") 多目標跟蹤在計算機視覺中的重要性
多目標跟蹤在計算機視覺中的重要性
摘要
隨著自動駕駛技術(shù)的發(fā)展,多目標跟蹤已成為計算機視覺領(lǐng)域研究的熱點問題之一。MOT 是一項關(guān)鍵的視覺任務(wù),可以解決不同的問題,例如擁擠場景中的遮擋、相似外觀、小目標檢測困難、ID切換等。為了應(yīng)對這些挑戰(zhàn),研究人員嘗試利用transformer的注意力機制、利用圖卷積神經(jīng)網(wǎng)絡(luò)獲得軌跡的相關(guān)性、不同幀中目標與siamese網(wǎng)絡(luò)的外觀相似性,還嘗試了基于簡單 IOU 匹配的 CNN 網(wǎng)絡(luò)、運動預(yù)測的 LSTM。
為了把這些分散的技術(shù)綜合起來,作者研究了過去三年中的一百多篇論文,試圖提取出近年來研究者們更加關(guān)注的解決 MOT 問題的技術(shù)。作者羅列了大量的應(yīng)用以及可能的方向,還有MOT如何與現(xiàn)實生活聯(lián)系起來。作者的綜述試圖展示研究人員長期使用的技術(shù)的不同觀點,并為潛在研究人員提供一些未來方向。此外,作者在這篇綜述中還包括了流行的基準數(shù)據(jù)集和指標。
簡介
目標跟蹤是計算機視覺中非常重要的任務(wù)之一。它剛好在目標檢測之后出現(xiàn)。為了完成目標跟蹤任務(wù),首先需要將目標定位在一幀中。然后給每個目標分配一個單獨的唯一id。然后連續(xù)幀中的每個相同目標將生成軌跡。在這里,一個目標可以是任何類別,比如行人、車輛、運動中的運動員、天空中的鳥等。
如果作者想在一幀中跟蹤多個目標,那么它被稱為多目標跟蹤或MOT。 過去幾年也有一些關(guān)于MOT的綜述論文[1]、[2]、[3]、[4]。但它們都有局限性。其中一些方法只包括基于深度學(xué)習(xí)的方法,只關(guān)注數(shù)據(jù)關(guān)聯(lián),只分析問題,沒有很好地對論文進行分類,并且缺少現(xiàn)實中應(yīng)用的介紹。 因此,綜上所述,作者以以下方式組織了本工作:
找出MOT的主要挑戰(zhàn)
列出常用的各種MOT方法
MOT基準數(shù)據(jù)集簡介
MOT指標摘要
探索各種應(yīng)用場景
MOT的主要挑戰(zhàn)
遮擋
當(dāng)想要看到的目標被同一幀中的另一個目標完全或部分隱藏或遮擋時,就會發(fā)生遮擋問題。大多數(shù)MOT方法僅基于沒有傳感器數(shù)據(jù)的相機。這就是為什么當(dāng)目標相互遮擋時,跟蹤器要跟蹤目標的位置有點困難的原因。此外,在擁擠的場景中,為了建模人與人之間的交互,遮擋變得更加嚴重。
隨著時間的推移,使用邊界框定位目標在MOT社區(qū)中非常流行。但在擁擠的場景中,遮擋很難處理,因為groundtruth邊界框通常相互重疊。通過聯(lián)合處理目標跟蹤和分割任務(wù),可以部分解決這個問題。在文獻中,作者可以看到外觀信息和圖形信息用于查找全局屬性以解決遮擋問題。
然而,頻繁的遮擋對MOT問題中較低的精度有顯著影響。因此,研究人員試圖在沒有任何提示的情況下解決這個問題。在下圖a中,對遮擋進行了說明。在下圖b中,紅衣女子幾乎被燈柱遮蓋。這是遮擋的一個示例。
輕量化架構(gòu)
盡管大多數(shù)問題的最新解決方案是依賴于重量級架構(gòu),但它們非常吃資源。因此在 MOT 中,重量級架構(gòu)對于實時目標跟蹤非常不利。因此,研究人員一直很重視輕量級體系結(jié)構(gòu)。對于 MOT 中的輕量級結(jié)構(gòu),還有一些額外的挑戰(zhàn)需要考慮。
Bin 等人提到了輕量級體系結(jié)構(gòu)面臨的三個挑戰(zhàn),比如: 目標跟蹤體系結(jié)構(gòu)需要預(yù)訓(xùn)練權(quán)重來實現(xiàn)良好的初始化,并對跟蹤數(shù)據(jù)進行微調(diào)。因為 NAS 算法需要來自目標任務(wù)的指導(dǎo),同時還需要可靠的初始化。NAS 算法需要同時關(guān)注骨干網(wǎng)絡(luò)和特征提取,以便最終的結(jié)構(gòu)能夠完全適合目標跟蹤任務(wù)。最終架構(gòu)需要編譯緊湊和低延遲的構(gòu)建模塊。
其它常見挑戰(zhàn)
MOT體系結(jié)構(gòu)經(jīng)常受到不準確的目標檢測的影響。如果沒有正確檢測到目標,那么跟蹤目標的所有努力都將白費。有時,目標檢測的速度成為MOT體系結(jié)構(gòu)的一個主要因素。對于背景失真,目標檢測有時變得非常困難。照度在目標檢測和識別中也起著至關(guān)重要的作用。
