,2 都已經(jīng)被系統(tǒng)占用了,當(dāng)系統(tǒng)啟動(dòng)的時(shí)候,這三個(gè)描述符就存在了。
其中 0 代表標(biāo)準(zhǔn)輸入,1 代表標(biāo)準(zhǔn)輸出,2 代表錯(cuò)誤輸出。當(dāng)我們創(chuàng)建新的文件描述符的時(shí)候,就會(huì)在 2 的基礎(chǔ)上進(jìn)行遞增。
可以這么說(shuō),文件描述符是為了管理被打開(kāi)的文件而創(chuàng)建的系統(tǒng)索引,他代表了文件的身份 ID。對(duì)標(biāo) Windows 的話(huà),你可以認(rèn)為和句柄類(lèi)似,這樣就更容易理解一些。
由于網(wǎng)上對(duì) Linux 文件這塊的原理描述的文章已經(jīng)非常多了,所以這里我不再做過(guò)多的贅述,感興趣的同學(xué)可以從 Wikipedia 翻閱一下。
由于這塊內(nèi)容比較復(fù)雜,不屬于本文普及的內(nèi)容,建議讀者另行自研。
select 模型
此模型是 IO 多路復(fù)用的最早期使用的模型之一,距今已經(jīng)幾十年了,但是現(xiàn)在依舊有不少應(yīng)用還在采用此種方式,可見(jiàn)其長(zhǎng)生不老。
首先來(lái)看下其具體的定義(來(lái)源于 man 二類(lèi)文檔):
intselect(intnfds,fd_set*readfds,fd_set*writefds,fd_set*errorfds,structtimeval*timeout);
這里解釋下其具體參數(shù):
- 參數(shù)一:nfds, 也即 maxfd,最大的文件描述符遞增一。這里之所以傳最大描述符,為的就是在遍歷 fd_set 的時(shí)候,限定遍歷范圍。
- 參數(shù)二:readfds, 可讀文件描述符集合。
- 參數(shù)三:writefds, 可寫(xiě)文件描述符集合。
- 參數(shù)四:errorfds, 異常文件描述符集合。
- 參數(shù)五:timeout, 超時(shí)時(shí)間。在這段時(shí)間內(nèi)沒(méi)有檢測(cè)到描述符被觸發(fā),則返回。
下面的宏處理,可以對(duì) fd_set 集合(準(zhǔn)確的說(shuō)是 bitmap,一個(gè)描述符有變更,則會(huì)在描述符對(duì)應(yīng)的索引處置 1)進(jìn)行操作:
- FD_CLR(inr fd,fd_set* set) : 用來(lái)清除描述詞組 set 中相關(guān) fd 的位,即 bitmap 結(jié)構(gòu)中索引值為 fd 的值置為 0。
- FD_ISSET(int fd,fd_set *set): 用來(lái)測(cè)試描述詞組 set 中相關(guān) fd 的位是否為真,即 bitmap 結(jié)構(gòu)中某一位是否為 1。
- FD_SET(int fd,fd_set*set): 用來(lái)設(shè)置描述詞組 set 中相關(guān) fd 的位,即將 bitmap 結(jié)構(gòu)中某一位設(shè)置為 1,索引值為 fd。
- FD_ZERO(fd_set *set): 用來(lái)清除描述詞組 set 的全部位,即將 bitmap 結(jié)構(gòu)全部清零。
首先來(lái)看一段服務(wù)端采用了 select 模型的示例代碼:
//創(chuàng)建server端套接字,獲取文件描述符
intlistenfd=socket(PF_INET,SOCK_STREAM,0);
if(listenfd0)return-1;
//綁定服務(wù)器
bind(listenfd,(structsockaddr*)&address,sizeof(address));
//監(jiān)聽(tīng)服務(wù)器
listen(listenfd,5);
structsockaddr_inclient;
socklen_taddr_len=sizeof(client);
//接收客戶(hù)端連接
intconnfd=accept(listenfd,(structsockaddr*)&client,&addr_len);
//讀緩沖區(qū)
charbuff[1024];
//讀文件操作符
fd_setread_fds;
while(1)
{
memset(buff,0,sizeof(buff));
//注意:每次調(diào)用select之前都要重新設(shè)置文件描述符connfd,因?yàn)槲募枋龇頃?huì)在內(nèi)核中被修改
FD_ZERO(&read_fds);
FD_SET(connfd,&read_fds);
//注意:select會(huì)將用戶(hù)態(tài)中的文件描述符表放到內(nèi)核中進(jìn)行修改,內(nèi)核修改完畢后再返回給用戶(hù)態(tài),開(kāi)銷(xiāo)較大
ret=select(connfd+1,&read_fds,NULL,NULL,NULL);
if(ret0)
{
printf("Failtoselect!
