 基于異常檢測的模型表現對比
基于異常檢測的模型表現對比
本文將從以下6個方面介紹:
異常分類
異常檢測的挑戰
異常檢測的模型分類
異常檢測的數據集
異常檢測的模型表現對比
結論和未來方向
一、異常分類
以前傳統關于異常檢測的分類如圖1(a)所示,分為:
●點異常值:相對于全局其他數據的異常實例。
●上下文異常值:上下文異常值通常在它們自己的上下文中具有相對較大/較小的值,但不是全局的。
●集體異常值:被定義為相對于整個數據集異常的相關異常數據實例的集合。
但這種分類方式常因為上下文定義邊界模糊,導致集體異常值和上下文異常值的定義邊界也模糊。上下文異常值的上下文在不同文獻中通常非常不同。它們可以是一個小窗口,包含相鄰點或在季節性方面具有相似相對位置的點。比如圖2中的集體異常值,如果以季節性方面的上下文考慮,其實也能看做是上下文異常。
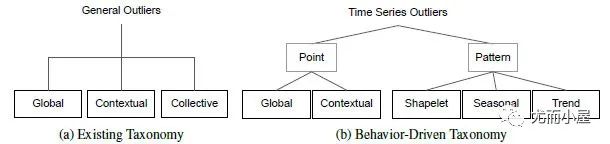 圖1:新舊異常分類對比
圖1:新舊異常分類對比
綜述[5]提出了新的異常分類法,如圖1(b)所示。具體的樣例如下:
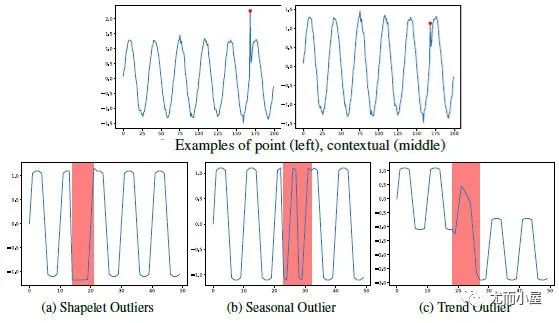 圖2:新異常分類下的數據樣例
圖2:新異常分類下的數據樣例
關于3類Pattern異常,可以基于shapelet函數來定義:其中, ,X是由多個不同
+頻率的波的值相加得到的。為趨勢項,例如線性函數 。如果s為相似度度量函數,那么以上3種異常類型可以分別定義為:
●shapelet outliers (異常的局部子序列): 。
●seasonal outliers (異常周期性的局部子序列): 。
●trend outliers (異常趨勢的局部子序列): 。
其中, 為異常判定的閾值。
二、異常檢測的挑戰
綜述[4]介紹了深度異常檢測解決的主要挑戰:
●CH1:異常檢測召回率低。由于異常非常罕見且異質,因此很難識別所有異常。
●CH2:異常通常在低維空間中表現出明顯的異常特征,而在高維空間中變得隱藏且不明顯。
●CH3:正常/異常的數據高效學習。利用標記數據來學習正常/異常的表征,對于準確的異常檢測至關重要。