因此,所有這些因素在目標跟蹤中變得更加重要。由于相機或目標的運動,運動模糊使MOT更具挑戰(zhàn)性。很多時候,MOT體系結(jié)構(gòu)發(fā)現(xiàn)很難確定一個目標是否為真正的輸入目標。挑戰(zhàn)之一是檢測和tracklet之間的正確關(guān)聯(lián)。在許多情況下,不正確和不精確的目標檢測也是精度低的結(jié)果。
還有一些挑戰(zhàn),例如相似的外觀經(jīng)常混淆模型,軌跡的開始和終止在MOT中是一個關(guān)鍵的任務(wù),多個目標之間的交互,ID切換(同一目標在連續(xù)幀中識別為不同)。由于形狀和其他外觀特性的非剛性變形和類間相似性,在許多情況下,人和車輛會帶來一些額外的挑戰(zhàn)。
例如,車輛的形狀和顏色與人們的衣服不同。最后,較小尺寸的目標可以形成各種不同的視覺元素。Liting等人嘗試用更高分辨率的圖像和更高的計算復(fù)雜度來解決這個問題。他們還將分層特征圖與傳統(tǒng)的多尺度預(yù)測技術(shù)相結(jié)合。
MOT方法
多目標跟蹤任務(wù)通常分為兩個步驟:目標檢測和目標關(guān)聯(lián)。有些側(cè)重于目標檢測,有些關(guān)注數(shù)據(jù)關(guān)聯(lián)。這兩個步驟有多種方法。無論是檢測階段還是關(guān)聯(lián)階段,這些方法都不是完全獨立的。 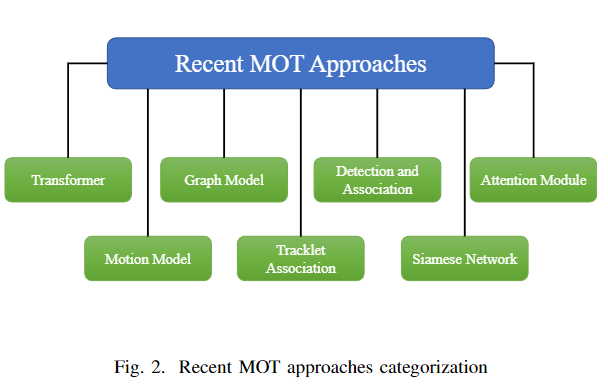
Transformer
Transformer是一個深度學(xué)習(xí)模型,與其他模型一樣,它有兩個部分:編碼器和解碼器[16]。編碼器捕獲自注意力,而解碼器捕獲交叉注意力。這種注意機制有助于長期記憶上下文。基于查詢鍵方式,使用轉(zhuǎn)換器預(yù)測輸出。
盡管過去它僅僅被用作一種語言模型,但近年來,視覺研究人員將重點放在了它上,以利用語境記憶。在大多數(shù)情況下,在MOT中,研究人員試圖根據(jù)之前的信息預(yù)測目標下一幀的位置,作者認為transformer是最好的方案。由于transformer專門處理序列信息,所以transformer可以完美地完成逐幀處理。下圖是一個Transformer的跟蹤例子。 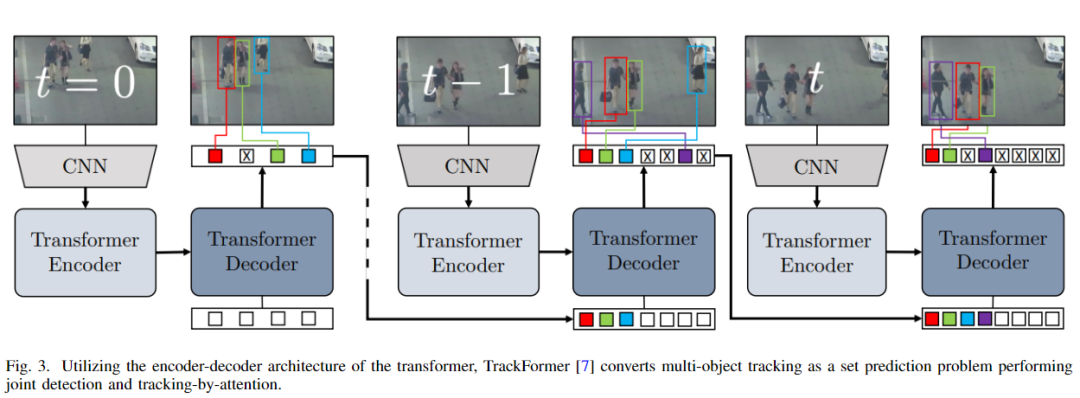
下表給出了MOT中基于transformer的方法的完整總結(jié)。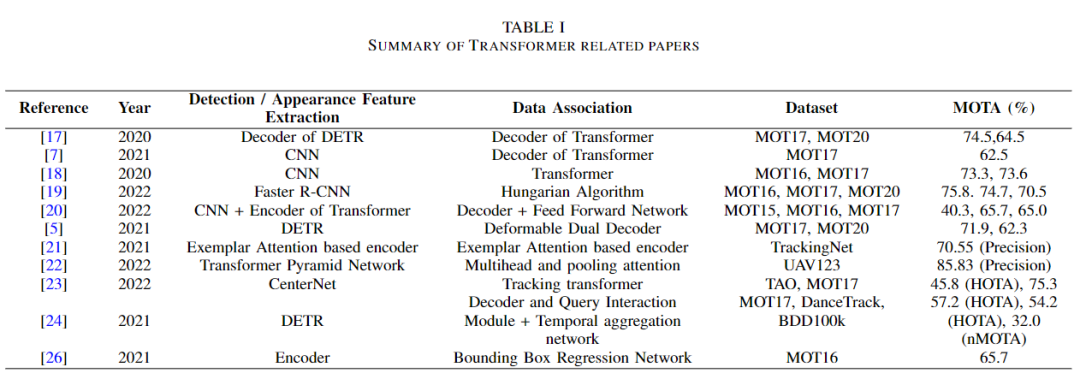
圖模型
圖卷積網(wǎng)絡(luò)(GCN)是一種特殊的卷積網(wǎng)絡(luò),其中神經(jīng)網(wǎng)絡(luò)以圖形的形式而不是線性的形式應(yīng)用。此外,最近的趨勢是使用圖模型來解決 MOT 問題,其中從連續(xù)幀中檢測到的一組目標被視為一個節(jié)點,兩個節(jié)點之間的鏈接被視為一個邊緣。通常情況下,數(shù)據(jù)關(guān)聯(lián)是通過應(yīng)用匈牙利算法來完成的[28]。下圖為基于GCN的目標跟蹤示例。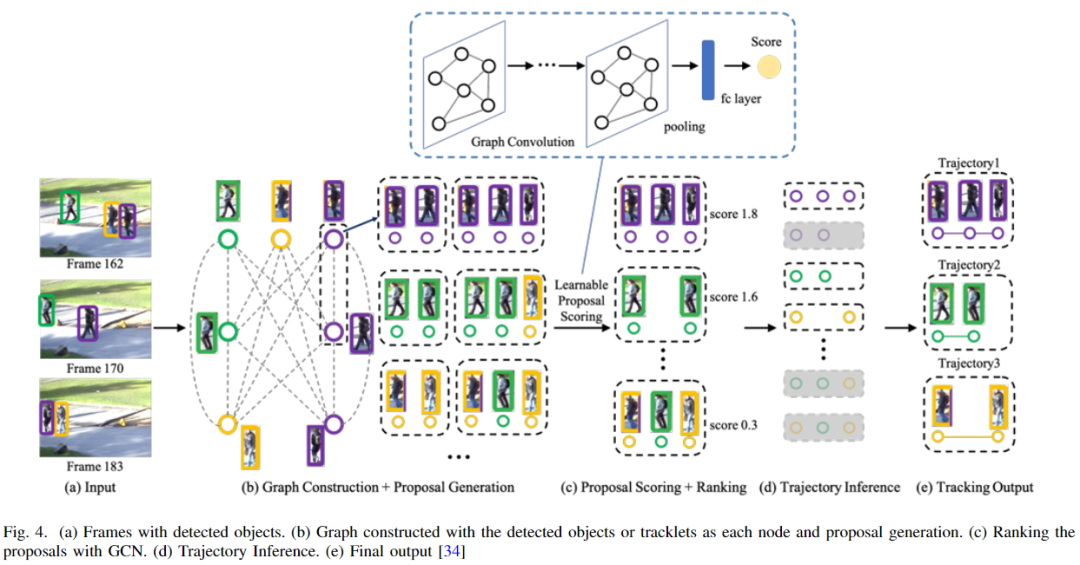
下表給出了用圖模型解決 MOT 問題的概述。
檢測和目標關(guān)聯(lián)
在這種方法中,檢測是通過任何深度學(xué)習(xí)模型來完成的。但主要的挑戰(zhàn)是關(guān)聯(lián)目標,即跟蹤感興趣的目標的軌跡[37]。在這方面,不同的論文遵循不同的方法。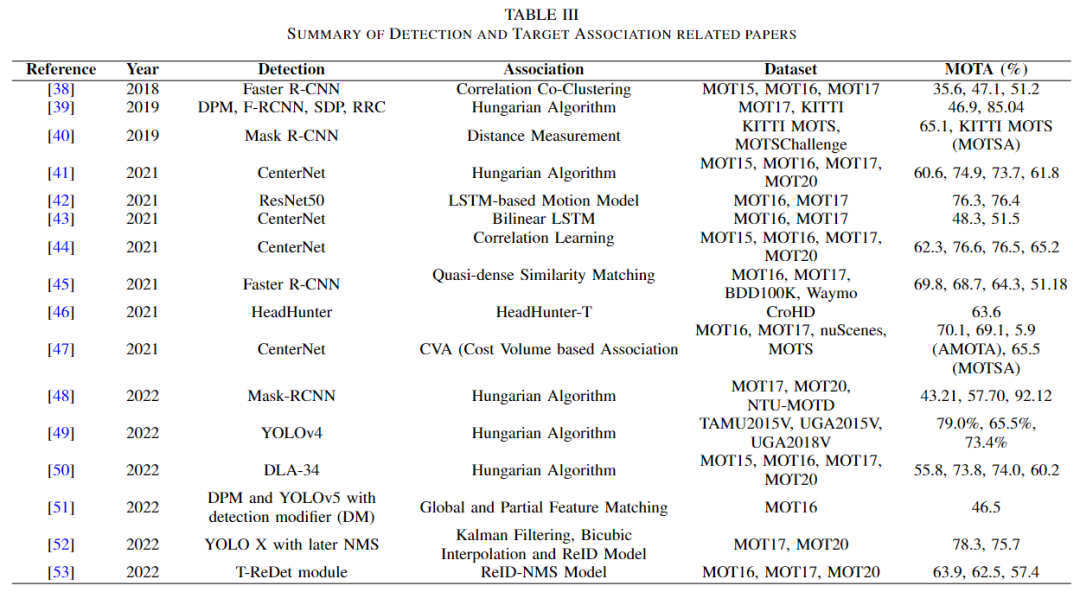
如上表所示,主要介紹部分方案。Margret 等人選擇了自下而上的方法和自上而下的方法。在自底向上的方法,點軌跡確定。但是在自頂向下的方法中,確定了邊界框。然后,通過結(jié)合這兩個,一個完整的軌跡的目標可以找到。在[3中,為了解決關(guān)聯(lián)問題,Hasith 等人簡單地檢測了目標,并使用著名的匈牙利算法來關(guān)聯(lián)信息。
2019年,Paul 等人提出了 Track-RCNN [40] ,這是 R-CNN 的一個延伸,顯然是 MOT 領(lǐng)域的一個革命性任務(wù)。到2022年,作者可以看到 MOT 問題陳述的多樣性。Oluaffunmilola 等人在進行目標預(yù)測的同時也進行了目標跟蹤[50]。他們使用 FairMOT 檢測了邊界框,然后堆疊了一個預(yù)測網(wǎng)絡(luò),并制作了聯(lián)合學(xué)習(xí)架構(gòu)(JLE)。
智洪等人提取了每個幀的新特征,以獲得全局信息,并積累了部分特征用于遮擋處理[51]。他們?nèi)诤狭诉@兩種特征來準確地檢測行人。除了[52]之外,沒有論文采取任何措施來保留重要的邊界框,以便在數(shù)據(jù)關(guān)聯(lián)階段不會消除它們。在檢測之后,Hong 等人在跟蹤階段應(yīng)用Non-Maskable Suppression(NMS)來減少重要邊界框被移除的概率[53]。Jian 等人還使用 NMS 來減少來自檢測器的冗余邊界框。它們通過比較特征和借助 IoU 重新識別邊界框來重新檢測軌跡定位。最終的結(jié)果是一個聯(lián)合再檢測和再識別跟蹤器(JDI)。