");
return-1;
}
//檢測(cè)文件描述符表中相關(guān)請(qǐng)求是否可讀
if(FD_ISSET(connfd,&read_fds))
{
ret=recv(connfd,buff,sizeof(buff)-1,0);
printf("receive%dbytesfromclient:%s
",ret,buff);
}
}
上面的代碼我加了比較詳細(xì)的注釋了,大家應(yīng)該很容易看明白,說(shuō)白了大概流程其實(shí)如下:
- 首先,創(chuàng)建 socket 套接字,創(chuàng)建完畢后,會(huì)獲取到此套接字的文件描述符。
- 然后,bind 到指定的地址進(jìn)行監(jiān)聽(tīng) listen。這樣,服務(wù)端就在特定的端口啟動(dòng)起來(lái)并進(jìn)行監(jiān)聽(tīng)了。
- 之后,利用開(kāi)啟 accept 方法來(lái)監(jiān)聽(tīng)客戶(hù)端的連接請(qǐng)求。一旦有客戶(hù)端連接,則將獲取到當(dāng)前客戶(hù)端連接的 connection 文件描述符。
雙方建立連接之后,就可以進(jìn)行數(shù)據(jù)互傳了。需要注意的是,在循環(huán)開(kāi)始的時(shí)候,務(wù)必每次都要重新設(shè)置當(dāng)前 connection 的文件描述符,是因?yàn)槲募杳枋龇碓趦?nèi)核中被修改過(guò),如果不重置,將會(huì)導(dǎo)致異常的情況。
重新設(shè)置文件描述符后,就可以利用 select 函數(shù)從文件描述符表中,來(lái)輪詢(xún)哪些文件描述符就緒了。
此時(shí)系統(tǒng)會(huì)將用戶(hù)態(tài)的文件描述符表發(fā)送到內(nèi)核態(tài)進(jìn)行調(diào)整,即將準(zhǔn)備就緒的文件描述符進(jìn)行置位,然后再發(fā)送給用戶(hù)態(tài)的應(yīng)用中來(lái)。
用戶(hù)通過(guò) FD_ISSET 方法來(lái)輪詢(xún)文件描述符,如果數(shù)據(jù)可讀,則讀取數(shù)據(jù)即可。
舉個(gè)例子,假設(shè)此時(shí)連接上來(lái)了 3 個(gè)客戶(hù)端,connection 的文件描述符分別為 4,8,12。
那么其 read_fds 文件描述符表(bitmap 結(jié)構(gòu))的大致結(jié)構(gòu)為 00010001000100000....0。
由于 read_fds 文件描述符的長(zhǎng)度為 1024 位,所以最多允許 1024 個(gè)連接。

而在 select 的時(shí)候,涉及到用戶(hù)態(tài)和內(nèi)核態(tài)的轉(zhuǎn)換,所以整體轉(zhuǎn)換方式如下:
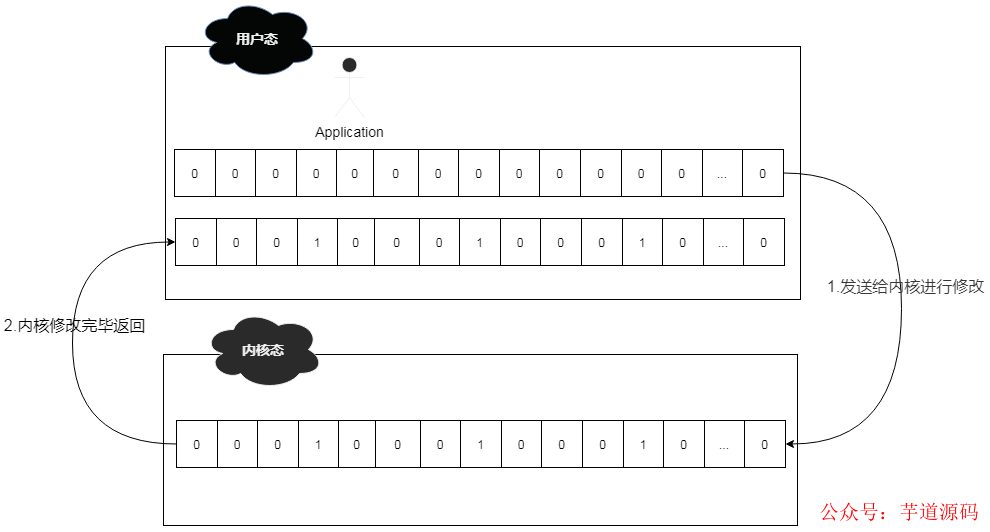
所以,綜合起來(lái),select 整體還是比較高效和穩(wěn)定的,但是呈現(xiàn)出來(lái)的問(wèn)題也不少。
這些問(wèn)題進(jìn)一步限制了其性能發(fā)揮:
- 文件描述符表為 bitmap 結(jié)構(gòu),且有長(zhǎng)度為 1024 的限制。
- fdset 無(wú)法做到重用,每次循環(huán)必須重新創(chuàng)建。
- 頻繁的用戶(hù)態(tài)和內(nèi)核態(tài)拷貝,性能開(kāi)銷(xiāo)較大。
- 需要對(duì)文件描述符表進(jìn)行遍歷,O(n) 的輪詢(xún)時(shí)間復(fù)雜度。
poll 模型
考慮到 select 模型的幾個(gè)限制,后來(lái)進(jìn)行了改進(jìn),這也就是 poll 模型,既然是 select 模型的改進(jìn)版,那么肯定有其亮眼的地方,一起來(lái)看看吧。
當(dāng)然,這次我們依舊是先翻閱 linux man 二類(lèi)文檔,因?yàn)檫@是官方的文檔,對(duì)其有著最為精準(zhǔn)的定義。
