") goroutine調(diào)度器的概念、演進(jìn)及場景分析
goroutine調(diào)度器的概念、演進(jìn)及場景分析

goroutine 調(diào)度器的概念
說到“調(diào)度”,首先會想到操作系統(tǒng)對進(jìn)程、線程的調(diào)度。操作系統(tǒng)調(diào)度器會將系統(tǒng)中的多個線程按照一定算法調(diào)度到物理 CPU 上去運行。
傳統(tǒng)的編程語言比如 C、C++ 等的并發(fā)實現(xiàn)實際上就是基于操作系統(tǒng)調(diào)度的,即程序負(fù)責(zé)創(chuàng)建線程,操作系統(tǒng)負(fù)責(zé)調(diào)度。
盡管線程的調(diào)度方式相對于進(jìn)程來說,線程運行所需要資源比較少,在同一進(jìn)程中進(jìn)行線程切換效率會高很多,但實際上多線程開發(fā)設(shè)計會變得更加復(fù)雜,要考慮很多同步競爭等問題,如鎖、競爭沖突等。
線程是操作系統(tǒng)調(diào)度時的最基本單元,而 Linux 在調(diào)度器并不區(qū)分進(jìn)程和線程的調(diào)度,只是說線程調(diào)度因為資源少,所以切換的效率比較高。
使用多線程編程會遇到以下問題:
并發(fā)單元間通信困難,易錯:多個 thread 之間的通信雖然有多種機制可選,但用起來是相當(dāng)復(fù)雜;并且一旦涉及到共享內(nèi)存,就會用到各種 lock,一不小心就會出現(xiàn)死鎖的情況。
對于線程池的大小不好確認(rèn),在請求量大的時候容易導(dǎo)致 OOM 的情況
雖然線程比較輕量,但是在調(diào)度時也有比較大的額外開銷。每個線程會都占用 1 兆以上的內(nèi)存空間,在對線程進(jìn)行切換時不僅會消耗較多的內(nèi)存,恢復(fù)寄存器中的內(nèi)容還需要向操作系統(tǒng)申請或者銷毀對應(yīng)的資源,每一次線程上下文的切換仍然需要一定的時間(us 級別)
對于很多網(wǎng)絡(luò)服務(wù)程序,由于不能大量創(chuàng)建 thread,就要在少量 thread 里做網(wǎng)絡(luò)多路復(fù)用,例如 JAVA 的Netty 框架,寫起這樣的程序也不容易。
這便有了“協(xié)程”,線程分為內(nèi)核態(tài)線程和用戶態(tài)線程,用戶態(tài)線程需要綁定內(nèi)核態(tài)線程,CPU 并不能感知用戶態(tài)線程的存在,它只知道它在運行1個線程,這個線程實際是內(nèi)核態(tài)線程。
用戶態(tài)線程實際有個名字叫協(xié)程(co-routine),為了容易區(qū)分,使用協(xié)程指用戶態(tài)線程,使用線程指內(nèi)核態(tài)線程。
協(xié)程跟線程是有區(qū)別的,線程由CPU調(diào)度是搶占式的,協(xié)程由用戶態(tài)調(diào)度是協(xié)作式的,一個協(xié)程讓出 CPU 后,才執(zhí)行下一個協(xié)程。
Go中,協(xié)程被稱為 goroutine(但其實并不完全是協(xié)程,還做了其他方面的優(yōu)化),它非常輕量,一個 goroutine 只占幾 KB,并且這幾 KB 就足夠 goroutine 運行完,這就能在有限的內(nèi)存空間內(nèi)支持大量 goroutine,支持了更多的并發(fā)。雖然一個 goroutine 的棧只占幾 KB,但實際是可伸縮的,如果需要更多內(nèi)容,runtime會自動為 goroutine 分配。
而將所有的 goroutines 按照一定算法放到 CPU 上執(zhí)行的程序就稱為 goroutine 調(diào)度器或 goroutine scheduler。
不過,一個 Go 程序?qū)τ诓僮飨到y(tǒng)來說只是一個用戶層程序,對于操作系統(tǒng)而言,它的眼中只有 thread,它并不知道有什么叫 Goroutine 的東西的存在。goroutine 的調(diào)度全要靠 Go 自己完成,所以就需要 goroutine 調(diào)度器來實現(xiàn) Go 程序內(nèi) goroutine 之間的 CPU 資源調(diào)度。
在操作系統(tǒng)層面,Thread 競爭的 CPU 資源是真實的物理 CPU,但對于 Go 程序來說,它是一個用戶層程序,它本身整體是運行在一個或多個操作系統(tǒng)線程上的,因此 goroutine 們要競爭的所謂 “CPU” 資源就是操作系統(tǒng)線程。
這樣 Go scheduler 的要做的就是:將 goroutines 按照一定算法放到不同的操作系統(tǒng)線程中去執(zhí)行。這種在語言層面自帶調(diào)度器的,稱之為原生支持并發(fā)。
goroutine 調(diào)度器的演進(jìn)
調(diào)度器的任務(wù)是在用戶態(tài)完成 goroutine 的調(diào)度,而調(diào)度器的實現(xiàn)好壞,對并發(fā)實際有很大的影響。