注意力模塊
為了重新識別被遮擋的目標,需要注意力。注意力意味著作者只考慮感興趣的目標,通過消除背景,使其特征被記住很長時間,甚至在遮擋之后也能如此。注意力模塊在 MOT 領(lǐng)域的應(yīng)用概述見下表。 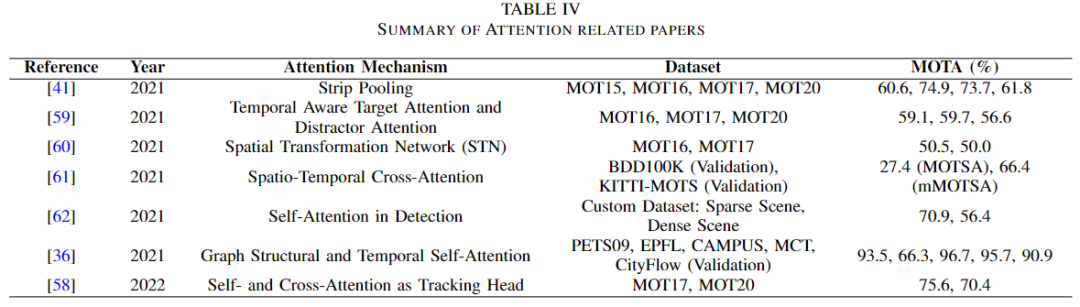
在[41]中,姚野等人引入了一個條形注意模塊來重新識別被背景遮擋的行人。這個模塊實際上是一個池化層,其中包括 max 和 mean 池化,它能夠更有效地從行人中提取特征,這樣當(dāng)它們被遮擋時,模型不會忘記它們,并能夠進一步重新識別。宋等人希望在數(shù)據(jù)關(guān)聯(lián)中使用目標定位的信息,在目標定位中使用數(shù)據(jù)關(guān)聯(lián)的信息。
為了將兩者聯(lián)系起來,他們使用了兩個注意力模塊,一個用于目標,另一個用于分散注意力。然后他們最終應(yīng)用了一個記憶聚合來制造增強的注意力。天一等人提出了空間注意機制[60] ,通過在外觀模型中實現(xiàn)空間轉(zhuǎn)換網(wǎng)絡(luò)(STN)來迫使模型只關(guān)注前景。另一方面,雷等人首先提出了原型交叉注意模塊(PCAM)從過去的幀中提取相關(guān)特征。
然后他們使用原型交叉注意網(wǎng)絡(luò)(PCAN)在整個幀中傳輸前景和背景的對比特征[61]。匯源等人提出了自注意機制來檢測車輛[62]。本文[36]還有一個應(yīng)用于動態(tài)圖中的自注意力模塊,用于組合攝像機的內(nèi)部和外部信息。賈旭等人以一種輕量級的方式使用了交叉注意力和自注意力[58]。如下圖所示,大家可以看到該體系結(jié)構(gòu)的交叉注意力頭。利用自注意模塊提取魯棒特征,減少背景遮擋。然后將數(shù)據(jù)傳遞給交叉注意模塊進行實例關(guān)聯(lián)。 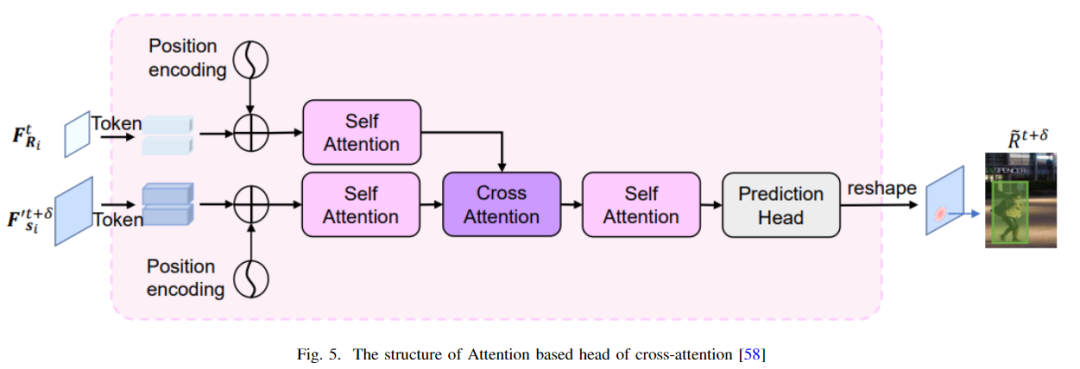
運動模型
運動是目標的必然屬性。因此,該特征可以用于多目標跟蹤領(lǐng)域,無論是檢測還是關(guān)聯(lián)。目標的運動可以通過目標在兩幀之間的位置差來計算。根據(jù)這個衡量標準,可以做出不同的決定,如下表所示。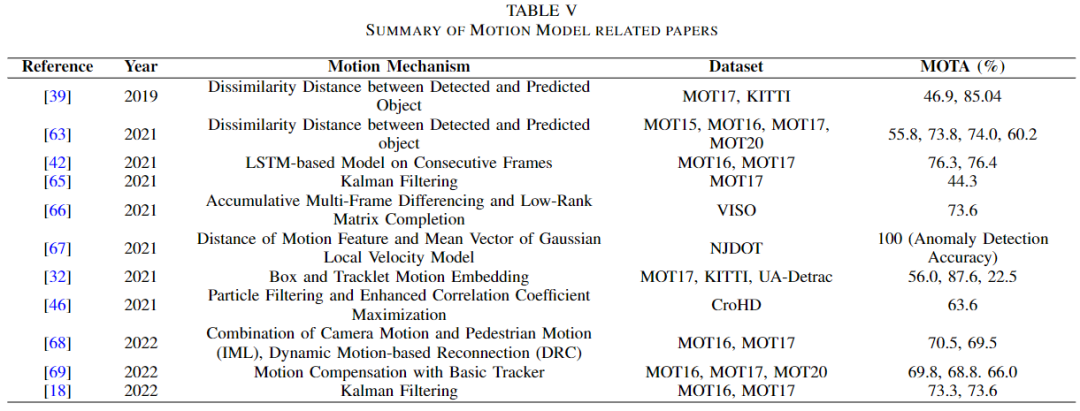
Hasith 等人和 Oluaffunmilola 等人分別在[39]和[63]中使用運動來計算差異代價。根據(jù)實際位置與預(yù)測位置的差值計算運動。為了預(yù)測被遮擋目標的位置,Bisheng 等人使用了基于 LSTM 的運動模型[42]。Wenyuan 等人將運動模型與深度親和網(wǎng)絡(luò)(DAN)相結(jié)合[64] ,通過消除目標不可能位于的位置來優(yōu)化數(shù)據(jù)關(guān)聯(lián)[65]。
倩等人還通過累積多幀差分(AMFD)和低秩矩陣完成(LRMC)測量連續(xù)衛(wèi)星幀的距離來計算運動[66] ,并形成了運動模型基線(MMB)來檢測和減少虛警的數(shù)量。韓等人在車輛駕駛領(lǐng)域使用運動特征識別前景目標[67]。他們通過比較運動特征和 GLV 模型來檢測相關(guān)目標。
Gaoang 等人提出了一種局部-全局運動(LGM)跟蹤器,它可以找出運動的一致性,從而將軌跡關(guān)聯(lián)起來[32]。除此之外,Ramana 等人還使用運動模型來預(yù)測目標的運動,而不是數(shù)據(jù)關(guān)聯(lián),這些數(shù)據(jù)關(guān)聯(lián)有三個模塊: 綜合運動定位(IML) ,動態(tài)重連上下文(DRC) ,3D 積分圖像(3DII)[46]。
在2022年,Shoudong 等人通過提出運動感知跟蹤器(MAT) ,將運動模型用于運動預(yù)測和目標關(guān)聯(lián)。智博等人提出了補償跟蹤器(CT) ,它可以獲得具有運動補償模塊的丟失目標[69]。Xiaotong 等使用運動模型來預(yù)測目標的邊界框[18] ,就像在[67]中所做的那樣,但是如Transformer章節(jié)中所討論的那樣制作圖像patches。
Siamese Network
兩幀之間的相似性信息對目標跟蹤有很大的幫助。因此,Siamese網(wǎng)絡(luò)試圖學(xué)習(xí)相似之處,并區(qū)分輸入。該網(wǎng)絡(luò)由兩個并行子網(wǎng)絡(luò)共享相同的權(quán)值和參數(shù)空間。最后將雙子網(wǎng)絡(luò)之間的參數(shù)綁定在一定的損失函數(shù)上進行訓(xùn)練,以度量雙子網(wǎng)絡(luò)之間的語義相似度。下表給出了Siamese網(wǎng)絡(luò)在MOT任務(wù)中的應(yīng)用概況。 