intpoll(structpollfd*fds,nfds_tnfds,inttimeout);
其實(shí),從運(yùn)行機(jī)制上說(shuō)來(lái),poll 所做的功能和 select 是基本上一樣的,都是等待并檢測(cè)一組文件描述符就緒,然后在進(jìn)行后續(xù)的 IO 處理工作。
只不過(guò)不同的是,select 中,采用的是 bitmap 結(jié)構(gòu),長(zhǎng)度限定在 1024 位的文件描述符表,而 poll 模型則采用的是 pollfd 結(jié)構(gòu)的數(shù)組 fds。
也正是由于 poll 模型采用了數(shù)組結(jié)構(gòu),則不會(huì)有 1024 長(zhǎng)度限制,使其能夠承受更高的并發(fā)。
pollfd 結(jié)構(gòu)內(nèi)容如下:
structpollfd{
intfd;/*文件描述符*/
shortevents;/*關(guān)心的事件*/
shortrevents;/*實(shí)際返回的事件*/
};
從上面的結(jié)構(gòu)可以看出,fd 很明顯就是指文件描述符,也就是當(dāng)客戶(hù)端連接上來(lái)后,fd 會(huì)將生成的文件描述符保存到這里。
而 events 則是指用戶(hù)想關(guān)注的事件;revents 則是指實(shí)際返回的事件,是由系統(tǒng)內(nèi)核填充并返回,如果當(dāng)前的 fd 文件描述符有狀態(tài)變化,則 revents 的值就會(huì)有相應(yīng)的變化。
events 事件列表如下:
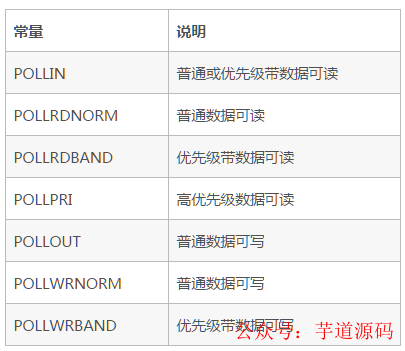
revents 事件列表如下:
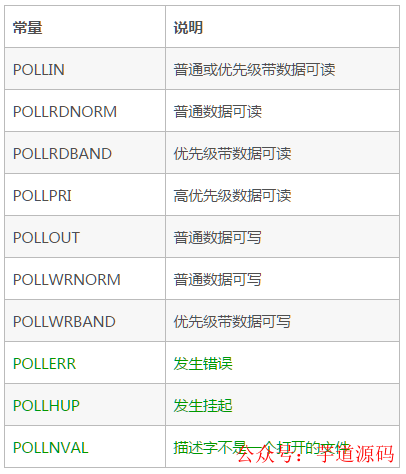
從列表中可以看出,revents 是包含 events 的。接下來(lái)結(jié)合示例來(lái)看一下:
//創(chuàng)建server端套接字,獲取文件描述符
intlistenfd=socket(PF_INET,SOCK_STREAM,0);
if(listenfd0)return-1;
//綁定服務(wù)器
bind(listenfd,(structsockaddr*)&address,sizeof(address));
//監(jiān)聽(tīng)服務(wù)器
listen(listenfd,5);
structpollfdpollfds[1];
socklen_taddr_len=sizeof(client);
//接收客戶(hù)端連接
intconnfd=accept(listenfd,(structsockaddr*)&client,&addr_len);
//放入fd數(shù)組
pollfds[0].fd=connfd;
pollfds[0].events=POLLIN;
//讀緩沖區(qū)
charbuff[1024];
//讀文件操作符
fd_setread_fds;
while(1)
{
memset(buff,0,sizeof(buff));
/**
**SELECT模型專(zhuān)用
**注意:每次調(diào)用select之前都要重新設(shè)置文件描述符connfd,因?yàn)槲募枋龇頃?huì)在內(nèi)核中被修改
**FD_ZERO(&read_fds);
**FD_SET(connfd,&read_fds);
**注意:select會(huì)將用戶(hù)態(tài)中的文件描述符表放到內(nèi)核中進(jìn)行修改,內(nèi)核修改完畢后再返回給用戶(hù)態(tài),開(kāi)銷(xiāo)較大
**ret=select(connfd+1,&read_fds,NULL,NULL,NULL);
**/
ret=poll(pollfds,1,1000);
if(ret0)
{
printf("Failtopoll!