G-M模型
現(xiàn)在的 Go語言調(diào)度器是 2012 年重新設(shè)計的,在這之前的調(diào)度器稱為老調(diào)度器,老調(diào)度器采用的是 G-M 模型,在這個調(diào)度器中,每個 goroutine 對應(yīng)于 runtime 中的一個抽象結(jié)構(gòu):G,而 os thread 作為物理 CPU 的存在而被抽象為一個結(jié)構(gòu):
M(machine)。M 想要執(zhí)行 G、放回 G 都必須訪問全局 G 隊列,并且 M 有多個,即多線程訪問同一資源需要加鎖進(jìn)行保證互斥/同步,所以全局 G 隊列是有互斥鎖進(jìn)行保護(hù)的。
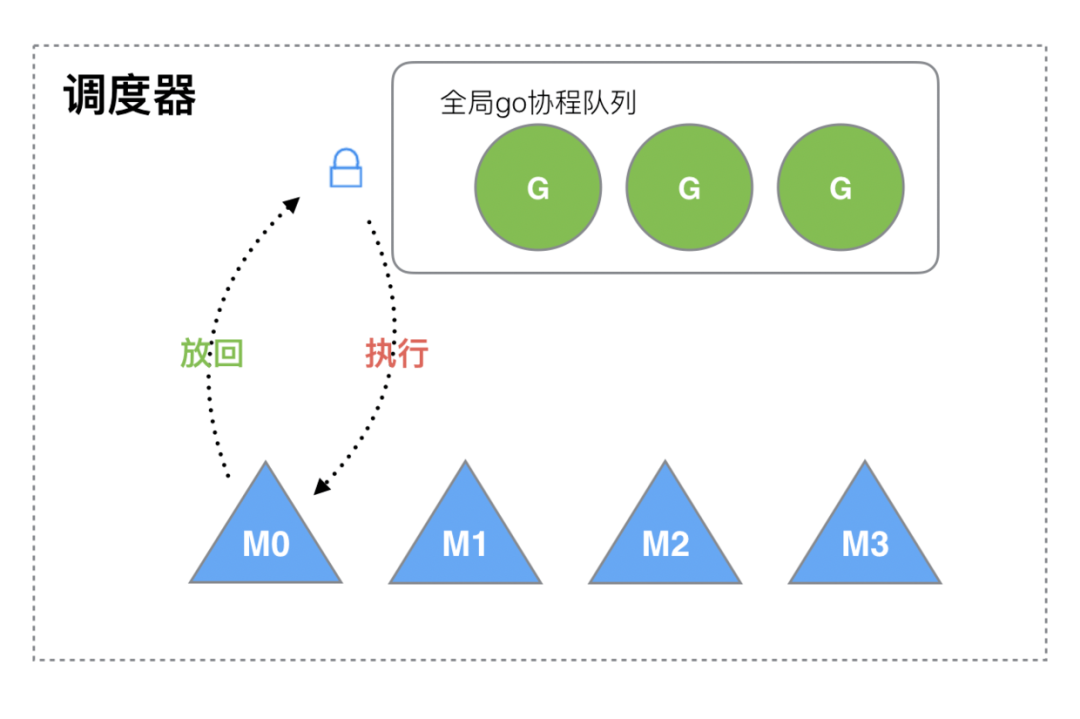
這個結(jié)構(gòu)雖然簡單,但是卻存在著許多問題。它限制了 Go 并發(fā)程序的伸縮性,尤其是對那些有高吞吐或并行計算需求的服務(wù)程序。主要體現(xiàn)在如下幾個方面:
單一全局互斥鎖(Sched.Lock)和集中狀態(tài)存儲的存在導(dǎo)致所有 goroutine 相關(guān)操作,比如:創(chuàng)建、重新調(diào)度等都要上鎖,這會造成激烈的鎖競爭
goroutine 傳遞問題:M 經(jīng)常在 M 之間傳遞可運行的 goroutine,這導(dǎo)致調(diào)度延遲增大以及額外的性能損耗
每個 M 做內(nèi)存緩存,導(dǎo)致內(nèi)存占用過高,數(shù)據(jù)局部性較差
系統(tǒng)調(diào)用導(dǎo)致頻繁的線程阻塞和取消阻塞操作增加了系統(tǒng)開銷
所以用了 4 年左右就被替換掉了。
G-P-M 模型
面對之前調(diào)度器的問題,Go 設(shè)計了新的調(diào)度器,并在其中引入了 P(Processor),另外還引入了任務(wù)竊取調(diào)度的方式(work stealing)
P:Processor,它包含了運行 goroutine 的資源,如果線程想運行 goroutine,必須先獲取 P,P 中還包含了可運行的 G 隊列。work stealing:當(dāng) M 綁定的 P 沒有可運行的 G 時,它可以從其他運行的 M 那里偷取G。G-P-M 模型的結(jié)構(gòu)如下圖:
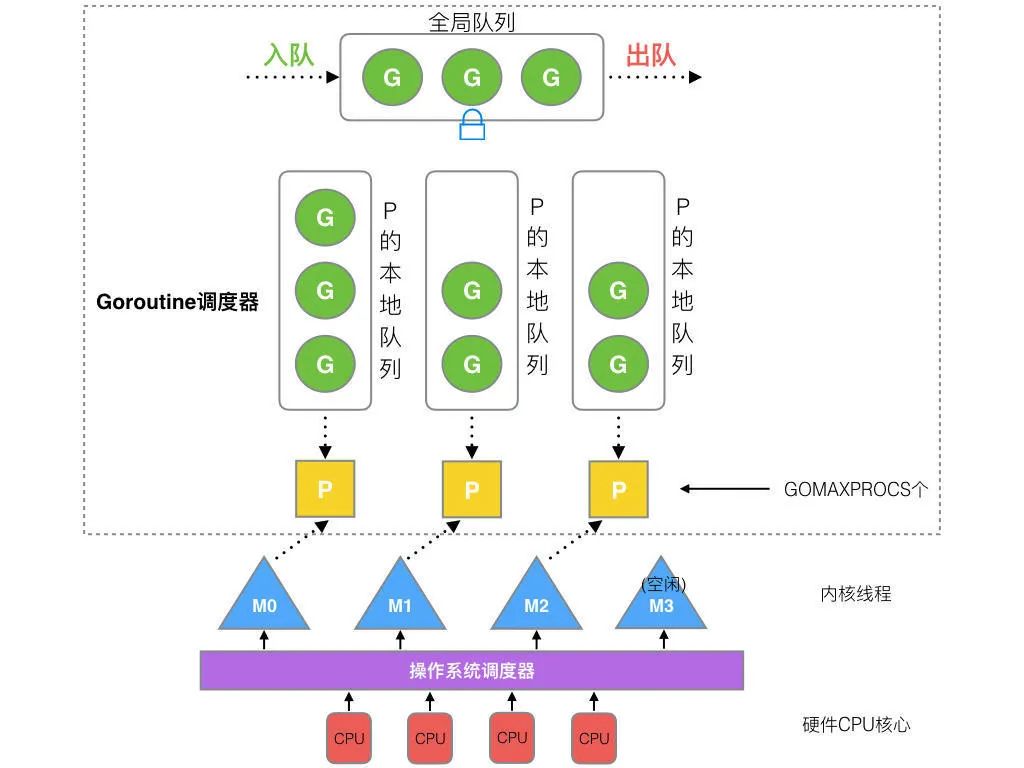
從上往下是調(diào)度器的4個部分:
全局隊列(Global Queue):存放等待運行的 G。P 的本地隊列:同全局隊列類似,存放的也是等待運行的G,存的數(shù)量有限,不超過256個。新建 G 時,G 優(yōu)先加入到 P 的本地隊列,如果隊列滿了,則會把本地隊列中一半的 G 移動到全局隊列。P列表:所有的 P 都在程序啟動時創(chuàng)建,并保存在數(shù)組中,最多有 GOMAXPROCS 個。M:線程想運行任務(wù)就得獲取 P,從 P 的本地隊列獲取 G,P 隊列為空時,M 也會嘗試從全局隊列拿一批 G放到 P 的本地隊列,或從其他 P 的本地隊列偷一半放到自己 P 的本地隊列。M 運行 G,G 執(zhí)行之后,M 會從 P 獲取下一個 G,不斷重復(fù)下去。Goroutine 調(diào)度器和 OS 調(diào)度器是通過 M 結(jié)合起來的,每個 M 都代表了1個內(nèi)核線程,OS 調(diào)度器負(fù)責(zé)把內(nèi)核線程分配到 CPU 的核上執(zhí)行。
有關(guān) P 和 M 的個數(shù)問題
P 的數(shù)量
由啟動時環(huán)境變量 $GOMAXPROCS 或者是由 runtime 的方法 GOMAXPROCS() 決定。這意味著在程序執(zhí)行的任意時刻都只有 $GOMAXPROCS 個 goroutine 在同時運行。
M 的數(shù)量
go 語言本身的限制:go 程序啟動時,會設(shè)置 M 的最大數(shù)量,默認(rèn) 10000。但是內(nèi)核很難支持這么多的線程數(shù),所以這個限制可以忽略。
runtime/debug 中的 SetMaxThreads 函數(shù),可以設(shè)置 M 的最大數(shù)量
一個 M 阻塞了,會創(chuàng)建新的 M。
M 與 P 的數(shù)量沒有絕對關(guān)系,一個 M 阻塞,P 就會去創(chuàng)建或者切換另一個 M,所以,即使 P 的默認(rèn)數(shù)量是 1,也有可能會創(chuàng)建很多個 M 出來。
搶占式調(diào)度
G-P-M 模型中還實現(xiàn)了搶占式調(diào)度,所謂搶占式調(diào)度指的是在 coroutine 中要等待一個協(xié)程主動讓出 CPU 才執(zhí)行下一個協(xié)程,在 Go 中,一個 goroutine 最多占用CPU 10ms,防止其他 goroutine 被餓死,這也是 goroutine 不同于 coroutine 的一個地方。在 goroutine 中先后實現(xiàn)了兩種搶占式調(diào)度算法,分別是基于協(xié)作的方式和基于信號的方式。