戴濤等人提出了一個金字塔網(wǎng)絡(luò),嵌入了一個輕量級的transformer注意力層。他們提出的Siamese transformer金字塔網(wǎng)絡(luò)增強了橫向交叉注意力金字塔特征之間的目標特征。因此,它產(chǎn)生了健壯的特定于目標的外觀表示[22]。如下圖所示: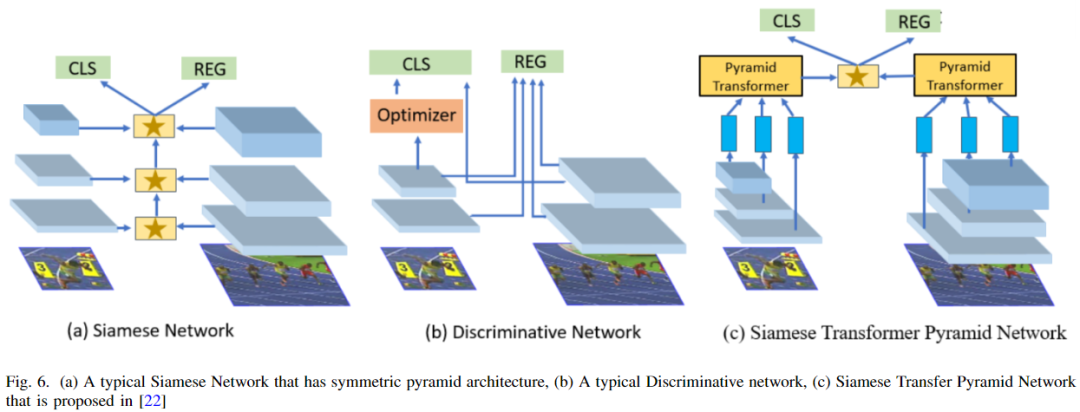
Bing 等人試圖通過結(jié)合運動建模來提升基于區(qū)域的多目標跟蹤網(wǎng)絡(luò)[70]。他們將Siamese網(wǎng)絡(luò)跟蹤框架嵌入到較快的RCNN中,通過輕量級跟蹤和共享網(wǎng)絡(luò)參數(shù)來實現(xiàn)快速跟蹤。Cong 等人提出了一種使用Siamese雙向GRU(SiaBiGRU)對軌跡進行后處理以消除軌跡損壞的切割網(wǎng)絡(luò)。
然后他們建立了重新連接網(wǎng)絡(luò)來連接這些軌跡并制造軌跡[31]。在典型的MOT網(wǎng)絡(luò)中,有預(yù)測和檢測模塊。所述預(yù)測模塊試圖預(yù)測下一幀中目標的外觀,所述檢測模塊檢測所述目標。這兩個模塊的結(jié)果用于特征匹配和目標軌跡更新。新文等人提出了Siamese RPN(區(qū)域提案網(wǎng)絡(luò))結(jié)構(gòu)作為預(yù)測因子。
他們還提出了一種數(shù)據(jù)關(guān)聯(lián)模塊的自適應(yīng)閾值確定方法[71]。因此,Siamese網(wǎng)絡(luò)的整體穩(wěn)定性得到了改善。與transformer模型相反,賈旭等人提出了一種基于注意力的在Siamese網(wǎng)絡(luò)的結(jié)構(gòu)下的輕量級跟蹤頭,增強了前景目標在目標框內(nèi)的定位[58]。另一方面,Philippe 等人已經(jīng)將他們的有效transformer層合并到Siamese跟蹤網(wǎng)絡(luò)中,他們用transformer層取代了卷積層[21]。
Tracklet Association
感興趣目標的一組連續(xù)幀稱為tracklet。在檢測和跟蹤目標時,首先使用不同的算法對軌跡進行識別。然后把它們聯(lián)系在一起,建立一個軌跡。軌跡關(guān)聯(lián)顯然是一個具有挑戰(zhàn)性的任務(wù)在 MOT 問題。一些論文特別關(guān)注這個問題。不同的論文采取了不同的方法。如下表所示。 
金龍等人提出了軌跡平面匹配(TPM)[72] ,其中首先從被檢測的目標創(chuàng)建短軌跡,并且它們在軌跡平面中對齊,其中每個軌跡根據(jù)其開始和結(jié)束時間分配超平面。這樣就形成了巨大的軌跡。這個過程還可以處理非相鄰和重疊的tracklet。為了改善這種情況,他們還提出了兩個方案。
Duy 等人首先用3D幾何算法制作了tracklet[73]。他們已經(jīng)形成了多個攝像機的軌跡,由于這一點,他們通過制定空間和時間信息優(yōu)化了全局關(guān)聯(lián)。在[31]中,Cong等人提出了位置投影網(wǎng)絡(luò)(PPN)來實現(xiàn)從局部環(huán)境到全局環(huán)境的軌跡轉(zhuǎn)換。
Daniel等人通過根據(jù)運動將新來的目標分配給先前發(fā)現(xiàn)的被遮擋的目標來重新識別被遮擋的目標。然后他們實現(xiàn)了已經(jīng)發(fā)現(xiàn)的進一步回歸軌跡,使用by-regression approach。此外,他們還通過提取時間方向來擴展工作,以提高性能。 在[75]中,可以看到與前者不同的策略。
將每個軌跡作為一個中心向量,建立了軌跡中心存儲庫(TMB) ,并對其進行動態(tài)更新和成本計算。整個過程稱為多視點軌跡對比學(xué)習(xí)(MTCL)。此外,他們還創(chuàng)建了可學(xué)習(xí)的視圖采樣(LVS) ,它將每個檢測作為關(guān)鍵點,幫助在全局上下文中查看軌跡。
他們還提出了相似引導(dǎo)特征融合(SGFF)方法來避免模糊特征。et,al等人已經(jīng)開發(fā)了軌跡助推器(TBooster)[76]來減輕關(guān)聯(lián)過程中發(fā)生的錯誤。TBooster有兩個組件: 拆分器和連接器。在第一個模塊中,在ID切換發(fā)生的地方拆分tracklet。因此,可以解決為多個目標分配相同ID的問題。在第二個模塊中,將同一目標的tracklet鏈接起來。通過這樣做,可以避免將相同的ID分配給多個tracklet。Tracklet嵌入可以通過連接器完成。