●CH4:抗噪異常檢測。許多弱/半監督異常檢測方法假設標記的訓練數據是干凈的,這可能容易受到被錯誤標記為相反類別標簽的噪聲實例的影響。
●CH5:復雜異常的檢測。現有的大多數方法都是針對點異常的,不能用于條件異常和組異常,因為它們表現出與點異常完全不同的行為。
●CH6:異常解釋。在許多安全關鍵領域中,如果將異常檢測模型直接用作黑盒模型,則可能存在一些重大風險。
圖3展示了傳統方法和深度方法在不同能力上的區別,以及不同能力對解決哪些挑戰至關重要:
 圖3:傳統方法和深度方法的能力對比
圖3:傳統方法和深度方法的能力對比
具體到模型上的挑戰,會在下面進行詳細講解。
三、異常檢測的模型分類
不同綜述對時序異常檢測的模型分類方式也挺不同的,比如:
● 綜述[3]:分為統計方法,經典機器學習方法和使用神經網絡的異常檢測方法。
● 綜述[5]:分為基于預測偏差的方法,基于時序表征分類的方法,基于子序列不一致性分析的方法。
● 綜述[4]:針對神經網絡算法,分為特征提取的方法,學習常態特征表征的方法,端對端學習異常分數的方法。
我總結如下:
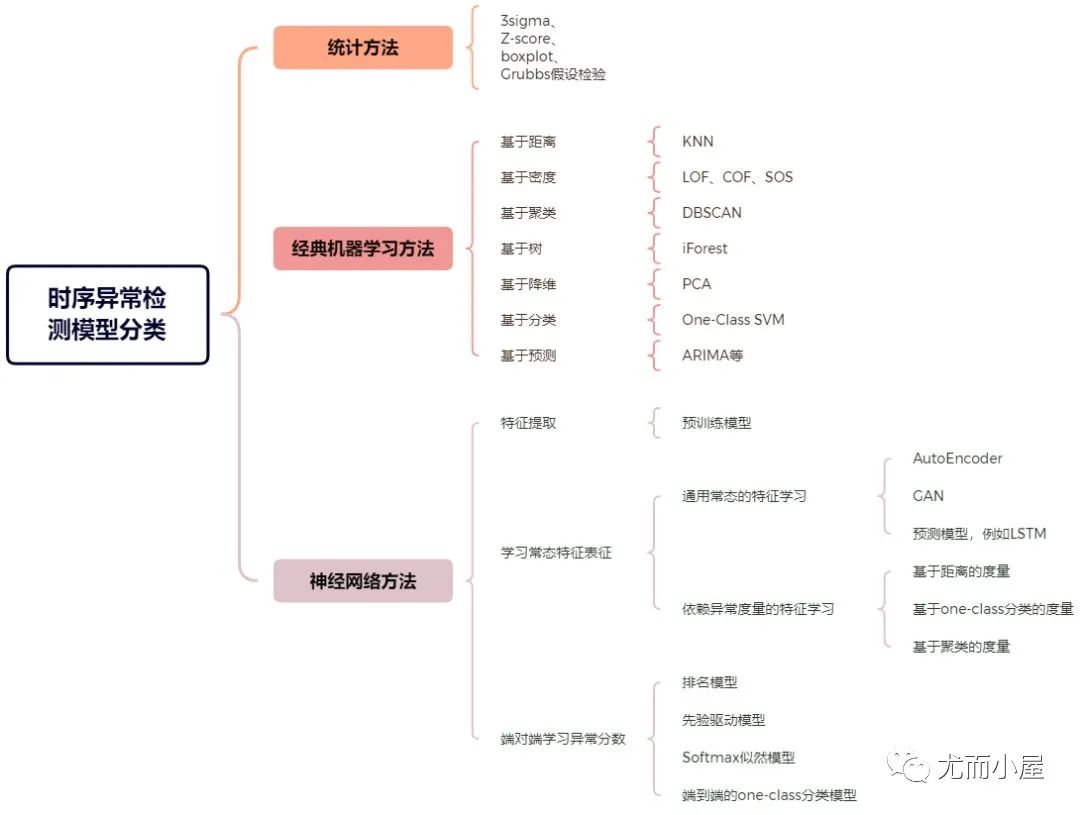 圖4:時序異常檢測的模型分類
圖4:時序異常檢測的模型分類
在之前的文章里,統計方法和經典機器學習的方法基本都已經介紹過了,這邊就不重復介紹了。
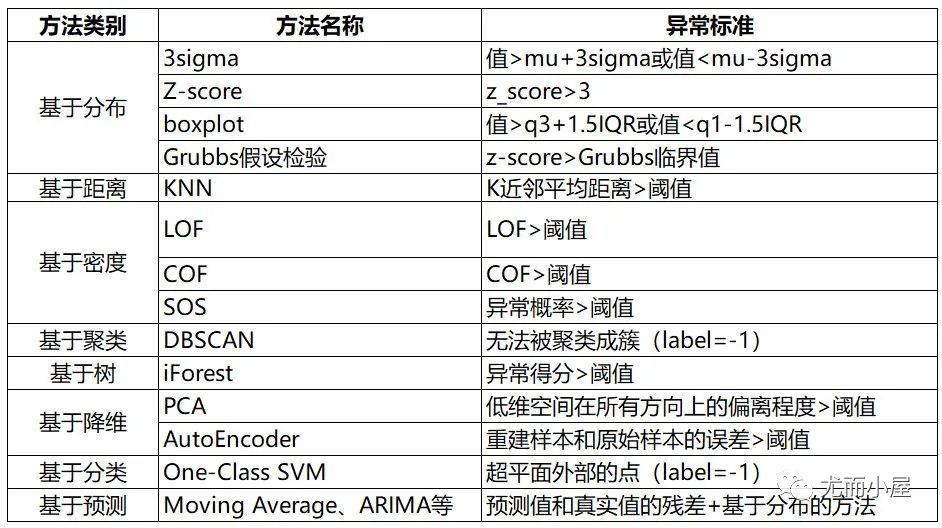 圖5:統計方法和經典機器學習的方法總結
圖5:統計方法和經典機器學習的方法總結
這里,主要基于綜述[4],介紹下神經網絡下的模型分類,其實zero在知乎已經整理了這篇綜述內容,寫的很好,強烈建議閱讀文章[6]。
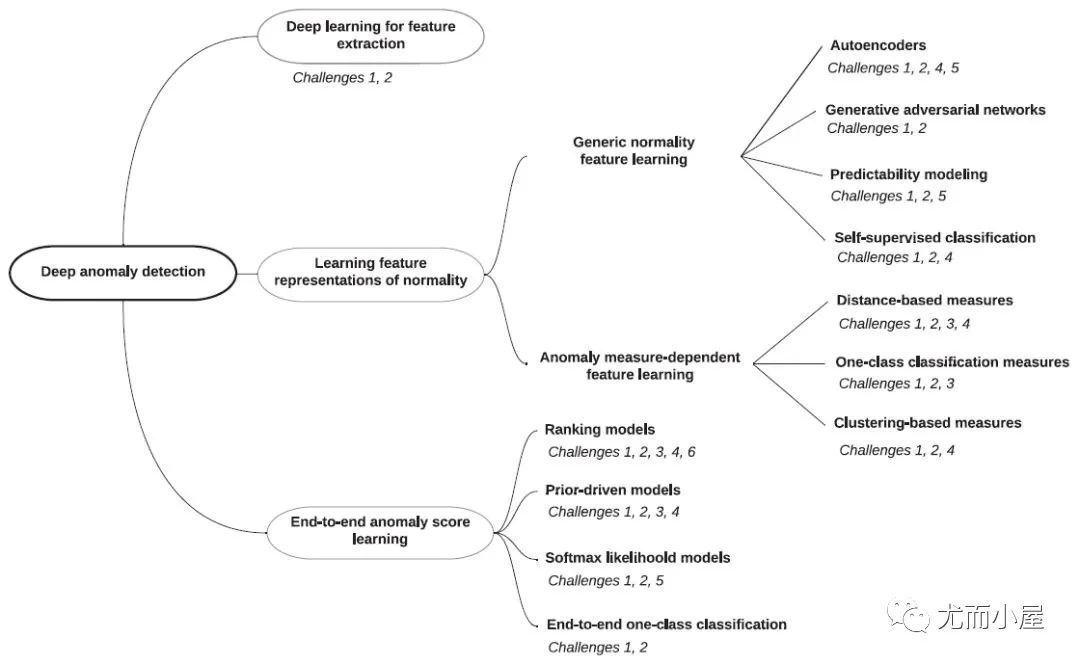 圖6:神經網絡異常檢測方法分類
圖6:神經網絡異常檢測方法分類
神經網絡下的模型分類如下:
1. 特征提取:deep learning和anomaly detection是分開的,deep learning只負責特征提取。