");
return-1;
}
/**
**SELECT模型專(zhuān)用
**檢測(cè)文件描述符表中相關(guān)請(qǐng)求是否可讀
**if(FD_ISSET(connfd,&read_fds))
**{
**ret=recv(connfd,buff,sizeof(buff)-1,0);
**printf("receive%dbytesfromclient:%s
",ret,buff);
**}
**/
//檢測(cè)文件描述符數(shù)組中相關(guān)請(qǐng)求
if(pollfds[0].revents&POLLIN){
pollfds[0].revents=0;
ret=recv(connfd,buff,sizeof(buff)-1,0);
printf("receive%dbytesfromclient:%s
",ret,buff);
}
}
由于源碼中,我做了比較詳細(xì)的注釋?zhuān)瑫r(shí)將和 select 模型不一樣的地方都列了出來(lái),這里就不再詳細(xì)解釋了。
總體說(shuō)來(lái),poll 模型比 select 模型要好用一些,去掉了一些限制,但是仍然避免不了如下的問(wèn)題:
- 用戶(hù)態(tài)和內(nèi)核態(tài)仍需要頻繁切換,因?yàn)?revents 的賦值是在內(nèi)核態(tài)進(jìn)行的,然后再推送到用戶(hù)態(tài),和 select 類(lèi)似,整體開(kāi)銷(xiāo)較大。
- 仍需要遍歷數(shù)組,時(shí)間復(fù)雜度為 O(N)。
epoll 模型
如果說(shuō) select 模型和 poll 模型是早期的產(chǎn)物,在性能上有諸多不盡人意之處,那么自 Linux 2.6 之后新增的 epoll 模型,則徹底解決了性能問(wèn)題,一舉使得單機(jī)承受百萬(wàn)并發(fā)的課題變得極為容易。
現(xiàn)在可以這么說(shuō),只需要一些簡(jiǎn)單的設(shè)置更改,然后配合上 epoll 的性能,實(shí)現(xiàn)單機(jī)百萬(wàn)并發(fā)輕而易舉。
同時(shí),由于 epoll 整體的優(yōu)化,使得之前的幾個(gè)比較耗費(fèi)性能的問(wèn)題不再成為羈絆,所以也成為了 Linux 平臺(tái)上進(jìn)行網(wǎng)絡(luò)通訊的首選模型。
講解之前,還是 linux man 文檔鎮(zhèn)樓:linux man epoll 4 類(lèi)文檔 linux man epoll 7 類(lèi)文檔,倆文檔結(jié)合著讀,會(huì)對(duì) epoll 有個(gè)大概的了解。
和之前提到的 select 和 poll 不同的是,此二者皆屬于系統(tǒng)調(diào)用函數(shù),但是 epoll 則不然,他是存在于內(nèi)核中的數(shù)據(jù)結(jié)構(gòu)。
可以通過(guò) epoll_create,epoll_ctl 及 epoll_wait 三個(gè)函數(shù)結(jié)合來(lái)對(duì)此數(shù)據(jù)結(jié)構(gòu)進(jìn)行操控。
說(shuō)到 epoll_create 函數(shù),其作用是在內(nèi)核中創(chuàng)建一個(gè) epoll 數(shù)據(jù)結(jié)構(gòu)實(shí)例,然后將返回此實(shí)例在系統(tǒng)中的文件描述符。
此 epoll 數(shù)據(jù)結(jié)構(gòu)的組成其實(shí)是一個(gè)鏈表結(jié)構(gòu),我們稱(chēng)之為 interest list,里面會(huì)注冊(cè)連接上來(lái)的 client 的文件描述符。
其簡(jiǎn)化工作機(jī)制如下:
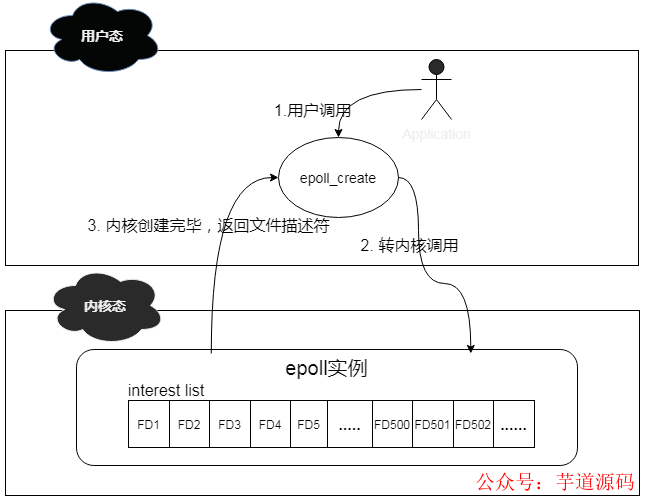
說(shuō)道 epoll_ctl 函數(shù),其作用則是對(duì) epoll 實(shí)例進(jìn)行增刪改查操作。有些類(lèi)似我們常用的 CRUD 操作。
這個(gè)函數(shù)操作的對(duì)象其實(shí)就是 epoll 數(shù)據(jù)結(jié)構(gòu),當(dāng)有新的 client 連接上來(lái)的時(shí)候,他會(huì)將此 client 注冊(cè)到 epoll 中的 interest list 中,此操作通過(guò)附加 EPOLL_CTL_ADD 標(biāo)記來(lái)實(shí)現(xiàn)。
當(dāng)已有的 client 掉線(xiàn)或者主動(dòng)下線(xiàn)的時(shí)候,他會(huì)將下線(xiàn)的 client從epoll 的 interest list 中移除,此操作通過(guò)附加 EPOLL_CTL_DEL 標(biāo)記來(lái)實(shí)現(xiàn)。