基于協(xié)作的搶占式調(diào)度
G-P-M 模型的實現(xiàn)是 Go scheduler 的一大進(jìn)步,但此時的調(diào)度器仍然有一個問題,那就是不支持搶占式調(diào)度,導(dǎo)致一旦某個 G 中出現(xiàn)死循環(huán)或永久循環(huán)的代碼邏輯,那么 G 將永久占用分配給它的 P 和 M,位于同一個 P 中的其他 G 將得不到調(diào)度,出現(xiàn)“餓死”的情況。當(dāng)只有一個 P 時(GOMAXPROCS=1)時,整個 Go 程序中的其他 G 都會被餓死。所以后面 Go 設(shè)計團隊在 Go 1.2 中實現(xiàn)了基于協(xié)作的搶占式調(diào)度。
這種搶占式調(diào)度的原理則是在每個函數(shù)或方法的入口,加上一段額外的代碼,讓 runtime 有機會檢查是否需要執(zhí)行搶占調(diào)度。
基于協(xié)作的搶占式調(diào)度的工作原理大致如下:
編譯器會在調(diào)用函數(shù)前插入一個 runtime.morestack 函數(shù)
Go 語言運行時會在垃圾回收暫停程序、系統(tǒng)監(jiān)控發(fā)現(xiàn) Goroutine 運行超過 10ms 時發(fā)出搶占請求,此時會設(shè)置一個 StackPreempt 字段值為 StackPreempt ,標(biāo)示當(dāng)前 Goroutine 發(fā)出了搶占請求。
當(dāng)發(fā)生函數(shù)調(diào)用時,可能會執(zhí)行編譯器插入的 runtime.morestack 函數(shù),它調(diào)用的 runtime.newstack 會檢查 Goroutine 的 stackguard0 字段是否為 StackPreempt
如果 stackguard0 是 StackPreempt,就會觸發(fā)搶占讓出當(dāng)前線程
這種實現(xiàn)方式雖然增加了運行時的復(fù)雜度,但是實現(xiàn)相對簡單,也沒有帶來過多的額外開銷,所以在 Go 語言中使用了 10 幾個版本。因為這里的搶占是通過編譯器插入函數(shù)實現(xiàn)的,還是需要函數(shù)調(diào)用作為入口才能觸發(fā)搶占,所以這是一種協(xié)作式的搶占式調(diào)度。這種解決方案只能說局部解決了“餓死”問題,對于沒有函數(shù)調(diào)用,純算法循環(huán)計算的 G,scheduler 依然無法搶占。
基于信號的搶占式調(diào)度
Go 語言在 1.14 版本中實現(xiàn)了非協(xié)作的搶占式調(diào)度,在實現(xiàn)的過程中重構(gòu)已有的邏輯并為 Goroutine 增加新的狀態(tài)和字段來支持搶占。
基于信號的搶占式調(diào)度的工作原理大致如下:
程序啟動時,在runtime.sighandler函數(shù)中注冊一個 SIGURG 信號的處理函數(shù)runtime.doSigPreempt
在觸發(fā)垃圾回收的棧掃描時會調(diào)用函數(shù) runtime.suspendG 掛起 Goroutine,此時會執(zhí)行下面的邏輯:
將處于運行狀態(tài)(_Grunning)的 Goroutine 標(biāo)記成可以被搶占,即將 Goroutine 的字段 preemptStop 設(shè)置成 true;
調(diào)用 runtime.preemptM函數(shù), 它可以通過 SIGURG 信號向線程發(fā)送搶占請求觸發(fā)搶占;
runtime.preemptM 會調(diào)用 runtime.signalM 向線程發(fā)送信號 SIGURG;
操作系統(tǒng)收到信號后會中斷正在運行的線程并執(zhí)行預(yù)先在第 1 步注冊的信號處理函數(shù) runtime.doSigPreempt;
runtime.doSigPreempt 函數(shù)會處理搶占信號,獲取當(dāng)前的 SP 和 PC 寄存器并調(diào)用 runtime.sigctxt.pushCall;
runtime.sigctxt.pushCall 會修改寄存器并在程序回到用戶態(tài)時執(zhí)行 runtime.asyncPreempt;
匯編指令 runtime.asyncPreempt 會調(diào)用運行時函數(shù) runtime.asyncPreempt2;
runtime.asyncPreempt2 會調(diào)用 runtime.preemptPark;
runtime.preemptPark會修改當(dāng)前 Goroutine 的狀態(tài)到_Gpreempted并調(diào)用runtime.schedule讓當(dāng)前函數(shù)陷入休眠并讓出線程,調(diào)度器會選擇其它的 Goroutine 繼續(xù)執(zhí)行