2. 常態特征表征學習:deep learning和anomaly detection是相互依賴的,一起學習正常樣本的有效表征。
●通用常態特征表征學習:這類方法最優化一個特征學習目標函數,該函數不是為異常檢測而設計的,但學習到的高級特征能夠用于異常檢測,因為這些高級特征包含了數據的隱藏規律。
●依賴異常度量的特征表征學習:該類方法直接將現有的異常評價指標嵌入表征學習的優化目標中。
3. 端對端異常分數學習:deep learning和anomaly detection是完全一體的,通過端到端的學習,直接輸出異常分數。
1. 特征提取
旨在利用深度學習從高維和/或非線性可分離數據中提取低維特征表征,用于下游異常檢測。特征提取和異常評分完全不相交且彼此獨立。因此,深度學習組件僅作為降維工作。
優點:
● 很容易獲得大量先進的預訓練深度模型和現成的異常檢測器做特征提取和異常檢測;
● 深度特征提取比傳統線性方法更有效。
缺點:
● 特征提取和異常評分是獨立分開的,通常會導致次優的異常評分;
● 預訓練的深度模型通常僅限于特定類型的數據。(感覺更適用于圖像,因為圖像可以做分類預訓練,個人對時序預訓練了解的不是很多)。
2. 通用常態特征表征學習
這類方法最優化一個特征學習目標函數,該函數不是為異常檢測而設計的。
但學習到的高級特征能夠用于異常檢測,因為這些高級特征包含了數據的隱藏規律。例如:AutoEncoder、GAN、預測模型。
優點:
● AE:方法簡單,可用不同AE變種;
● GAN:產生正常樣本的能力很強,而產生異常樣本的能力就很弱,因此有利于進行異常檢測;
● 預測模型:存在大量序列預測模型,能學到時間和空間的依賴性。
缺點:
● AE:學習到的特征表征可能會因為“訓練數據中不常見的規律、異常值或噪聲“而產生偏差;
● GAN:訓練可能存在多種問題,比如難以收斂,模式坍塌。因此,基于異常檢測的 GANs 訓練或難以進行;
● 預測模型:序列預測的計算成本高。
另外,以上方法都有兩個共性問題:
●都假設訓練集是正常樣本,但若訓練集中混入噪聲或異常值,會給模型表征學習能力帶來偏差;
●沒有將異常評價納入到模型優化的目標當中,最后檢測的結果可能是次優的。