當(dāng)有 client 的文件描述符有變更的時(shí)候,他會(huì)將 events 中的對(duì)應(yīng)的文件描述符進(jìn)行更新,此操作通過(guò)附加 EPOLL_CTL_MOD 來(lái)實(shí)現(xiàn)。
當(dāng) interest list 中有 client 已經(jīng)準(zhǔn)備好了,可以進(jìn)行 IO 操作的時(shí)候,他會(huì)將這些 clients 拿出來(lái),然后放到一個(gè)新的 ready list 里面。
其簡(jiǎn)化工作機(jī)制如下:
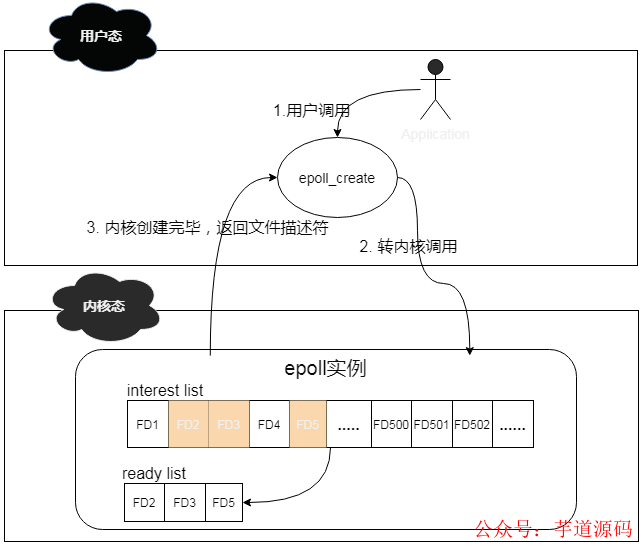
說(shuō)道 epoll_wait 函數(shù),其作用就是掃描 ready list,處理準(zhǔn)備就緒的 client IO,其返回結(jié)果即為準(zhǔn)備好進(jìn)行 IO 的 client 的個(gè)數(shù)。通過(guò)遍歷這些準(zhǔn)備好的 client,就可以輕松進(jìn)行 IO 處理了。
上面這三個(gè)函數(shù)是 epoll 操作的基本函數(shù),但是,想要徹底理解 epoll,則需要先了解這三塊內(nèi)容,即:inode,鏈表,紅黑樹(shù)。
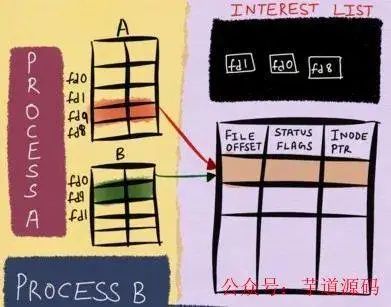
在 Linux 內(nèi)核中,針對(duì)當(dāng)前打開(kāi)的文件,有一個(gè) open file table,里面記錄的是所有打開(kāi)的文件描述符信息;同時(shí)也有一個(gè) inode table,里面則記錄的是底層的文件描述符信息。
這里假如文件描述符 B fork 了文件描述符 A,雖然在 open file table 中,我們看新增了一個(gè)文件描述符 B,但是實(shí)際上,在 inode table 中,A 和 B 的底層是一模一樣的。
這里,將 inode table 中的內(nèi)容理解為 Windows 中的文件屬性,會(huì)更加貼切和易懂。
這樣存儲(chǔ)的好處就是,無(wú)論上層文件描述符怎么變化,由于 epoll 監(jiān)控的數(shù)據(jù)永遠(yuǎn)是 inode table 的底層數(shù)據(jù),那么我就可以一直能夠監(jiān)控到文件的各種變化信息,這也是 epoll 高效的基礎(chǔ)。
簡(jiǎn)化流程如下:
數(shù)據(jù)存儲(chǔ)這塊解決了,那么針對(duì)連接上來(lái)的客戶(hù)端 socket,該用什么數(shù)據(jù)結(jié)構(gòu)保存進(jìn)來(lái)呢?
這里用到了紅黑樹(shù),由于客戶(hù)端 socket 會(huì)有頻繁的新增和刪除操作,而紅黑樹(shù)這塊時(shí)間復(fù)雜度僅僅為 O(logN),還是挺高效的。
有人會(huì)問(wèn)為啥不用哈希表呢?當(dāng)大量的連接頻繁的進(jìn)行接入或者斷開(kāi)的時(shí)候,擴(kuò)容或者其他行為將會(huì)產(chǎn)生不少的 rehash 操作,而且還要考慮哈希沖突的情況。
雖然查詢(xún)速度的確可以達(dá)到 o(1),但是 rehash 或者哈希沖突是不可控的,所以基于這些考量,我認(rèn)為紅黑樹(shù)占優(yōu)一些。
客戶(hù)端 socket 怎么管理這塊解決了,接下來(lái),當(dāng)有 socket 有數(shù)據(jù)需要進(jìn)行讀寫(xiě)事件處理的時(shí)候,系統(tǒng)會(huì)將已經(jīng)就緒的 socket 添加到雙向鏈表中,然后通過(guò) epoll_wait 方法檢測(cè)的時(shí)候。
其實(shí)檢查的就是這個(gè)雙向鏈表,由于鏈表中都是就緒的數(shù)據(jù),所以避免了針對(duì)整個(gè)客戶(hù)端 socket 列表進(jìn)行遍歷的情況,使得整體效率大大提升。
整體的操作流程為:
- 首先,利用 epoll_create 在內(nèi)核中創(chuàng)建一個(gè) epoll 對(duì)象。其實(shí)這個(gè) epoll 對(duì)象,就是一個(gè)可以存儲(chǔ)客戶(hù)端連接的數(shù)據(jù)結(jié)構(gòu)。
- 然后,客戶(hù)端 socket 連接上來(lái),會(huì)通過(guò) epoll_ctl 操作將結(jié)果添加到 epoll 對(duì)象的紅黑樹(shù)數(shù)據(jù)結(jié)構(gòu)中。
- 然后,一旦有 socket 有事件發(fā)生,則會(huì)通過(guò)回調(diào)函數(shù)將其添加到 ready list 雙向鏈表中。