MOT Benchmarks
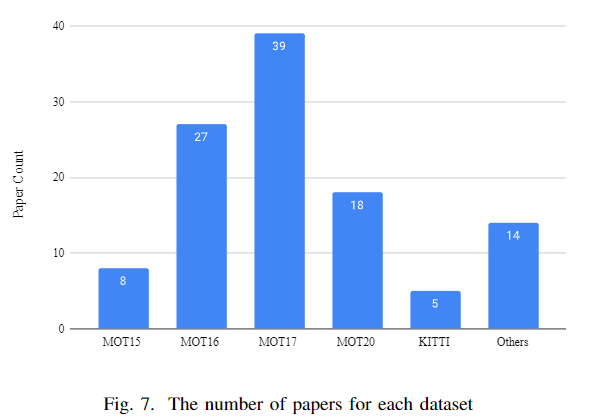
典型的 MOT 數(shù)據(jù)集包含視頻序列。在這些序列中,每個目標都由一個唯一的 id 標識,直到它不再出現(xiàn)。一旦一個新目標進入幀,它就會得到一個新的唯一標識。MOT 有很多基準。其中,MOT 挑戰(zhàn)基準有多個版本。自2015年以來,他們幾乎每年都會發(fā)布一個變化更多的新基準。
還有一些流行的基準,如 PETS、 KITTI、 STEPS 和 DanceTrack。到目前為止,MOT 挑戰(zhàn)有17個目標跟蹤數(shù)據(jù)集,其中包括 MOT15[81] ,MOT16[82] ,MOT20,[6]和其他。MOt15基準包含威尼斯,KITTI,ADL-Rundle,eTH-Pescross,eTH-Sunnyday,PET,TUd-cross 數(shù)據(jù)集。
這個基準是在一個不受約束的環(huán)境中拍攝的,有靜態(tài)攝像機和運動攝像機。MOT16和 MOT17基本上是從 MOT15更新的基準,具有較高的groundtruth精度和嚴格遵循的協(xié)議。MOT20是一個行人探測挑戰(zhàn)賽。這個基準有8個具有挑戰(zhàn)性的視頻序列(4列火車,4測試)在無約束的環(huán)境[6]。
除了目標跟蹤,MOTS 數(shù)據(jù)集也有分割任務(wù)[40]。一般來說,跟蹤數(shù)據(jù)集有一個邊界框,框中的目標有一個唯一標識符。 TAO [83]數(shù)據(jù)集有一個巨大的規(guī)模,由于跟蹤每一個目標在一幀內(nèi)。有一個叫Head Tracking 21的數(shù)據(jù)集。這個基準的任務(wù)是跟蹤每個行人的頭部。STEP 數(shù)據(jù)集對每個像素進行了分割和跟蹤。
還有一些其他的數(shù)據(jù)集。下圖顯示了作者審閱的論文中使用的數(shù)據(jù)集的頻率。從圖表中可以看出,MOT17數(shù)據(jù)集的使用頻率高于其他數(shù)據(jù)集。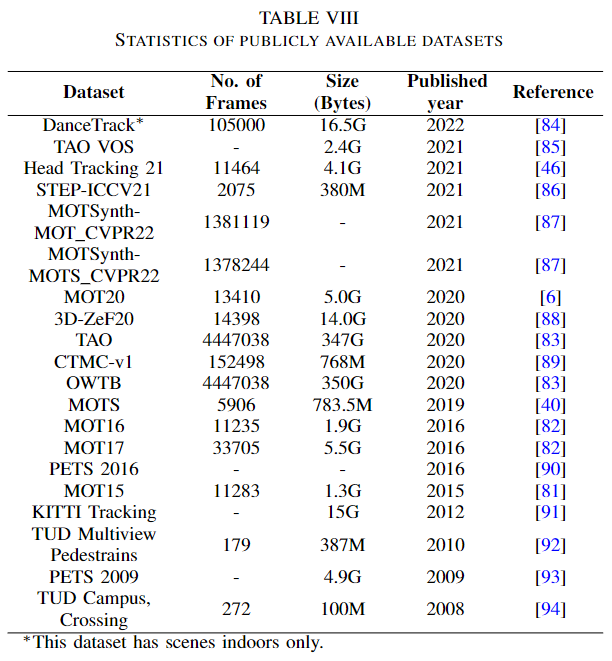
MOT 指標
MOTP
多目標跟蹤精度(MOTP)。無論跟蹤器是否有能力識別目標形狀和保持一致的軌跡,它都是根據(jù)跟蹤器在尋找目標位置時的精確程度給出的分數(shù)。由于 MOTP 只能提供定位精度,因此經(jīng)常與 MOTA (Multiple Object Tracking Accuracy)結(jié)合使用,因為 MOTA 不能單獨說明定位誤差。定位(Localization)是 MOT 任務(wù)的輸出之一。它讓大家知道目標在本幀中的位置。單憑它不能提供一個完整的跟蹤器的性能。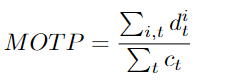
Dit: 在時間t時刻,實際目標與其各自假設(shè)之間的距離,在一個單幀內(nèi),對于集合中的每個目標Oi,跟蹤器分配一個假設(shè)hi。Ct: 在t時刻目標和假設(shè)之間匹配的數(shù)量。
MOTA
多目標跟蹤準確度。這個度量衡量跟蹤器在不考慮精度的情況下檢測目標和預(yù)測軌跡的能力。這個度量標準考慮了三種類型的誤差: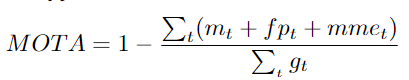
Mt: 在t時刻丟失的數(shù)量;fpt誤檢數(shù)量;mmet: ID切換的數(shù)量 gt: 在t時刻出現(xiàn)的真實目標的數(shù)量。 MOTA過分強調(diào)精確檢測的效果。它側(cè)重于檢測級別的預(yù)測和真值之間的匹配,并沒有考慮關(guān)聯(lián)。當(dāng)考慮沒有ID切換的MOTA,度量會更偏向于被較差的精度影響。
上述的局限性可能會導(dǎo)致研究人員調(diào)整他們的跟蹤器,使其在檢測水平上更具精度和準確性,同時忽略了跟蹤的其他重要方面。MOTA 只能考慮短期關(guān)聯(lián)。它只能評估算法執(zhí)行一階關(guān)聯(lián)的效果,而不能評估算法在整個軌跡中的關(guān)聯(lián)效果。且它根本沒有考慮關(guān)聯(lián)精度/ID轉(zhuǎn)換。事實上,如果一個跟蹤器能夠糾正任何關(guān)聯(lián)錯誤,它會懲罰它而不是獎勵它。MOTA 的最高分是1,但是沒有一個固定的最小值,這會導(dǎo)致 MOTA 的分數(shù)為負。
IDF1
ID度量。它試圖將預(yù)測的軌跡與實際軌跡進行映射,這與MOTA等在檢測級別執(zhí)行雙射線映射的指標形成對比。它被設(shè)計用來測量“識別”,不同于檢測和關(guān)聯(lián),它與軌跡有關(guān).