3. 依賴異常度量的特征表征學習
該類方法直接將現有的異常評價指標嵌入表征學習的優化目標中,解決了通用常態特征表征學習中第二個共性問題。例如Deep one-class SVM,Deep one-class Support Vector Data Description (Deep one-class SVDD)等。
優化:
● 基于距離的度量:比起傳統方法,能處理高維空間數據,有豐富的理論支持;
● 基于one-class分類的度量:表征學習和one-class模型能一起學習更好的特征表示,同時免于手動選擇核函數;
● 基于聚類的度量:對于復雜數據,可以讓聚類方法在深度專門優化后的表征空間內檢測異常點。
缺點:
● 基于距離的度量:計算量大;
● 基于one-class分類的度量:在正常類內分布復雜的數據集上,該模型可能會無效;
● 基于聚類的度量:模型的表現嚴重依賴于聚類結果。也受污染數據的影響。
以上缺點在于:沒辦法直接輸出異常分數。
3. 端對端異常分數學習
通過端到端的學習,直接輸出異常分數。個人對這部分的了解是一片空白,只能初略轉述下綜述中的內容,有興趣的朋友可以閱讀原文跟進相關工作。
優點:
● 排名模型:利用了排序理論;
● 先驗驅動模型:將不同的先驗分布嵌入到模型中,并提供更多解釋性;
● Softmax似然模型:可以捕捉異常的特征交互信息;
● 端到端的one-class分類模型:端到端式的對抗式優化,GAN有豐富的理論和實踐支持。
缺點:
● 排名模型:訓練數據中必須要有異常樣本;
● 先驗驅動模型:沒法設計一個普遍有效的先驗,若先驗分布不能很好地擬合真實分布,模型的效果可能會變差;
● Softmax似然模型:特征交互的計算成本很大,而且模型依賴負樣本的質量;
● 端到端的one-class分類模型:GAN具有不穩定性,且僅限于半監督異常檢測場景。
深度相關的30個代表性模型:
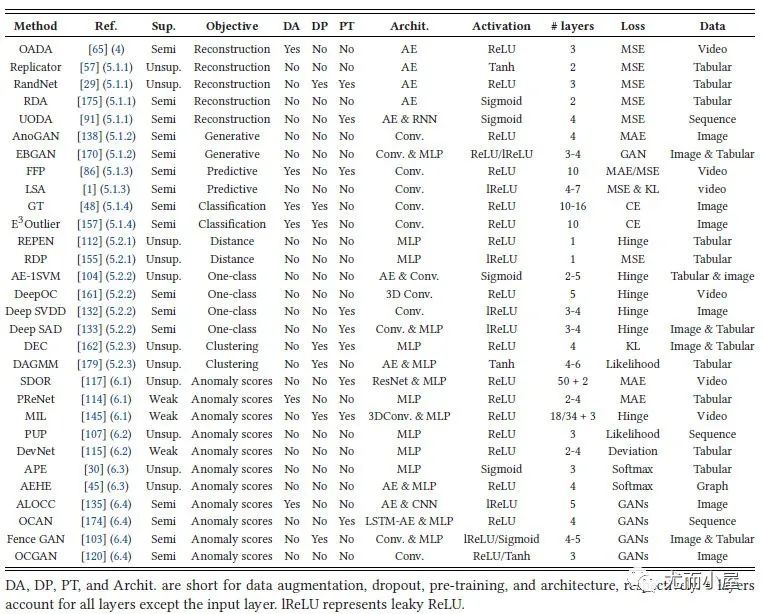 圖7:30個代表性的深度模型
圖7:30個代表性的深度模型
四、異常檢測的數據集
