 一個基于參數更新的遷移學習的統一框架
一個基于參數更新的遷移學習的統一框架
1 簡介
在下游任務對大規模預訓練模型進行finetune已經成為目前NLP一種流行的學習方法,然而傳統的finetune方法會更新預訓練語言模型的全部參數,這種方式隨著模型尺寸跟下游任務數量的增加會變得難以承受。
于是乎,出現了一系列高效的更新參數的遷移學習方式,通過只更新少量模型參數來保證下游任務的效果,例如前面章節提及的prompt learning,Adapter,LoRA,BitFit等方法。
這些方法雖然有效,但他們成功的原因跟彼此之間的聯系卻不明所以,這對我們理解這些關鍵設計造成了阻礙。
在這個章節,我們介紹一篇ICLR2022相關的論文,它提出一個基于參數更新的遷移學習的統一框架,建立多種參數優化方法之間的聯系,從而方便理解不同方法背后的關鍵設計,進而設計出只更新更少參數同時取得更好效果的參數優化方法。
2 背景
在這個篇章,我們從另一種角度去回顧之前提及的多種高效的參數優化方法,通過一種更加抽象的方式去解析其中的原理跟細節,從而比對彼此之間的共性與差異,構建一個統一的框架。
2.1 Prefix tuning
Prefix tuning會在每層transformer的多個attention的key跟value向量中插入l個用于更新參數的prefix向量,每個attention的計算公式如下,其中的Pk,Pv就是新插入的prefix向量。

圖1:prefix tuning
而等式的前半部分是不加入prefix向量的初始attention計算的公式,后半部分則是跟上下文向量C無關的部分,通過一個類似門的機制來計算前后兩部分的比重,如果用h表示原本的attention模塊輸出,那么prefix tuning的attention計算可以寫成如下形式,加入prefix的attention模塊輸出等于原本attention模塊輸出和一個的與上下文無關的增量之間的加權平均。
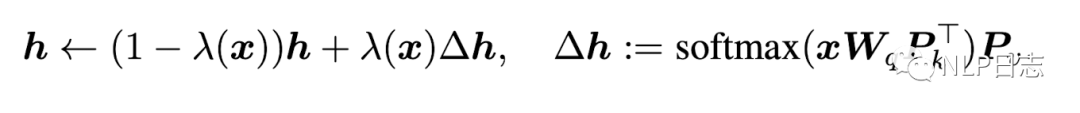
2.2 Adapter
Adapter方法在transformer層子模塊之間插入一些新的模塊,在Adapter內部,它的輸入h通過矩陣乘法Wdown,先將特征維度縮小,然后通過一個非線形層f,再通過矩陣乘法Wup將特征維度放大到跟adapter輸入一樣的尺寸,最后通過一個跨層連接,將adapter的輸入跟上述結果加到一起作為最終adapter的輸出,即下圖形式。
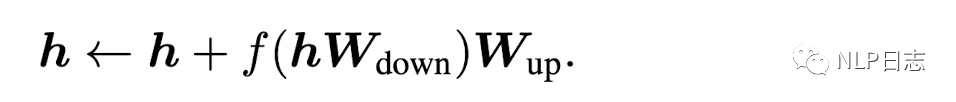
同樣包括前面兩部分,前面部分還是原先的輸入h,而后面部分則是h的一個增量變化,但是相比prefix tuning這里用于計算的前面兩部分的權重的門的機制,同樣可以把上式改寫為以下形式。
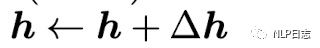
2.3LoRA
LoRA在transformer的權重矩陣旁插入了一個低秩矩陣,用于近似權重更新,對于預訓練模型的權重矩陣W,LoRA通過低秩分解將其表示為如下形式,其中s是一個可訓練的參數,在形式跟LoRA極其相似,只是少了一個中間非線性運算和多了一個標準化參數s。
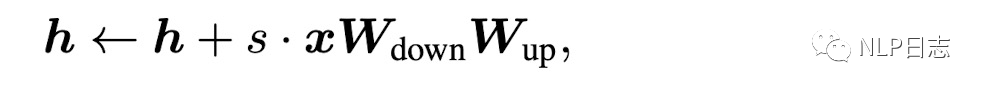
3.1 The unified framework
通過對上述幾種方法的抽象表示,不難發現這幾種方法存在一定的共性,隱藏層的最終表征都由兩部分組成,分別是原始的語言模型的輸出跟新的增量兩部分,雖然很多關鍵設計有所不同,但是這幾種方法都在學習應用于各種隱藏表征的一個修正向量,也就是后半部分。
為了建立統一的框架去理解這些不同方法背后的關鍵設計,論文定義了以下四個設計維度,并分析了不同方法在這四個維度之間的差異跟聯系。
a) Functional Form,修正向量的計算方式,下圖中的第二列。
b) Modified Representation,直接調整的隱藏表征位置,作用于attetnion模塊還是FFN模塊?