- 最后,epoll_wait 會(huì)遍歷鏈表來(lái)處理已經(jīng)準(zhǔn)備好的 socket,然后通過(guò)預(yù)先設(shè)置的水平觸發(fā)或者邊緣觸發(fā)來(lái)進(jìn)行數(shù)據(jù)的感知操作。
從上面的細(xì)節(jié)可以看出,由于 epoll 內(nèi)部監(jiān)控的是底層的文件描述符信息,可以將變更的描述符直接加入到 ready list,無(wú)需用戶(hù)將所有的描述符再進(jìn)行傳入。
同時(shí)由于 epoll_wait 掃描的是已經(jīng)就緒的文件描述符,避免了很多無(wú)效的遍歷查詢(xún),使得 epoll 的整體性能大大提升,可以說(shuō)現(xiàn)在只要談?wù)?Linux 平臺(tái)的 IO 多路復(fù)用,epoll 已經(jīng)成為了不二之選。
水平觸發(fā)和邊緣觸發(fā)
上面說(shuō)到了 epoll,主要講解了 client 端怎么連進(jìn)來(lái),但是并未詳細(xì)的講解 epoll_wait 怎么被喚醒的,這里我將來(lái)詳細(xì)的講解一下。
水平觸發(fā),意即 Level Trigger,邊緣觸發(fā),意即 Edge Trigger,如果單從字面意思上理解,則不太容易,但是如果將硬件設(shè)計(jì)中的水平沿,上升沿,下降沿的概念引進(jìn)來(lái),則理解起來(lái)就容易多了。
比如我們可以這樣認(rèn)為:

如果將上圖中的方塊看做是 buffer 的話(huà),那么理解起來(lái)則就更加容易了,比如針對(duì)水平觸發(fā),buffer 只要是一直有數(shù)據(jù),則一直通知;而邊緣觸發(fā),則 buffer 容量發(fā)生變化的時(shí)候,才會(huì)通知。
雖然可以這樣簡(jiǎn)單的理解,但是實(shí)際上,其細(xì)節(jié)處理部分,比圖示中展現(xiàn)的更加精細(xì),這里來(lái)詳細(xì)的說(shuō)一下。
①邊緣觸發(fā)
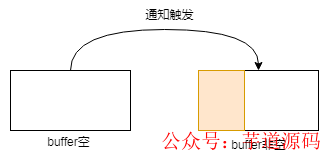
針對(duì)讀操作,也就是當(dāng)前 fd 處于 EPOLLIN 模式下,即可讀。此時(shí)意味著有新的數(shù)據(jù)到來(lái),接收緩沖區(qū)可讀,以下 buffer 都指接收緩沖區(qū):
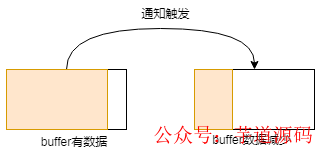
buffer 由空變?yōu)榉强眨饧从袛?shù)據(jù)進(jìn)來(lái)的時(shí)候,此過(guò)程會(huì)觸發(fā)通知:
buffer 原本有些數(shù)據(jù),這時(shí)候又有新數(shù)據(jù)進(jìn)來(lái)的時(shí)候,數(shù)據(jù)變多,此過(guò)程會(huì)觸發(fā)通知:
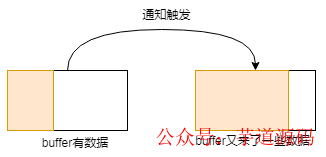
buffer 中有數(shù)據(jù),此時(shí)用戶(hù)對(duì)操作的 fd 注冊(cè) EPOLL_CTL_MOD 事件的時(shí)候,會(huì)觸發(fā)通知:
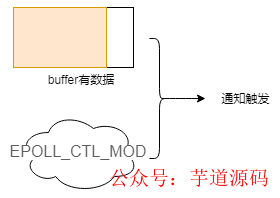
針對(duì)寫(xiě)操作,也就是當(dāng)前 fd 處于 EPOLLOUT 模式下,即可寫(xiě)。此時(shí)意味著緩沖區(qū)可以寫(xiě)了,以下 buffer 都指發(fā)送緩沖區(qū):
buffer 滿(mǎn)了,這時(shí)候發(fā)送出去一些數(shù)據(jù),數(shù)據(jù)變少,此過(guò)程會(huì)觸發(fā)通知:
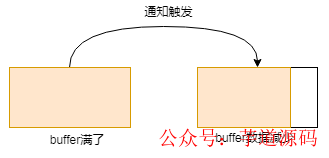
buffer 原本有些數(shù)據(jù),這時(shí)候又發(fā)送出去一些數(shù)據(jù),數(shù)據(jù)變少,此過(guò)程會(huì)觸發(fā)通知:
這里就是 ET 這種模式觸發(fā)的幾種情形,可以看出,基本上都是圍繞著接收緩沖區(qū)或者發(fā)送緩沖區(qū)的狀態(tài)變化來(lái)進(jìn)行的。
晦澀難懂?不存在的,舉個(gè)栗子:
在服務(wù)端,我們開(kāi)啟邊緣觸發(fā)模式,然后將 buffer size 設(shè)為 10 個(gè)字節(jié),來(lái)看看具體的表現(xiàn)形式。
服務(wù)端開(kāi)啟,客戶(hù)端連接,發(fā)送單字符 A 到服務(wù)端,輸出結(jié)果如下:
-->ETMode:itwastriggeredonce
get1bytesofcontent:A
-->waittoread!