SEQ:[5]中提出基于shapelet函數,我們可以獲取35個合成數據集(可稱NeurlIPS-TS synthestic datasets or SEQ),其中20個單變量,15個多變量數據集。該數據集覆蓋各類異常數據。
21個開源真實數據集:
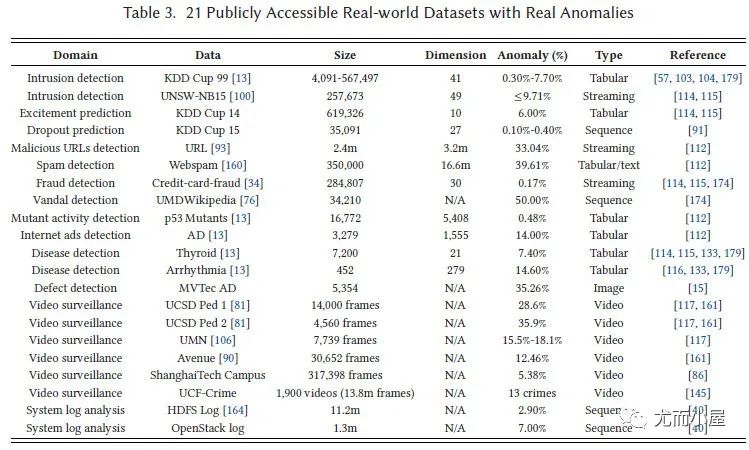 圖8:21個開源真實數據集[4]
圖8:21個開源真實數據集[4]
五、異常檢測的模型表現對比
各類綜述論文下的模型表現,因為所用數據集,參數或后處理不一致,導致表現對比可能存在差異,這里僅供參考。
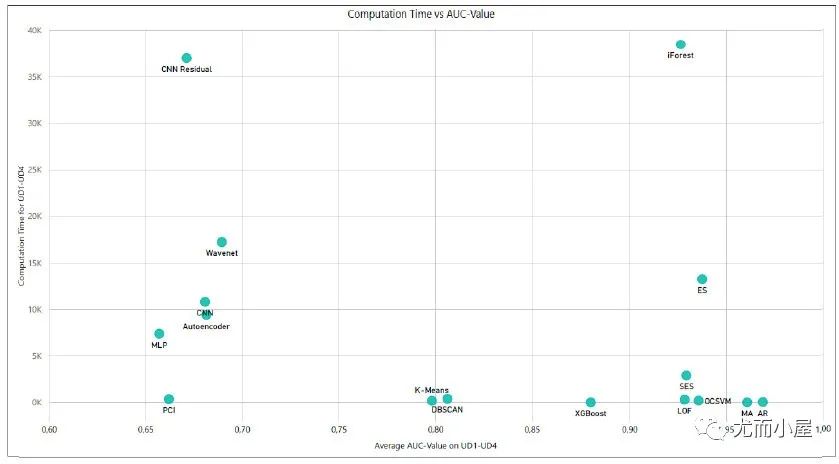 圖9:在UD1-UD4數據集上個模型AUC和計算時間的對比[3]
圖9:在UD1-UD4數據集上個模型AUC和計算時間的對比[3] 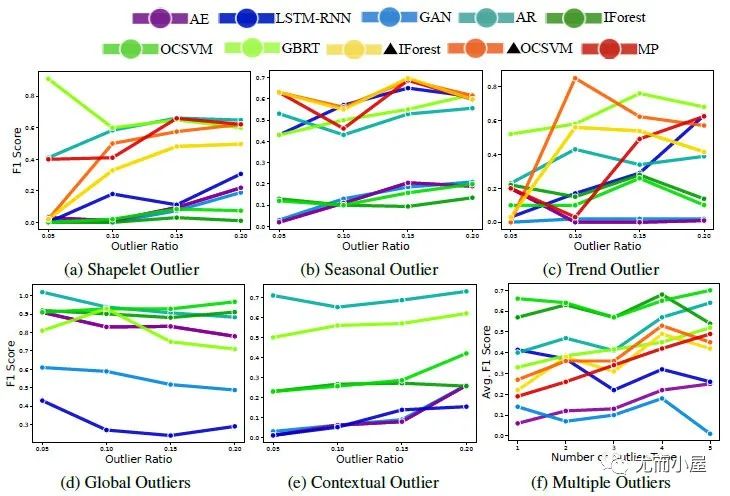 圖10:在合成數據SEQ上的模型表現[5]
圖10:在合成數據SEQ上的模型表現[5]
圖10很明顯打臉了一眾深度模型,我們不可否認實際業務場景中,深度模型性能的不穩定,傳統模型確實更好用,但在學術圈里,深度模型還是有它研究價值在;
而有些深度異常檢測論文的F1分數比圖10高,除了參數和數據問題,也可能是像Anomaly Transformer代碼Issue中很多人提到的類似“detection adjustment”后處理優化的結果。所以這塊仁者見仁智者見智吧。
六、結論和未來方向
綜述[4]給出了未來異常檢測的結論和發展方向:
●把異常度量目標加入到表征學習中:表征學習時,一個關鍵問題是它們的目標函數是通用的,但沒有專門針對異常檢測進行優化。在前面有提到依賴于異常度量的特征學習,它便是通過施加來自傳統異常度量的約束,來幫助解決這個問題;
●探索少標記樣本的利用:探索利用這些小標記數據來學習更強大的檢測模型和更深層次架構;
●大規模無監督/自監督表示學習:首先在無監督/自監督模式下從大規模未標記數據中學習可遷移的預訓練表示模型,然后在半監督模式下微調異常檢測模型;