c) Insertion Form,新增模塊如何插入語言模型中?序列化還是并行化?
如果輸入是語言模型的輸入,輸出是語言模型的輸出,則屬于并行化,類似于Prefix tuning,如果輸入跟輸出都是語言模型的輸出,則屬于序列化,類似于Adapter.
d)Composition Form,修正向量跟原本的隱藏層表征如何結合到一起去構建新的隱藏層表征?
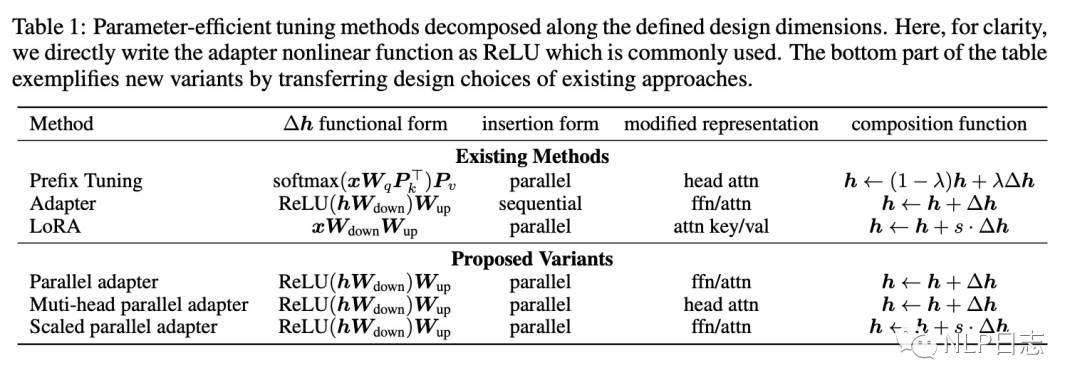
圖2:不同方法在4個設計維度下的具體信息
在提出上述統一的框架后,通過調整某些設計維度下的信息,論文提出了3種新的遷移學習方法的設計,具體細節可以參考下圖理解。
a)Parallel Adapter,
將prefix tuning的并行插入方式遷移到Adapter,也就是把Adapter的insertion form的屬性改成prefix tuning。
b)Multi-head Parallel Adapter
將Parallel Adapter應用到multi head attention的位置,也就是把Parallel Adapter的modified representation的屬性改成prefix tuning。
c)Scaled Parallel Adapter
將LoRA的復合函數跟插入方式遷移到Adapter,也就是把Adapter的composition form跟insertion form的屬性改成LoRA
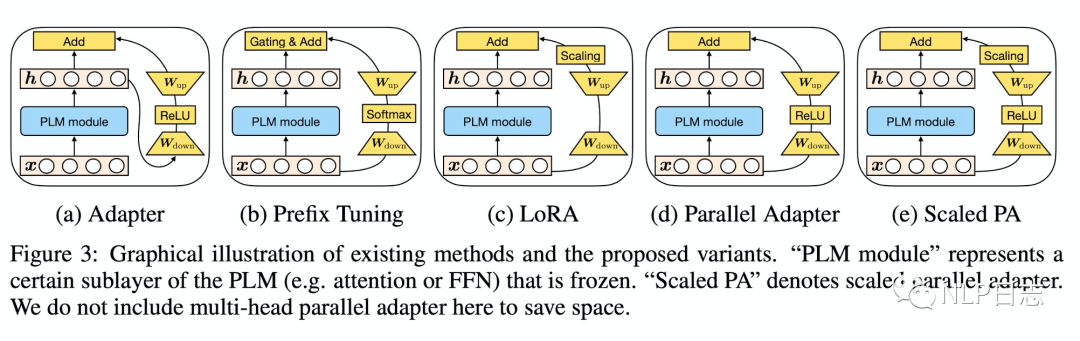
圖3:多種參數優化方法結構對比
4 實驗