IDTP:代表ID真正例,預(yù)測得到的目標軌跡與groundtruth目標軌跡匹配。IDFN:ID假反例。任何未被發(fā)現(xiàn)的groundtruth值并且其軌跡未被匹配。IDFP:ID誤檢。任何錯誤的預(yù)測結(jié)果。 由于MOTA對檢測精度的高度依賴,一些人更喜歡IDF1,因為該指標更注重關(guān)聯(lián)性。
然而,IDF1也有一些缺陷。在IDF1中,最佳unique的雙映射不會導(dǎo)致預(yù)測軌跡和實際軌跡之間的最佳對齊。最終結(jié)果將為更好的匹配留下空間。即使檢測正確,IDF1分數(shù)也會降低。如果有很多不匹配的軌跡,分數(shù)也會降低。這促使研究人員增加unique的總數(shù)量,而不是專注于進行合理的檢測和關(guān)聯(lián)。
Track-mAP
這種度量匹配GroundTruth軌跡和預(yù)測軌跡。當(dāng)軌跡相似性得分Str大于或等于閾值αtr時,在軌跡之間進行匹配。此外,預(yù)測的軌跡必須具有最高的置信度得分。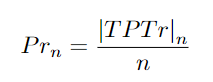
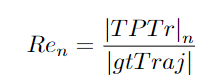
n:預(yù)測軌跡的總數(shù)。預(yù)測軌跡按照置信度得分降序排列。Prn:計算跟蹤器的精度。TPTr:真正軌跡。找到匹配的任何預(yù)測軌跡。|TPTr|n:n條預(yù)測軌跡中的真正軌跡數(shù)。Ren:Measures Re-call。|gtTraj |:目標軌跡真值,使用精度和召回方程進行進一步計算,以獲得最終Track?mAP分數(shù)。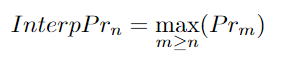
作者首先對精度值進行插值,得到每個n值的InterpPr。然后,作者將每個n值繪制一個InterpPr與 Ren 對應(yīng)的圖。作者現(xiàn)在有了精確-召回曲線。這條曲線的積分會給出 Track-mAP 得分。Track-mAP 也有一些缺點。軌跡mAP的跟蹤結(jié)果很難直觀地顯示出來。
它對于單個軌道有多個輸出。低置信度得分的軌跡對最終得分的影響是模糊的。有一種方法可以“黑掉”這個度量標準。研究人員可以得到一個較高的分數(shù),通過創(chuàng)造幾個有較低置信度分數(shù)的預(yù)測。這將增加獲得合適匹配的機會,從而增加得分。然而,這并不是一個良好跟蹤的指標。跟蹤 mAP 無法指示跟蹤器是否具有更好的檢測和關(guān)聯(lián)。
HOTA
Higher Order Tracking Accuracy。原論文[96]將 HOTA 描述為: “ HOTA 測量匹配檢測的軌跡對齊程度,并對整體匹配檢測進行平均,同時懲罰不匹配的檢測。”HOTA 應(yīng)該是一個單一的分數(shù),可以涵蓋跟蹤評估的所有要素。它還應(yīng)該被分解為子度量。HOTA 彌補了其他常用指標的缺點。雖然像 MOTA 這樣的指標忽略關(guān)聯(lián)并且嚴重依賴于檢測(MOTA)或反之亦然(IDF1),但是 TPA,F(xiàn)PA 和 FNA 等新概念的發(fā)展使得關(guān)聯(lián)可以像TP,F(xiàn)Ns 和 FP 用于測量檢測一樣進行測量。
A(c):測量預(yù)測軌跡和groundtruth軌跡的相似程度。TP:真正例,在S ≥ α的條件下,將groundtruth檢測與預(yù)測檢測相匹配。S是定位相似度,α是閾值。FN: 假反例。漏掉的groundtruth檢測 FP: 假正例。一種沒有與任何groundtruth匹配的預(yù)測。TPA: 真正關(guān)聯(lián)正例。與給定的 TPC 具有相同的groundtruth ID和相同的預(yù)測ID的真正正例的集合。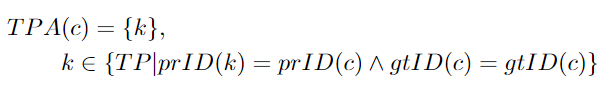
FNA: 具有與給定TPC相同的groundtruth ID的一組groundtruth檢測目標。然而,這些檢測目標被分配了一個不同于c或根本沒有的預(yù)測ID。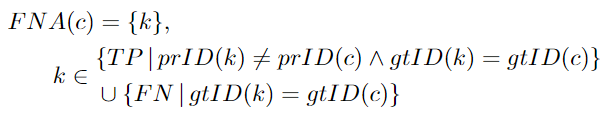
FPA:與給定TPc具有相同預(yù)測ID的預(yù)測檢測集。然而,這些檢測目標被分配了一個不同于c的groundtruth ID,或者根本沒有。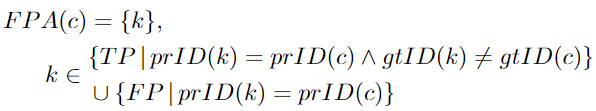
HOTaα 是計算α的特殊值的HOTA。需要進一步計算才能得到最終的HOTA分數(shù)。作者找到了不同α的值對應(yīng)的HOTA,α范圍從0到1,然后計算它們的平均值。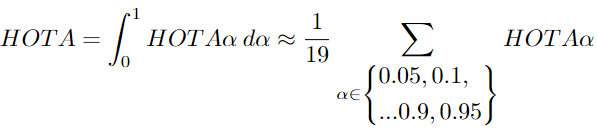
作者能夠?qū)?HOTA 分解為幾個子指標。這很有用,因為可以采用跟蹤評估的不同元素,并使用它們進行比較。可以更好地了解跟蹤器正在產(chǎn)生的錯誤。跟蹤中常見的錯誤有五種類型: 假反例、假正例、碎片化、合并和偏差。這些可以分別通過檢測召回、檢測精度、關(guān)聯(lián)召回、關(guān)聯(lián)精度和定位來衡量。
LocA
Localization Accuracy[96].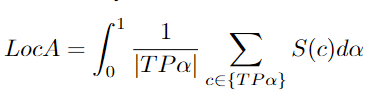
S(c): 預(yù)測檢測與groundtruth之間的空間相似性得分。這個子度量處理錯誤類型偏差或定位錯誤。當(dāng)預(yù)測檢測和groundtruth不一致時,就會產(chǎn)生定位誤差。這與 MOTP 類似,但又不同,因為它包含幾個定位閾值。常用的度量標準,如 MOTA 和 IDF1沒有考慮到定位。
AssA:Association Accuracy Score
根據(jù) MOT 基準: “所有匹配檢測的關(guān)聯(lián)Jaccard索引的平均值,平均值超過定位閾值”[96]。關(guān)聯(lián)是MOT 任務(wù)結(jié)果的一部分,它讓大家知道不同幀中的目標是屬于同一個還是不同的目標。這些目標具有相同的ID,并且是相同軌跡的一部分。關(guān)聯(lián)精度給出了匹配軌跡之間的平均對齊度。它主要關(guān)注關(guān)聯(lián)錯誤。這是由于groundtruth中的單個目標被給予了兩種不同的預(yù)測,或者一個單獨的預(yù)測被給予了兩種不同的groundtruth目標。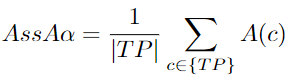