_Gpreempted狀態(tài)表示當(dāng)前 groutine 由于搶占而被阻塞,沒有執(zhí)行用戶代碼并且不在運行隊列上,等待喚醒
在上面的選擇 SIGURG 作為觸發(fā)異步搶占的信號:
該信號需要被調(diào)試器透傳;
該信號不會被內(nèi)部的 libc 庫使用并攔截;
該信號可以隨意出現(xiàn)并且不觸發(fā)任何后果;
需要處理多個平臺上的不同信號;
垃圾回收過程中需要暫停整個程序(Stop the world,STW),有時候可能需要幾分鐘的時間,這會導(dǎo)致整個程序無法工作。所以 STW 和棧掃描是一個可以搶占的安全點(Safe-points), Go 語言在這里先加入搶占功能。基于信號的搶占式調(diào)度只解決了垃圾回收和棧掃描時存在的問題,它到目前為止沒有解決全部問題。
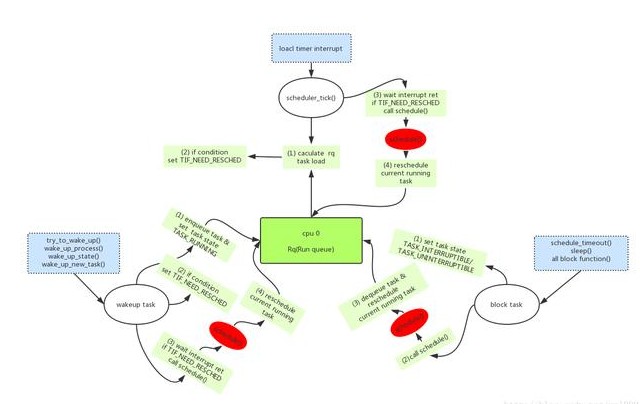
go func() 調(diào)度流程
基于上面的模型,當(dāng)我們使用 go func()創(chuàng)建一個新的 goroutine 的時候,其調(diào)度流程如下:
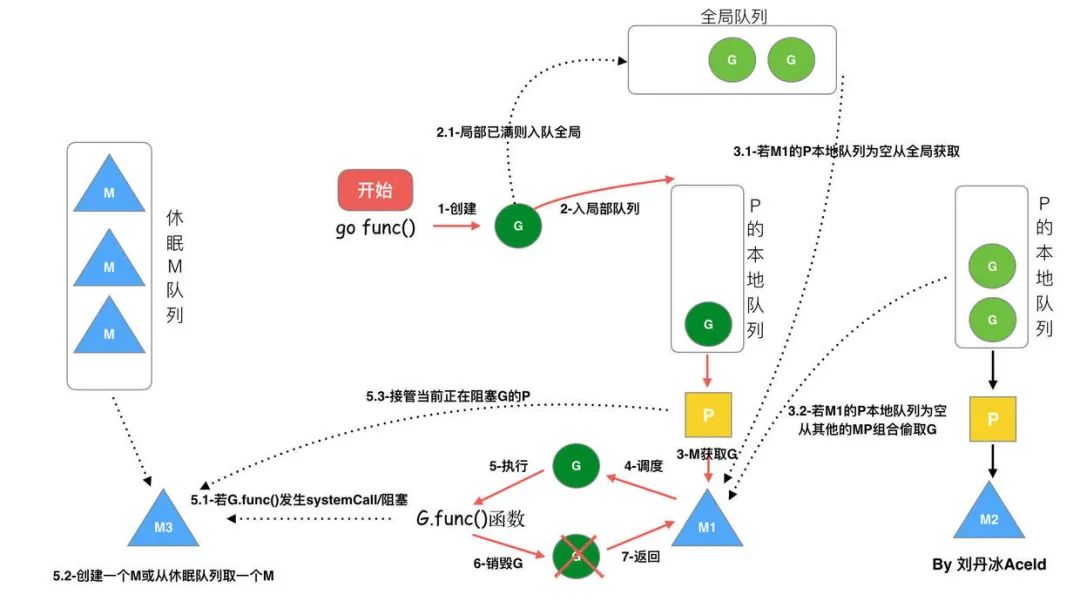
通過 go func ()來創(chuàng)建一個 goroutine;
有兩個存儲 G 的隊列,一個是局部調(diào)度器 P 的本地隊列、一個是全局 G 隊列。新創(chuàng)建的 G 會先保存在 P 的本地隊列中,如果 P 的本地隊列已經(jīng)滿了就會保存在全局的隊列中;
G 只能運行在 M 中,一個 M 必須持有一個 P,M 與 P 是 1:1 的關(guān)系。M 會從 P 的本地隊列彈出一個可執(zhí)行狀態(tài)的 G 來執(zhí)行,如果 P 的本地隊列為空,就會想其他的 MP 組合偷取一個可執(zhí)行的 G 來執(zhí)行;
一個 M 調(diào)度 G 執(zhí)行的過程是一個循環(huán)機制;
當(dāng) M 執(zhí)行某一個 G 時候如果發(fā)生了 syscall 或則其余阻塞操作,M 會阻塞,如果當(dāng)前有一些 G 在執(zhí)行,runtime 會把這個線程 M 從 P 中摘除 (detach),然后再創(chuàng)建一個新的操作系統(tǒng)的線程 (如果有空閑的線程可用就復(fù)用空閑線程) 來服務(wù)于這個 P;
當(dāng) M 系統(tǒng)調(diào)用結(jié)束時候,這個 G 會嘗試獲取一個空閑的 P 執(zhí)行,并放入到這個 P 的本地隊列。如果獲取不到 P,那么這個線程 M 變成休眠狀態(tài), 加入到空閑線程中,然后這個 G 會被放入全局隊列中。
Goroutine 生命周期
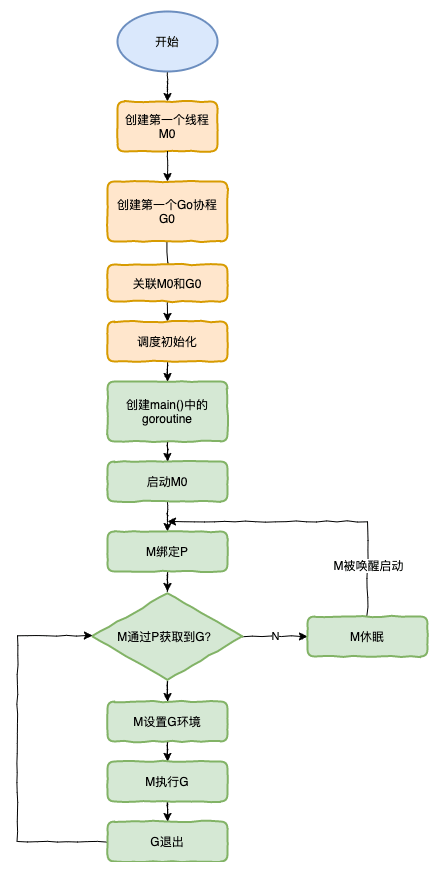
在這里有一個線程和一個 groutine 比較特殊,那就是 M0 和 G0:
M0:M0 是啟動程序后的編號為 0 的主線程,這個 M 對應(yīng)的實例會在全局變量 runtime.m0 中,不需要在 heap 上分配,M0 負(fù)責(zé)執(zhí)行初始化操作和啟動第一個 G, 在之后 M0 就和其他的 M 一樣了。
G0 :G0 是每次啟動一個 M 都會第一個創(chuàng)建的 gourtine,G0 僅用于負(fù)責(zé)調(diào)度的 G,G0 不指向任何可執(zhí)行的函數(shù),每個 M 都會有一個自己的 G0。在調(diào)度或系統(tǒng)調(diào)用時會使用 G0 的棧空間,全局變量的 G0 是 M0 的 G0。
對于下面的簡單代碼:
package main
import "fmt"
// main.main
func main() {
fmt.Println("Hello scheduler")
}
其運行時所經(jīng)歷的過程跟上面的生命周期相對應(yīng):
runtime 創(chuàng)建最初的線程 m0 和 goroutine g0,并把 2 者關(guān)聯(lián)。
調(diào)度器初始化:初始化 m0、棧、垃圾回收,以及創(chuàng)建和初始化由 GOMAXPROCS 個 P 構(gòu)成的 P 列表。
示例代碼中的 main 函數(shù)是 main.main,runtime 中也有 1 個 main 函數(shù)——runtime.main,代碼經(jīng)過編譯后,runtime.main會調(diào)用 main.main,程序啟動時會為 runtime.main 創(chuàng)建 goroutine,稱它為main goroutine,然后把 main goroutine 加入到P的本地隊列。
啟動 m0,m0 已經(jīng)綁定了 P,會從 P 的本地隊列獲取 G,獲取到 main goroutine。
G 擁有棧,M 根據(jù) G 中的棧信息和調(diào)度信息設(shè)置運行環(huán)境
M 運行 G
G 退出,再次回到 M 獲取可運行的 G,這樣重復(fù)下去,直到 main.main 退出,runtime.main執(zhí)行 Defer 和 Panic 處理,或調(diào)用 runtime.exit 退出程序。