為了探索不同的設計維度所隱藏的特性,以及哪些設計維度尤為重要,論文在4個不同類型的下游任務上進行了實驗,包括文本總結,文本翻譯,文本推斷以及情感分類任務,相應的數據集分別為XSum, en-ro, MNLI, SST2。至于語言模型的選擇,為了更貼合當前實際,論文使用了encoder-decoder結構的語言模型在前兩者上做實驗,而使用encoder結構的語言模型在后兩者上進行實驗。
a)當下主流方法的表現
在文本推斷跟情感分類任務的數據集上,現存的幾種主流方法在只更新小于1%的參數量條件下可以達到媲美更新全部模型參數的效果,但在文本總結跟翻譯任務數據集上,即便增加要更新的參數量,這幾種參數優化的方法距離更新全部模型參數的方法在效果上仍有一定差距。
這也說明那些宣稱可以媲美finetune全部參數方法效果的參數優化方法,其實是在只包含encoder的模型并在GLUE上取得,或者是基于encoder-decoder的模型在相對簡單的文本生成任務上取得媲美finetune全部參數的效果,不能泛化到其他標準評測任務。
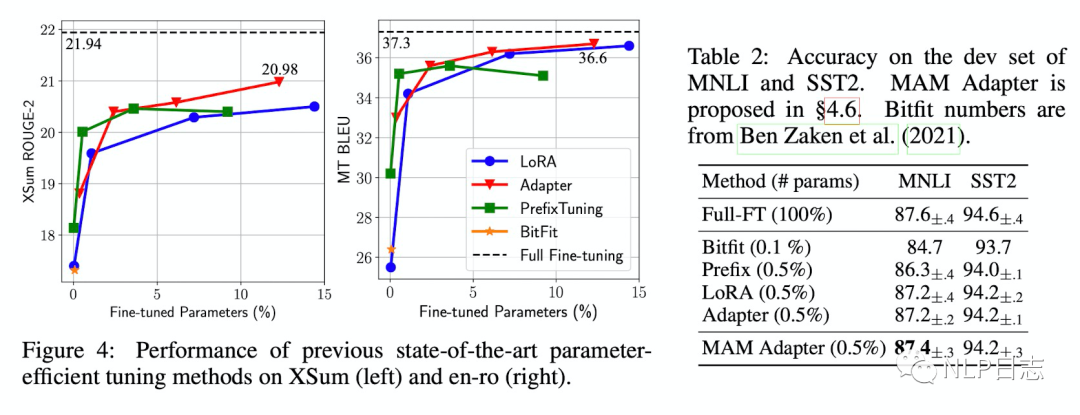
圖4:目前幾種主流方法的效果對比
b)Insertion Form
下圖中,SA指的是Adapter,相應的insertion form是sequential,PA則是Parallel Adapter,相應的insertion form跟prefix tuning一樣,都是parallel。
從實驗結果看,使用parallel作為插入方式的prefix tuning跟PA效果明顯優于SA,從而說明parallel的插入形式更優。
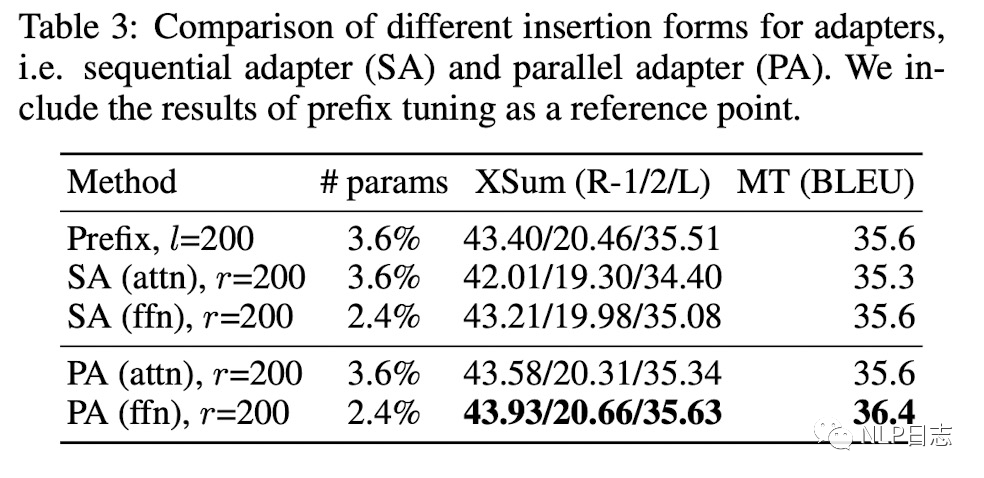
圖5:Insertion Form對比
c)ModifiedRepresentation