●復雜異常的深度檢測:對條件/組異常的深度模型的探索明顯較少。另外多模態異常檢測是一個很大程度上尚未探索的研究領域;
●可解釋和可操作的深度異常檢測:具有提供異常解釋的內在能力的深度模型很重要,能減輕對人類用戶的任何潛在偏見/風險以及實現決策行動;
●新穎的應用和設置:例如分布外 (OOD) 檢測、curiosity learning等。
個人來看,在【三、異常檢測的模型分類】里談論的模型中,我們可以相互借鑒,比如Anomaly Transformer便采取了依賴異常度量的特征表征學習,同時還借鑒了端對端異常分數學習中的先驗驅動模型,引入了先驗關聯。
當我們帶著各類模型優缺點的基礎知識去閱讀新論文時,也能引發思考,比如Anomaly Transformer的先驗關聯采用高斯分布是否普遍有效?若窗口內存在離散異常尖峰(即多峰異常),那單峰先驗關聯和多峰序列關聯是否便存在一定關聯差異,那么檢測效果是不是會有負面影響?多頭Anomaly Attention是否可以緩解這個問題?
這有些跑題了,但希望本篇文章大家能帶來些反思和啟發,鼓勵閱讀綜述原文,深入了解其中的思想。
-
函數
+關注
關注
3文章
4374瀏覽量
64377 -
模型
+關注
關注
1文章
3500瀏覽量
50104 -
數據集
+關注
關注
4文章
1223瀏覽量
25313
原文標題:時序異常檢測綜述整理!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于變分自編碼器的異常小區檢測
基于特征模式的馬爾可夫鏈異常檢測模型
基于危險模式的異常檢測模型
基于隱馬爾可夫模型的視頻異常檢測模型
基于稀疏隨機森林模型的用電側異常行為檢測
基于概率圖模型的時空異常事件檢測算法
基于健壯多元概率校準模型的全網絡異常檢測
云模型的網絡異常流量檢測
基于Greenshield模型的異常節點檢測機制
一種多維時間序列汽車駕駛異常點檢測模型
如何選擇異常檢測算法
FreeWheel基于機器學習的業務異常檢測實踐
哈工大提出Myriad:利用視覺專家進行工業異常檢測的大型多模態模型

基于DiAD擴散模型的多類異常檢測工作






 工商網監
工商網監
評論