DetA:Detection Accuracy
根據(jù) MOT 基準: “檢測 Jaccard 索引平均超過定位閾值”[96]。檢測是 MOT 任務(wù)的另一個輸出。它只是幀內(nèi)的目標。檢測精度是正確檢測的一部分。當(dāng)groundtruth被忽略或者存在虛假檢測時,檢測誤差就會存在。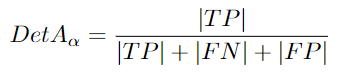
DetRe:Detection Recall
給出了一個定位閾值的計算方程。需要平均所有定位閾值[96]: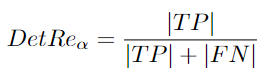
檢測召回錯誤是假反例。它們發(fā)生時,跟蹤器錯過了一個真實目標,檢測精度可分為檢測召回和檢測精度。
DetPr:
給出了一個計算定位閾值的方程,需要對所有定位閾值進行平均[96]: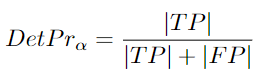
如前所述,檢測精度是檢測精度的一部分。檢測精度誤差為假正例(誤檢)。當(dāng)追蹤器做出不存在于groundtruth中的預(yù)測時,它們就會發(fā)生。
AssRe:Association Recall
需要計算下面的公式,然后計算所有匹配檢測的平均值。最后,平均結(jié)果要超過定位閾值[96]: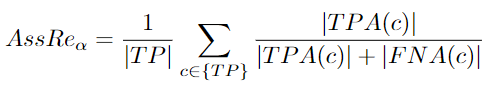
當(dāng)跟蹤器將不同的預(yù)測軌跡分配給相同的groundtruth軌跡時,就會發(fā)生關(guān)聯(lián)召回錯誤。關(guān)聯(lián)精度可分為關(guān)聯(lián)召回和關(guān)聯(lián)精度。
AssPr:Association Precision
作者需要計算下面的方程,然后對所有匹配檢測進行平均。最后,結(jié)果的平均值超過定位閾值[96]: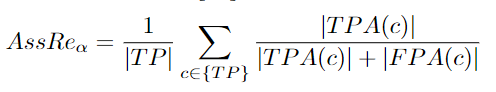
關(guān)聯(lián)精度是關(guān)聯(lián)精度的一部分。當(dāng)兩條不同的groundtruth軌跡具有相同的預(yù)測ID時,就會出現(xiàn)關(guān)聯(lián)錯誤。
MOTSA: Multi Object Tracking and Segmentation Accuracy
這是 MOTA 度量的一種變體,因此也可以評估分割任務(wù)的跟蹤器性能。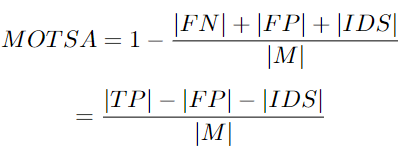
這里 M 是一組 N 個非空的groundtruth掩模。每個mask被分配一個groundtruth跟蹤ID。TP 是一組真正例。當(dāng)一個假設(shè)的掩碼映射到一個groundtruth掩碼時,真正例出現(xiàn)。FP 是假正例的,沒有任何groundtruth,F(xiàn)N是一組假反例,有真值但沒有任何相應(yīng)的檢測結(jié)果。
IDS、ID切換是屬于同一軌道但被分配了不同ID的groundtruth掩碼。MOTSA 算法的缺點包括: 使檢測比關(guān)聯(lián)更加重要,并且會受到匹配閾值選擇的影響。
AMOTA: Average Multiple Object Tracking Precision
這是通過平均所有recall的MOTA值來計算的: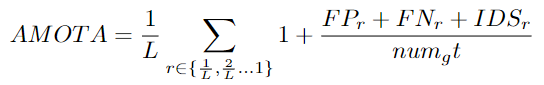
numg數(shù)值是所有幀中g(shù)roundtruth目標的數(shù)量。對于一個特定的召回值r,F(xiàn)P的數(shù)目、FN的數(shù)目和ID切換的數(shù)目表示為 FPr、 FNr 和 IDSr。召回值的數(shù)量用 L 表示。
應(yīng)用
MOT有無數(shù)應(yīng)用程序。許多工作都涉及到跟蹤各種目標,包括行人、動物、魚、車輛、體育運動員等。實際上,多目標跟蹤的領(lǐng)域不能僅限于幾個領(lǐng)域。但是,為了從應(yīng)用的角度獲得一個想法,作者將根據(jù)具體的應(yīng)用涵蓋論文。
自動駕駛
自動駕駛可以說是多目標跟蹤中最常見的任務(wù)。這是近年來人工智能領(lǐng)域的一個熱門話題。高等人提出了一個自動駕駛的雙重注意力網(wǎng)絡(luò),他們整合了兩個注意力模塊[97]。傅先生等人首先利用自注意力機制檢測車輛,然后利用多維信息進行關(guān)聯(lián)。他們還通過重新跟蹤失蹤的車輛來處理堵塞問題[62]。
龐等人將車輛檢測與基于隨機有限集(RFS)引入3D MOT 的多測量模型濾波器(RFS-M3)相結(jié)合[98]。羅等人還應(yīng)用了3D MOT技術(shù),提出了模擬跟蹤技術(shù),該技術(shù)可以通過激光雷達捕捉到的點云來檢測和關(guān)聯(lián)飛行器。Mackenzie 等人做了兩項研究: 一項是關(guān)于自動駕駛汽車的,另一項是關(guān)于運動的。
他們研究了多目標避讓(MOA)的整體表現(xiàn),這是一種測量自動駕駛中行動注意力的工具。鄒等人提出了一個輕量級的框架,用于路邊攝像機拍攝的2D交通場景的全棧感知。Cho等人通過YOLOv4和DeepSORT的交通監(jiān)控攝像頭,在將圖像從局部到全局坐標系統(tǒng)投影后,識別并跟蹤了這些車輛[101]。
其它
行人跟蹤:是多目標跟蹤系統(tǒng)中最常見的任務(wù)之一。由于街頭攝像頭的視頻很容易被捕捉,人們已經(jīng)做了很多關(guān)于人類或行人跟蹤的工作。 車輛監(jiān)控:與自動駕駛一樣,也是一項非常重要的任務(wù)。為了監(jiān)控車輛的活動,可以應(yīng)用MOT技術(shù)。
運動員跟蹤:在人工智能時代,對任何運動中的運動員進行嚴格的分析都是最重要的戰(zhàn)術(shù)之一。因此 MOT 在許多方面被用來跟蹤運動員。 野生動物追蹤:MOT 的一個潛在應(yīng)用案例是野生動物跟蹤。它可以幫助野生動物研究人員避免昂貴的傳感器,這些傳感器在某些情況下并不那么可靠。