調(diào)度器的生命周期幾乎占滿了一個Go程序的一生,runtime.main 的 goroutine 執(zhí)行之前都是為調(diào)度器做準(zhǔn)備工作,runtime.main 的 goroutine 運行,才是調(diào)度器的真正開始,直到 runtime.main 結(jié)束而結(jié)束。
Goroutine 調(diào)度器場景分析
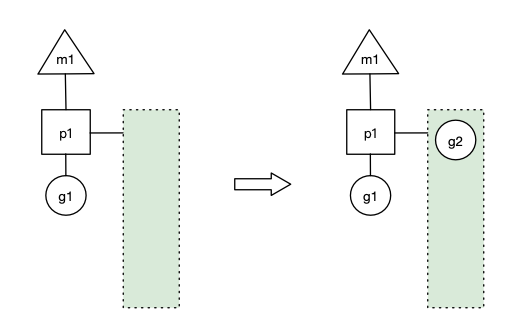
場景一
p1 擁有 g1,m1 獲取 p1 后開始運行g(shù)1,g1 使用 go func() 創(chuàng)建了 g2,為了局部性 g2 優(yōu)先加入到 p1 的本地隊列:
場景二
g1運行完成后(函數(shù):goexit),m 上運行的 goroutine 切換為 g0,g0 負(fù)責(zé)調(diào)度時協(xié)程的切換(函數(shù):schedule)。
從 p1 的本地隊列取 g2,從 g0 切換到 g2,并開始運行 g2 (函數(shù):execute)。實現(xiàn)了線程 m1 的復(fù)用。
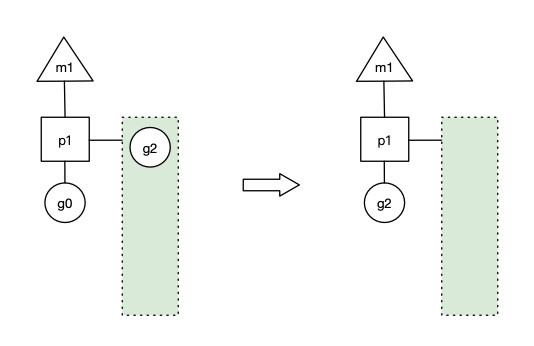
場景三
假設(shè)每個 p 的本地隊列只能存 4 個 g。g2 要創(chuàng)建 6 個 g,前 4 個g(g3, g4, g5, g6)已經(jīng)加入 p1 的本地隊列,p1 本地隊列滿了。
g2 在創(chuàng)建 g7 的時候,發(fā)現(xiàn) p1 的本地隊列已滿,需要執(zhí)行負(fù)載均衡,把 p1 中本地隊列中前一半的 g,還有新創(chuàng)建的 g 轉(zhuǎn)移到全局隊列
實現(xiàn)中并不一定是新的 g,如果 g 是 g2 之后就執(zhí)行的,會被保存在本地隊列,利用某個老的 g 替換新 g 加入全局隊列),這些 g 被轉(zhuǎn)移到全局隊列時,會被打亂順序。
所以 g3,g4,g7 被轉(zhuǎn)移到全局隊列。
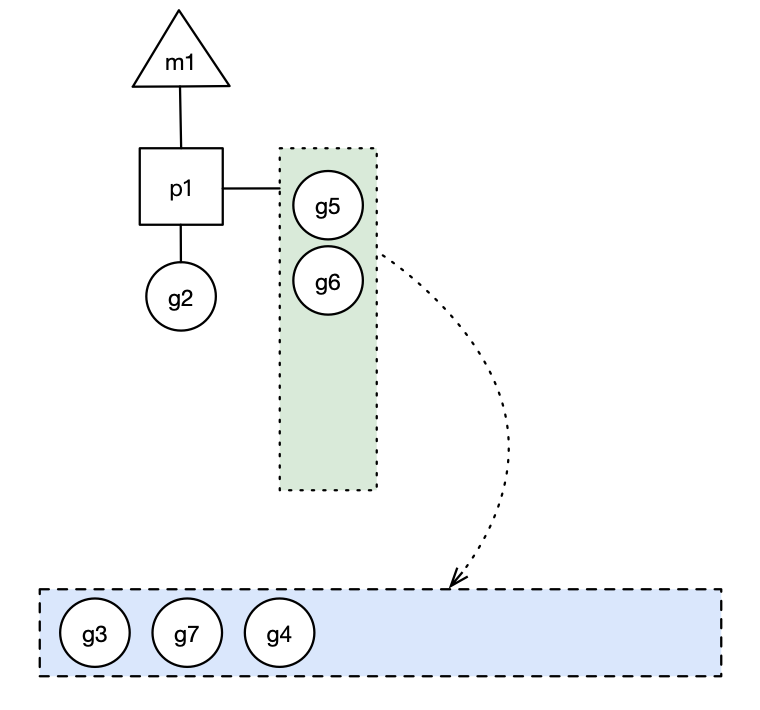
藍(lán)色長方形代表全局隊列。
如果此時 G2 創(chuàng)建 G8 時,P1 的本地隊列未滿,所以 G8 會被加入到 P1 的本地隊列:
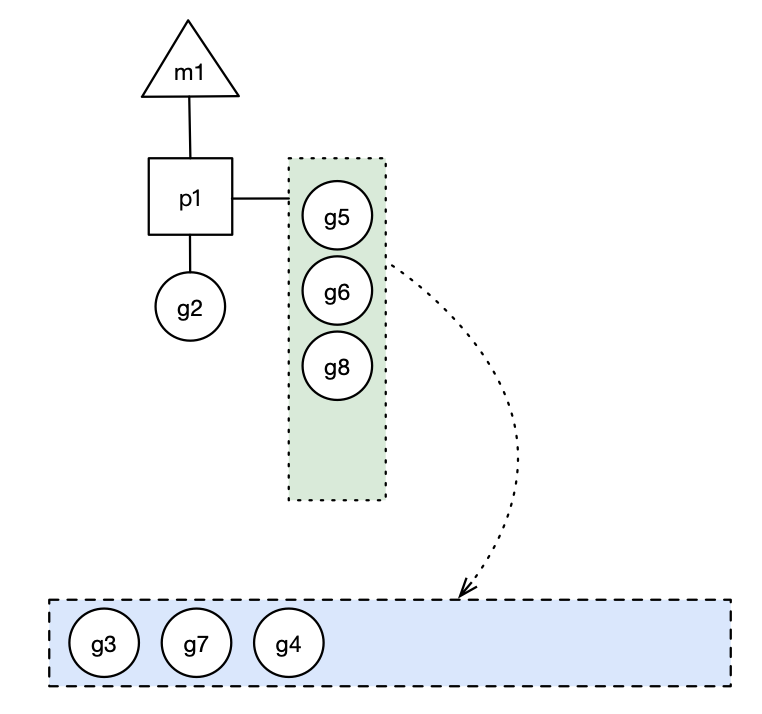
場景四
在創(chuàng)建 g 時,運行的 g 會嘗試喚醒其他空閑的 p 和 m 組合去執(zhí)行。假定 g2 喚醒了 m2,m2 綁定了 p2,并運行 g0,但 p2 本地隊列沒有 g,m2 此時為自旋線程(沒有 G 但為運行狀態(tài)的線程,不斷尋找 g)。
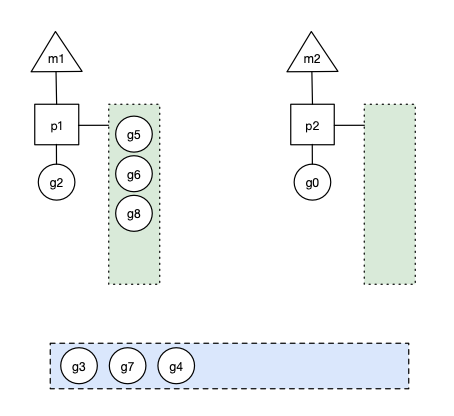
m2 接下來會嘗試從全局隊列 (GQ) 取一批 g 放到 p2 的本地隊列(函數(shù):findrunnable)。m2 從全局隊列取的 g 數(shù)量符合下面的公式:
n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))
公式的含義是,至少從全局隊列取 1 個 g,但每次不要從全局隊列移動太多的 g 到 p 本地隊列,給其他 p 留點。這是從全局隊列到 P 本地隊列的負(fù)載均衡。
假定場景中一共有 4 個 P(GOMAXPROCS=4),所以 m2 只從能從全局隊列取 1 個 g(即 g3)移動 p2 本地隊列,然后完成從 g0 到 g3 的切換,運行 g3:
場景五
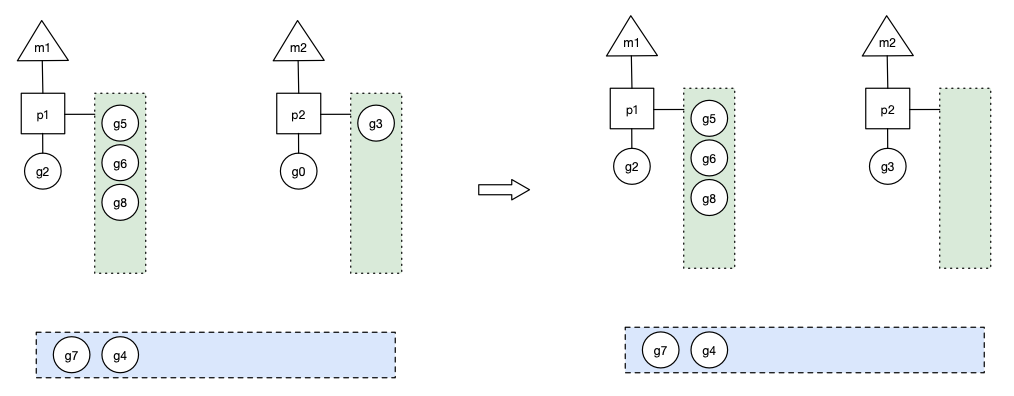
假設(shè) g2 一直在 m1上運行,經(jīng)過 2 輪后,m2 已經(jīng)把 g7、g4 也挪到了p2的本地隊列并完成運行,全局隊列和 p2 的本地隊列都空了,如下圖左邊所示。
全局隊列已經(jīng)沒有 g,那 m 就要執(zhí)行 work stealing:從其他有 g 的 p 哪里偷取一半 g 過來,放到自己的 P 本地隊列。p2 從 p1 的本地隊列尾部取一半的 g,本例中一半則只有 1 個 g8,放到 p2 的本地隊列,情況如下圖右邊:
場景六
p1 本地隊列 g5、g6 已經(jīng)被其他 m 偷走并運行完成,當(dāng)前 m1 和 m2 分別在運行 g2 和 g8,m3 和 m4 沒有g(shù)oroutine 可以運行,m3 和 m4 處于自旋狀態(tài),它們不斷尋找 goroutine。
這里有一個問題,為什么要讓 m3 和 m4 自旋?自旋本質(zhì)是在運行,線程在運行卻沒有執(zhí)行 g,就變成了浪費CPU,銷毀線程可以節(jié)約CPU資源不是更好嗎?實際上,創(chuàng)建和銷毀CPU都是浪費時間的,我們希望當(dāng)有新 goroutine 創(chuàng)建時,立刻能有 m 運行它,如果銷毀再新建就增加了時延,降低了效率。當(dāng)然也考慮了過多的自旋線程是浪費 CPU,所以系統(tǒng)中最多有 GOMAXPROCS 個自旋的線程,多余的沒事做的線程會讓他們休眠(函數(shù):notesleep() 實現(xiàn)了這個思路)。