可以看到,由于 buffer 從空到非空,邊緣觸發(fā)通知產(chǎn)生,之后在 epoll_wait 處阻塞,繼續(xù)等待后續(xù)事件。
這里我們變一下,輸入 ABCDEFGHIJKLMNOPQ,可以看到,客戶(hù)端發(fā)送的字符長(zhǎng)度超過(guò)了服務(wù)端 buffer size,那么輸出結(jié)果將是怎么樣的呢?
-->ETMode:itwastriggeredonce
get9bytesofcontent:ABCDEFGHI
get8bytesofcontent:JKLMNOPQ
-->waittoread!
可以看到,這次發(fā)送,由于發(fā)送的長(zhǎng)度大于 buffer size,所以?xún)?nèi)容被折成兩段進(jìn)行接收,由于用了邊緣觸發(fā)方式,buffer 的情況是從空到非空,所以只會(huì)產(chǎn)生一次通知。
②水平觸發(fā)
水平觸發(fā)則簡(jiǎn)單多了,他包含了邊緣觸發(fā)的所有場(chǎng)景,簡(jiǎn)而言之如下:
當(dāng)接收緩沖區(qū)不為空的時(shí)候,有數(shù)據(jù)可讀,則讀事件會(huì)一直觸發(fā):
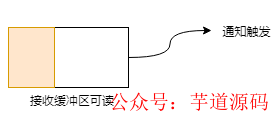
當(dāng)發(fā)送緩沖區(qū)未滿(mǎn)的時(shí)候,可以繼續(xù)寫(xiě)入數(shù)據(jù),則寫(xiě)事件一直會(huì)觸發(fā):
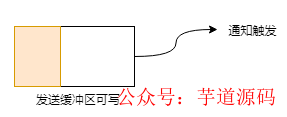
同樣的,為了使表達(dá)更清晰,我們也來(lái)舉個(gè)栗子,按照上述入輸入方式來(lái)進(jìn)行。
服務(wù)端開(kāi)啟,客戶(hù)端連接并發(fā)送單字符 A,可以看到服務(wù)端輸出情況如下:
-->LTMode:itwastriggeredonce!
get1bytesofcontent:A
這個(gè)輸出結(jié)果,毋庸置疑,由于 buffer 中有數(shù)據(jù),所以水平模式觸發(fā),輸出了結(jié)果。
服務(wù)端開(kāi)啟,客戶(hù)端連接并發(fā)送 ABCDEFGHIJKLMNOPQ,可以看到服務(wù)端輸出情況如下:
-->LTMode:itwastriggeredonce!
get9bytesofcontent:ABCDEFGHI
-->LTMode:itwastriggeredonce!
get8bytesofcontent:JKLMNOPQ
從結(jié)果中,可以看出,由于 buffer 中數(shù)據(jù)讀取完畢后,還有未讀完的數(shù)據(jù),所以水平模式會(huì)一直觸發(fā),這也是為啥這里水平模式被觸發(fā)了兩次的原因。
有了這兩個(gè)栗子的比對(duì),不知道聰明的你,get 到二者的區(qū)別了嗎?
在實(shí)際開(kāi)發(fā)過(guò)程中,實(shí)際上 LT 更易用一些,畢竟系統(tǒng)幫助我們做了大部分校驗(yàn)通知工作,之前提到的 SELECT 和 POLL,默認(rèn)采用的也都是這個(gè)。
但是需要注意的是,當(dāng)有成千上萬(wàn)個(gè)客戶(hù)端連接上來(lái)開(kāi)始進(jìn)行數(shù)據(jù)發(fā)送,由于 LT 的特性,內(nèi)核會(huì)頻繁的處理通知操作,導(dǎo)致其相對(duì)于 ET 來(lái)說(shuō),比較的耗費(fèi)系統(tǒng)資源,所以,隨著客戶(hù)端的增多,其性能也就越差。
而邊緣觸發(fā),由于監(jiān)控的是 FD 的狀態(tài)變化,所以整體的系統(tǒng)通知并沒(méi)有那么頻繁,高并發(fā)下整體的性能表現(xiàn)也要好很多。
但是由于此模式下,用戶(hù)需要積極的處理好每一筆數(shù)據(jù),帶來(lái)的維護(hù)代價(jià)也是相當(dāng)大的,稍微不注意就有可能出錯(cuò)。所以使用起來(lái)須要非常小心才行。
至于二者如何抉擇,諸位就仁者見(jiàn)仁智者見(jiàn)智吧。
行文到這里,關(guān)于 epoll 的講解基本上完畢了,大家從中是不是學(xué)到了很多干貨呢?