從下圖可以看出,直接作用于FFN層的方法的效果明顯優化作用于attention層,這些結果顯示FFN層可以更高效的利用新增的參數進行調整。這可能是由于FFN層學習的是具體任務的文本模式,而attention層學習的是文本不同位置之間的交互,具有一定泛化能力,不需要特地為新任務做太多調整導致的。
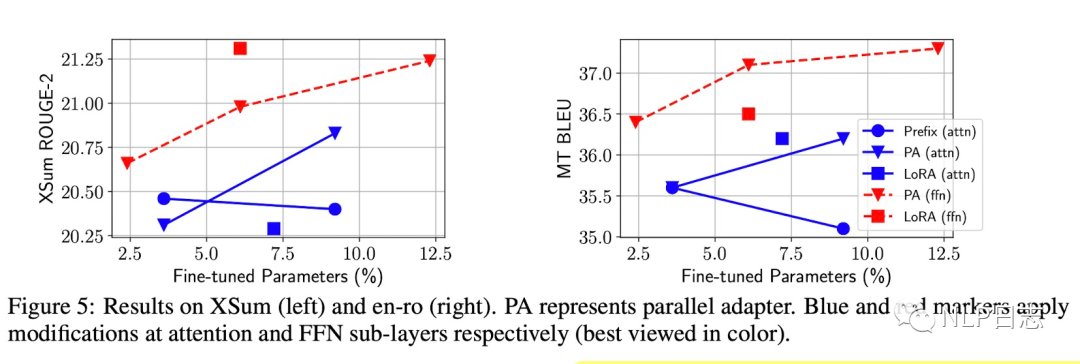
圖6:modified representation對比
當更新的參數量從3.6%減少到0.1%時,作用于attention模塊的MH PA(attn)跟prefix tuning的方法在效果上領先于其他方法。
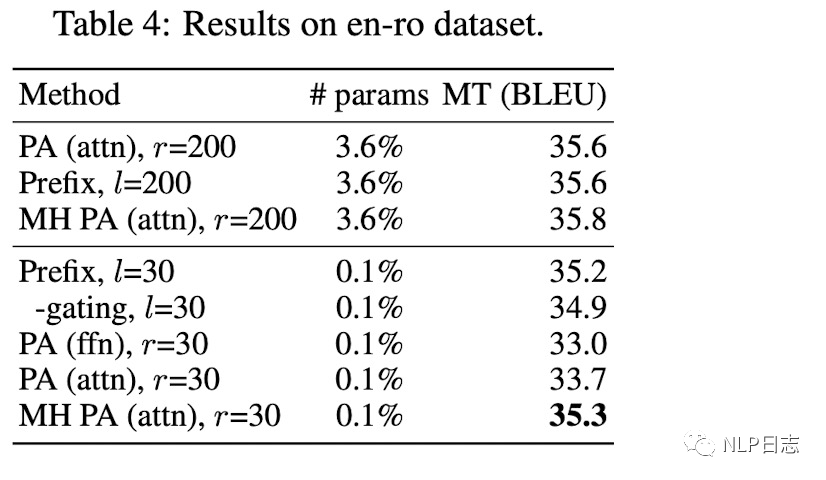
圖7:multi head attention的有效性
結合上述實驗效果,當目標參數量非常少時,作用于attention層的方法可以取得更好效果,反之,則優先選擇作用于FFN層的方法。
d) Composition Function
不難看出,scaling的復合函數效果優于簡單相加的復合函數。
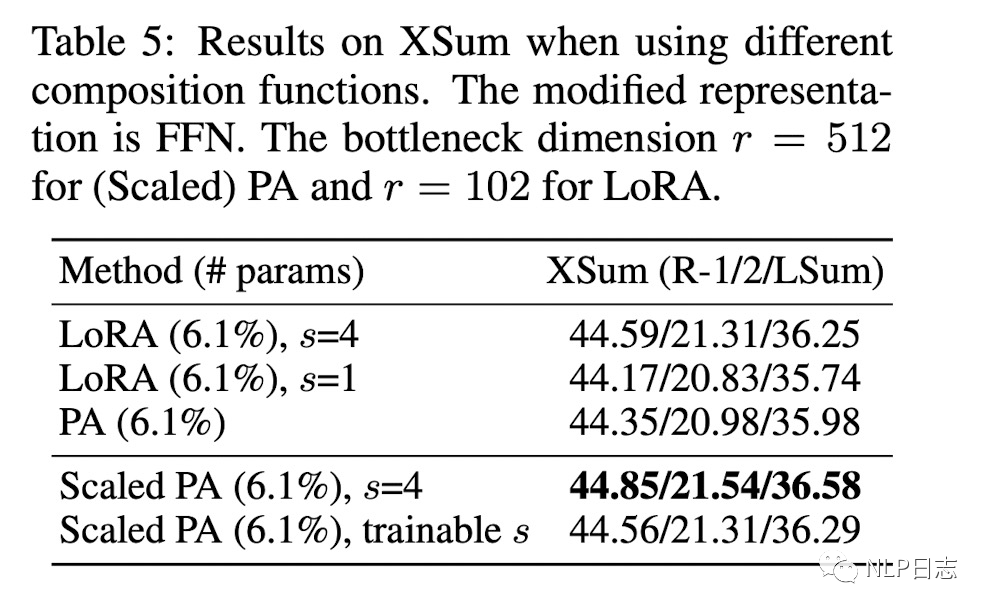
圖8:不同composition function對比
5 總結
基于前面的實驗結論,論文有以下重大發現:
a) Scaled parallel adapter是作用于FFN層的最好變體。
b) FFN層可以通過更多的參數從而更好優化下游模型表現。
c)類似于prefix tuning的作用于attention的方式可以在僅更新0.1%比例參數量的前提下得到不錯效果。
于是論文提出一種新的方法Mix-And-Match adapter(MAM Adapter),它包括作用于attention模塊30個prefix tuning向量,以及引入更多參數量的scaled parallel adapter,在諸多任務上取得了SOTA效果。融合prefix tuning跟scaled parallel adapter的結構,并根據它們的特點分配合適的優化參數,從而達到一個整體的更優。