場景七
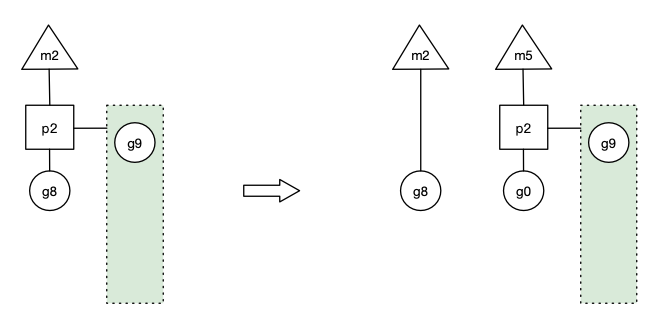
假定當(dāng)前除了 m3 和 m4 為自旋線程,還有 m5 和 m6 為自旋線程,g8 創(chuàng)建了 g9,g9 會放入本地隊列。加入此時g8 進(jìn)行了阻塞的系統(tǒng)調(diào)用,m2 和 p2 立即解綁,p2 會執(zhí)行以下判斷:如果 p2 本地隊列有 g、全局隊列有 g 或有空閑的 m,p2 都會立馬喚醒1個 m 和它綁定,否則 p2 則會加入到空閑 P 列表,等待 m 來獲取可用的 p。本場景中,p2 本地隊列有 g,可以和其他自旋線程 m5 綁定。
場景八
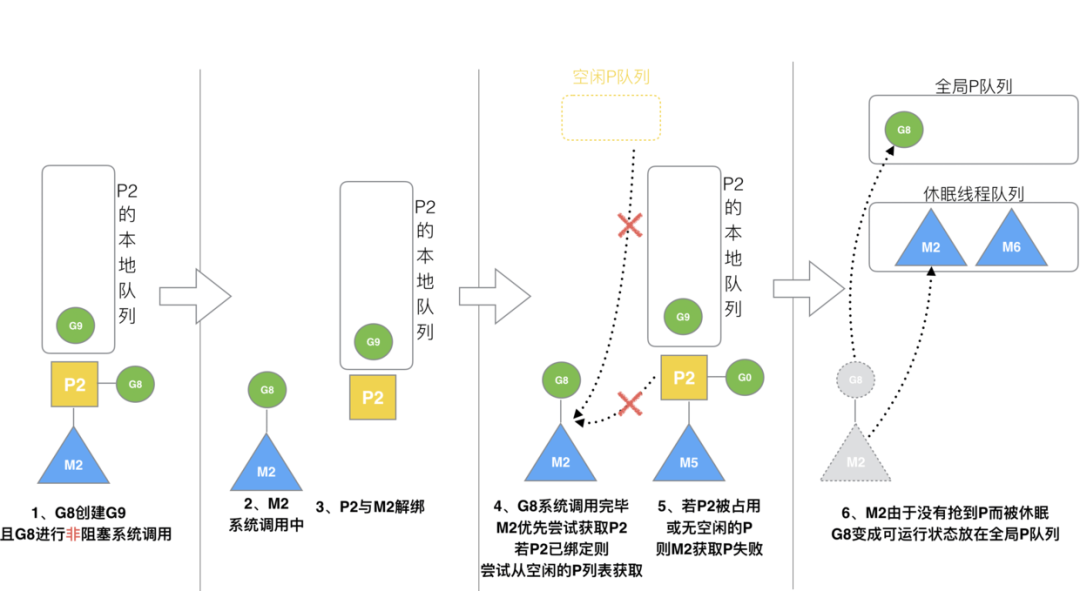
假設(shè) g8 創(chuàng)建了 g9,假如 g8 進(jìn)行了非阻塞系統(tǒng)調(diào)用(CGO會是這種方式,見cgocall()),m2 和 p2 會解綁,但 m2 會記住 p,然后 g8 和 m2 進(jìn)入系統(tǒng)調(diào)用狀態(tài)。當(dāng) g8 和 m2 退出系統(tǒng)調(diào)用時,會嘗試獲取 p2,如果無法獲取,則獲取空閑的 p,如果依然沒有,g8 會被記為可運行狀態(tài),并加入到全局隊列。
場景九
前面說過,Go 調(diào)度在 go1.12 實現(xiàn)了搶占,應(yīng)該更精確的稱為基于協(xié)作的請求式搶占,那是因為 go 調(diào)度器的搶占和 OS 的線程搶占比起來很柔和,不暴力,不會說線程時間片到了,或者更高優(yōu)先級的任務(wù)到了,執(zhí)行搶占調(diào)度。go 的搶占調(diào)度柔和到只給 goroutine 發(fā)送 1 個搶占請求,至于 goroutine 何時停下來,那就管不到了。搶占請求需要滿足2個條件中的1個:
G 進(jìn)行系統(tǒng)調(diào)用超過 20us
G 運行超過 10ms。調(diào)度器在啟動的時候會啟動一個單獨的線程 sysmon,它負(fù)責(zé)所有的監(jiān)控工作,其中 1 項就是搶占,發(fā)現(xiàn)滿足搶占條件的 G 時,就發(fā)出搶占請求。
狀態(tài)匯總
從上面的場景中可以總結(jié)各個模型的狀態(tài):
G狀態(tài)
G的主要幾種狀態(tài):
| 狀態(tài) | 描述 |
|---|---|
| _Gidle | 剛剛被分配并且還沒有被初始化,值為0,為創(chuàng)建goroutine后的默認(rèn)值 |
| _Grunnable | 沒有執(zhí)行代碼,沒有棧的所有權(quán),存儲在運行隊列中,可能在某個P的本地隊列或全局隊列中 |
| _Grunning | 正在執(zhí)行代碼的goroutine,擁有棧的所有權(quán) |
| _Gsyscall | 正在執(zhí)行系統(tǒng)調(diào)用,擁有棧的所有權(quán),沒有執(zhí)行用戶代碼,被賦予了內(nèi)核線程 M 但是不在運行隊列上 |
| _Gwaiting | 由于運行時而被阻塞,沒有執(zhí)行用戶代碼并且不在運行隊列上,但是可能存在于 Channel 的等待隊列上 |
| _Gdead | 當(dāng)前goroutine未被使用,沒有執(zhí)行代碼,可能有分配的棧,分布在空閑列表 gFree,可能是一個剛剛初始化的 goroutine,也可能是執(zhí)行了 goexit 退出的 goroutine |
| _Gcopystack | 棧正在被拷貝,沒有執(zhí)行代碼,不在運行隊列上 |
| _Gpreempted | 由于搶占而被阻塞,沒有執(zhí)行用戶代碼并且不在運行隊列上,等待喚醒 |
| _Gscan | GC 正在掃描棧空間,沒有執(zhí)行代碼,可以與其他狀態(tài)同時存在 |
P 狀態(tài)
| 狀態(tài) | 描述 |
|---|---|
| _Pidle | 處理器沒有運行用戶代碼或者調(diào)度器,被空閑隊列或者改變其狀態(tài)的結(jié)構(gòu)持有,運行隊列為空 |
| _Prunning | 被線程 M 持有,并且正在執(zhí)行用戶代碼或者調(diào)度器 |
| _Psyscall | 沒有執(zhí)行用戶代碼,當(dāng)前線程陷入系統(tǒng)調(diào)用 |
| _Pgcstop | 被線程 M 持有,當(dāng)前處理器由于垃圾回收被停止 |
| _Pdead | 當(dāng)前處理器已經(jīng)不被使用 |
M 狀態(tài)
自旋線程:處于運行狀態(tài)但是沒有可執(zhí)行 goroutine 的線程,數(shù)量最多為 GOMAXPROC,若是數(shù)量大于 GOMAXPROC 就會進(jìn)入休眠。