MOT在跟蹤魚類等水下生物方面也發(fā)揮著至關(guān)重要的作用。在[118]中,李等人提出了 CMFTNet,它通過應(yīng)用聯(lián)合檢測和嵌入來提取和關(guān)聯(lián)特征來實現(xiàn)。在復(fù)雜背景下,采用可變形卷積方法進一步提高特征的銳化能力,并借助重量平衡損失的方法實現(xiàn)對魚的精確跟蹤。
在視覺監(jiān)控領(lǐng)域,Ahmed 等人提出了一個基于SSD和YOLO的協(xié)作機器人框架,用于檢測和一系列跟蹤算法的組合[120]。 還可以看到MOT在農(nóng)業(yè)中的實施。為了跟蹤番茄種植,Ge 等人使用基于YOLO的shufflenetv2作為基線,CBAM 作為注意力機制,BiFPN 作為多尺度融合結(jié)構(gòu),DeepSORT 作為跟蹤[125]。Tan 等人還使用 YOLOv4作為棉花幼苗的檢測器和一種基于光流的跟蹤方法來跟蹤幼苗[49]。
MOT還可以應(yīng)用于各種現(xiàn)實生活中的應(yīng)用,如安全監(jiān)控、社會距離監(jiān)控、雷達跟蹤、活動識別、智能老年護理、犯罪跟蹤、人員重識別、行為分析等。
未來方向
由于 MOT 是一個多年來的研究熱點,人們已經(jīng)在它上面做了大量的努力。但是,這個領(lǐng)域仍然有很大的發(fā)展空間。在這里,作者想指出一些MOT的潛在的方向:
在多個攝像頭下進行多目標跟蹤有點困難。主要的挑戰(zhàn)是如何融合這些場景。但是,如果將非重疊攝像機的場景融合在一起,投影到虛擬世界中,那么 MOT 就可以在一個較長的區(qū)域內(nèi)連續(xù)跟蹤目標。類似的努力可以在[31]中看到。一個相對較新的數(shù)據(jù)集多攝像機多人跟蹤也可用[126]。Xindi等人提出了一種用于多目標多攝像機跟蹤的實時在線跟蹤系統(tǒng)[127]。
基于類的跟蹤系統(tǒng)可以與多目標跟蹤相結(jié)合。MOT算法試圖跟蹤一幀中幾乎所有的運動目標。如果可以進行基于類的跟蹤,這將更好地應(yīng)用于實際場景中。例如,鳥類跟蹤MOT系統(tǒng)在機場非常有用,因為為了防止鳥類與飛機在跑道上相撞,目前采用了一些人工預(yù)防機制。它可以完全自動使用基于類的MOT系統(tǒng)。基于類的跟蹤在許多方面有助于監(jiān)視。因為它有助于有效地跟蹤特定類型的目標。
MOT 在二維場景中有著廣泛的應(yīng)用。雖然這是一個有點具有挑戰(zhàn)性的任務(wù),利用MOT分析3D視頻將是一個很好的研究課題。三維跟蹤可以提供更精確的跟蹤和遮擋處理。正如在三維場景深度信息保存,因此它有助于克服一個主要的挑戰(zhàn),MOT中的遮擋問題。
到目前為止,大多數(shù)transformer都被用作黑匣子。但transformer可以更具體地用于解決不同的MOT任務(wù)。一些方法是完全基于檢測和進一步的回歸被用來預(yù)測下一幀的邊界框[128]。在這種情況下,DETR[25]可用于檢測,因為它在檢測目標方面有非常高的效率。
在任何應(yīng)用程序中,輕量級體系結(jié)構(gòu)對于實際應(yīng)用程序都非常重要。因為輕量級體系結(jié)構(gòu)是資源有效的,而且在實際場景中,資源是有限的。在MOT中,如果想在物聯(lián)網(wǎng)嵌入式設(shè)備中部署一個模型,輕量級架構(gòu)也是非常關(guān)鍵的。同時在實時跟蹤中,輕量級體系結(jié)構(gòu)起著非常重要的作用。因此,在不降低精度的情況下,如果能夠?qū)崿F(xiàn)更多的fps,那么它就可以在實際應(yīng)用中實現(xiàn),在實際應(yīng)用中,輕量級體系結(jié)構(gòu)是非常必要的。
在現(xiàn)實生活中,在線多目標跟蹤是唯一可行的解決方案。因此,推理時間起著至關(guān)重要的作用。作者觀察到近年來從研究人員那里獲得更多準確性的趨勢。但是,如果能夠?qū)崿F(xiàn)超過30幀率的推理時間,那么就可以使用MOT作為實時跟蹤。由于實時跟蹤是監(jiān)控的關(guān)鍵,因此它是未來 MOT 研究的主要方向之一。
近年來,量子計算在計算機視覺中的應(yīng)用呈現(xiàn)出一種趨勢。量子計算也可以用于MOT。Zaech等人在Ising模型的幫助下發(fā)表了MOT使用絕熱量子計算(AQC)的第一篇論文[129]。他們期望AQC能夠在將來的關(guān)聯(lián)過程中加速N-P硬分配問題。由于量子計算在不久的將來具有很大的潛力,這可能是一個非常有前途的研究領(lǐng)域。
總結(jié)
本文試圖對計算機視覺在MOT中的最新發(fā)展趨勢進行總結(jié)和回顧。作者試圖分析其局限性和重大挑戰(zhàn)。與此同時,作者發(fā)現(xiàn),除了一些主要的挑戰(zhàn),如遮擋,ID切換,也有一些小的挑戰(zhàn)。這項研究包括了與每種方法相關(guān)的簡要理論,試圖平等地關(guān)注每一種方法。
作者也添加了一些流行的基準數(shù)據(jù)集以及他們自己的見解。根據(jù)最近的MOT趨勢,展望了一些MOT未來可能的方向。作者發(fā)現(xiàn),最近研究人員更多地關(guān)注基于transformer的結(jié)構(gòu),這是因為transformer的上下文信息存儲能力。由于輕量級架構(gòu)的transformer仍然是很吃資源的,所以開發(fā)新的模塊也很必要。最后,希望本文的研究能夠?qū)Χ嗄繕烁欘I(lǐng)域的研究者起到補充作用,開啟多目標跟蹤研究的新篇章。
審核編輯:劉清
-
計算機視覺
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46613 -
自動駕駛
+關(guān)注
關(guān)注
788文章
14242瀏覽量
169908 -
LSTM
+關(guān)注
關(guān)注
0文章
60瀏覽量
3999
原文標題:多目標跟蹤最新綜述(基于Transformer/圖模型/檢測和關(guān)聯(lián)/孿生網(wǎng)絡(luò))
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
工業(yè)計算機的定義與重要性






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論