之前在學習怎么高效的參數優化方法時總是感覺里面有很多神似的地方,但是建立不了其中的聯系,看到這篇論文后,有一種茅塞頓開的領悟,這篇文章提出的統一框架能夠幫助大家更好的理解這些參數優化方法,從而更好理解這些關鍵設計帶來的價值。具體到個人,可以根據自己的任務和場景,設計出更加靈活的參數優化的遷移學習方案了。
審核編輯:劉清
-
SST
+關注
關注
0文章
69瀏覽量
35608 -
GLUE
+關注
關注
0文章
5瀏覽量
7471 -
LoRa技術
+關注
關注
3文章
102瀏覽量
16824
原文標題:Parameter-efficient transfer learning系列之A Unified View
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于動態編譯(Just-in-Time)的全新深度學習框架
兩個EXCEL文件,一每天更新,一固定不變; 用新的更新計劃和固定標準對比,取出一個值;這種結構框架怎么弄??
分享一種智能網卡對熱遷移支持的新思路
面向用戶的IMS媒體層統一安全框架
屏幕衍生商機 統一化框架助力UI設計
深度學習發展的5個主力框架

PLASTER:一個與深度學習性能有關的框架
天才黑客George Hotz開源了一個小型深度學習框架tinygrad
統一框架下期望在線核選擇的競爭性分析

基于谷歌中長尾item或user預測效果的遷移學習框架
一文詳解遷移學習
視覺深度學習遷移學習訓練框架Torchvision介紹






 工商網監
工商網監
評論