非自旋線程:處于運行狀態(tài)有可執(zhí)行 goroutine 的線程。
調(diào)度器設(shè)計
從上面的流程可以總結(jié)出 goroutine 調(diào)度器的一些設(shè)計思路:
調(diào)度器設(shè)計的兩大思想
復(fù)用線程:協(xié)程本身就是運行在一組線程之上,所以不需要頻繁的創(chuàng)建、銷毀線程,而是對線程進(jìn)行復(fù)用。在調(diào)度器中復(fù)用線程還有2個體現(xiàn):
work stealing,當(dāng)本線程無可運行的 G 時,嘗試從其他線程綁定的 P 偷取 G,而不是銷毀線程。
hand off,當(dāng)本線程因為 G 進(jìn)行系統(tǒng)調(diào)用阻塞時,線程釋放綁定的 P,把 P 轉(zhuǎn)移給其他空閑的線程執(zhí)行。
利用并行:GOMAXPROCS 設(shè)置 P 的數(shù)量,當(dāng) GOMAXPROCS 大于 1 時,就最多有 GOMAXPROCS 個線程處于運行狀態(tài),這些線程可能分布在多個 CPU 核上同時運行,使得并發(fā)利用并行。另外,GOMAXPROCS 也限制了并發(fā)的程度,比如 GOMAXPROCS = 核數(shù)/2,則最多利用了一半的 CPU 核進(jìn)行并行。
調(diào)度器設(shè)計的兩小策略
搶占:
在 coroutine 中要等待一個協(xié)程主動讓出 CPU 才執(zhí)行下一個協(xié)程,在 Go 中,一個 goroutine 最多占用CPU 10ms,防止其他 goroutine 被餓死,這就是 goroutine 不同于 coroutine 的一個地方。
全局G隊列:
在新的調(diào)度器中依然有全局 G 隊列,但功能已經(jīng)被弱化了,當(dāng) M 執(zhí)行 work stealing 從其他 P 偷不到 G 時,它可以從全局 G 隊列獲取 G。
GPM 可視化調(diào)試
有 2 種方式可以查看一個程序 GPM 的數(shù)據(jù):
go tool trace
trace 記錄了運行時的信息,能提供可視化的Web頁面。
簡單測試代碼:main 函數(shù)創(chuàng)建 trace,trace 會運行在單獨的 goroutine 中,然后 main 打印 “Hello trace” 退出。
func main() {
// 創(chuàng)建trace文件
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
// 啟動trace goroutine
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
// main
fmt.Println("Hello trace")
}
運行程序和運行trace:
$ go run trace.go Hello World
會得到一個 trace.out 文件,然后可以用一個工具打開,來分析這個文件:
$ go tool trace trace.out 2020/12/07 23:09:33 Parsing trace... 2020/12/07 23:09:33 Splitting trace... 2020/12/0723:09:33Openingbrowser.Traceviewerislisteningonhttp://127.0.0.1:56469
接下來通過瀏覽器打開 http://127.0.0.1:33479 網(wǎng)址,點擊 view trace 能夠
看見可視化的調(diào)度流程:

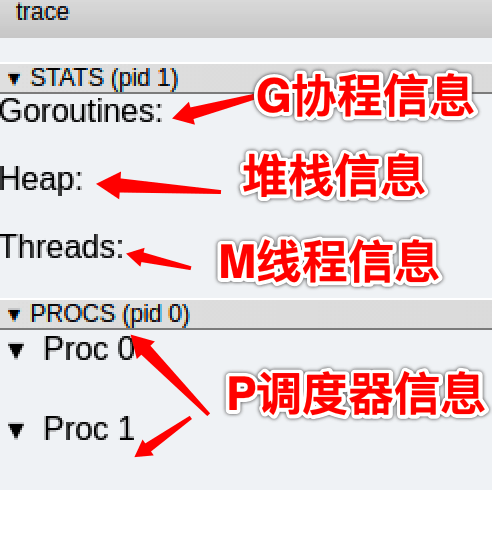
g 信息
點擊 Goroutines 那一行的數(shù)據(jù)條,會看到一些詳細(xì)的信息:
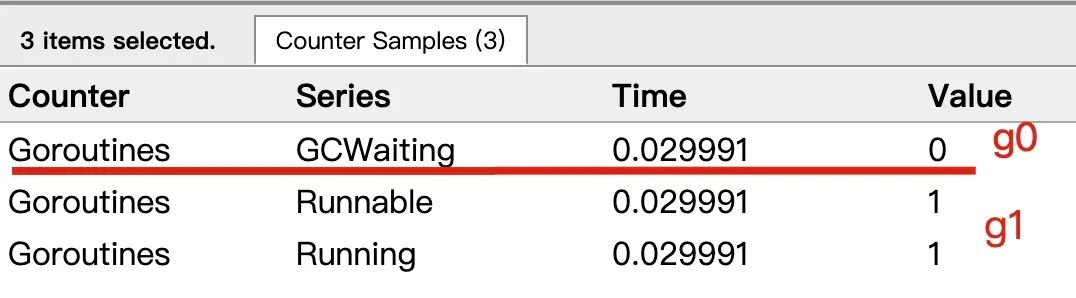
上面表示一共有兩個 G 在程序中,一個是特殊的 G0,是每個 M 必須有的一個初始化的 G。其中 G1 就是 main goroutine (執(zhí)行 main 函數(shù)的協(xié)程),在一段時間內(nèi)處于可運行和運行的狀態(tài)。
m 信息
點擊 Threads 那一行可視化的數(shù)據(jù)條,會看到一些詳細(xì)的信息:
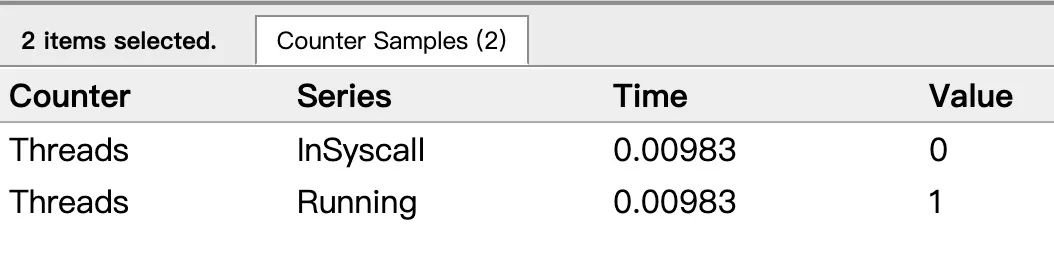
這里一共有兩個 M 在程序中,一個是特殊的 M0,用于初始化使用。
p 信息

G1 中調(diào)用了 main.main,創(chuàng)建了 trace goroutine g6。G1 運行在 P0 上,G6運行在 P1 上。
這里有三個 P。
在看看上面的 M 信息:

可以看到確實 G6 在 P1 上被運行之前,確實在 Threads 行多了一個 M 的數(shù)據(jù),點擊查看如下:
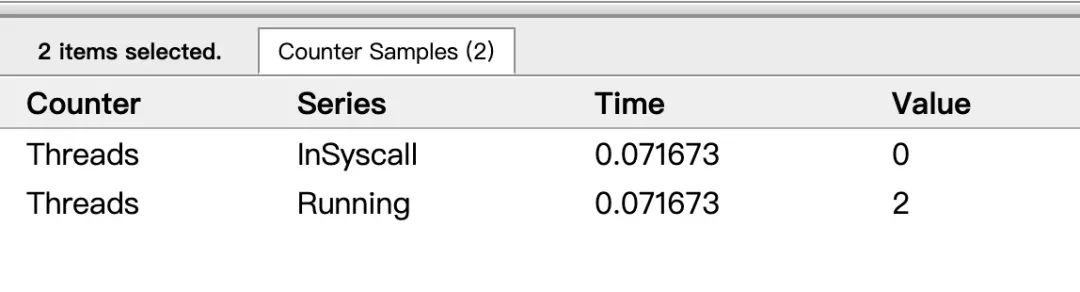
多了一個 M2 應(yīng)該就是 P1 為了執(zhí)行 G6 而動態(tài)創(chuàng)建的 M2。