由于從 Netty 研究到 linux epoll 底層,其難度非常大,可以用曲高和寡來(lái)形容,所以在這塊探索的文章是比較少的,很多東西需要自己照著 man 文檔和源碼一點(diǎn)一點(diǎn)的琢磨(linux 源碼詳見(jiàn) eventpoll.c 等)。
這里我來(lái)糾正一下搜索引擎上,說(shuō) epoll 高性能是因?yàn)槔?mmap 技術(shù)實(shí)現(xiàn)了用戶(hù)態(tài)和內(nèi)核態(tài)的內(nèi)存共享,所以性能好。
我前期被這個(gè)觀(guān)點(diǎn)誤導(dǎo)了好久,后來(lái)下來(lái)了 Linux 源碼,翻了一下,并沒(méi)有在 epoll 中翻到 mmap 的技術(shù)點(diǎn),所以這個(gè)觀(guān)點(diǎn)是錯(cuò)誤的。
這些錯(cuò)誤觀(guān)點(diǎn)的文章,國(guó)內(nèi)不少,國(guó)外也不少,希望大家能審慎抉擇,避免被錯(cuò)誤帶偏。
所以,epoll 高性能的根本就是,其高效的文件描述符處理方式加上頗具特性邊的緣觸發(fā)處理模式,以極少的內(nèi)核態(tài)和用戶(hù)態(tài)的切換,實(shí)現(xiàn)了真正意義上的高并發(fā)。
手寫(xiě) epoll 服務(wù)端
實(shí)踐是最好的老師,我們現(xiàn)在已經(jīng)知道了 epoll 之劍怎么嵌入到石頭中的,現(xiàn)在就讓我們不妨嘗試著拔一下看看。
手寫(xiě) epoll 服務(wù)器,具體細(xì)節(jié)如下(非 C 語(yǔ)言 coder,代碼有參考):
#include
詳細(xì)的注釋我都已經(jīng)寫(xiě)上去了,這就是整個(gè) epoll server 端全部源碼了,僅僅只有 200 行左右,是不是很驚訝。
接下來(lái)讓我們來(lái)測(cè)試下性能,看看能夠達(dá)到我們所說(shuō)的單機(jī)百萬(wàn)并發(fā)嗎?其實(shí)悄悄的給你說(shuō),Netty 底層的 C 語(yǔ)言實(shí)現(xiàn),和這個(gè)是差不多的。
單機(jī)百萬(wàn)并發(fā)實(shí)戰(zhàn)
在實(shí)際測(cè)試過(guò)程中,由于要實(shí)現(xiàn)高并發(fā),那么肯定得使用 ET 模式了。
但是由于這塊內(nèi)容更多的是 Linux 配置的調(diào)整,且前人已經(jīng)有了具體的文章了,所以這里就不做過(guò)多的解釋了。
這里我們主要是利用 VMware 虛擬機(jī)一主三從,參數(shù)調(diào)優(yōu),來(lái)實(shí)現(xiàn)百萬(wàn)并發(fā)。
此塊內(nèi)容由于比較復(fù)雜,先暫時(shí)放一放,后續(xù)將會(huì)搭建環(huán)境并對(duì)此手寫(xiě) server 進(jìn)行壓測(cè)。
審核編輯 :李倩
-
多線(xiàn)程
+關(guān)注
關(guān)注
0文章
279瀏覽量
20348 -
模型
+關(guān)注
關(guān)注
1文章
3500瀏覽量
50138 -
服務(wù)端
+關(guān)注
關(guān)注
0文章
68瀏覽量
7202
原文標(biāo)題:Netty如何做到單機(jī)百萬(wàn)并發(fā)?
文章出處:【微信號(hào):芋道源碼,微信公眾號(hào):芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
鴻蒙5開(kāi)發(fā)寶藏案例分享---應(yīng)用并發(fā)設(shè)計(jì)
從云端到單機(jī)的數(shù)據(jù)匿名化全攻略
RK3568驅(qū)動(dòng)指南|第三篇-并發(fā)與競(jìng)爭(zhēng)-第19章 并發(fā)與競(jìng)爭(zhēng)實(shí)驗(yàn)

產(chǎn)品如何做到可靠的防靜電設(shè)計(jì)

藍(lán)牙AOA定位系統(tǒng)如何做到高精準(zhǔn)度?
ADC7846如何做到使用手指觸摸有效?
兩個(gè)高速ADC的CLK時(shí)鐘如何做到同步無(wú)相位差?
工程行業(yè)中如何做到低碳甚至零碳
TPA3251如何做到180W的功率,電壓12V,電流應(yīng)該多少?
寫(xiě) Verilog 如何做到心中有電路?
定華雷達(dá)儀表學(xué)堂:雷達(dá)物位計(jì)如何做到測(cè)量無(wú)死角
高并發(fā)物聯(lián)網(wǎng)云平臺(tái)是什么
高并發(fā)系統(tǒng)的藝術(shù):如何在流量洪峰中游刃有余





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論