Debug trace
示例代碼:
// main.main
func main() {
for i := 0; i < 5; i++ {
time.Sleep(time.Second)
fmt.Println("Hello scheduler")
}
}
編譯后通過 Debug 方式運行,運行過程會打印trace:
? go build . ? GODEBUG=schedtrace=1000 ./one_routine2
結(jié)果:
SCHED 0ms: gomaxprocs=4 idleprocs=2 threads=3 spinningthreads=1 idlethreads=0 runqueue=0 [1 0 0 0] Hello scheduler SCHED 1003ms: gomaxprocs=4 idleprocs=4 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0] Hello scheduler SCHED 2007ms: gomaxprocs=4 idleprocs=4 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0] Hello scheduler SCHED 3010ms: gomaxprocs=4 idleprocs=4 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0] Hello scheduler SCHED 4013ms: gomaxprocs=4 idleprocs=4 threads=5 spinningthreads=0 idlethreads=3 runqueue=0 [0 0 0 0] Hello scheduler
各個字段的含義如下:
SCHED:調(diào)試信息輸出標(biāo)志字符串,代表本行是 goroutine 調(diào)度器的輸出;
0ms:即從程序啟動到輸出這行日志的時間;
gomaxprocs: P的數(shù)量,本例有 4 個P;
idleprocs: 處于 idle (空閑)狀態(tài)的 P 的數(shù)量;通過 gomaxprocs 和 idleprocs 的差值,就可以知道執(zhí)行 go 代碼的 P 的數(shù)量;
threads: os threads/M 的數(shù)量,包含 scheduler 使用的 m 數(shù)量,加上 runtime 自用的類似 sysmon 這樣的 thread 的數(shù)量;
spinningthreads: 處于自旋狀態(tài)的 os thread 數(shù)量;
idlethread: 處于 idle 狀態(tài)的 os thread 的數(shù)量;
runqueue=0:Scheduler 全局隊列中 G 的數(shù)量;[0 0 0 0]: 分別為 4 個 P 的 local queue 中的 G 的數(shù)量。
看第一行,含義是:剛啟動時創(chuàng)建了 4 個P,其中 2 個空閑的 P,共創(chuàng)建 3 個M,其中 1 個 M 處于自旋,沒有 M 處于空閑,第一個 P 的本地隊列有一個 G。
另外,可以加上 scheddetail=1 可以打印更詳細(xì)的 trace 信息。
命令:
? GODEBUG=schedtrace=1000,scheddetail=1 ./one_routine2
審核編輯:湯梓紅
-
Linux
+關(guān)注
關(guān)注
87文章
11511瀏覽量
213864 -
調(diào)度器
+關(guān)注
關(guān)注
0文章
98瀏覽量
5505
原文標(biāo)題:goroutine 調(diào)度器原理
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
中斷、切換、調(diào)度等概念關(guān)系不太明白
多頻超寬頻天線場景應(yīng)用
【HarmonyOS】鴻蒙內(nèi)核源碼分析(調(diào)度機制篇)
鴻蒙內(nèi)核源碼分析(調(diào)度機制篇):Task是如何被調(diào)度執(zhí)行的
Linux2.4和Linux2.6的調(diào)度器對比分析,Linux2.6對調(diào)度器的改進(jìn)有哪些方面?
編譯器優(yōu)化的靜態(tài)調(diào)度介紹
VxWorks實時內(nèi)核調(diào)度的研究分析
Vx Works實時內(nèi)核調(diào)度的研究分析
VxWorks實時內(nèi)核調(diào)度的研究分析
CAN調(diào)度理論與實踐分析
uClinux進(jìn)程調(diào)度器的實現(xiàn)分析
基于PLSA模型的群體情緒演進(jìn)分析
基于形式概念分析的圖像場景語義標(biāo)注模型
Linux進(jìn)程調(diào)度時機概念分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論